
우측 Mux16
우측 먹스 16은 a 단자에 A registor, b 단자에 inM이 들어온다. 그러면 어떨때 A reg의 값을, 어떨때 inM의 값이 전달되는지 판단해야한다.
일단 1번지 명령어 실행한 결과 M=0이 실행되었지만 M/A에는 inM이 아닌 @A가 들어와있다.
지금 보니까 dest=(A or D or 1)+M 같은 경우가 아니라면 inM을 연산에 사용하는 경우가 아니면,
M/Ainput에 들어올 필요가 없을거같다.
그러면 A+M의 경우는 어떻게 해야할까.
다행이 hack의 alu는 A+M연산을 할일이 없다.
comp 연산 테이블을 자세히 보면
a==0인 경우 A를 연산에 사용하고, a==1인경우 M을 연산에 사용한다.
그러니까 여기까지만 보면 a==0의 여부에 따라서 우측 Mux16의 sel 단자를 선택해주면 될거같다.
우측 mux16는 기존에 이런식으로 되어있으면
명령어의 opcode가 1이고, a비트가1인 경우 우측 먹스 16의 sel 단자에 1을 넣는다(and 연산). 그 외 경우에는 c=0이
//right Mux16
And(a=instruction[15], b=instruction[12], out=mIsUsed);
Mux16(a=aRegistor, b=instruction, sel=mIsUsed,out=inputMA);
이제 마지막으로 ALU를 정리하자
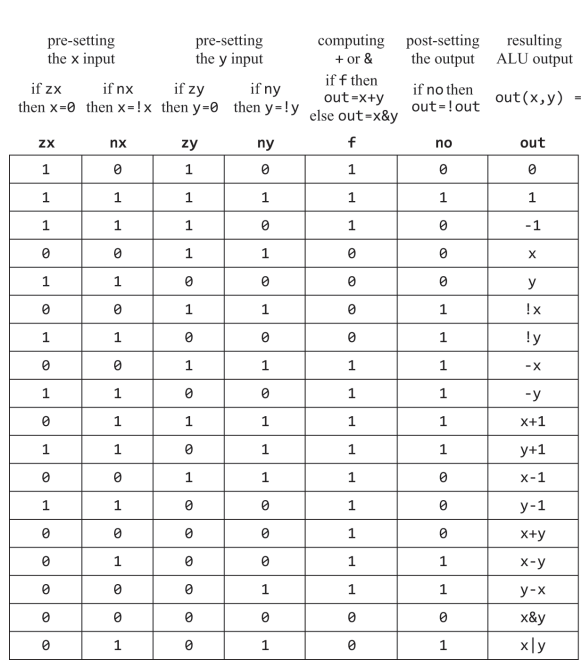 ALU의 제어비트 테이블 |
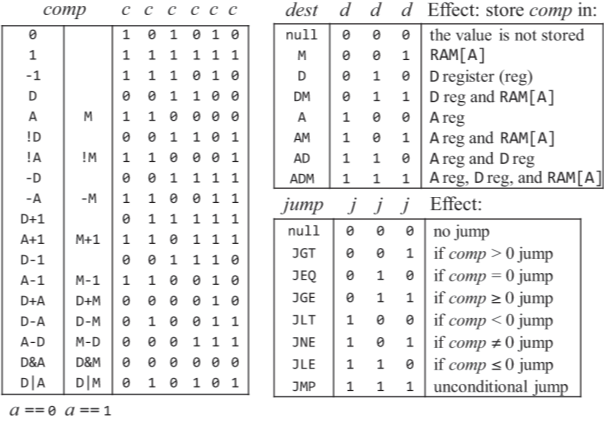 C명령어 제어 비트 테이블  ALU 입출력 |
위 테이블을 보면 c 명령어의 c비트를 그대로 alu의 c비트로 넣어주면 될거같고.
zr과 ng는 구현은 했지만 어디다가 쓰라는 말은 없었다.
C 명령어때는알겠는데,
A명령어 때는 ALU는 어떤 출력을 하는지 잠깐 보면 이전 C 명령어의 연산 결과가 그대로 유지되고있다.
