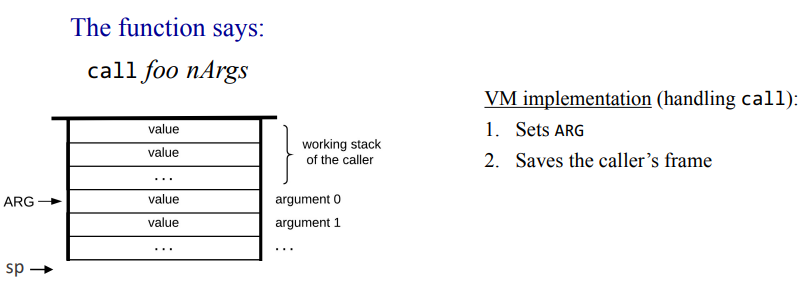
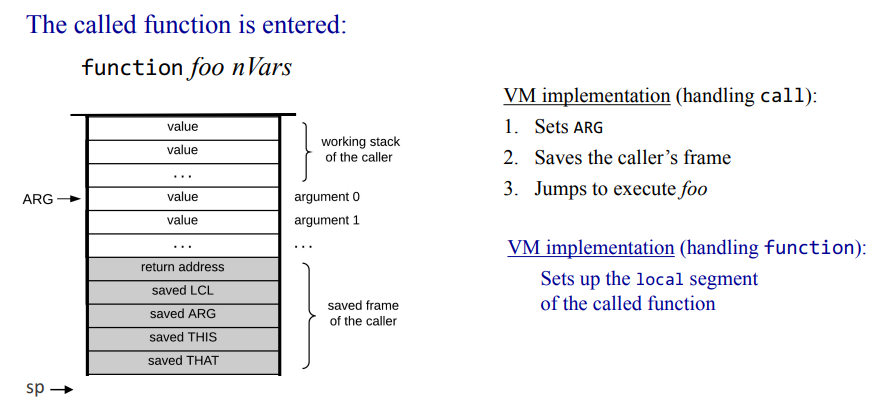
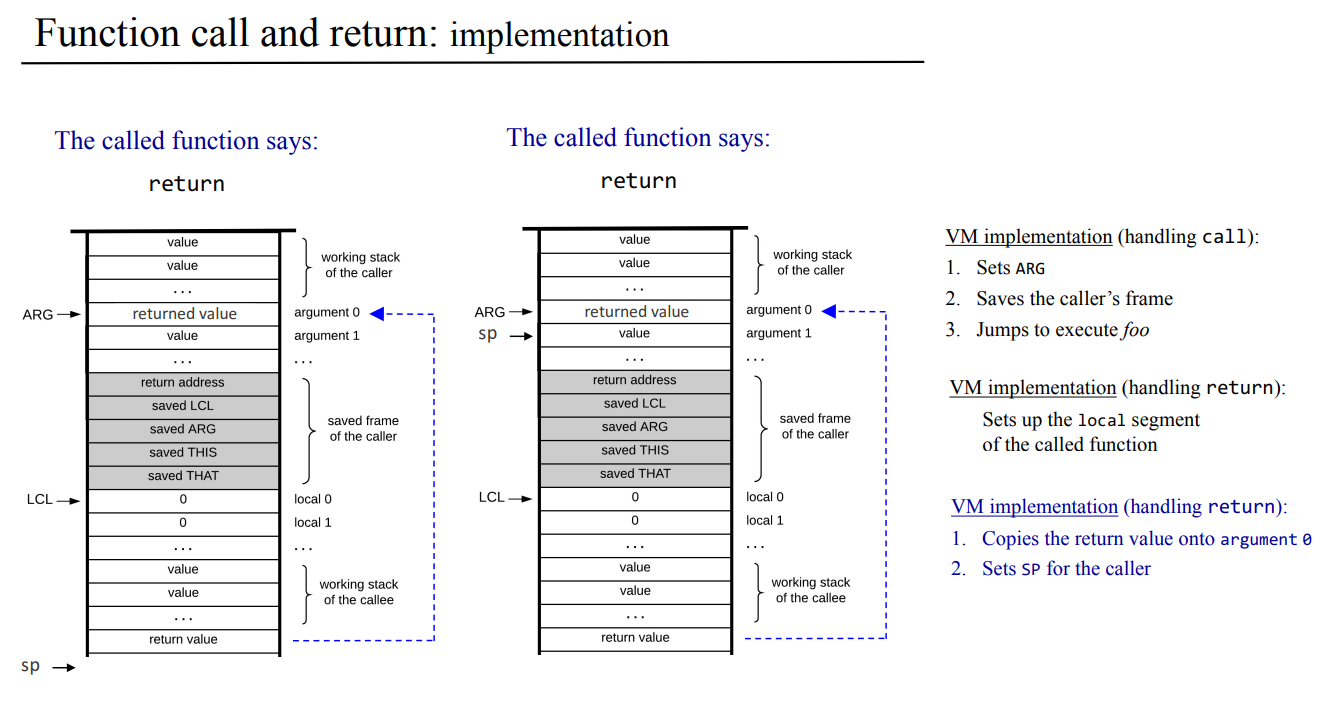
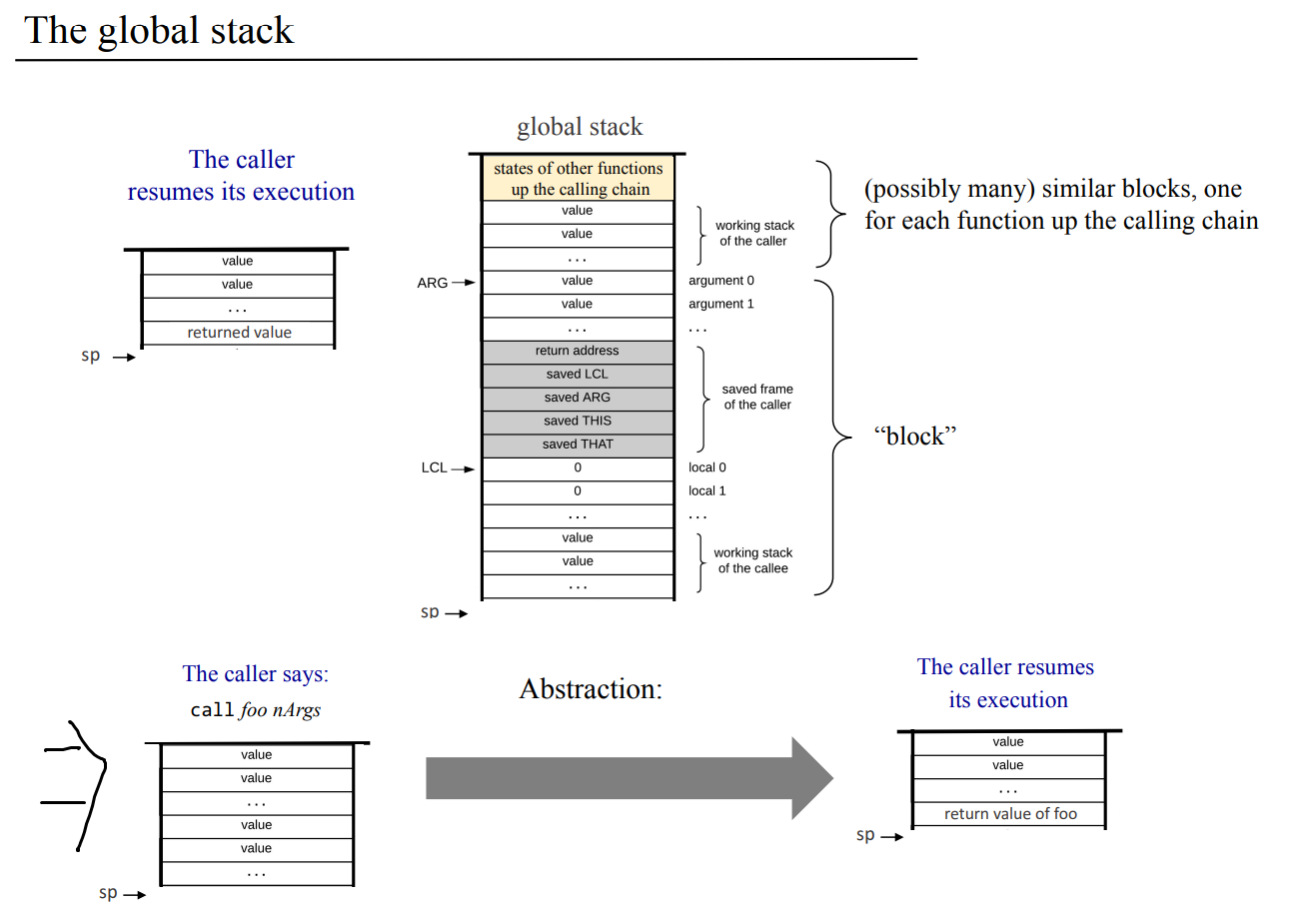
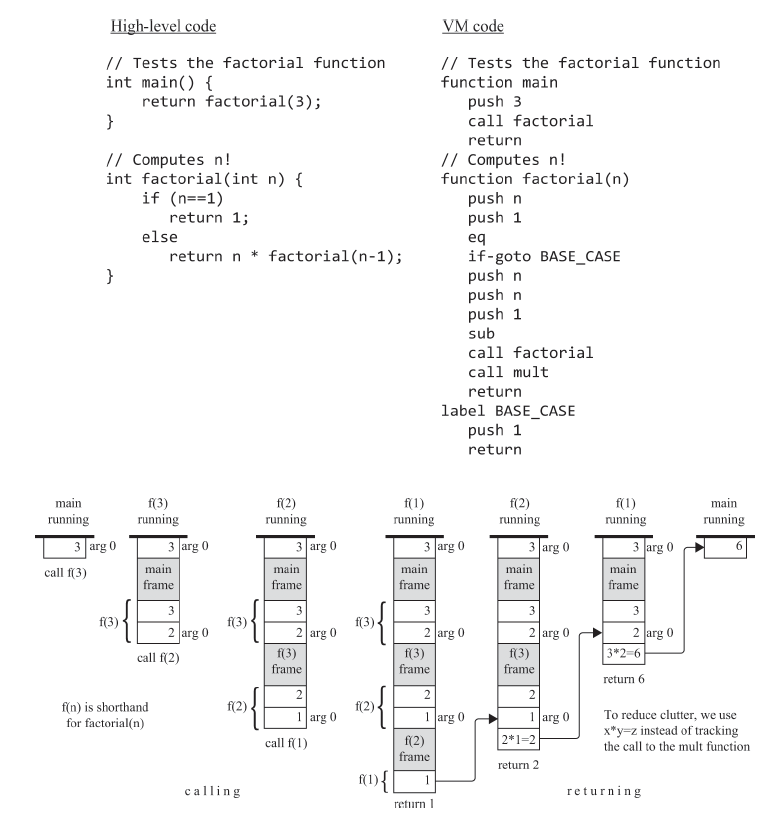
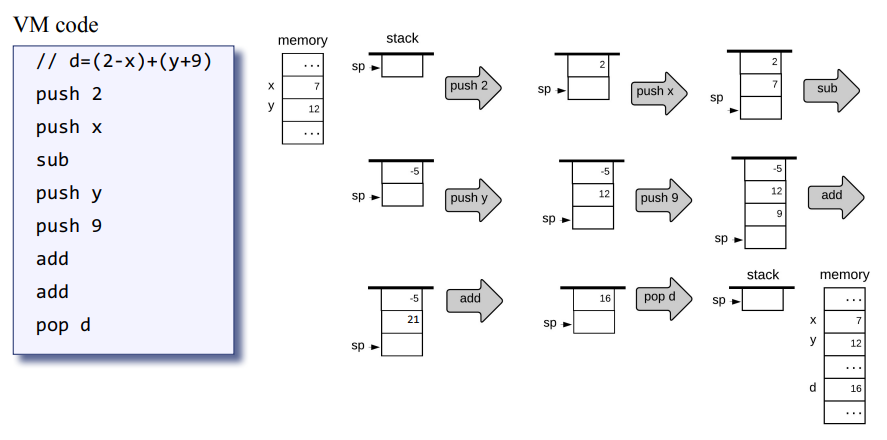
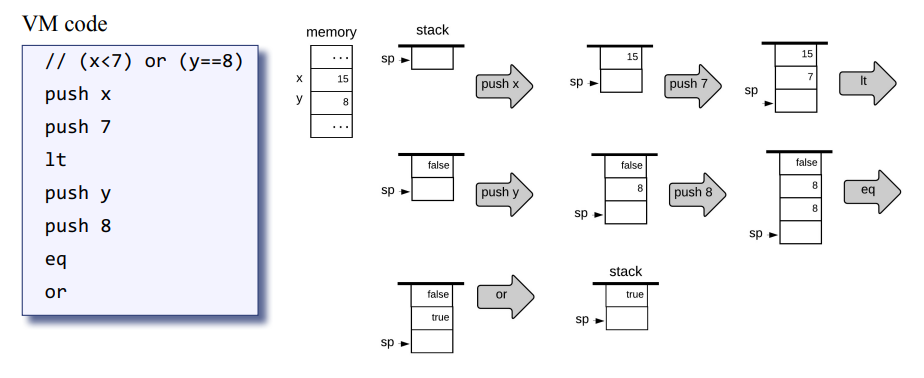
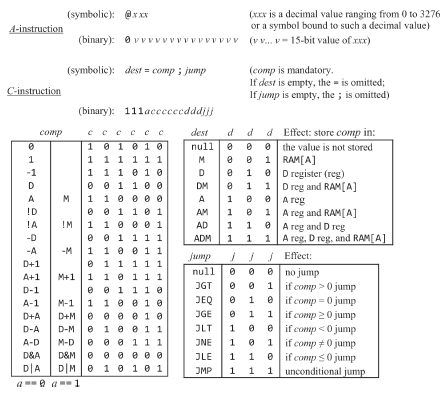
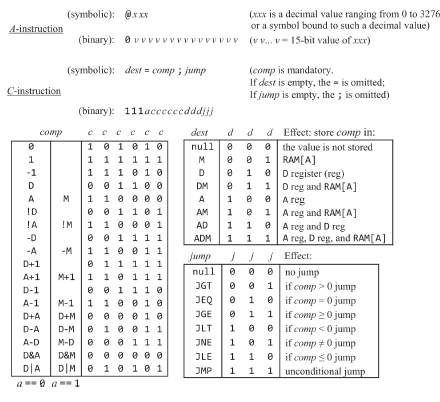
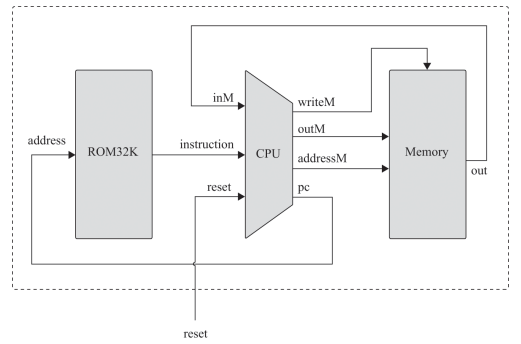
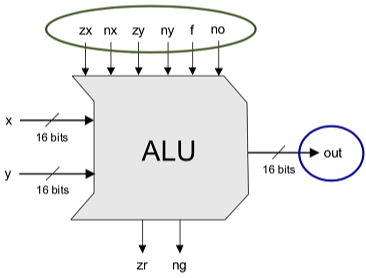
잠깐 쉬고나서 10장 컴파일러를 시작한다는게
너무 놀다가 11시가 되버렸다.
오늘 좀 늦게 자려고 중간에 잠깐 자기도 했지만 너무 늦어버리긴 했지만
