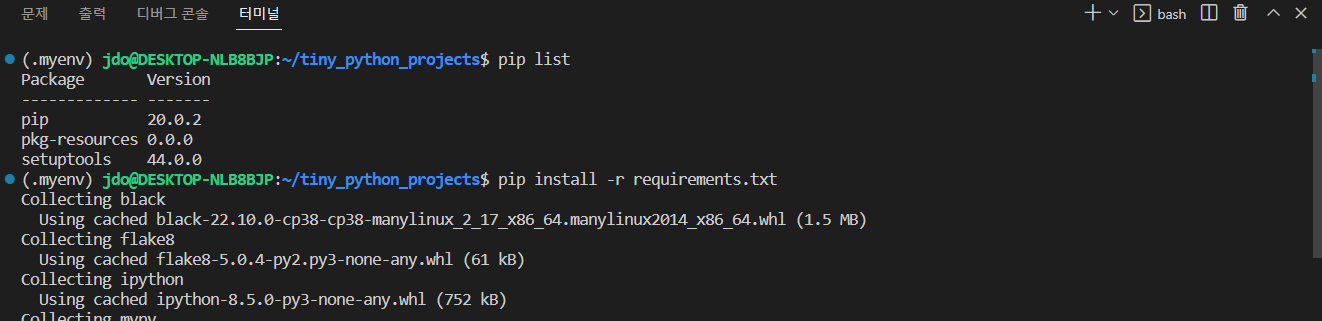
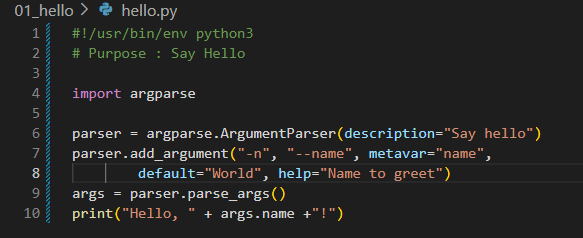
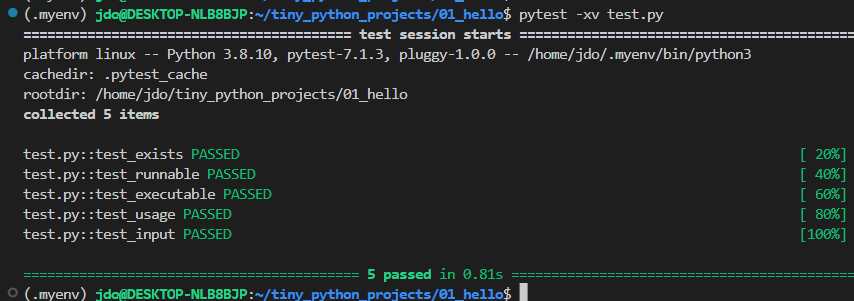
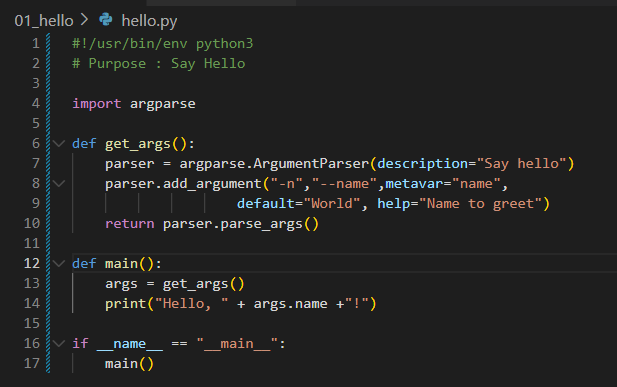
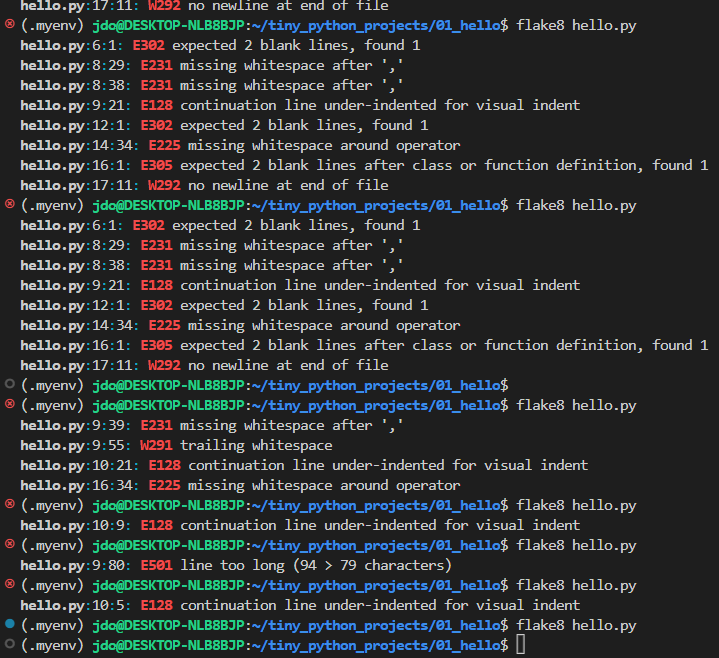
그래프
가장 구현하거나 이해하기 막막한 자료구조인데
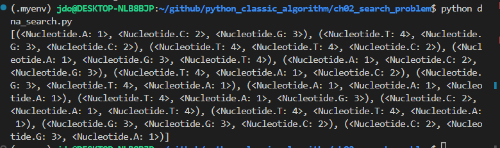
각 노드를 정점 vertex
노드간 연결을 에지라고 하는데
이번에는 미국 지도를 그래프로 만들어서 다뤄보자.
