1. 인코딩 관련
문자열 인코딩과 문자 집합
- 프로세스와 메모리에서는 바이너리로 데이터를 읽고, 쓰므로 모든 것들이 2진수로 처리된다. 문자열 인코딩은 2진수 데이터를 어떤 식으로 읽어서 문자로 표현할지에 대한 방식을 의미한다.
- UTF-16으로 쓴 문자열을, UTF-8로 읽을 경우 문자가 깨지게 된다. 읽고자 하는 텍스트의 인코딩 방식으로 읽어야한다.
- 예시 : 아스키 코드, EUC-KR, UTF-8, UTF-16
- 문자 집합 chracter set : 문자들의 모음으로 ASCII는 영어와 여러 특수 문자의 모음, 유니코드는 전세계 문자들의 모음
- 문자 집합과 문자열 인코딩의 차이 : 문자집합인 유니코드를 인코딩 한 방식이 UTF-8, UTF-16 등이므로 문자 집합(바이너리=수와 문자의 관계 모음)과 인코딩 방식(바이너리를 어떻게 읽을지에 대한 규칙)이란 점에서 다름.
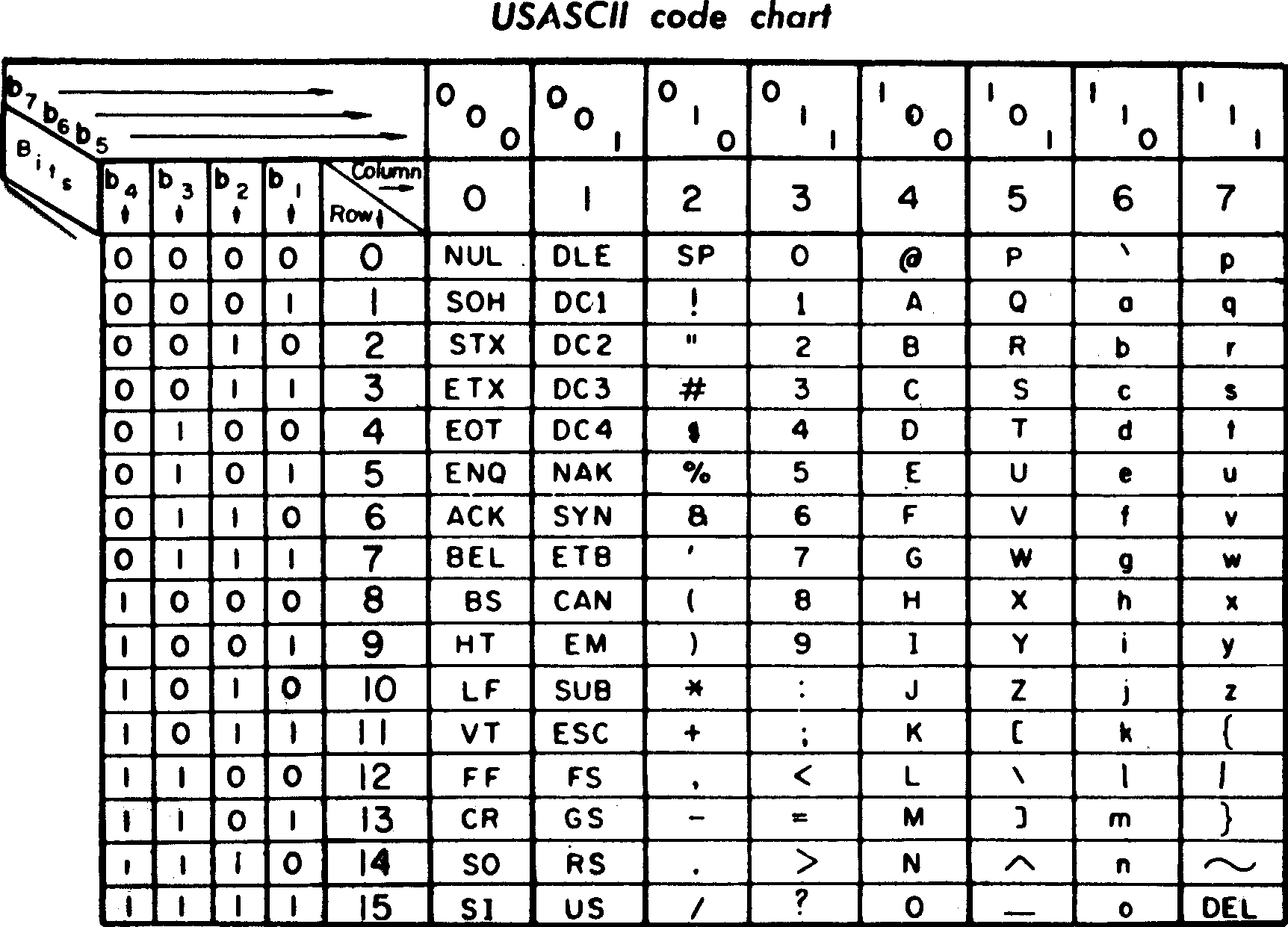 ASCII |
 유니코드 |
문자열 인코딩 종류
1. 아스키 코드 : 1바이트로 128개의 문자 표현
2. EUC-KR
- 옛날에 한글과 영어만을 표현하기 위한 한국만의 인코딩 방식, 2바이트
3. UTF-8
- 여러 언어를 모은 유니코드의 인코딩 방식 중 하나로 1바이트로 인코딩. 문자에 다라 1 ~ 6바이트까지 사용
- 가장 많이 쓰는 방식, 아스키 코드와 호환, 윈도우, 자바, 임베디드 외 대부분 환경에서의 표준(+Json)
4. UTF-16
- 2바이트로 인코딩 -> 유니코드 값이 커 2바이트로 부족하면 4바이트 사용.
- 자바와 윈도우에서 주로 사용