일단 하는데까지는 해봐야지
이번 글 제목을 적는데서 부터 조금 불편한게
10장이 신텍스 에날리시스인데 아날리시스랑 파서랑의 차이가 뭔가 싶었다.
지난 번에 vm 부분이었었나 어셈블리어였엇나. 아 어셈블리어 파트구나 파서를 구현하라고 하는데
파서의 뜻이 그냥 파서라고 봐왓다보니까 그냥 파서라 생각하고 대충 넘겨왔지만
잠깐 찾아보니 분석하다라는 의미였었다.
이번 장 제목이 신텍스 에날리시스인데,
아날리시스도 결국에는 분석하다는 의미였지 않았던가.
아날리시스와 파서가 한국어로는 동일한거 같아도 영어에서의 의미는 조금 다를거란 생각이 들었다.


영영 사전을 보니 아날라이즈가 이해하도록 조사 연구하는 식으로 분석한다면, 파스는 문장을 분할한다는 의미더라. 결국에 이번 장 제목인 신텍스 에날리시스는 문법 분석이고, (파싱의 의미) 파싱은 주어진 문법에 따라서 토큰들을 분석하여 나누는 것/분류하는 것 정도로 생각하면 되는거같다. 다른 개발 블로그에서도 파싱, 파서를 그런식으로 설명하고.