그래프를 파이썬으로 처리하기 위해서
그래프 프레임워크부터 만들면..
일단 그래프는 에지에 가중치가 있거나 없는경우, 방향이 있거나 없는 경우가 있는데
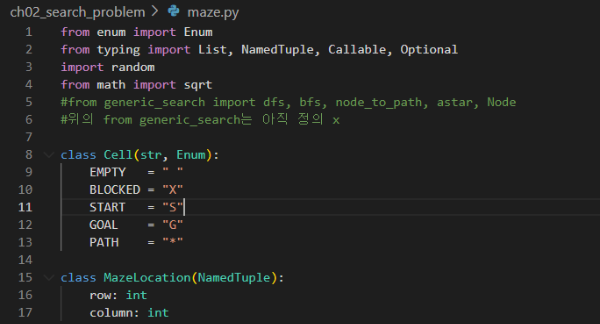
일단 가중치가 없는 무향 그래프부터 만들자.
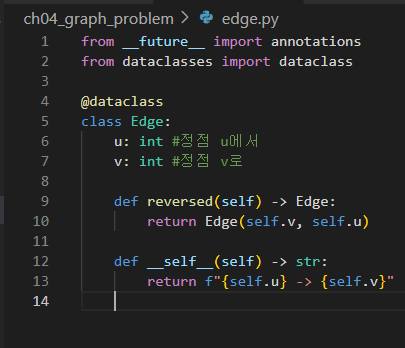
에지 구현하기
우선 가중치 없는 에지부터 구현
@dataclass는 타입힌트랑 같이 파이썬 3.7에 추가된 기능인데 이 데커레이터를 쓰면 아래의 코드 기준
아래의 초기화 구문을 자동으로 생성해준다고 보면 되나보다. 편해지긴 편해졌다.
class Edge:
def __init__(self, u: int, v: int):
self.u: int = u
self.v: int = v그런데 코드보면 f"{self.u} -> {self.v}"가 있는데
문자열에 변수를 집어넣을때 앞에 f붙이고 넣을 변수를 {}로 감싸주면 되나보다.
잠깐보니 이걸 f-string이라고 하는거같다.
https://www.daleseo.com/python-f-strings/
파이썬의 f-string 사용법
Engineering Blog by Dale Seo
www.daleseo.com
무가중 에지를 만들었으니
이번에는 무가중 그래프를 만들자.
그래프 구현
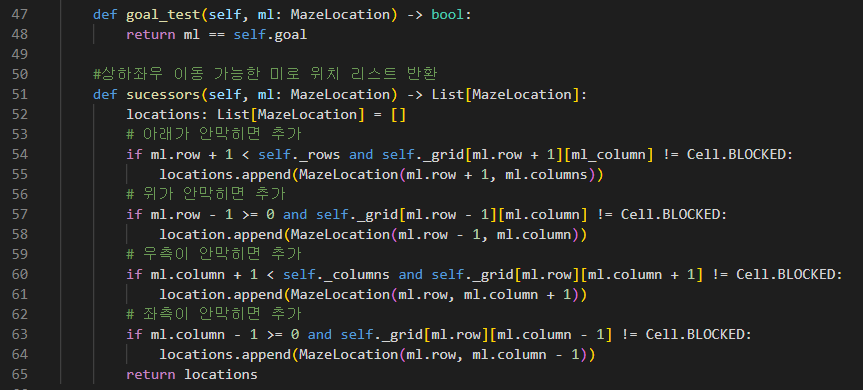
그래프를 만들땐 정점들의 리스트를 받고,
그래프 자료구조를 만들땐 정점 행렬 혹은 인접 리스트를 쓰는데 여기서는 인접 리스트를 사용해서 만드는거같다.
https://sarah950716.tistory.com/12
[그래프] 인접 행렬과 인접 리스트
그래프 관련 문제를 풀 때는, 문제 상황을 그래프로 모델링한 후에 푸는 것이 보편적입니다. 이 때, 모델링한 그래프의 연결관계를 나타내는 두 가지 방식이 있습니다. 1. 인접 행렬 2. 인접 리스
sarah950716.tistory.com
나머지 부분은 좀 긴데
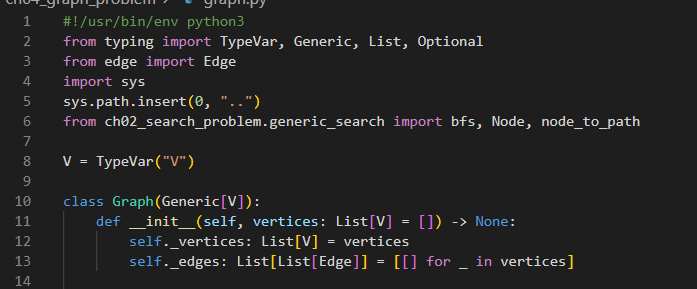
vertex_count야 이름 그대로 정점 개수 반환해주고.
edge_count는 edge 수를
add_vertex는 새 정점을 버택스 리스트에 추가하고, 에지에는 빈 리스트 추가. 반환값은 추가된 정점 인덱스
add_edge는 이해하기 좀 햇갈리개 생겼는데 edge.u 와 .v가 정점의 인덱스니 해당 정점 리스트에서 에지를 append 시킨단소리 같다.