 UTF-8 규칙 - 1바이트만으로 충분한 경우(영어) : 0xxxxxxx(0으로 시작) ex) 영어 A는 유니코드 0x0041 -> 0x41 한바이트로 표현 - 2바이트가 필요한 경우 : (1) 110x xxxx (2) 10xx xxxx ex) 파이는 유니코드 0x3C = 0000 0011(3) 1100 0000(C) -> 위 규칙으로 표현하면 110/0 1111(0xCF), 1000 0000(0x80) - 3 바이트가 필요한 경우 한글 : (1) 1110 xxxx (2, 3) 10xx xxxxex) '한'은 유니코드 0xD55C = 1101 0101(D5) 0101 1100(5C) -> 1100/ 1101(0xED), 10/01 0101(0x95), 10/01 1100(0x9C) |
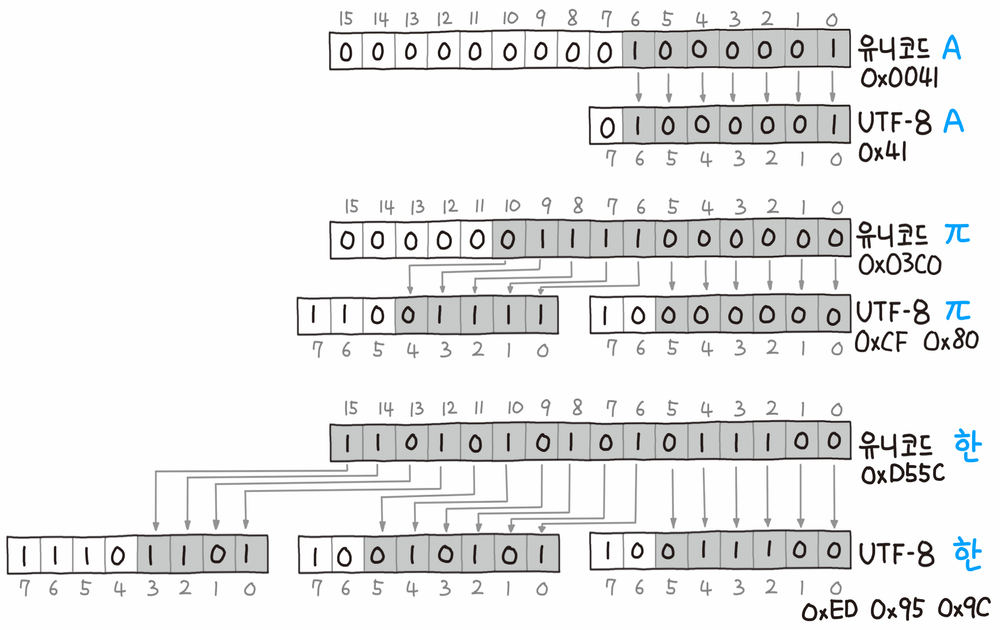 유니코드를 UTF-8로 인코딩 예시 - 좌측에 A, 파이, 한의 유니코드 값에 따라 UTF-8로 3바이트까지 사용해서 인코딩한 예시 내용 정리 |
2. 시간, 식별자, 해시
컴퓨터 시간 종류
- 타임 스탬프 : 1970년 1월 1일 0시 0분 0초부터 1초 단위(.밀리초)로 증가해서 정수 형태로 나타내는 시간
- 단조 시간 : OS 시작햇을때 기준으로 시간
- 실제 시간 : 시간 서버로 얻어 동기화 한 시간

범용고유 식별자 UUID Universial Unique IDentifier
- 같은 세션, 같은 사용자를 넘어서 가장 크게 구분하기 위한 식별자
- 형태 : 16진수 32개(8-4-4-4-12) 4 x 32 = 128비트 = 16바이트 크기 -> xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx
해시 함수
