지난 금요일 까지만해도 주말에 가상머신을 끝내야되겠다고 마음먹고
집에 갔었지만
막상 가니 너무 편해서 쉬기만 하고 와버리고 말았는데
오늘부터는 구현은 가능한 넘어가고 빠르게 이론부터 진도를 나가야될거같다.
지난 금요일날 어셈블러까지 보면서 이책의 하드웨어 파트 절반이 완전히 끝났고
이번 장부터는 소프트웨어 영역으로 넘어가게 된다.
가상머신 장이 시작하기 전에 중간에 소프트웨어 파트 전반에 관해 설명이 나오기는 하지만
굳이 짚고 넘어가기는 귀찬아서 바로 가상머신을 시작하려고한다.
기존에는 책만 보고 이해한 내용을 바탕으로 정리를 해왔지만
잠깐 난드 투 테트리스 홈페이지에 나와있는 강의 자료를 봤는데
생각보다 책만 봤을때보다 이해하기 좋게 동작과정을 그림으로 잘 정리되어있더라.
그래서 이론 내용을 정리하면서 강의 자료도 참고하고자한다.
그렇게 바로 가상머신 내용을 시작하려고했지만
막상 보니 가상 머신이 중간 코드를 타겟 플랫폼의 어셈블리로 바꿔주는 걸로 시작하는데
이 내용이 간단하게 소프트웨어 개요 부분에서 나오다보니 안짚고 넘어갈수가 없을거같다.
소프트웨어 파트 앞으로 배울 내용들
아무튼 하드웨어 절반을 지나와서 앞으로는 소프트웨어에 대해서 정리하게 될건데
지금까지 공부한 내용으로 컴퓨터라는 블랙박스가 하드웨어적으로 어떻게 구성이 된건지 알수 있었고, 앞으로는 이 블랙박스가 소프트웨어로 어떻게 원하는 동작을 하게 되는지 배우게 된다.
9장에서는 hack 컴퓨터에서 사용가능한 객체지향언어 JACK에 대해서 알아볼 것이고, 이 언어로 게임이나 OS 같은 것들을 만들 예정이다. 그리고 고급 언어로 응용 어플리케이션과 운영체제 구현으로 넘어가기 전에 여전히 어샘블리어와 고급 언어 사이에 공부하지 못해서 잘 모르는 중간 다리가 있는데 어떻게 하길래 우리가 구현한 고급 언어가 어샘블리어로 로 컴파일하는지 컴파일러, 가상머신, 운영체제 등에 대해서 배우게 된다.
JACK 언어에 대해서 공부 한 뒤에는 JACK 컴파일러를 알아볼건데 이 컴파일러는 신텍스 분석과 코드 생성 파트로 구성되어 있어 10장, 11장에서 다루게 된다. 그리고 근데 이 컴파일러가 뭘 하냐면, C 언어 컴파일러처럼 타겟 플랫폼에 맞는 컴파일러를 선택하여 바로 그 플랫폼에서 쓸수있는 저급 언어를 생성하는게 아니라 자바 가상머신이나 C#처럼 가상 머신을 돌릴 수 있는 VM 코드를 만들어 내고, 컴파일러가 만들어낸 VM 코드를 각 플랫폼의 가상 머신에서 돌려 어셈블리어로 만들고 이 어셈블리어를 번역하여 컴퓨터를 동작하게 되는 과정이 된다.
이와 같이 고급언어 -> 저급언어로 바로 컴파일 하는 컴파일러를 1단계 컴파일러라 하고, 고급 언어 -> VM 언어 -> 저급 언어와 같이 2번 컴파일하는 과정을 거치는걸 2단계 컴파일러(2 tier compiler)라고 한다. 내가 앞에서 어딘가에다가 가상머신과 관련된 내용을 정리했던거 같기도 하고, 기억이 가물가물한데 아ㅏ.. 그때 C언어 이식성과 어셈블리어에 대해서 설명하면서 정리했던거 같다.
뒤의 책 내용 본 바로는 C언어의 이식성과 가상 머신이 결국 한 언어로 여러 플랫폼에서 사용한다는 큰 틀에서는 같아보이긴한데 조금 더 들어가서 보면 차이가 있었던거 같다. 아무튼 좀더 정리하면서 다시 봐야될거같고. 가상머신이 VM code를 기계어로 바꾸게 된다.