add_edge_by_indices는 정점의 인덱스로 에지 추가를
add_edge_by_vertices()는 정점인덱스가 아니라 정점 자체로 인덱스를 찾아 에지 추가
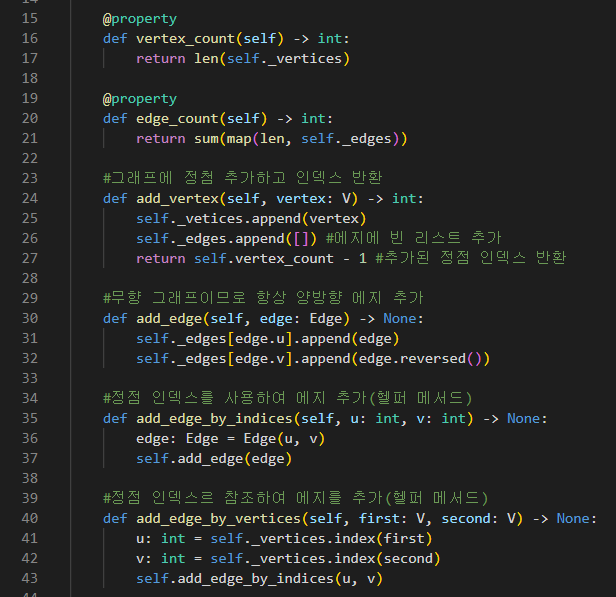
vertex_at은 정점의 인덱스로 정점 가져오기.
index_of야 정점을 줘서 그 정점의 인덱스 가져오기
neighbors_for_index는 정점의 인덱스를 줬을때 _edges[index]로 에지들의 e.v 즉, 정점 인덱스 가져오고 그걸 vertex_at으로 정점을 가져와 리스트로 만들어버린다. index 인근 정점 리스트 반환
neighbors for vertex는 버텍스로 인덱스를 구해서 위 함수에 대입
edges for index는 해당 정점 인덱스의 에지들을
edges for vertex는 정점의 인덱스를 얻어서 위 함수에 대입.
__str__은 정점 수만큼 루프를 돌면서 "정점값 - 해당 정점 인근리스트 \n" 한 것을 반환.

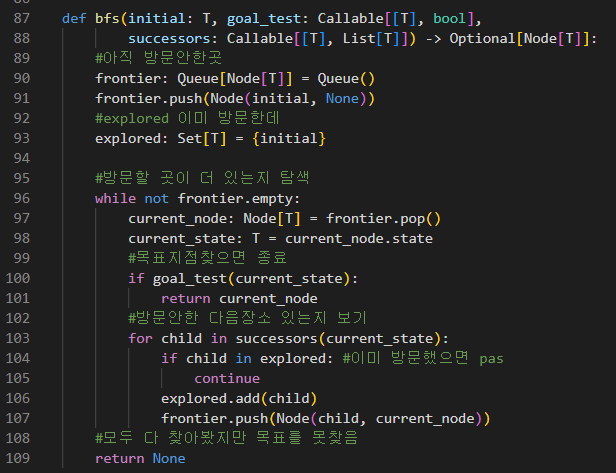
bfs로 경로탐색
가중치 없는 그래프 구조를 잡았고,
이걸 이전에 구현한 너비 우선 탐색을 쓸수 있는데
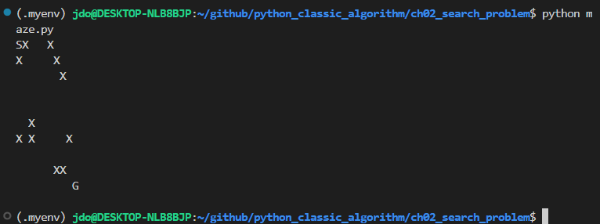
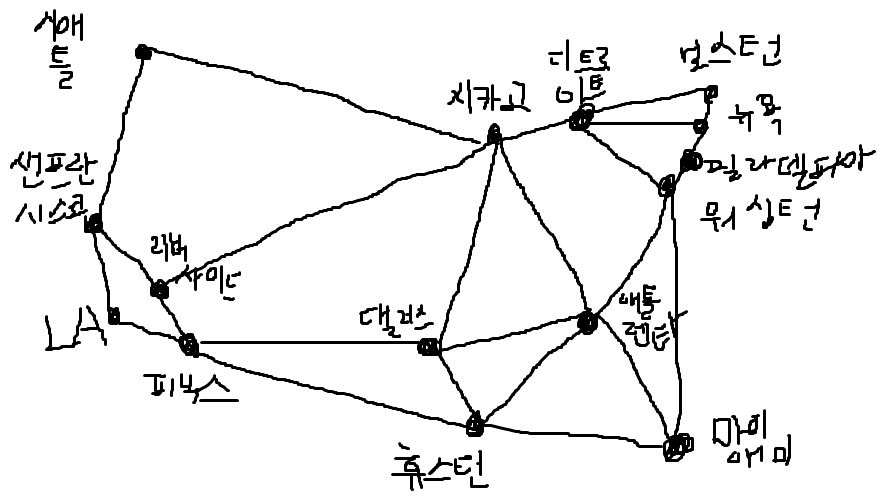
미국 대도시 그래프를 만들고 돌려보자.