1. 특징 : 어떤 종류든 간에 입력된 값을 고정 길이 해시 값으로 변환, 동일한 입력 = 동일한 해시, 해시로 입력 복원 불가
2. 용도
- 암호 검증 : 서버에서 암호 대신 해시 저장 -> 입력한 비번의 해시가 저장된 해시와 같으면 ok(비번 저장필요 x)
- 데이터 변조여부 검증 : 데이터 변조시 해시 값이 변경됨.
ex) 파일 전송 시 파일과 해시값을 같이 보냄. 해시 함수에 전송된 파일을 넣어 얻은 해시값과, 전달받은 해시값이 다르면 파일 전송 오류/변조
3. 종류
- MD 5 : 초기 해시 알고리즘, 적은 연산량, 충돌/동일한 해시값이 나오기 쉬움
- SHA-1 Secured Hash Algorithm-1 : 200TB까지 입력 가능, 20바이트 해시 생성, md5보다 많은 연산량+적은 충돌가능성
- SHA-2 : SHA-224/256/512 등 통틀어서 부르는 명칭. SHA-1보다 연산량 많으나 안전
3. 데이터 규격
JSON
- {}와 키, 값으로 구성된 데이터 구조, UTF-8 문자열 인코딩 사용, 주석 지원 x
- 장점 : 읽기 쉽다.
- 단점 : 텍스트로 이뤄저 크다, JSON 파일의 형태(버전)이 바뀐경우 전체(서버, 클라이언트 등) 바꿔줘야함.
YAML Yet Another Markup Language
- json과 비슷 + UTF-8/16 + 앵커, 별칭 이용
XML eXtensible Markup Language
- 여러 목적의 마크업 언어를 만들기 위한 마크업 언어 = 다양한 형태의 데이터 구조를 만드는 마크업 언어
- 일찍만들어짐, 많이 씀, MS 워드 파일 등은 XML 파일 형태, 다양한 인코딩 지원, 읽기 쉬우나 많은 데이터 필요
 xml |
 json |
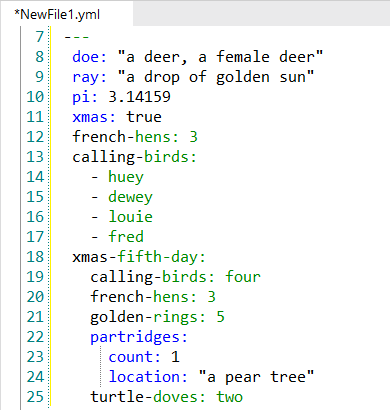 yaml |