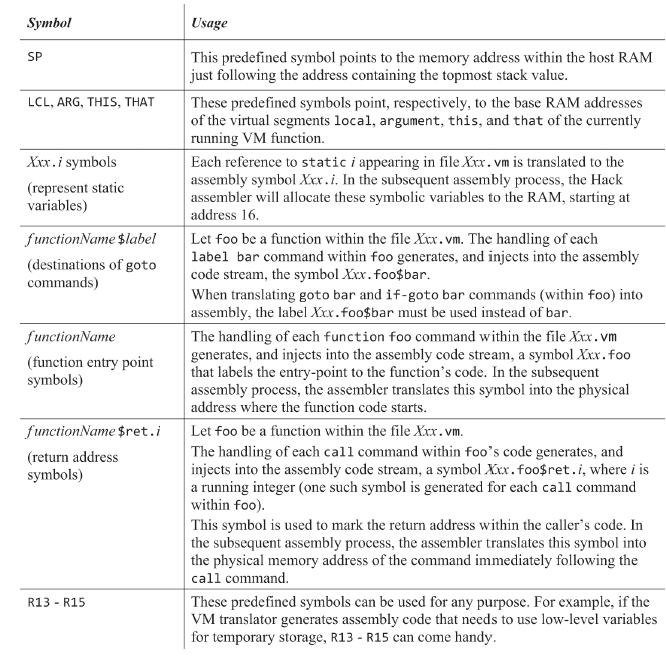
신텍스/문법 분석기 개요
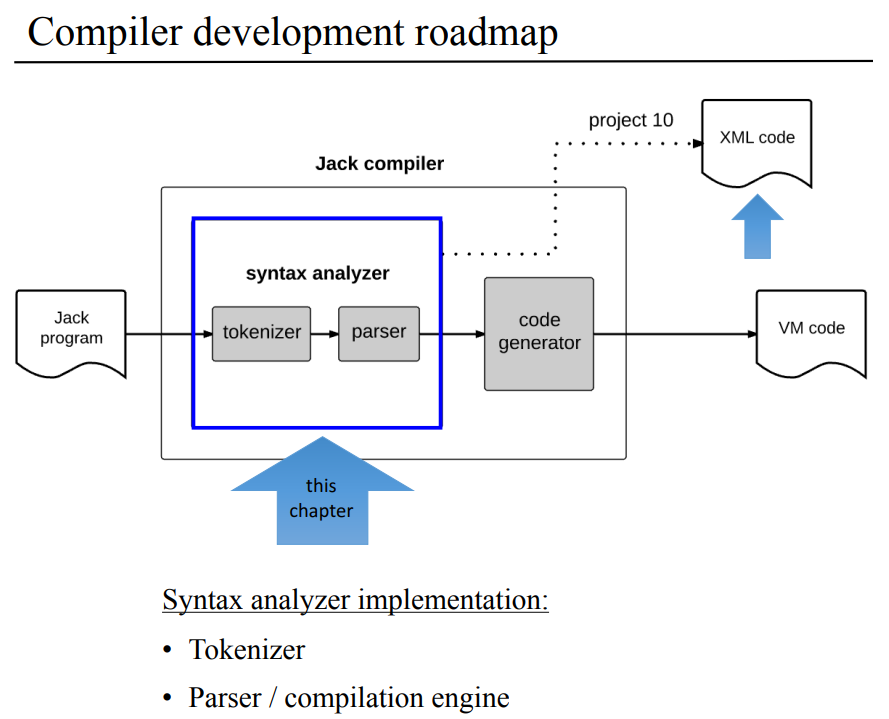
자. 이제 시작하면 컴파일이야 고급 언어를 중간 언어로 생성하는 걸 말하고, 크게 문법 분석과 코드 생성 작업으로 구분된다. 이번 장에서는 문법 분석을 다루며 문법 분석기는 토크나이저와 파서, 그러니까 형태소 분리기?와 토큰을 문법에 따라 분류하고 xml로 생성하는 파서로 구성된다.
그런데 컴파일러 만드는법을 배우는게 왜 필요할까? 저자분은 컴파일러를 만들면서 프로그래밍 언어를 분석하는데 쓰는 규칙과 문법/방식들이 컴퓨터 그래픽스나, 통신, 네트워크, 머신러닝 등 다양한 분야에서도 사용된다고 한다. 그런 분야 중 하나로 자연어 처리, 언어 번역 같은 곳에서도 텍스트를 분석하고 의미를 가진 단어들을 합성을 하기 때문이란다.
확실히 전에 자연어 처리 잠깐 볼때 토크나이저가지고 단어 나누고 어째저쨰하면 자연어 처리 모델이 문장을 만드는걸 보긴 했었다. 이런데는 아니더라도 데이터, 텍스트같은걸 다룰대 비슷한 내용들을 마주치긴한다.
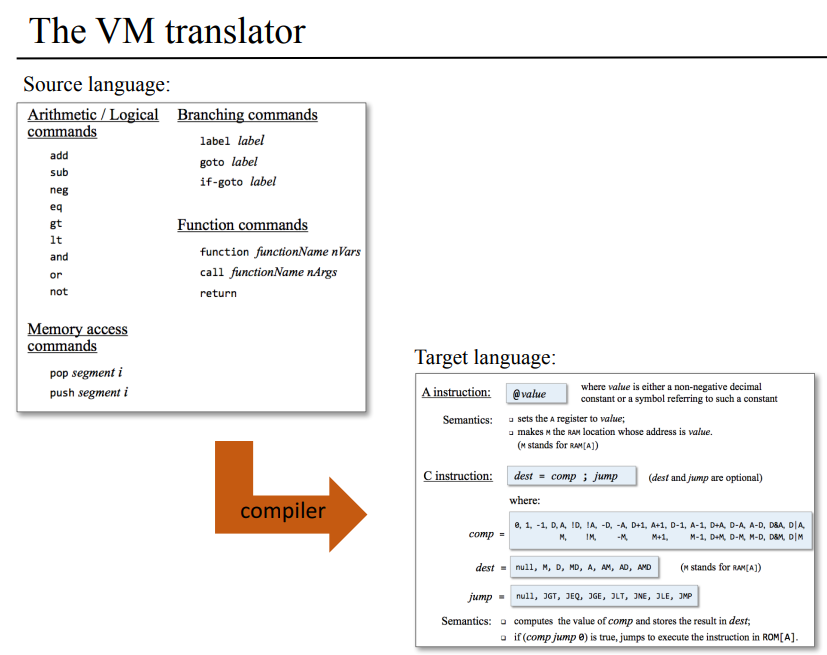
아까 잭 컴파일러가 문법 분서기와 코드 생성기로 구분할 수 있다고 했는데, 문법 분석기는 토크나이징/형태소화와 파싱/형태소 구조화이 두가지 작업으로 나뉜다고 한다. 문법 분석기의 출력으로는 XML 파일인데 이 XML로 작업이 잘 됬는지를 쉽게 확인할수 있고, 완전한 코드를 생성하는데 사용할 수가 있다.
여기서는 문법 분석기가 어떻게 사람처럼 프로그램 구조가 어떤지, 문법이 틀렸는지, 어디서 클래스/메소드가 시작하고 끝나는지 등을 분석할수 있도록 만드는지를 다룰건데, 이것들을 하려면 가장 먼저 프로그램을 토큰화(형태소화)를 하는것에서 부터 시작한다.
이 신텍스/문법 분석기에서 사용되는 개념들로 어휘 분석 lexical analysis, 문맥에 얽히지 않은 문법 context free grammars, 파스 트리 parse tree, 재귀 하강 파싱 알고리즘 recursive descent parsing 등을 살펴보자.