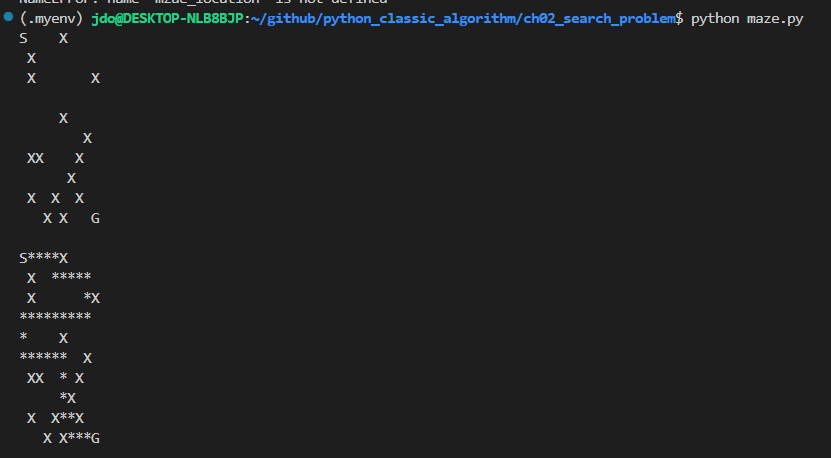
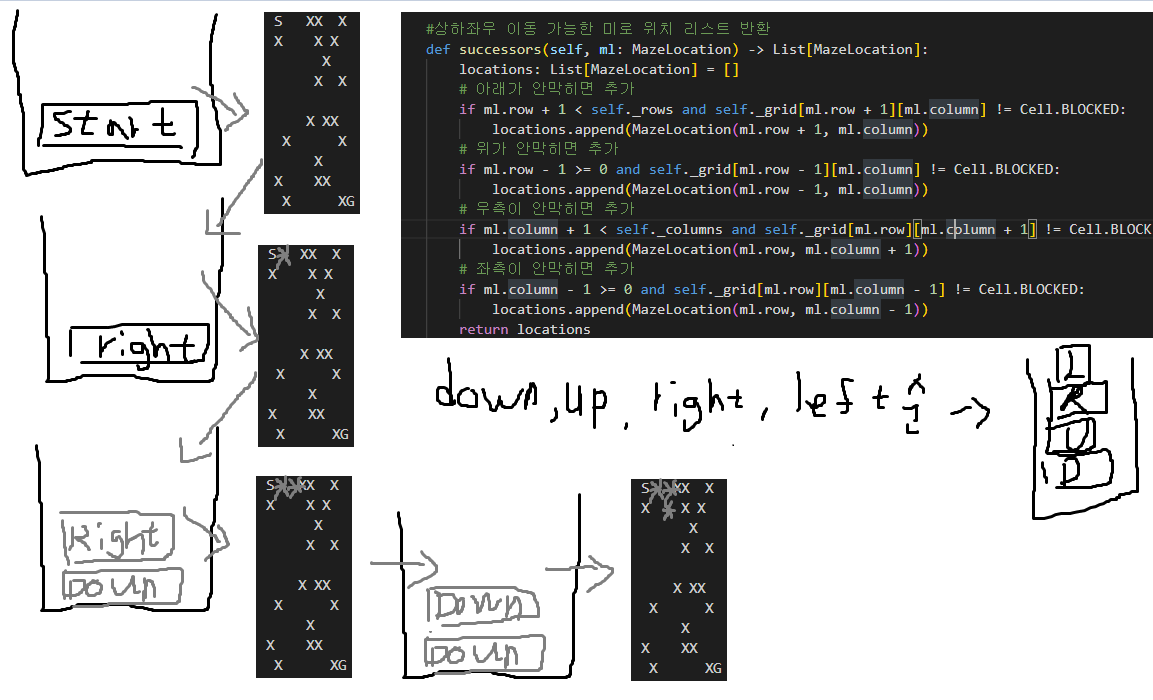
보스턴에서 마이애미까지 bfs로 찾은 경로는 보스턴-디트로이트-워싱턴-마이애미가 된다.

왜 이렇게 될까..
지역이 많아서 그리기는 싫은데..
엉성하게 그려서 보니 경로는 대강 맞는거같다.
가중화된 에지 구현
위 bfs에서는 무가중치 그러니 거리는 고려없이 정점의 개수만으로 경로를 찾았는데
실제는 거리, 가중치를 고려할수 있도록 가중화된 그래프를 만들어야 한다.
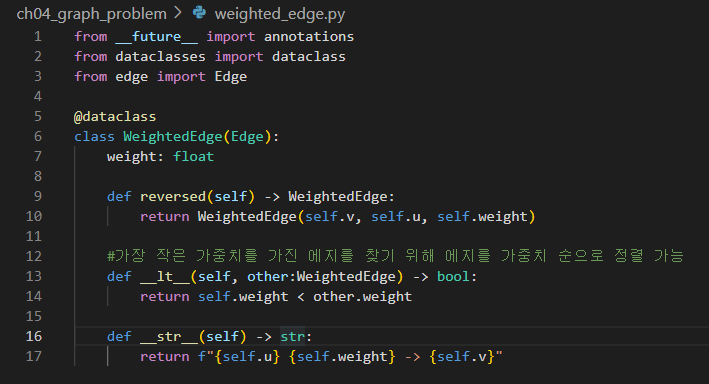
가중화 에지는
기존의 에지를 상속받고, weight 추가. 비교할수 있게 lt도 구현.
가중화 된 그래프 구현
기본적으로 그래프 상속받고
에드 에지 바이 인덱시스와 버텍시스는 기존 그래프 함수를 오버라이드 시켰고,
네이버스 포 인덱스 위드 웨이트는 [(가중화된 에지, 가중치)] 리스트를 반환해준다.