프로토콜 버퍼 Protoco Buffer = Protobuf)
- 구조화된 데이터(구조를 가진 텍스트)를 데이터 직렬화(바이너리)하는 구글이만든 오프소스
- 장단점 : 크기가 줄어 통신, 저장 시 사용 <-> 알아보기 힘듬 = 유지보수 힘들다
- 프로토콜 버퍼 사용법
1. 스키마 파일(데이터 규격) 정의(.proto) : 직렬화(바이너리) 형태 정의
2. 컴파일러(protoc)로 컴파일 : 인터페이스 코드 생성
3. 인터페이스 코드 임포트
4. 인코더 - 디코드
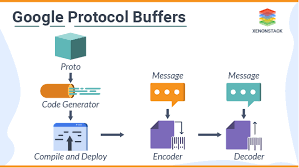 protobuf 사용법 |
 protobuf 스키마 파일, 데이터 예시 |
base64
- 바이너리를 아스키 문자열로 대치한 인코딩
- 방식 : 바이너리를 24비트(3바이트)로 나눔(바이트가 남을때 패딩 '='(=0) 추가)-> 6비트로나눔 -> 0 ~63개(64개)문자 표현
- 장단점 : 바이너리를 문자열로 취급(=이미지, 음성 등 바이너리를 문자로 표현) <-> 데이터가 길어진다
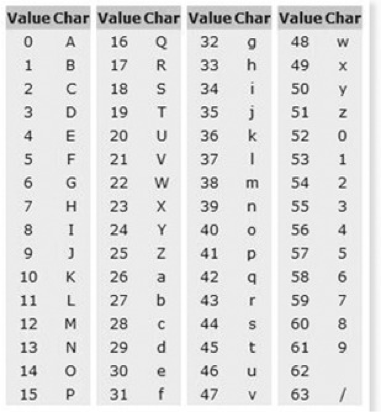 base64 인코딩 테이블 |
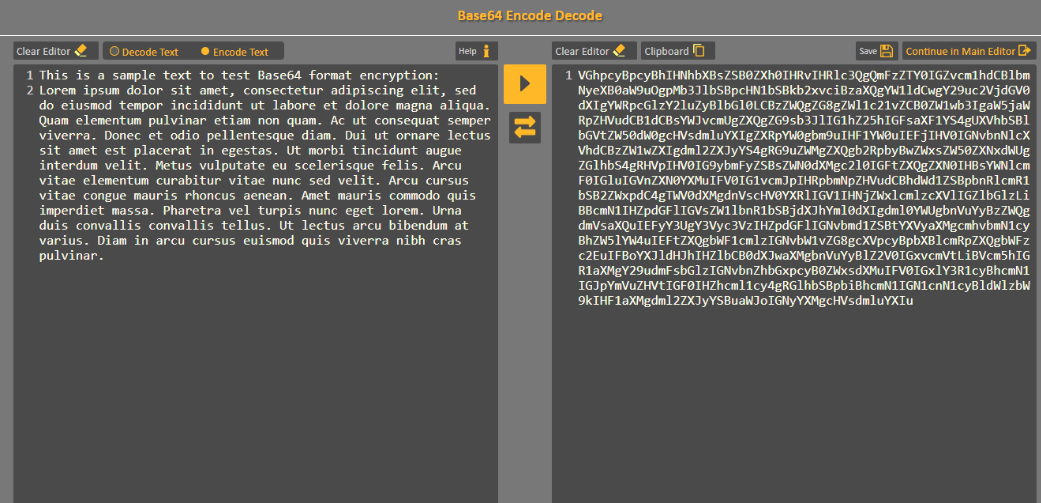 text를 base64인코딩 |
4. 프로세서 관련
가상 메모리
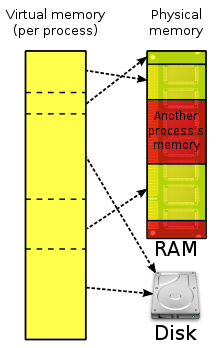
- 2차 메모리(HDD, SSD)를 이용하여 각 프로세서가 4GB의 가상의 메모리 공간(주소)을 가지고 프로그램 실행.
- 각 가상메모리는 코드, 데이터(전역 변수), 힙(동적 할당), 스택(함수 호출, 지역 변수) 영역을 가짐.