하지만 A 명령어의 11 ~ 6비트 자리의 값에 따라서 멋대로 ALU가 연산하고 결과를 내보내면 안되니 별도의 로직이 필요하고
ALU는 기억장치가 아닌데 값을 유지하려면 기존의 ALU 출력을 다시 피드백해서 내보내고 있어야한다.
ALU 출력 결과를 그대로 가져온다면
1. D Registor의 값을 받아서 ALU가 그대로 내보내거나
2. 좌측 먹스에서 ALU OUT이 선택되고, A레지스터에 선택된후 우측 먹스를 통해 넘어온게 다시 출력으로 간다고 봐야할거같다.
아무튼 결국 A 명령어인 경우 a 혹은 b 입력을 그대로 전달해주기만 하면될거같은데.
a 단자를 전달한다면 001100, b단자의 값을 내보낸다면 110000을 제어 비트 단자에 넣어주면 되겠지만
어쩔때 a 혹은 b 입력을 전달할지 판단 기준이 필요하다.
....
와 CPU 구현하는데만 순수하게 6-7시간 쯤 걸린거 같다.
어제 저녁부터 새벽 내내 하고, 오늘도 수업 시간 중에 틈틈이 계속하고 지금이 8시 좀 넘었는데 지금까지 했으니
원래는 글 적어가면서 전체 틀잡고, 에러 고쳐가려고했는데 수정해야될게 너무 많더라
책에서는 어떻게 회로들을 연결하면 CPU가 만들어지는지 친절하게 설명해줘서
CPU야 금방 만들겟꺼니 했는데
단순 연결을 떠나서 각 회로의 제어 비트를 어떻게 값을 넣일지 조정하는게 너무 어렵더라
A, D 레지스터의 로드 비트,
좌 우측 먹스에 어쩔때 a를 넘길지 b를 시킬지
가장 힘들었던건
프로그램 카운터 점프 시점을 조절하는게 너무 힘들었다.
8가지의 점프 조건과 D 값이 일치하는 경우에만 load 자리에 1을 대입시켜 전달 받은 A 레지스터의 값을 저장시키도록
로직 구현하는데 CPU 구현하는 시간의 2/3정도 낭비했다.