가상화.. 컴퓨터 가지고 이것저것하면서 vm player, 버추얼박스에서 라든가, 가상 메모리라든가, 앞에서 공부하면서 가상 레지스터에 대해서 잠깐 봤고, 클라우트 컴퓨팅에서도 가상화가 쓰이면서 가상화라는 개념이 엄청 중요한거라고 한다. 이 가상화에 대해서 7, 8장에서 살펴볼수 있을거같다.
9장에서 JACK 언어, 10, 11에서 컴파일러(신텍스 분석과 코드 생성), 7, 8장에서 가상머신에 대해서 배운다고 했고 그러면 이제 OS만 남는거 같은데 이 OS는 정처기나 운영체제 수업을 들어도 OS가 프로세스니 응용과 하드웨어 사이를 연계해주니 자원 관리하는다고 배웠던거 같기는한데 그렇게 와닿지는 않았었다.
당장 여기서는 OS가 라이브러리들을 모은 것이라고 설명하고 있다. 문자열 처리나, 메모리 관리, 그래픽 처리, 유저 인터페이싱 등을 처리하는 라이브러리들의 모음. OS라고 하면 프로그래밍 언어로 컴파일해서 돌아가는 뭔가라 생각했는데, 라이브러리의 집합이라고 하니 조금 생소하게 느껴지긴하다. 아무튼 이 OS가 저급 언어와 JACK 사이의 그동안 아무리 들어도 외우기만 했지 막연했던 연결고리 같은 역활을 한다고 하며,
JACK이라는 프로그래밍 언어를 쓸수 있게 만드는 프로그램(OS를 말하는건지는 아직 잘 모르겠지만)을 어떻게 JACK으로 구현하는지를 배우게 되는데 이 방법을 부트스트래핑이라고 한다. 이 부분의 말이 잘 이해가 가지는 않는데, JACK을 VM 코드로 변환해주는 컴파일러를 JACK으로 만드는 방법을 배운다고 이해하면 되는건지 아직 감은 잘 안잡히지만 지금은 그냥 넘어가야 될거같다.
아무튼 12장에서 OS를 만드는 과정에서 하드웨어와 주변 장치를 효율적으로 제어 할수있게 하는 자료 구조와 알고리즘 기법들에 대해서 배우고 JACK으로 구현하는게 소프트 웨어 파트 전체적인 틀인거 같다.
중간에 JACK 코드 예시나
운영체제가 뭔지 컴파일러가 뭔지 조금 나오는데 보고 싶은 부분만 잠깐 짚고 넘어가면
OS : main 함수 단에서 문자열을 출력할때, 여기다가 코드가 어떻게 된지는 적지는 않았지만, output.printString 이라는 함수를 쓰는데, 이 함수가 OS API, OS에서 에서 제공하는 표준 클래스? 라이브러리 내용이란다. 그리고 객체를 생성할때 RAM 상에 새 객체의 주소가 어딘지, 어떻게 프로그램 동작 과정에 메모리를 효율적으로 관리할지가 OS의 영역이다.
컴파일 : 심볼릭한 고급 언어를 돌리려면 기계어로 바꿔야하는데 이 과정이 컴파일이며, 고급 언어 프로그램을 컴파일하는 프로그램이 컴파일러가 된다. 근데 아까 2 단계 컴파일에 대해서 언급했는데, JAVA, C#, python 등이 이런 2단계 컴파일을 하는 고급언어라고 한다. JAVA의 경우에는 컴파러로 컴파일을 하면 bytecode라고 하는 중간 코드가 나오고 이를 타겟 플랫폼의 JVM에서 기계어로 번역되어 동작한다.
2단계 컴파일을 하는 이유는 7장 끝에서 자세히 나오니 지금은 넘어가야지
nand 2 tetris PPT에서 이해하기 좋게 나와있으니 좀 복사해와서 쓰면
7장 가상머신 동작에서 배울 내용들을 아래와 같다.