__str__이야 그래프랑 큰 차이없고.
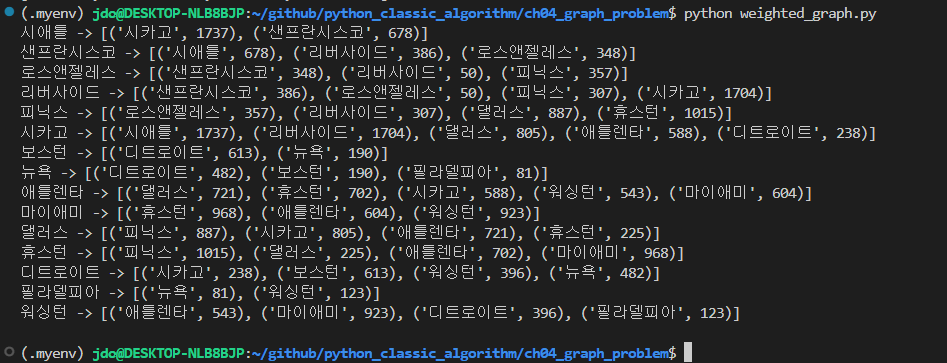
한번 미국 대도시 그래프에 가중치(거리)를 넣어서 출력하면
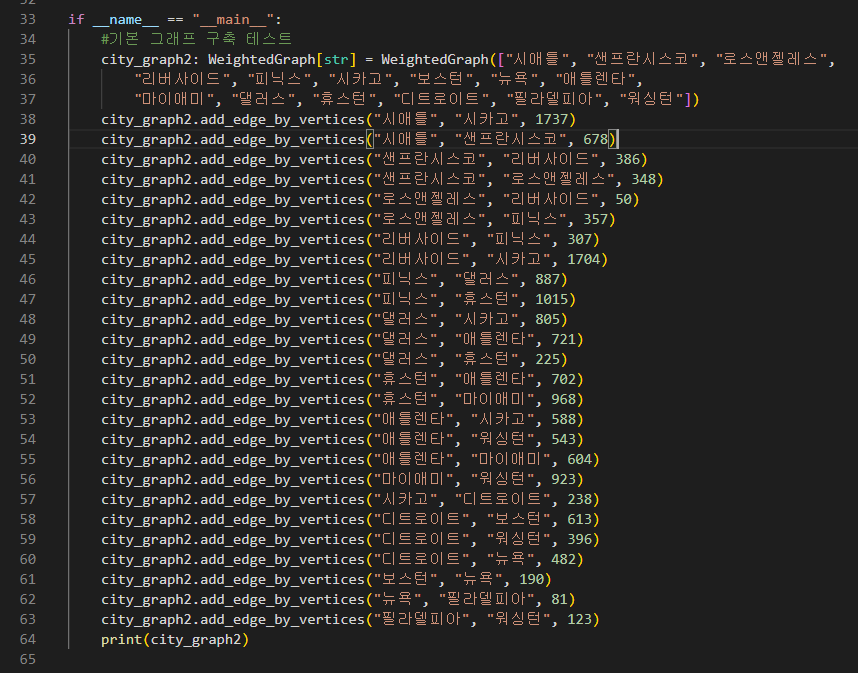
시애틀은 시카고까지 1737, 샌프란시스코까진 678 이면서
다른 지역들도 블라블라 나온다.
최소 신장트리 구하기
트리는 정점 사이 경로가 하나뿐인 그래프(사이클이 없다)인데,
신장 트리 spanning tree는 모든 정점을 연결하는 트리이고
최소 신장 트리 minimum spanning tree는 가중치 그래프 모든 정점을 가장 짝게 최소 비용으로 연결한 신장 트리가 된다.
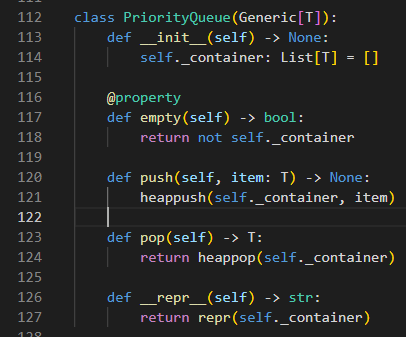
최소 신장 트리를 만들기 위해서 프림 알고리즘을 쓰는데 우선순위 큐이 필요하니 구현하자.

그리고 가중치를 가진 에지들의 모임 가중화된 경로는 모든 에지 가중치를 단순 합하면 되니 이렇게 구현하면 되고..

mst를 구하기 위한 프림 알고리즘은 다음의 순서로 동작된다고 한다.
1. mst에 포함할 정점 선정
2. mst에 포함되지 않은 정점 중 가중치 가장 에지 낮은거 찾아 mst 추가
3. 모든 정점으로 mst를 만들때까지 2 반복.
mst 함수 내용을 보면
가중화된 그래프와 시작 정점 인덱스를 줘서 가중화된 경로를 반환하는 내용인데
처음 조건문에서 시작 인덱스가 음수거나 너무 크다. 즉 없는 거면 None 반환.
15-17내용은 처음 가중화된 경로와, 우선순위 큐, 정점 방문 여부 리스트 초기화
내부에 visit 함수가 있는데 정점 인덱스를 받아 방문했다고 True 표시하고.
해당 정점 주위 에지들을 받아 방문하지 않은곳을 골라 우선순위 큐에 집어넣는 형태로 정의되었다.
그 뒤의 루틴이야 스타트 인덱스로 비짓 함수 시작.
우선순위 큐가 텅빌때까지 계속 루프를 돈다.
우선순위가 가장 높은? 에지를 꺼내고 heappop은 가장 작은 원소 꺼낸다고 한다.
불리언 리스트인 visited[edge.v]로 해당 정점 방문했는지도 체크.
방문한데가 아니면 가중화된경로 리스트에 추가.
우선순위 큐에서 우선순위 고려해서 꺼낸거니 바로 그 정점에서 비짓 함수 반복.