어휘 분석 lexical analysis
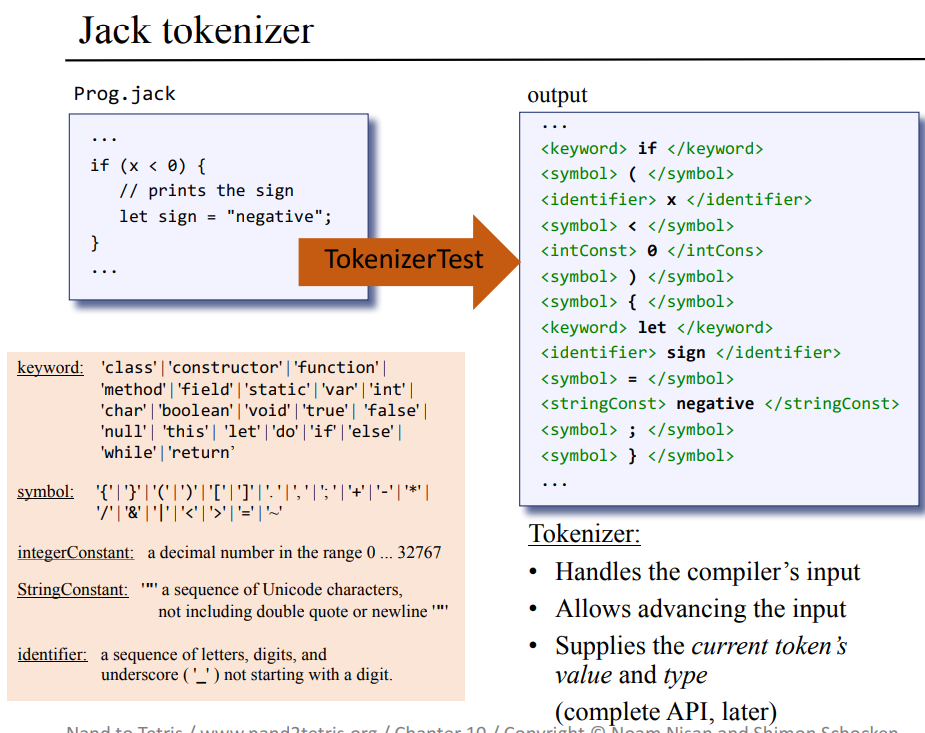
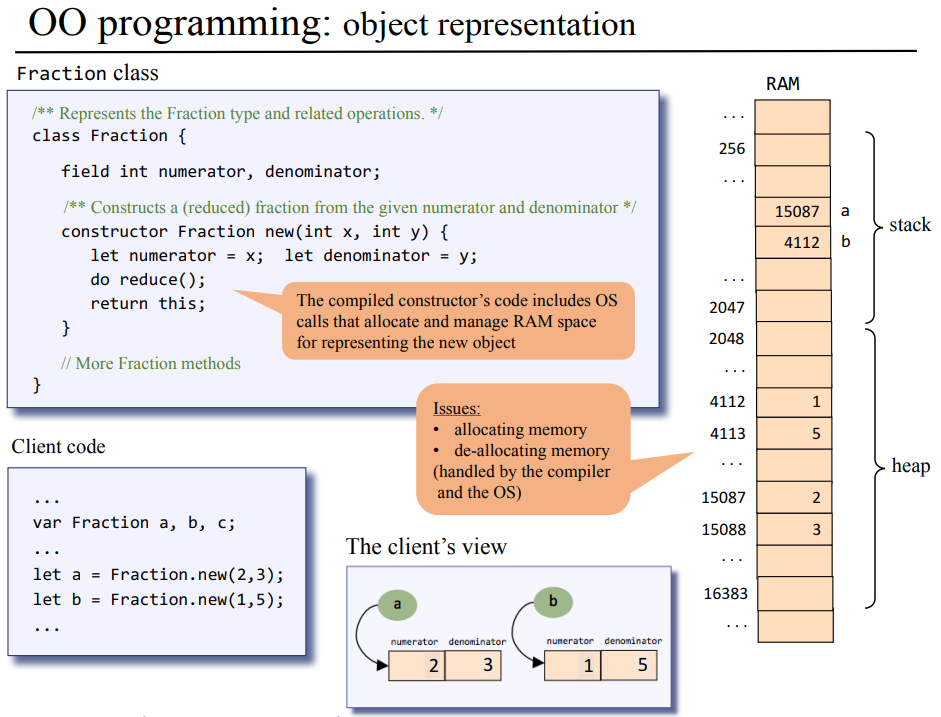
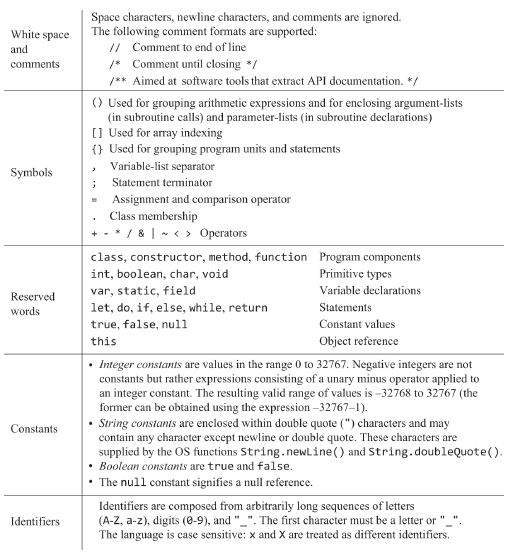
모든 프로그래밍 언어는 각 언어마다 고유의 토큰 종류들을 가지고 있다. JACK 언어의 경우 토큰들을 5가지 키워드, 심볼, 정수 상수, 문자열 상수, 식별자로 분류한다. 토큰화기/형태소화기는 주어진 프로그램을 형태소/의미를 가진 최소의 낱말 단위로 분할하여 우측의 xml 형태의 파일로 만들어낸다.
문법
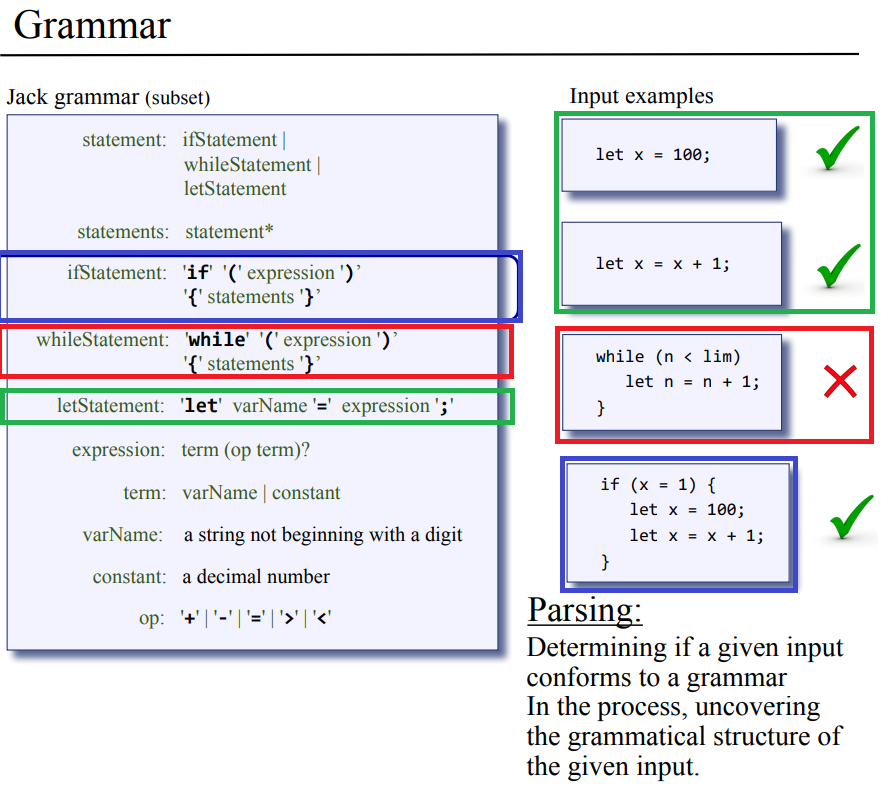
문법 컴파일에서 당 연하게 중요해 보이는데, 프로그래밍 언어의 문법은 토크나이저로 분리한 토큰들의 흐름/모음을 보고 이게 어떤 종류인지 구문인지, 표현식인지, 구문이면 if구문인지 while구문인지, let구문인지, 표현식이라면 용어 하나만 있는지 연산자와 따른 용어가 또 있는지 등으로 주어진 토큰들의 종류를 판단하는데 사용한다. 또, 토큰 뭉치가 그 종류의 구문/표현식의 문법을 따르는지 보고 올바른 문장인지 아닌지를 확인하는데 쓸수 있다.
문법 왼편과 오른편으로 나눠보자 : 저자 분은 문법을 메타 언어라고 하는데, 언어가 어떻게 되어있는지 표현하는 언어라고 한다. 이 경우에는 JACK이란 프로그래밍 언어가 어떤 형식과 규칙을 가지고 있는지를 영어로 표현한게 문법이 되는거같다. 컴파일 이론에서 언어, 메타언어, 문법, 추론 등의 내용이 있지만 여기서는 단순하게 왼편 오른쪽편만 나눠서 보자.
문법 규칙 왼편의 예시 : 위 그림의 왼편에는 규칙의 이름으로 실제로 프로그래밍 언어에 쓰이는건 아니지만 규칙끼리 구분하고, letStatement: 'let' varName '=' expression';' 처럼 letStatement라는 규칙 안에 varName이라는 규칙과 expression이라는 규칙이 들어가는데 이런식으로 다른 규칙 내용안에 포함되기도 한다.
문법 규칙 우측의 형태 : 규칙의 오른쪽 편에는 이 규칙이 어떻게 생겻는지 언어적으로 패턴이 나와있다. 이 언어 패턴은 3가지 블록 터미널, 비터미널 nonterminal, 수식어 qualifier로 구성된다. 여기서 말하는 터미널은 토큰(형태소)이고, 비터미널은 다른 규칙의 이름, 수식어 qualifier는 |, *, ?, (, ) 이 5가지 심볼로 구성된다.
토큰을 터미널이라고 하는건 터미널이 끝단이란 의미니까 의미를 가진 단어의 최소 단위/끝이므로 이걸 토큰을 터미널이라 하고, 터미널 외에 단어는 비터미널이라고 하는거같다. 위 문법 내용에서는 터미널 요소인 'if'처럼 볼드체에다가 따옴표가 붙어있고, expression같은 비터미널 요소에는 이탤릭체를, *나 ?처럼 수식어는 그냥 일반 폰트로 나타낸다.