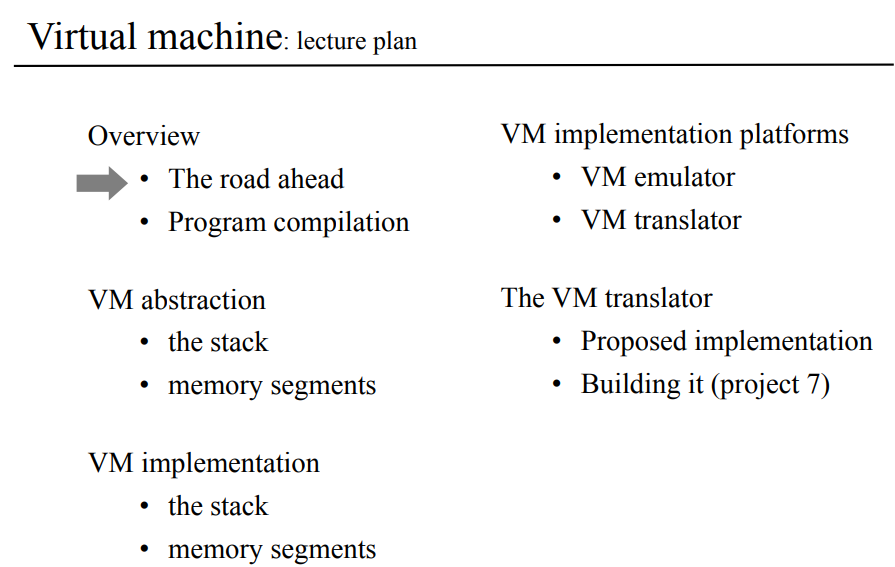
굳이 한글로 다시 정리한다면 이럴거같은데.
개요
- 앞으로 배울거
- 컴파일
VM 요악
- 스택
- 메모리 세그먼트
abtraction 이걸 그냥 앱스트랙션이라 하는게 나을지, 요약이라 할지 아니면 인터페이싱이라고 할지 고민하다가, 다른데는 추상화라고 하는거같기는 한데, 추상화라고 하면 너무 막연한 단어인거같아서 요약이라고 적었지만 인터페이싱이 더 맞는 느낌인거 같다. 추상화나 인터페이싱이나 거기서 거기긴한데 abstrction 적힌걸 인터페이싱이라 하면 뜬금없는거같고, 추상화라고 하기에는 거부감이 좀 든다. 아무튼 추상화라 하면 실제 타겟 플랫폼에 맞게 구현하는건 아니지만 여러 플랫폼에서 사용 가능한 전체적인 틀을 짜는 정도?로 알고 넘어가면 충분할거같다.(1장인가 2장인가 쯤에서 이 개념을 입출력이 어떻게 되는지만 정의한거라고 썻던거 같은데 그게 그거지)
VM 구현
- 스택
- 메모리 세그먼트
VM 구현 플랫폼
- VM 에뮬레이터
- VM 번역기
VM 번역기
- 구현법
- 구현하기
JACK 언어로 Hello World를 하려면 알아야 할것들과 추상화

보통 코딩을 처음 공부할때 hello world를 치는 방법을 배울때 언어 기초 문법을 잠깐 배우고 바로 적어서 해내기는 했지만, 이 장을 시작하기 전에 JACK언어로 문자열을 출력하려면, OS API를 써야 된다고 짧게 말하고 넘어갔어도 실제로는 화면 띄우기, 클래스와 함수 처리하기, do와 while(와일은 위 jack 프로그램에 보이지는 않지만 os 라이브러리 어딘가에 있어서 넣은거같다.), 함수 호출과 리턴, 운영체제 등이 다뤄지고 있다.
하지만 프로그래밍 하는 사람들 중에서 하드웨어와 운영체제 단에서 이런걸 이해하고 코딩하는 사람은 비교적 적을거같다. 이런걸 몰라도 알아서 다해주니까, 위 내용들을 몰라도 output.printString()만 치면 알아서 자원 할당하고, 함수 호출해서 화면에 띄워주는데 맨 앞에만 알아도 되는걸, 다시 적으면 output.printString()이란 함수와 매개변수, 출력만 알아도 원하는 동작이 되는걸 추상화라 생각해도 충분할거같다. 아깐 abstraction을 요약이라고 했지만 요약이라고 하기에는 부족한거 같아서 앞으로는 추상화라고 하지만 그때 그때 병행해서 써야겠다.