이 가중화된 경로를 출력할수 있는 함수도 구현하고

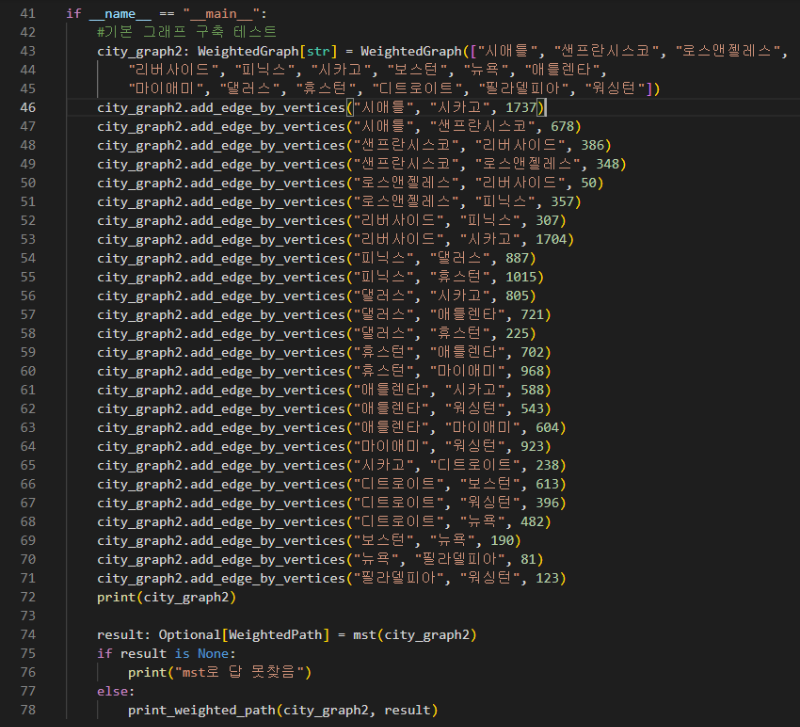
mst에 시작 정점 인덱스를 따로 안줘서 기본값 0(시애틀)에서 출발한 결과 아래의 경로로 mst가 만들어졌다.
왜이렇게 되었을까
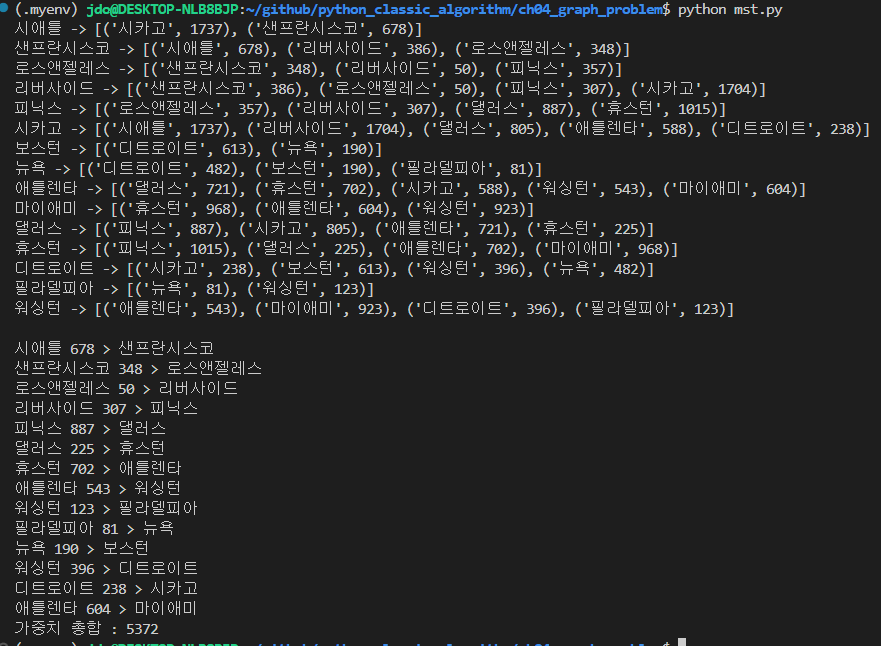
결국 그래프를 그렸는데 여기서 다시보면.

대강 맞게 간거 같다. 근대 마지막 애틀렌타-마이애미는 잘못된거같은데..? 그냥 pass
다익스트라 알고리즘으로 길찾기
다익스트라 알고리즘도 최단경로 찾는데 쓰이는 알고리즘으로 최소 가중치 경로를 반환받는데
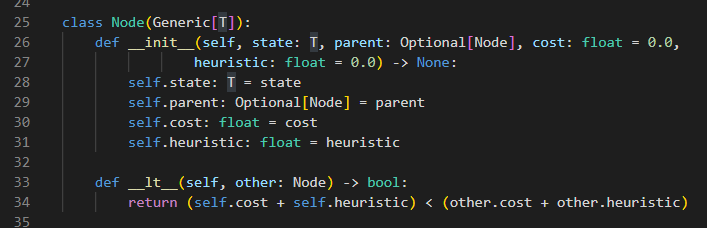
다익스트라 노드를 사용한다. 이 노드는 정점 인덱스와 현재 위치까지의 거리(비용)을 가지며
이 비용으로 lt, eq 연산이 수행된다.

다익스트라 알고리즘 과정은
- 시작 정점을 우선순위 큐에다가 넣고
- 가장 가까운 접점(현재 정점)을 팝, 그리고 연결된 모든 이웃 정점을 확인하여 방문하지 않았거나 한 에지가 최단경로시 시작점에서 그 정점까지의 거리와 에지를 기록하고 그 최단거리 방향 정점을 우선순위 큐에 추가
- 위 과정을 계속 반복하여 시작점에서 다른 모든 정점까지 최단거리 반환.