문법 규칙 우측의 예시 : 예시로 하나를 보면 언어 규칙 ifStatement: 'if' '(' expression ')' '{' statements '}' 라고 되어있는데 이 의미는 모든 if문은 'if'라는 토큰으로 시작하고, 그다음에는 '('라는 토큰이, 그다음에는 expression이라는 비터미널이, 그다음에는 토큰), 또 토큰 '{', 뒤엔 비터미널 statements, 마지막으로 '}'토큰이 붙어 있다면 이게 유효한 ifStatement가 된다!
수식어의 역활 : 수식어 *는 0, 1 혹은 그 이상을 의미하는데 statements: statement*는 구문이 여러개 올수 있다는 의미가 된다. ?는 0, 1개만 온다는 의미로 expression: term (op term)? 이란 규칙에서 (op term)이 없거나 1개만 추가 될수 있다고 보면 될거같다. 수식어 (, )는 그룹핑으로 바로 윗줄의 (op term)?의 경우 op가 먼저 오고 term이 붙어서 한덩어리가 된다는 의미다.
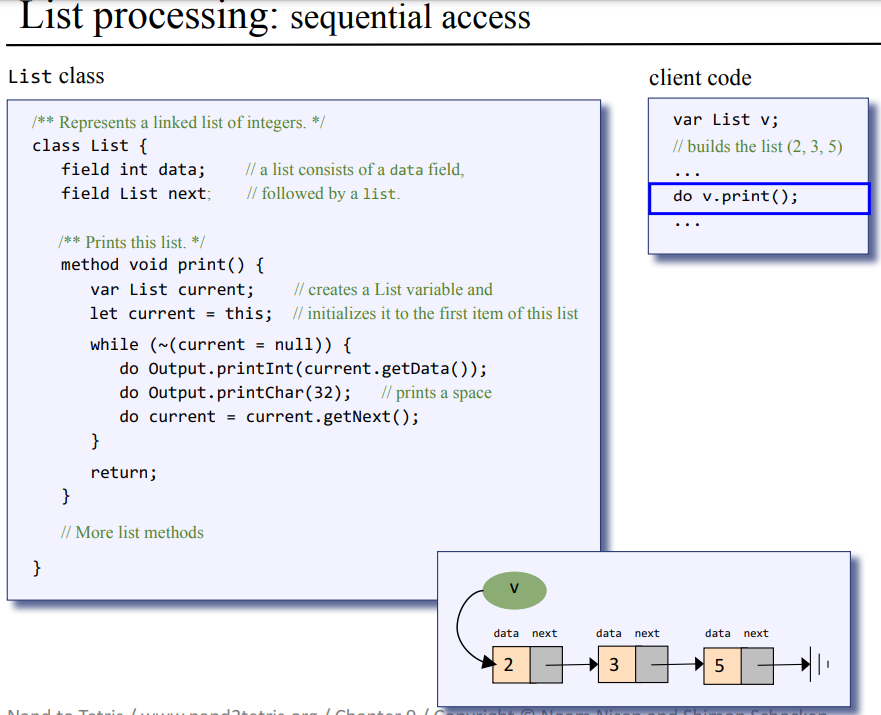
파스 트리 : 토큰들을 문법에 따라 분류한 트리
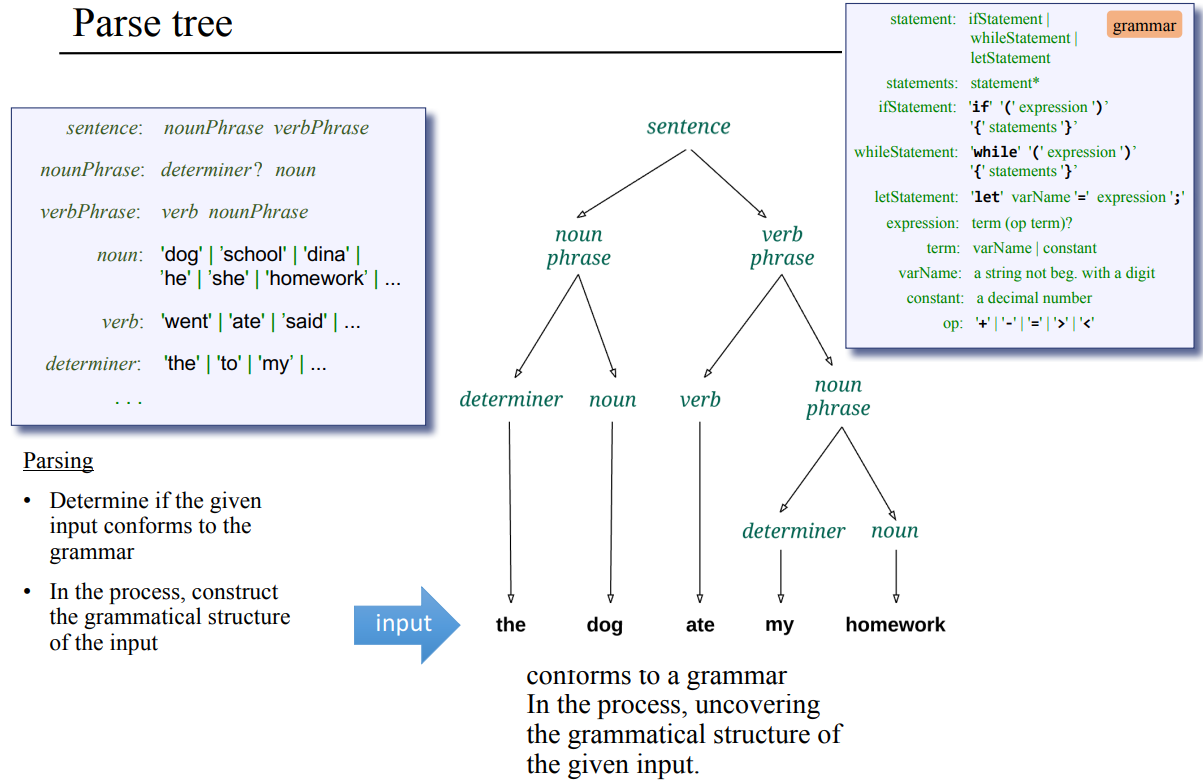
앞에서 프로그램을 토큰화기를 통해 토큰들과 각 토큰들의 종류를 xml로 정리했었다. 또, JACK의 문법 규칙들이 어떤 형태로 되어있는지도 봤다. 문법과 토큰, 토큰의 종류를 봤으니 이제 토큰들을 문법에 따라서 분류를 파스 트리를 만들 차례이다.
위 문법을 보고 코딩하던걸 생각해보면 문법을 재귀적으로 따르던걸 알수 있다.
void main()
{
int num = 0;
while (1)
{
if(num == 10)
{
printf("out");
break;
}
num = num + 1;
}
}재귀적으로 반복되는 문법 규칙들 : 이 코드는 Jack은 아니지만 간단한 c언어를 작성했는데, jack 언어의 문법 규칙을 참고해서 보면 while (1)은 while구문 바로 뒤에 수식어 ()와 수식어 안에는 1이라는 expression이 존재한다. 근데 이 표현식은 용어 term이 1개인 표현식이며, 이 용어는 변수 용어가 아닌 상수 용어이다.
수식어 )뒤에는 수식어 {}가 오며 이 안에는 구문들 statements이 들어가 있는데, 이 구문들은 if 구문과 num = num +1이니 let 구문 2개로 구성되어 있다고 볼수 있을거 같다. 또 이 구문안에는 또 다른 구문이 들어가 있는 식으로 문법 규칙들이 재귀적으로 계속 반복되고 있다.