- 장점 ; 모든 프로세스는 4GB나 되는 공간을 갖는다, 프로세스 간에 침범 방지
- 원리
1. 가상 주소가 크므로 주소를 4kb의 고정 크기 덩어리 페이지로 분할
2. 메모리 관리 장치 MMU 혹은 페이지 테이블로 가상 주소를 물리 주소로 변환
=> MMU나 페이지 테이블이 알아서 가상 주소를 물리 주소려 변환해주니 신경 쓸필요 없음
명령어 파이프라인
- 비 파이프라인 : 명령어 사이클(읽기, 해석, 실행, 기록)이 다 끝나면 다음 명령 처리
- 명령어 파이프라인 : 작업이 넘어가면 새로운 명령어를 받아 수행하는 방식. 아래 그림의 경우 최대 4명령이 동시 실행
- 슈퍼스칼라 파이프라인 구조 : 파이프라인을 여러개 두어 여러 명령어를 동시에 처리
- 비순차 프로세서 파이프라인 : 파이프라인에서 순차적으로 처리하면 대기해야하는 경우 발생, 스케줄링을 추가하여 비순차적으로 처리하여 고속화. 명령어 인출 -> 해독 -> 리네임(가짜 의존성 제거를 위한 레지스터 이름 변경) -> 이슈(할당) -> 스케쥴링 -> 실행
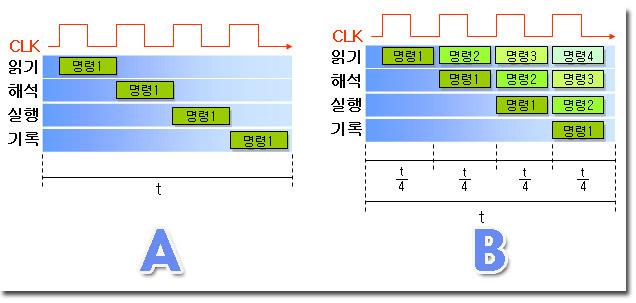 비파이프라인 A, 파이프라인 B |
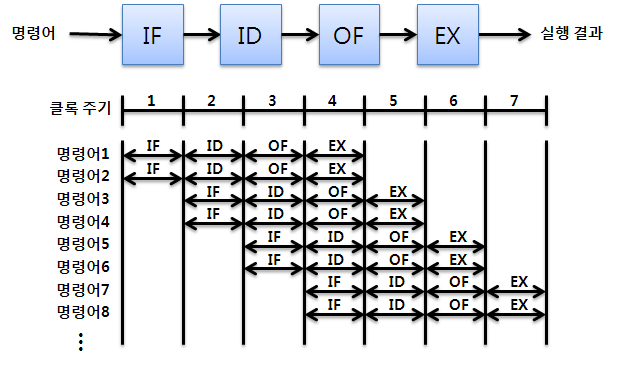 슈퍼스칼라 파이프라인 |
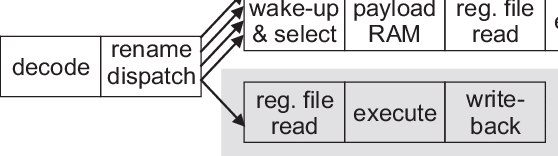 비순차 프로세서 파이프라인 |
|
하이퍼 스레딩
- 하나의 HW가 두개의 컨텍스트 유지(프로세서가 2개처럼 보인다)
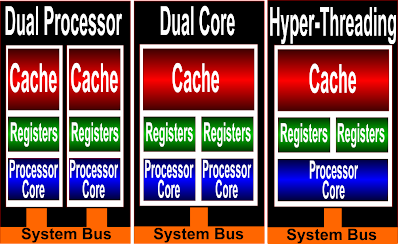
병렬 컴퓨터