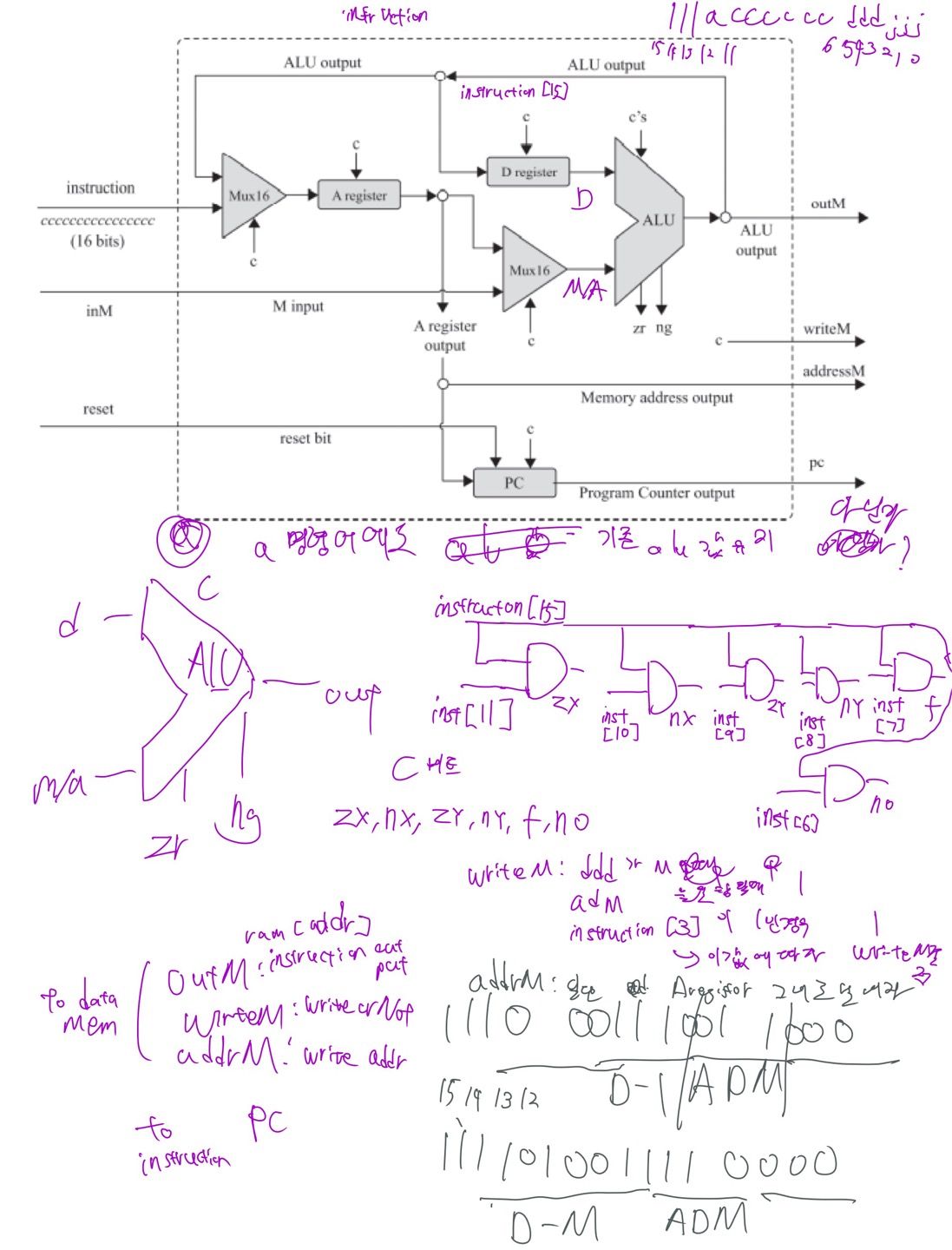
이건 어떻게 배치해야할까 생각하면서 정리한 내용인데 중간에 instruction[15]와 and 게이트 여러개 있는건 명령어로부터 ALU 제어 비트를 뽑아내기 위한 로직이고, 아래에는 writeM, addressM, 목적지 고민하면서 끄적데던 흔적이다.

나는 처음에는 점프를 C 명령어 j 비트에 값이 존재한 경우에 무조건 PC의 load 비트에 1을 대입하여 점프하도록 시켰었는데, 그랬더니 jjj의 조건에 맞지 않는 연산 결과가 나와도 점프 해버리는 문제가 발생했었다.
그 문제때문에 어떻게 하면 jjj 비트에 따라서 올바른 조건을 찾아 그 조건이 성립하는지에 따라 load 비트로 값을 전달하는 로직을 고민하면서 mux를 이용했다. jjj로 먹스의 셀렉트할 단자를 선택하고 각 입력에서는 jjj 비트별 연산 출력을 받도록 하는데, JEQ, JGT, JNE 등 각 연산을 해서 조건에 맞으면 1, 안되면 0을 출력하는걸 sel 비트로 선택해서 load로 전달하는게 되겠다.
CHIP CPU {
IN inM[16], // M value input (M = contents of RAM[A])
instruction[16], // Instruction for execution
reset; // Signals whether to re-start the current
// program (reset==1) or continue executing
// the current program (reset==0).
OUT outM[16], // M value output
writeM, // Write to M?