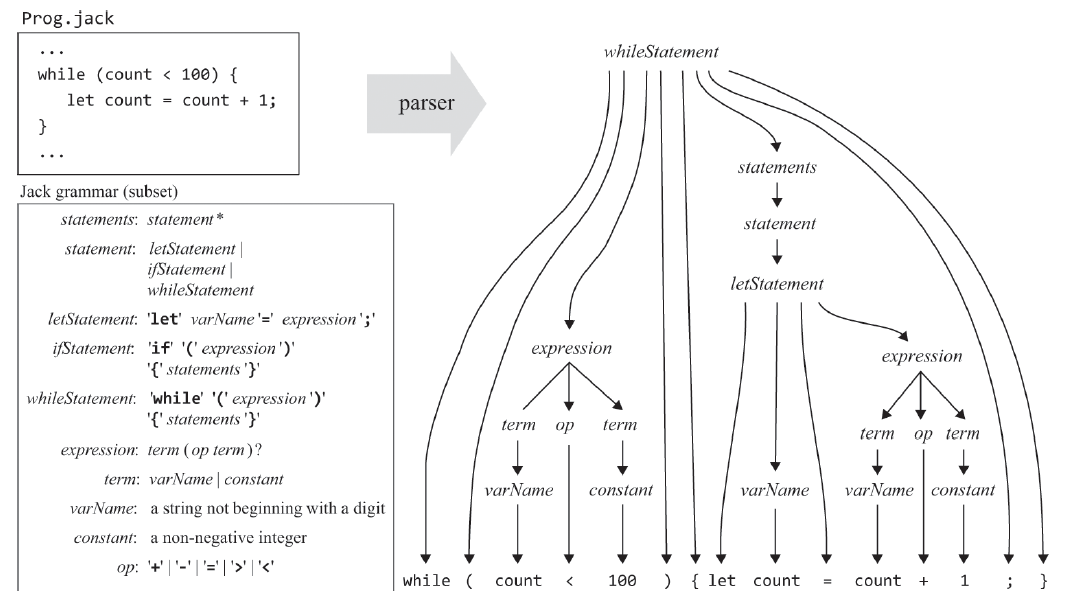
파스 트리 : 이와 같은 식으로 문법 규칙을 기준으로 구문들을 구문으로 구문의 종류에 따라서 또 분리하고, 들어가서 또 분리하기를 반복하며 모든 토큰들을 분류해낸 결과물이 파싱 트리이다. 위 그림은 while 구문을 규칙에 따라서 분류해 만든 결과물이다.

파스 트리 XML : 파스 트리를 만들면 이걸 어떻게 표현할까? nand2tetris에서는 XML형태 파일로 만드는데, 바로 위 while구문의 파스트리를 XML 파일로 만들면 이런 형태가 된다.
파서와 재귀 하강을 통한 파싱 처리

앞에서 문법 규칙에 따라서 파스 트리를 만들었는데, 파서는 프로그램을 입력받아서 파스 트리를 xml로 만들어내는 프로그램이 된다. 여기서 파스 트리를 만들기 위해 사용하는 방법은 재귀 하강 파싱이다.
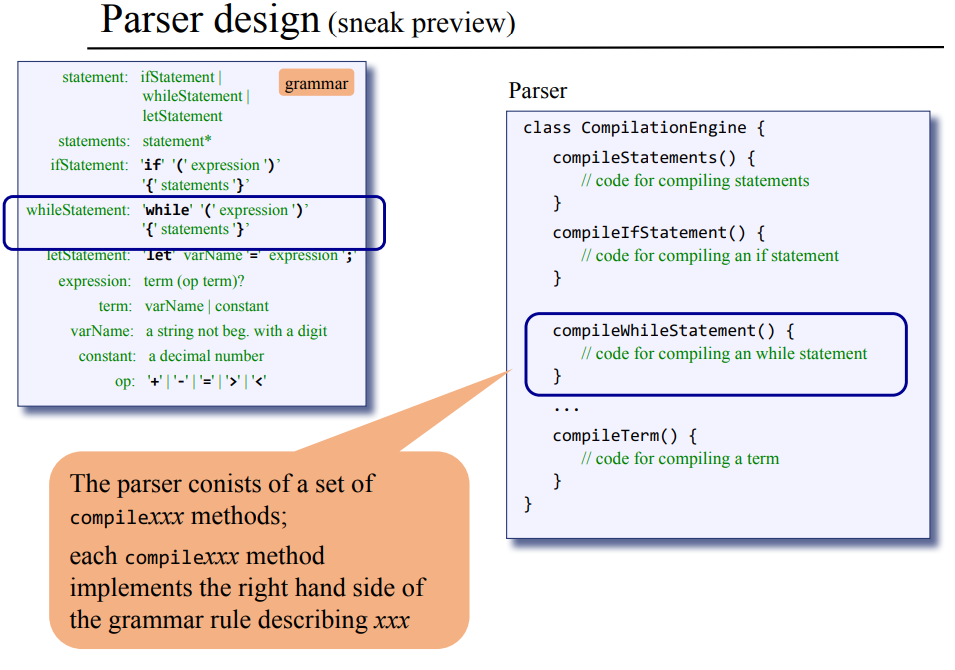
파서의 구현 : 파스 트리는 문법 규칙에 따라서 재귀적으로 구문을 내려가며, 끝에는 토큰단위로 분해해내었는데, 이 동작을 재귀적으로 호출해서 처리 할 수 있도록 각 문법 규칙 때마다 컴파일 하도록 구문 종류별 컴파일 함수 compileStatements(), compileIfstatement() 들을 구현해내면 된다.

compileWhile() 슈도 코드 : 위 그림은 while 구문의 컴파일 구현 슈도 코드로 어떻게 while 구문을 파싱 트리로서 xml 출력을 낼지를 보여주는데, 가장 먼저 <whileStatement>를 출력한 후, process("while")을 통해 이 문자열을 XML 토큰으로 출력한다.
그 다음 수식어 (를 처리하고, while 구문 규칙상 수식어 ( 뒤에는 표현식 Expression이 오므로 compileExpression()를 호출한다.
이와 같은 식으로 내부에 존재하는 수식어를 출력하고, 구문들을 컴파일 하면서 필요한 경우 재귀적으로 더 내려가면서 반복하게 되고 모든 재귀 연산을 마치고 나머지 수식어 출력도 마치면 </whileStatement>로 이 while 구문의 xml 부분 출력을 마무리한다.