- 프로세서를 모아, 협력해서 계산
- 구조
1. SISD(single instruction single data) : 하나의 명령어가 하나의 데이터만 갖고 계산, 스칼라/슈퍼스칼라 프로세서
2. SIMD(single instruction multiple data) : 하나의 명령어가 여러 데이터갖고 계산(벡터 연산), MMX, SSE
3. MISD(multiple instruction single data) : 데이터 하나 명령어 여러개
4. MIMD(multiple instruction multiple data) ; 여러 명령어로 여러 데이터 처리, 일반적인 멀티 프로세서 -공유/분산 메모리
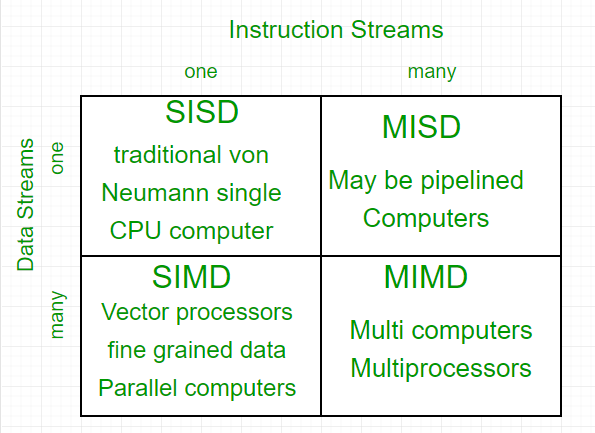 병렬 컴퓨터 구조 비교 |
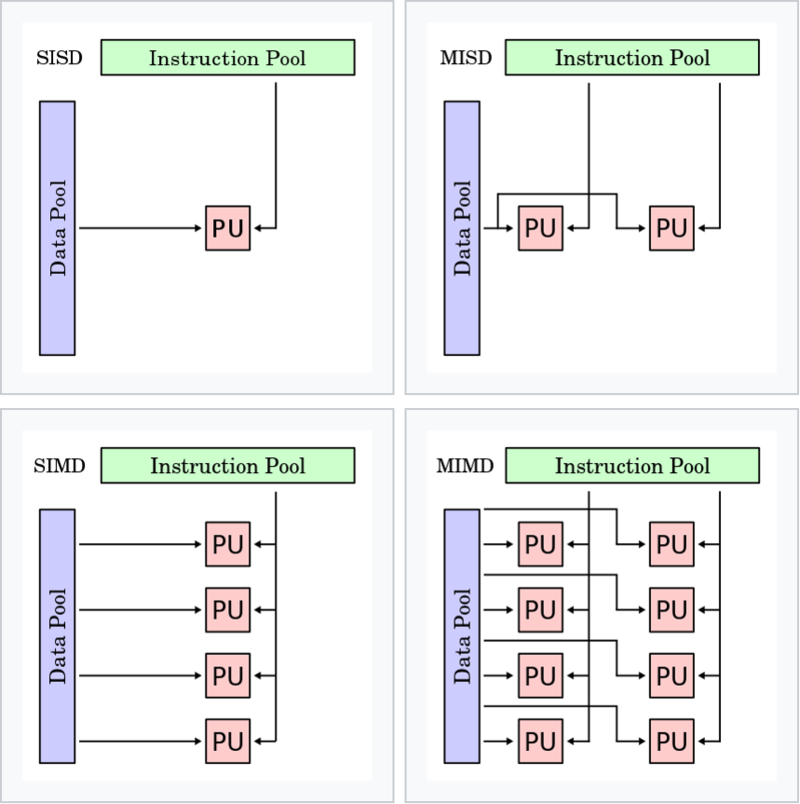 병렬 컴퓨터 구조 형태 |
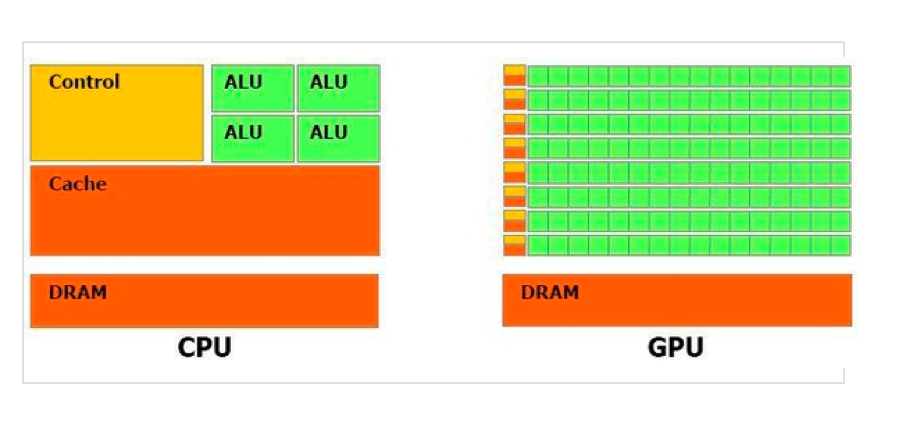
- GPU : 병렬 프로세서, 비순차 처리가 많지만 ALU가 적은 CPU와 달리 훨씬 많은 ALU와 큰 메모리 대역폭 가짐
'요약' 카테고리의 다른 글
| 미분방정식으로 현실을 어떻게 수학 모델로 만들까 2 -비동차미방풀기 (0) | 2023.09.20 |
|---|---|
| 미분방정식으로 현실을 어떻게 수학 모델로 만들까 1 - 간단미방종류 (0) | 2023.09.20 |
| 네트워크 간단 요약 (0) | 2022.05.29 |
| 로봇 공학 요약 - 로봇 종류부터 구성 요소, 구동기, 센서까지 (0) | 2022.05.05 |