addressM[15], // Address in data memory (of M)
pc[15]; // address of next instruction
PARTS:
//PC PARTS
Or(a=instruction[0], b=instruction[1], out=jmp12or);
Or(a=jmp12or, b=instruction[2], out=jmp123or);
And(a=instruction[15], b=jmp123or, out=isJump); //c instruction and jmp
// jump condition implementation * comp = outMLoop
Mux(a=true, b=false, sel=true, out=noJump); // jump con 1. 000 no jump
Not(in=ng, out=isNotNegative); // jump con 2. 001 JGT comp > 0 jump = not zero & not negative
And(a=isNotNegative, b=isNotZero, out=isPositive);
Mux16(a=false, b=true, sel=isPositive, out=isJGT16); // end JGT
Mux16(a=false, b=true, sel=zr, out=isJEQ16); // jump con 3. 010 JEQ
Or16(a=isJGT16, b=isJEQ16, out=isJGE16); // jump con 4. 011 JGE, comp >= zero, jump
Mux16(a=false, b=true, sel=ng, out=isJLT16); // jump con 5. 100 JLT
Not(in=zr, out=isNotZero); // jump con 6. 101 JNE, comp != zero, jump
Mux16(a=false, b=true, sel=isNotZero, out=isJNE16); // end JNE
Or16(a=isJLT16, b=isJEQ16, out=isJLE16); // jump con 7. 110 JLE
Mux16(a=false, b=true, sel=true, out=jump16); // jump con 8. 111 JMP, always jump
Mux8Way16(a=false, b=isJGT16, c=isJEQ16, d=isJGE16,
e=isJLT16, f=isJNE16, g=isJLE16, h=jump16,
sel[2]=instruction[2], sel[1]=instruction[1],
sel[0]=instruction[0], out[0..7]=isJump0to7, out[8..15]=isJump8to15);
Or8Way(in=isJump0to7, out=jumpRes1);
Or8Way(in=isJump8to15, out=jumpRes2);
Or(a=jumpRes1, b=jumpRes2, out=isJumpCondition);
And(a=isJump, b= isJumpCondition, out=isPCLoad);
Not(in=reset, out=isNotReset);