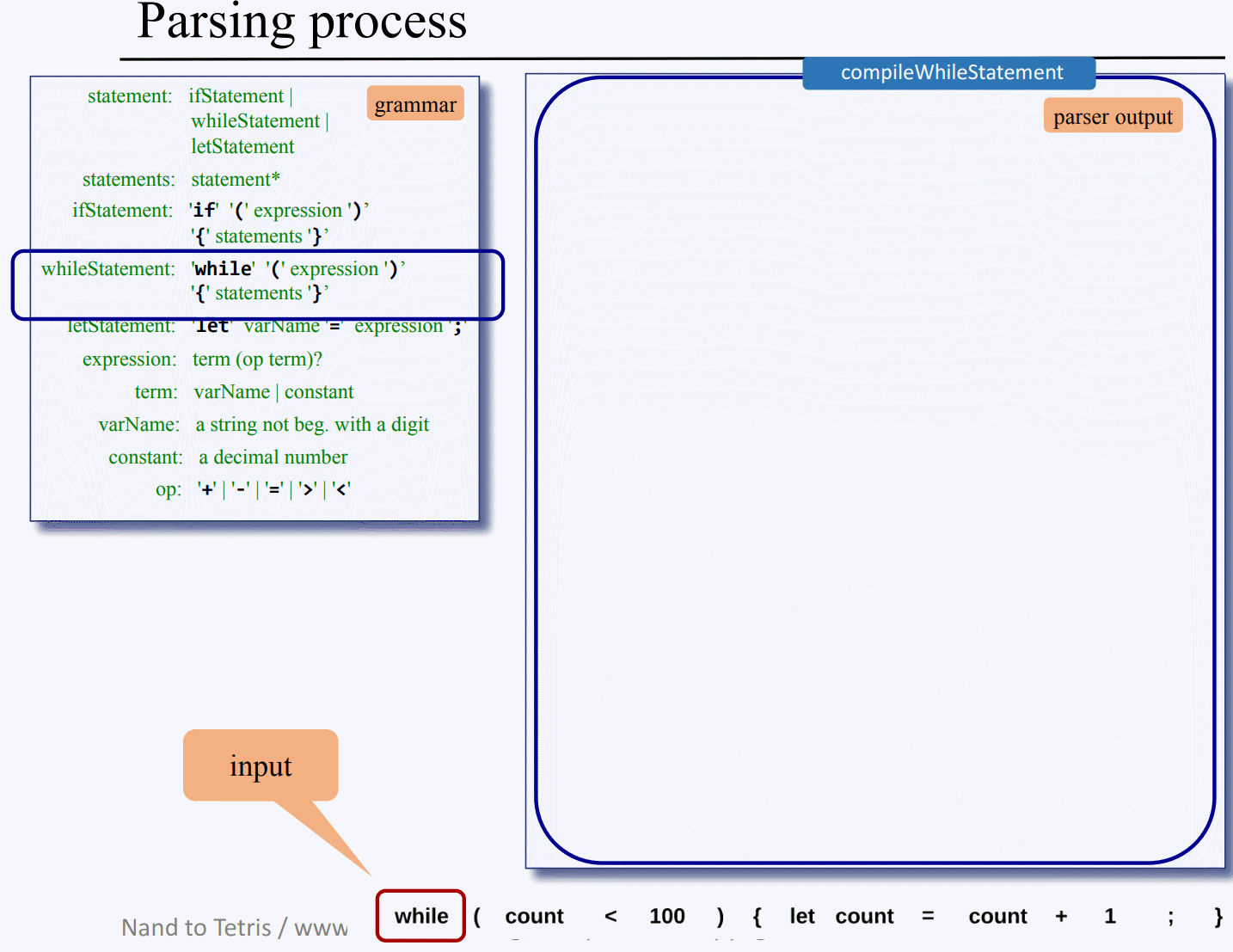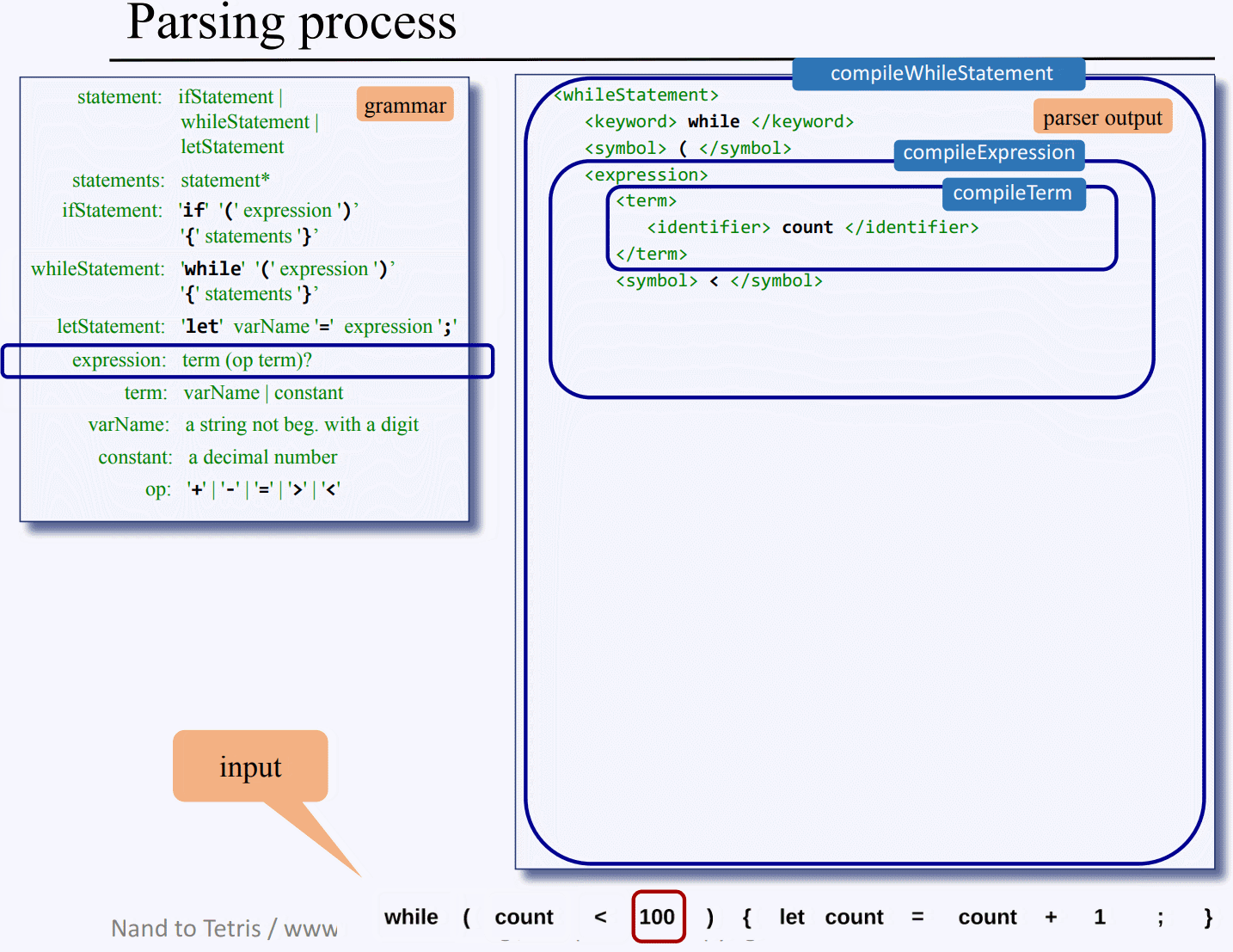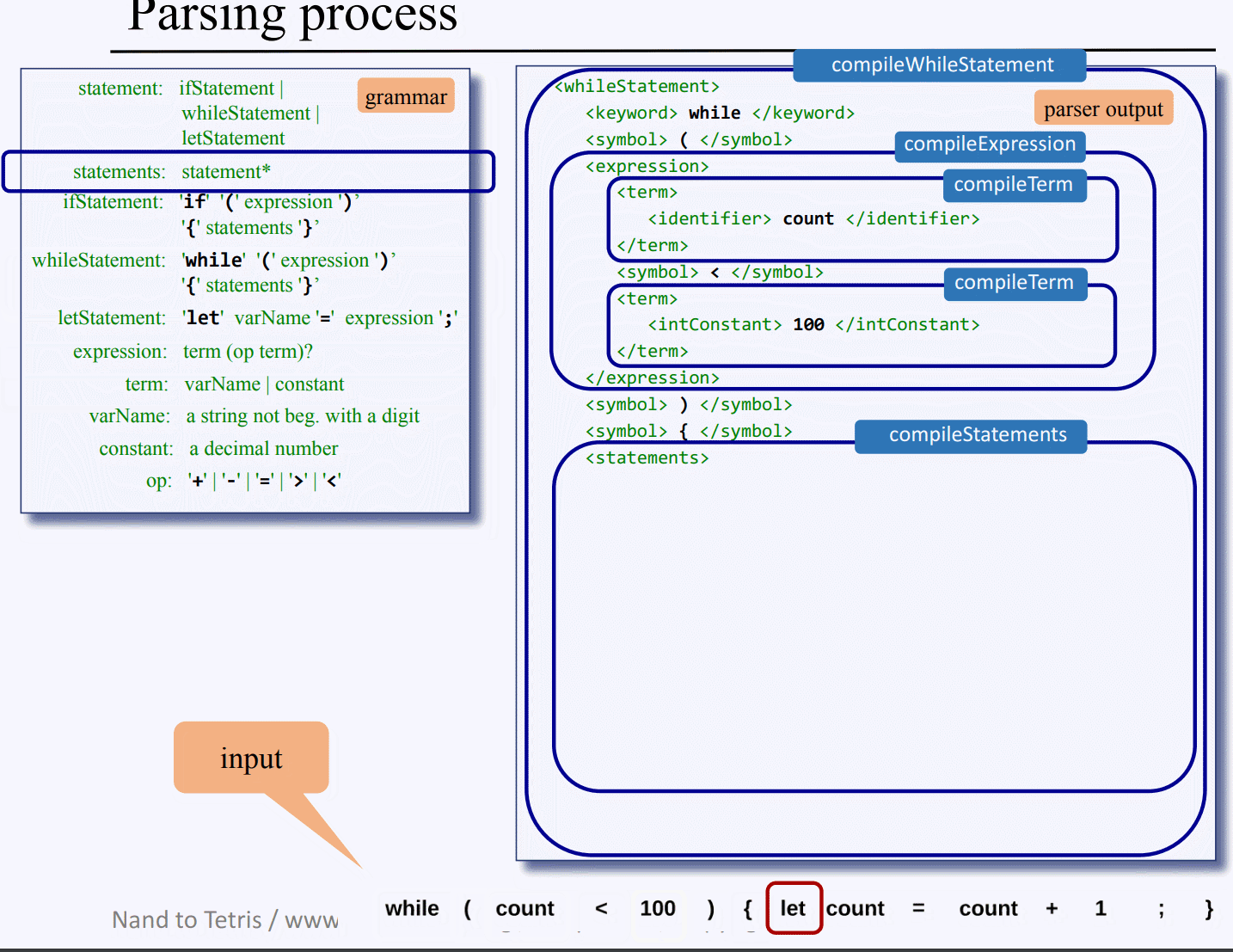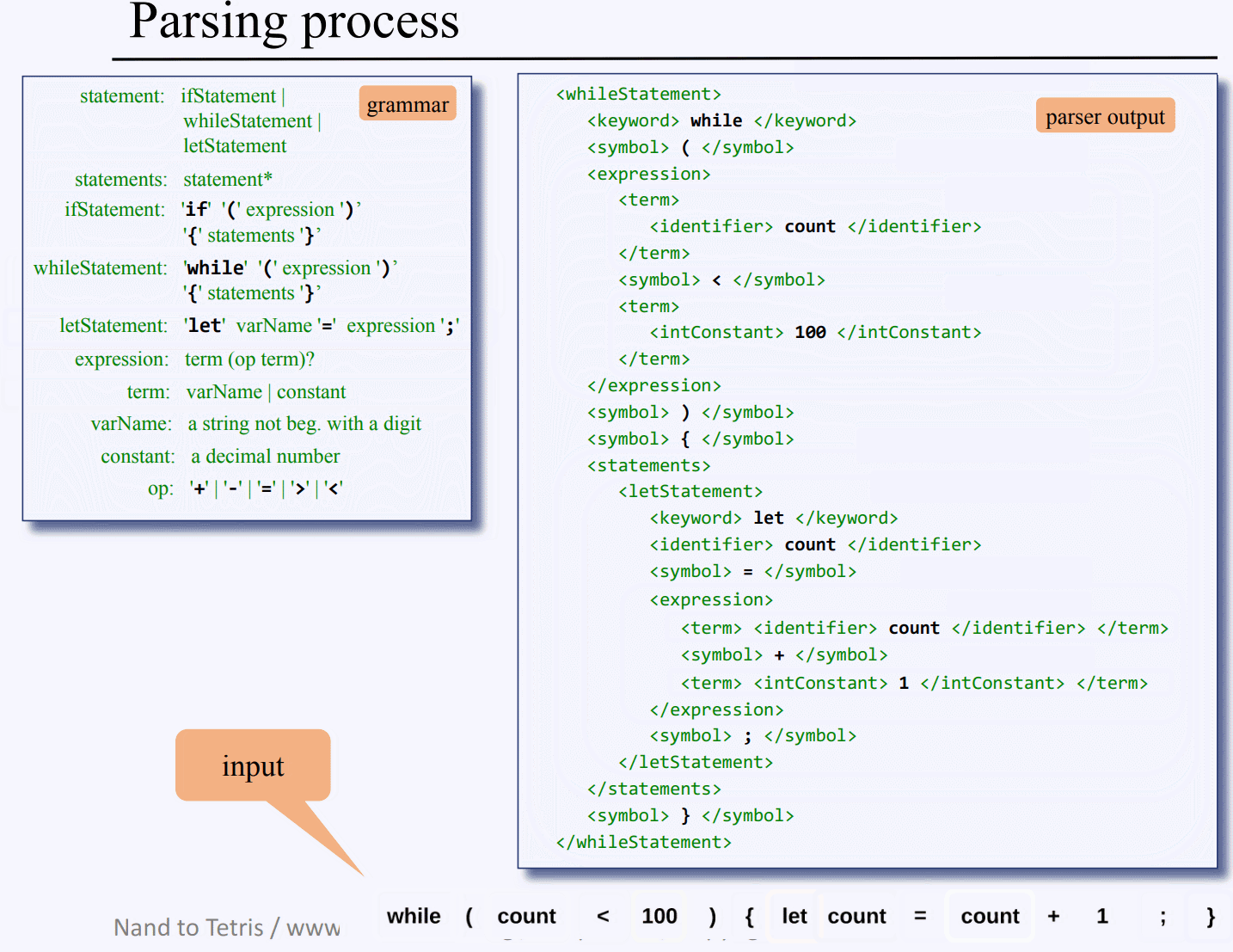
이쯤 되면 대강 파싱 XML 만드는 과정이 감이 잡힐탠대 PPT 내용을 일일히 캡처해서 while 구문을 xml로 만드는 과정을 gif로 찍어왔다..

방금 본 문법 규칙들 외에도 실제 객체 지향 언어의 문법 규칙은 더 복잡한데 jack에서 클래스 레벨의 static이나 인스턴스 레벨의 field 변수의 경우 이런 규칙을 쓴다.

LL 문법 (var, let, while 토큰의 역활) : 이런식으로 재귀를 이용하여 쉽게 파싱 동작을 수행할수 있게 만들었다. 이쯤되면 왜 jack에서 let이니 var이니 같은걸 쓰는걸 궁금했을텐데, 앞에다가 let이나 var 같은 토큰을 두면서 이게 무슨 동작을 하는건지 let 구문 규칙을 비교해야할지, var 구문 규칙이랑 비교해야할지 구분할 수 있게 해준다. 위 gif 예시에서도 while이라는 토큰이 맨 앞에 있어서 while 구문인걸 알고 compilewhile()을 호출해서 썻다.
위 문법 표처럼 첫번째 토큰으로 어느 문법 규칙을 봐야할지 판단할수 있으면 LL(1), 이걸로는 부족해서 두번째 토큰도 봐야한다면 LL(2)를 이와 같은 방식을 LL 문법이라 하며 이 덕분에 백트래킹 없이도 효율적인 재귀 파싱 알고리즘을 구현해냈다.
JACK 문법 정리
 |
 |
이제 앞서 본 문법 표기법에 따라서 JACK의 문법을 정리한 내용은 우측의 그림과 같다.
첫번째 토큰만으로는 애매할 때

위 그림처럼 foo라는 토큰 뒤에 (, . , [ 같은 심볼이 올때가 있다. 그러면 foo[인 경우, foo. 인 경우, foo(인 경우 등 경우에 따라서 다른 형태의 문법 규칙을 사용해서 컴파일을 해야하는데 첫째 토큰인 foo 만으로는 어느 컴파일 함수를 해야할지 판단할 수 없다. 그러므로 LL 문법에 따라서 2번째 토큰이나 필요한 경우 3번째 토큰 혹은 그 이상을 확인하는 식으로 판단하면 된다.