이라는데 일단 코드를 봐야알거같다.
구현한 다익스트라 함수는 가중화 그래프와 정점 루트를 받아서 (거리 리스트, 딕트(정점, 에지)) 튜플을 반환받는데
처음에는 루트 인덱스를 first에다 담고, 모든 정점들 거리 리스트 distances 초기화, 루트에서의 거리는 0
경로 딕트와 다익스트라 노드를 담는 우선순위 큐를 만들어 첫 정점에 대한 다익스트라 노드(인덱스와 거리 0) 푸시
우선순위 큐가 텅빌떄까지 반복
u에다간 노드 정점 인덱스를, dist_ut에는 거리 담고
정점 인덱스로 인근 에지 가져와 루프
해당 에지 정점 거리를 가져와 dist_v에 담긴한데
이전 거리 dist_v가 없거나 최단거리( dist_u 현재까지 거리 + we.weight 에지 거리가 dist_v 보다 작다면)있으면
새로 구한 거리로 덮어씌우고 distances[we.v]
이 에지로 경로 딕트 갱신 path_dict[we.v] = we
짧은 경로 정점에 대한 다익스트라 노드를 만들어 우선순위 큐에 추가.
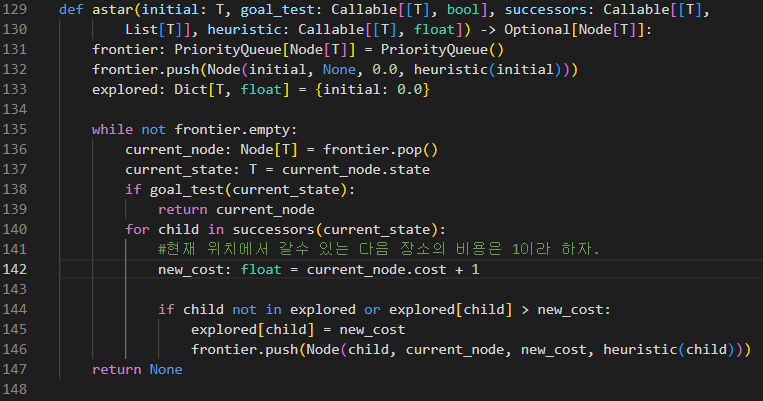
지금까지 내용보면 astar에서 휴리스틱 함수가 빠진게 차이인거같다.

일단 실행하기전에 필요한 함수 구현하고
다음 코드를 실행하면..

시작점을 로스앤잴래스로 했을때
모든 정점에 대한 거리와
LA에서 보스턴까지 최단경로가 나온다.
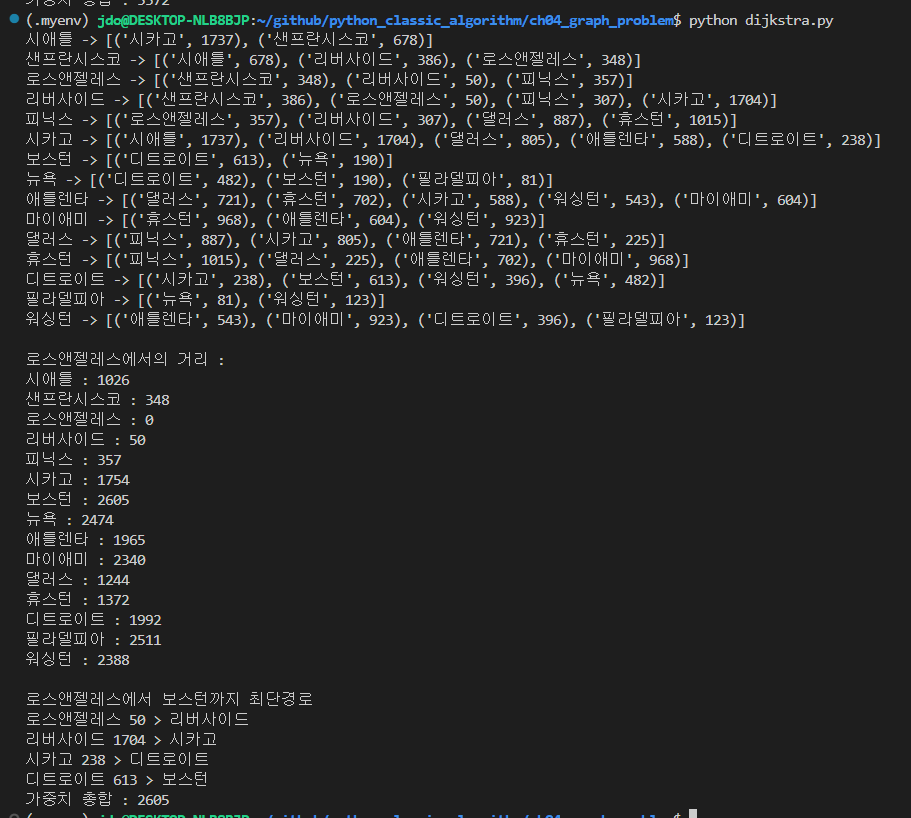
우선 디스턴스 어레이 투 버텍스 딕트를 보면.
가중화된 그래프와 거리 리스트를 받아서 딕셔너리(정점, 거리)를 반환하니
각 정점별 거리를 쉽게 구할수 있겠고.
패스 딕트 투 패스는
시작 정점 인덱스, 도착지 인덱스와 경로딕트(인덱스, 가중화된 에지)를 인자로 받아 가중화된 경로(에지 리스트)를 반환한다.ㅍ 근데 패스 딕트가 어떻게 만들어지는지 잘 이해가지는 않는데.