PC(in=aRegistorOut, load=isPCLoad, inc=isNotReset, reset=reset, out[0..14]=pc);
//A registor PARRTS
Not(in=instruction[15], out=opcodeOut); // A instruction == store to A registor
And(a=instruction[15], b=instruction[5], out=loadA); //if instruction is C and dest is a, store outM to A registor
Or(a=opcodeOut, b=loadA, out=aRegistorLoad);
//if opcode is 0 (== A instruction) -> opcodeOut = 1 -> load = 1
ARegister(in=leftMuxOut, load=aRegistorLoad, out=aRegistorOut, out[0..14]=addressM);
//D registor PARTS
And(a=instruction[15], b=instruction[4], out=loadD); //if instruction is C and dest is d, store outM to A registor
DRegister(in=outMLoop, load=loadD, out=dRegistorOut);
//right Mux16
And(a=instruction[15], b=instruction[12], out=mIsUsed);
Mux16(a=aRegistorOut, b=inM, sel=mIsUsed, out=inputMA);
//left Mux16
And(a=instruction[5], b=instruction[15], out=isOutMLoop);
Mux16(a=instruction, b=outMLoop, sel=isOutMLoop, out=leftMuxOut);
//ALU parts
And(a=instruction[15], b=instruction[11], out=zx);
And(a=instruction[15], b=instruction[10], out=nx);
And(a=instruction[15], b=instruction[9], out=zy);
And(a=instruction[15], b=instruction[8], out=ny);
And(a=instruction[15], b=instruction[7], out=f);
And(a=instruction[15], b=instruction[6], out=no);
ALU(x=dRegistorOut, y=inputMA, zx=zx, nx=nx, zy=zy, ny=ny, f=f, no=no, out=outMLoop, out=outM, zr=zr, ng=ng);
//writeM
And(a=instruction[15], b=instruction[3], out=writeM);
}