마무리
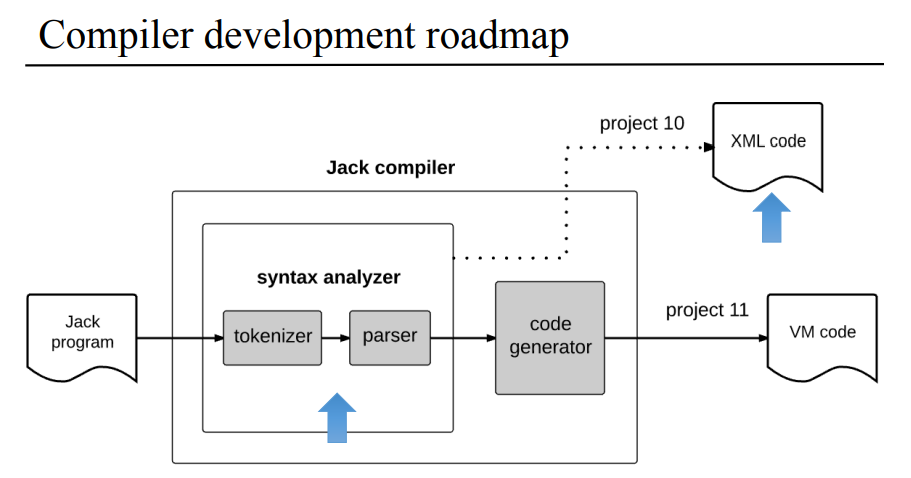

모든 파트가 그렇듯이 구현하는 부분도 있지만 넘어가고, jack으로 짜여진 프로그램에서 vm 코드를 생성하기 위해 이번 장에서는 토큰화기와 파서로 구성된 신텍스 분석기로 파싱 트리 XML을 만드는 과정 전반을 살펴봤다.
와 하루만에 챕터 2장 봤어. 지난 주에는 삽질도 제대로 하면서 구현까지 하느라 기본 1장에 이틀은 걸렸는데 진짜 금요일에 OS까지 훑어보고 이젠 nand2tetris 좀 그만 끝내고싶다 ㅋㅋㅋㅋㅋㅋ
실제 구현도 하면 더 기억에 오래남겠지만 가산기도 제대로 못만들어서 끄적대다가 원서도 이만큼 읽고 ppt의 도움으로 여기까지 왔으니 나중에 하고싶어지면 구현해야지 싶다 지금은 이렇게 CS 지식을 좀 더 쌓은것만으로도 충분히 잘한거라 생각한다.
----
05.26
어제 하루만에 2장을 급히 훑어보고
11장, 12장만 하면 되는데 오늘 급 의욕이 떨어졌다.
처음에 시작할때는 괜찬았는데 대강 지금까지 한 내용들만해도 내가 궁금했던거 거의 다 보기도 했고
OS 파트를 좀 보긴 해야되는데 나중에 하고싶어지면 보고 일단 nand2tetris는 여기까지 마무리하는걸로?
이 다음으로는 임베디드나 이용성 교수님이 알려주신 프로테우스로 회로 만들고 시뮬레이션 하는걸 해볼까 싶다.
'컴퓨터과학 > 디지털회로' 카테고리의 다른 글
| nand2tetris - 19. 고오급 언어 JACK (0) | 2022.05.25 |
|---|---|
| nand2tetris - 18. 가상 머신의 구현 방법 (0) | 2022.05.24 |
| nand2tetris - 17. 가상 머신을 이용한 제어 2 - 함수 (0) | 2022.05.24 |
| nand2tetris - 16. 가상 머신을 이용한 제어 1 - 분기 (0) | 2022.05.23 |
| nand2tetris - 15. 가상 머신의 동작 (0) | 2022.05.23 |