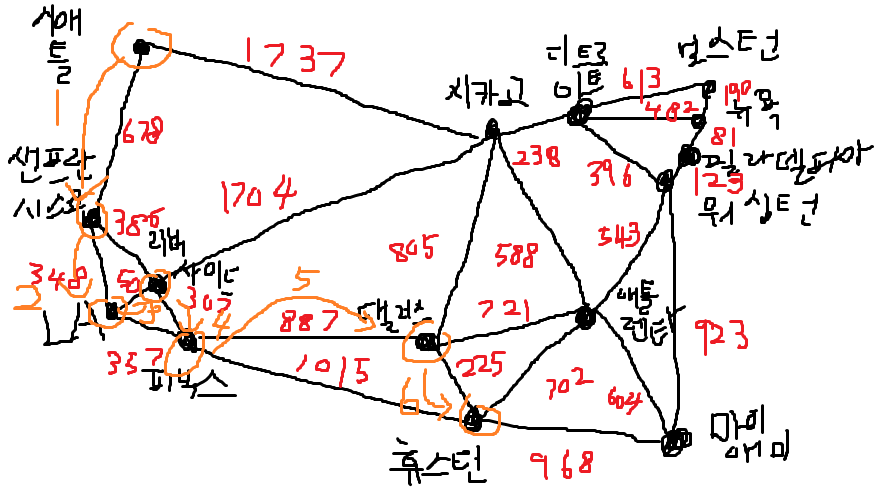
잠깐 LA에서 보스턴 가는 경로를 그림판으로 보면
LA 기준 샌프란, 리버사이드, 피닉스에 대해서 루프를 다돌긴하겠지만.
우선 리버가 가까우니 리버부터 보면 아래와 같이 넣을것이고,
pq에 리버에 대한 다익스트라 노드가 들어갔으니 이번엔 이걸 보겠다.
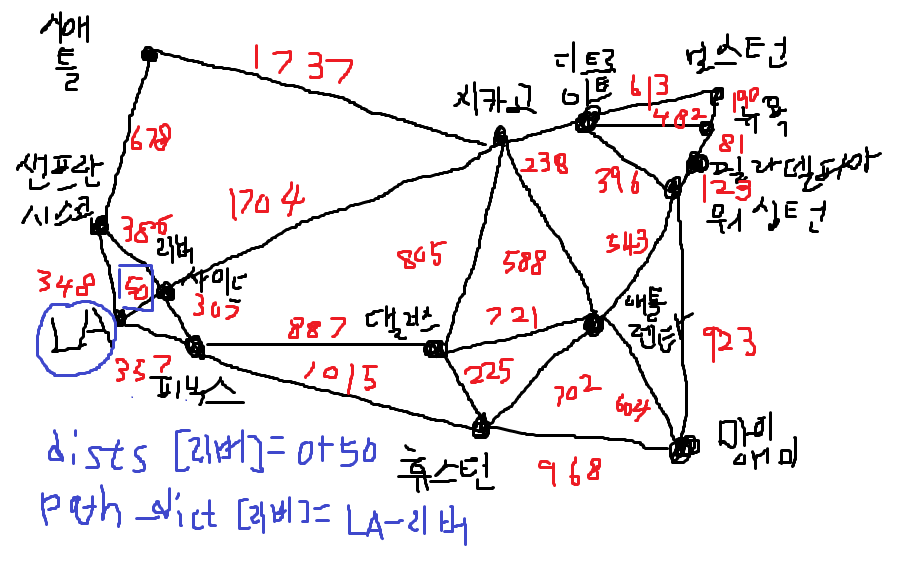
이번에는 리버에서 가장 가까운데가 피닉스인데 내가 원하는데서 좀 멀어지고 있다..
지금 이해된건데 다익스트라 알고리즘은 시작점에서 모든 정점까지 가장 가까운 거리를 찾는다는게 이소리구나.
LA-리버-피닉스나 LA-피닉스 거리가 동일하니 다른 얘로보자면
LA에서 시애틀 가는 경우 거꾸로 놓고보면
전자 : 시애틀-시카고-리버-LA보다
후자 : 시애틀-샌프란-LA가 거리가 가까우므로
dist[시애틀] = 전자가 dist[시애틀] = 후자로 덮어씌워지고
path_dict[시애틀] = 시애틀-시카고 가 아닌 path_dict[시애틀] = 시애틀-샌프란으로 갱신된다는 소린거 같다.
완전히 이해는 안되지만 대강 이런식으로 이전 거리와 경로를 덮어씌운다는게 이 의미로 보인다.

그래서 path_dict_to_path는
이미 시작점에 가장 가까운 경로로 path_dict가 만들어 져있으니
목적지에서 에지를 꺼내 리스트 만드는 과정이고,
경로가 거꾸로되어있으니 마지막에 리버스를 시켜주는거같다.
'컴퓨터과학' 카테고리의 다른 글
| jetson nano yahboom USB 부팅 삽질기 2(usb 부팅 완료, vnc까지) (0) | 2022.11.09 |
|---|---|
| jetson nano yahboom USB 부팅 삽질기 1(emmc 설치 완료) (0) | 2022.11.04 |
| python - 3. 선형/이진/깊이우선/너비우선 탐색, A* (0) | 2022.10.23 |
| python - 2. 재귀와 메모이제이션 피보나치, 비트스트링 압축, 하노이탑 (0) | 2022.10.21 |
| python - 1. hello world 힘들게 만들기(WSL, 파이썬 가상환경, argparse, 린터, 파이테스트) (0) | 2022.10.20 |