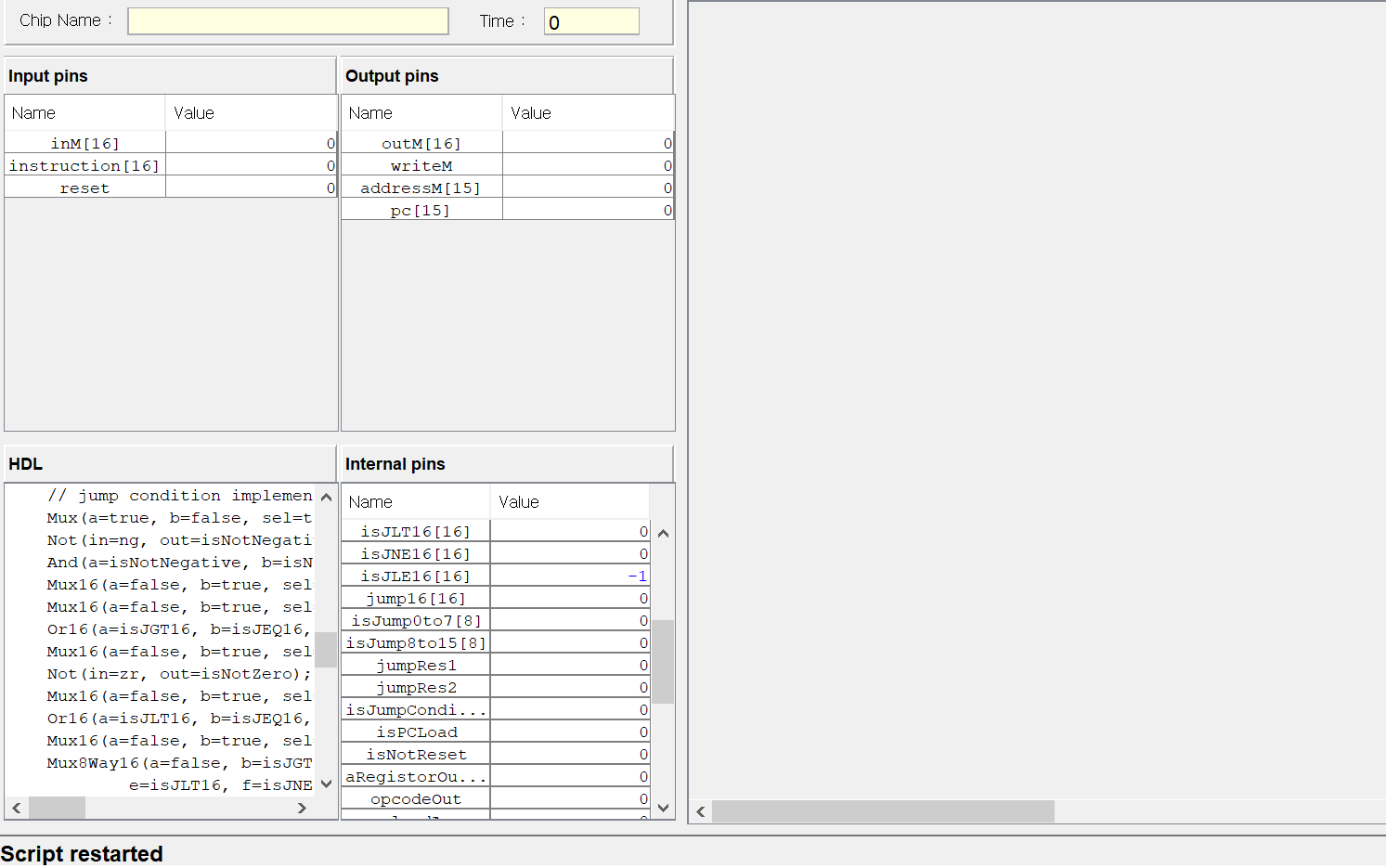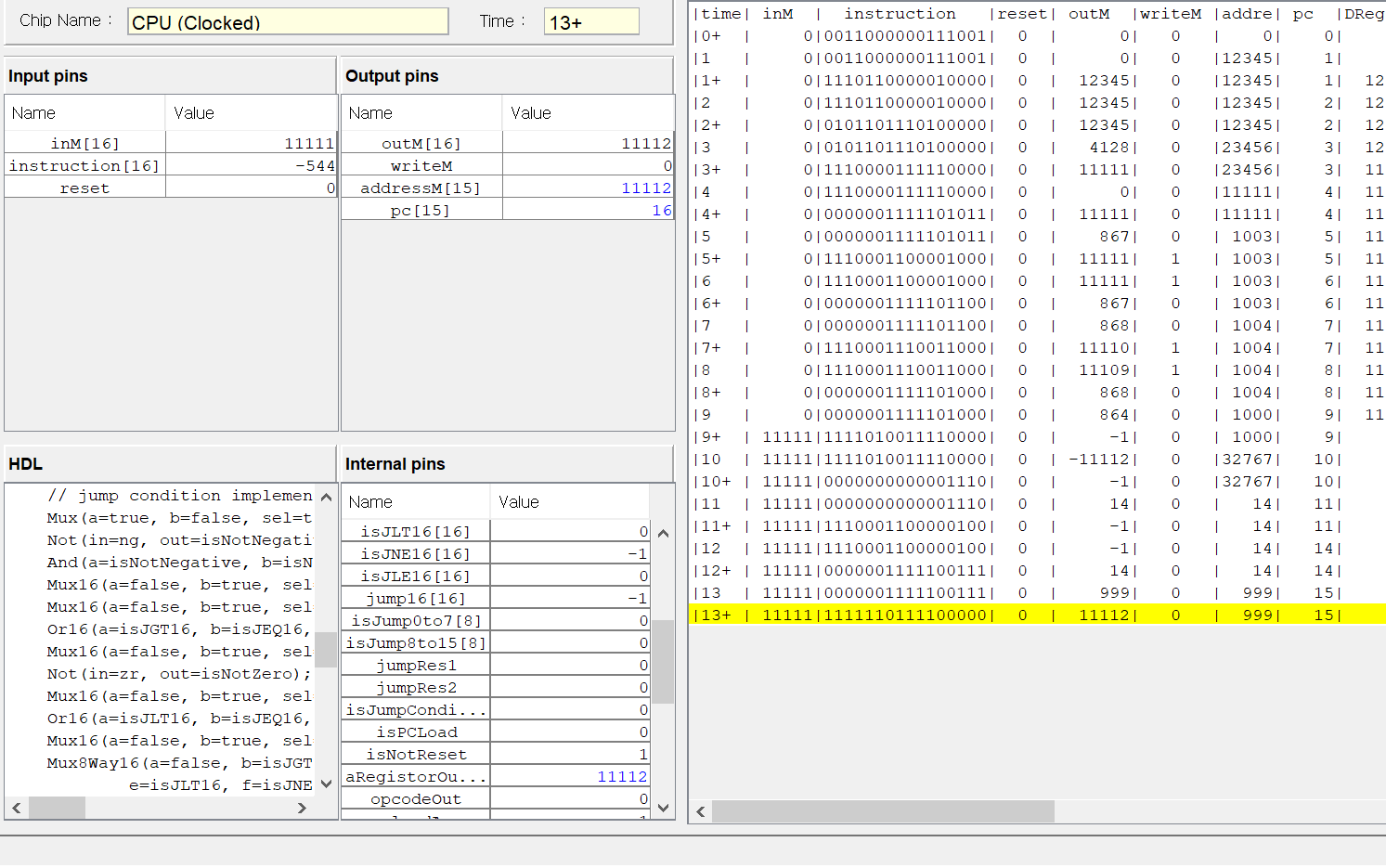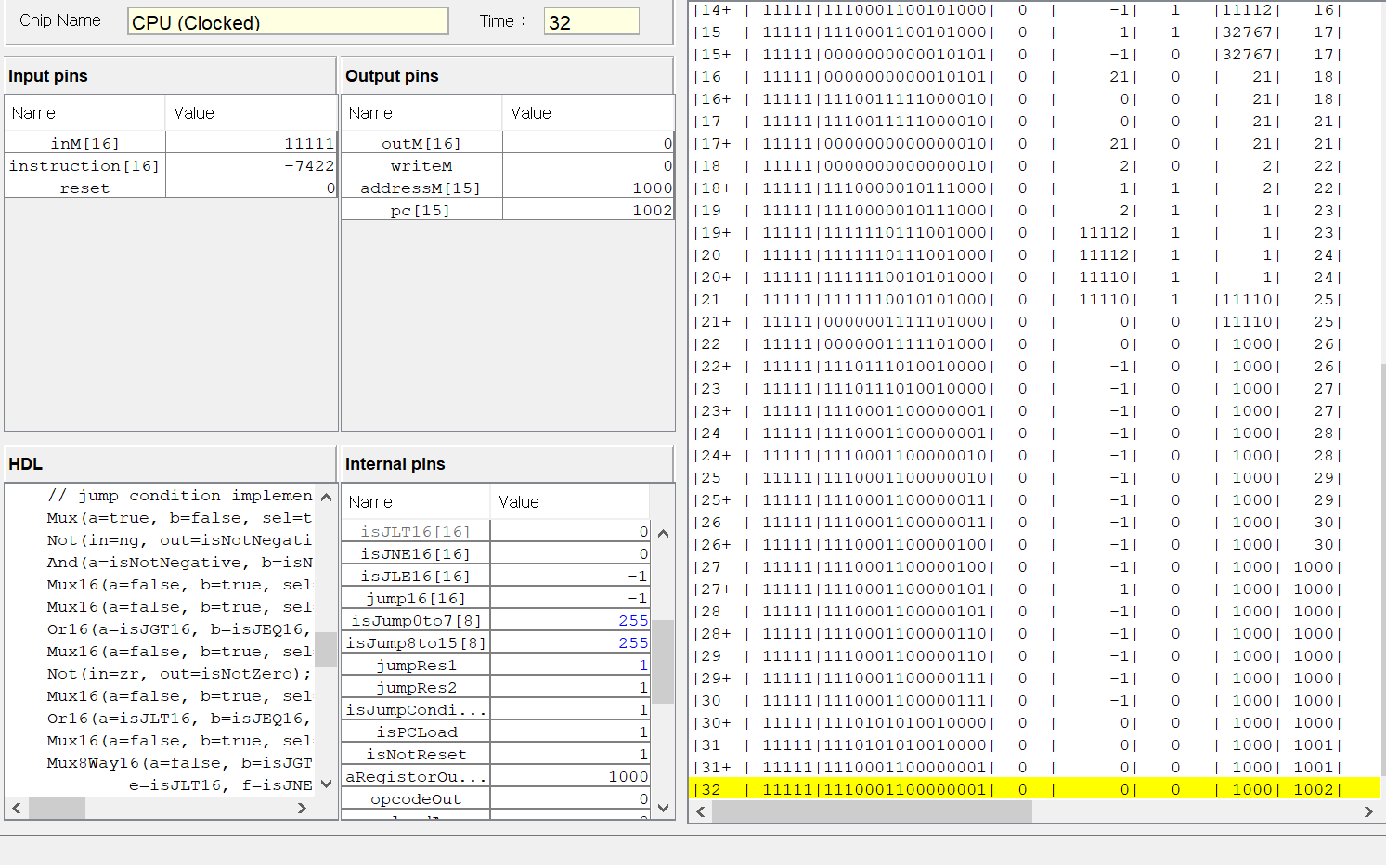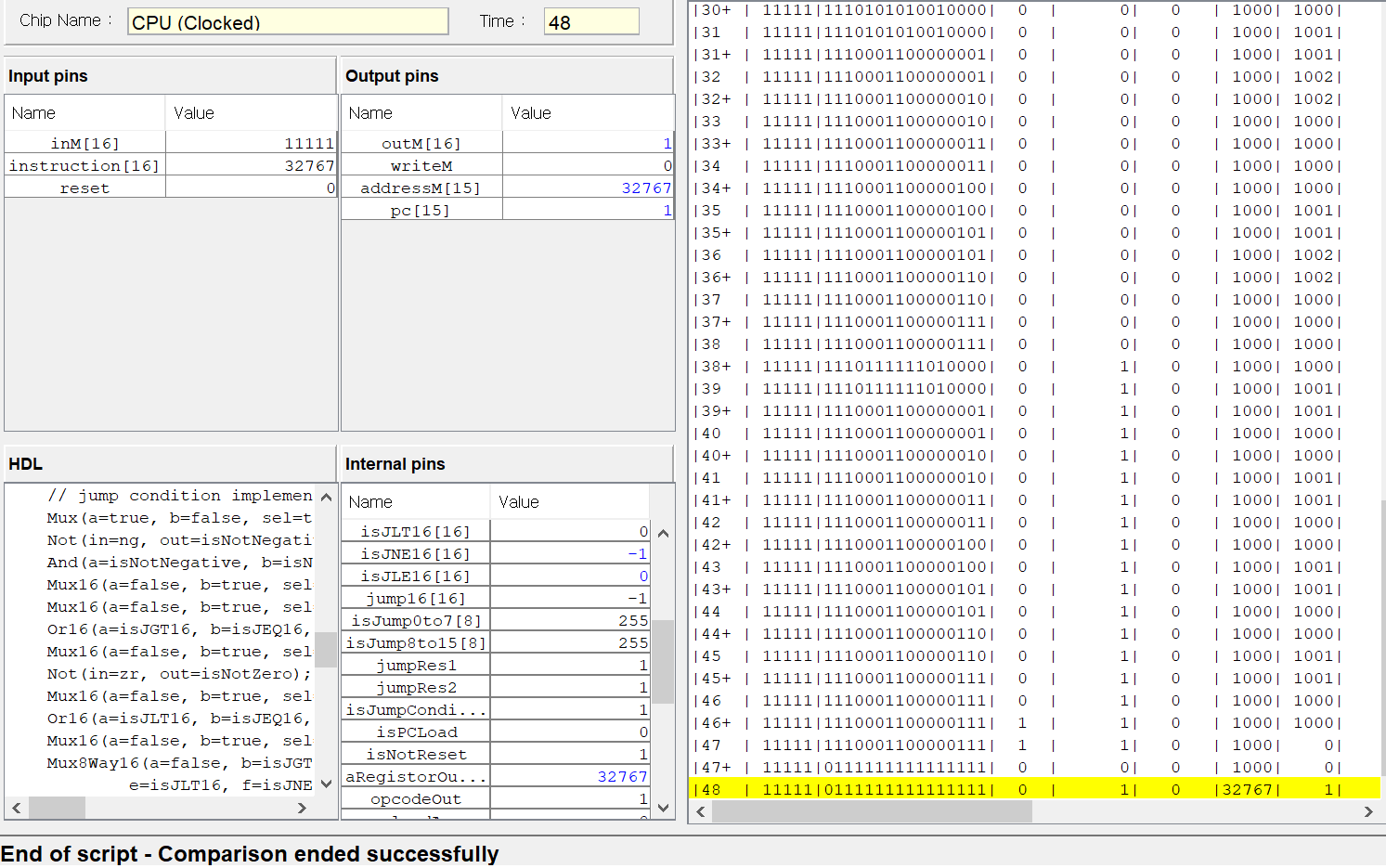
이 코드가 HDL을 이용해서 우리가 앞서 구현한 칩들을 잘 조합해서 만든 CPU이고,
테스트 코드도 잘 동작한다.
다른 사람이 만들어둔거 참고해서 할수도 있었는데
조금만 더하면 해결되겠지 싶어서 계속하던게 너무 오래걸렸다.
그래도 결국에는 난드 게이트로 CPU를 만들었다!
잠깐 되돌아볼까?
난드 게이트로 and, or, mux, demux 등을 만든 후 이걸 조합해서 alu를 만들었고
데이터 플립플롭을 앞의 조합논리회로랑 결합하여 레지스터, 메모리, 프로그램 카운터를 구현했다.
그리고 이것들을 오늘 다합쳐서 CPU를 완성한거고.
CPU는 다했으니 끝이면 좋겠지만 이번 장은 이게 끝이 아니지.
일단 이번 장은 여기서 한번 끊는다.
'컴퓨터과학 > 디지털회로' 카테고리의 다른 글
| nand2tetris - 13. hack 어셈블러 이론 (0) | 2022.05.20 |
|---|---|
| nand2tetris - 12. HACK 컴퓨터 구현하기 2(완성) (0) | 2022.05.19 |
| nand2tetris - 10. HACK 컴퓨터 구현하기 1 (0) | 2022.05.19 |
| nand2tetris - 9. 컴퓨터 아키텍처 이론 (0) | 2022.05.18 |
| nand2tetris - 8. HACK 어셈블리어로 곱셈 연산, 입출력제어 (0) | 2022.05.18 |