이 글을 처음 쓸때는 책의 SOFTWARE 개요 파트만 보면서 정리했는데, 지금 강의 자료 앞부분을 보니 아까 적은 내용들이 나온다. 강의 자료 내용을 앞에다가 다시 끼워 넣으면 꼬이는 글이 더꼬일거같아서 그림이랑 같이 반복하면
| 1단계 컴파일 | 2단계 컴파일 |
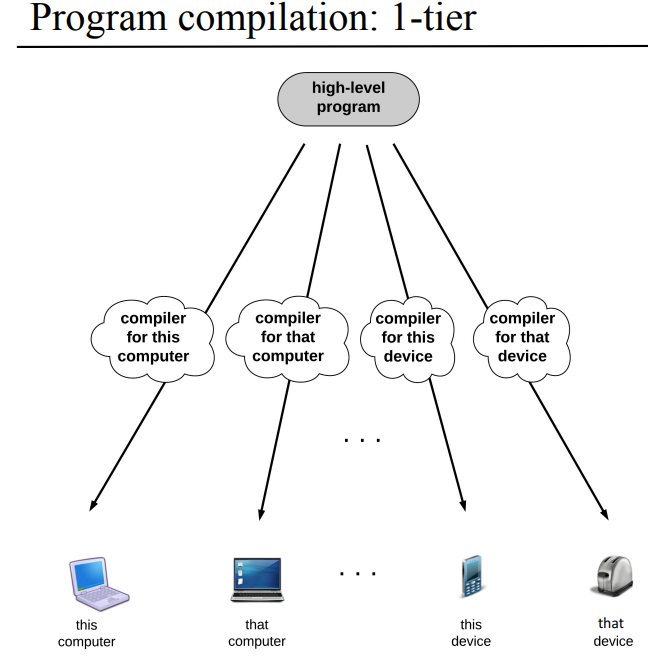 |
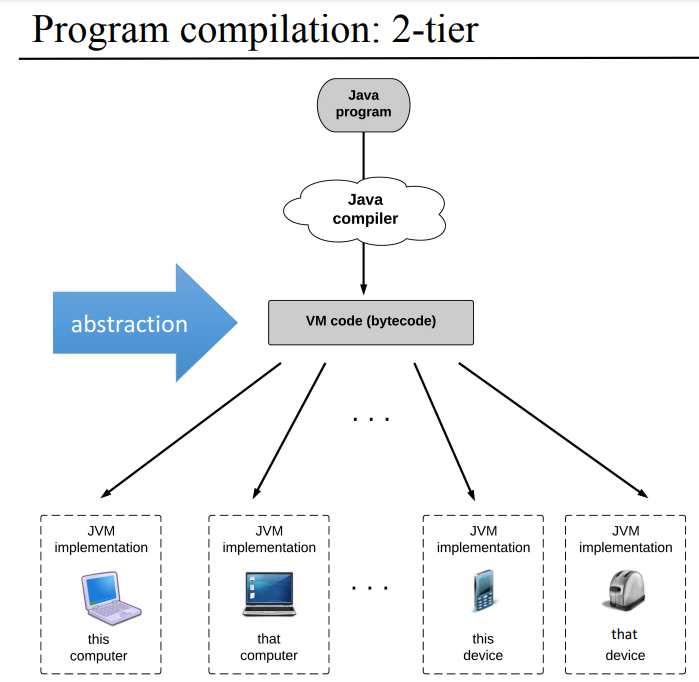 |
1단계 컴파일에다가 gcc 예시를 갖다 붙이려 했는데 번거로울거같아서 그냥 생략하고, Atmega 128같은 마이크로 프로세서에다가 컴파일 해서 짚어넣으려고 하면 각 타겟 보드/플랫폼이 뭔지 선택해야하는데 각 타겟에 맞는 컴파일러를 써야하는게 1단계 컴파일의 특징이고
2단계 컴파일 같은 경우에는 자바로 프로그램 짜고 컴파일을 시키면 바이트 코드라고 하는 가상머신 코드(중간 언어)가 나오는데, 이걸 각 플랫폼에 맞게 구현한 JVM에 돌리면 프로세스가 동작할수 있는게 특징이 된다. 아, 다시 정리하면 2단계 컴파일에서 1번째 번역기를 컴파일러, 2번째 번역기를 가상머신(번역기)가 된다.
근데 이렇게 적었지만 여전히 각 플랫폼에 맞는 컴파일러를 작성한거나, 각 플랫폼에 맞는 JVM 을 만들어서 돌리는거나 결국에는 둘다 각각 컴파일러랑 가상머신이 필요하다는 점에서 뭔 차이인가 싶어서 그렇게 와닿지는 않는다. 책에서 계속 2단계 쓰는게 효율적이라고는 하는데, 각 플랫폼 컴파일러 짜는것 보다는 가상머신 만드는게 일이 적어서 그런건지. 아무튼 뒷부분에 역사적인 배경이 나오긴 하는데 그걸 다시 봐야 더 이해할수 있을거같다.
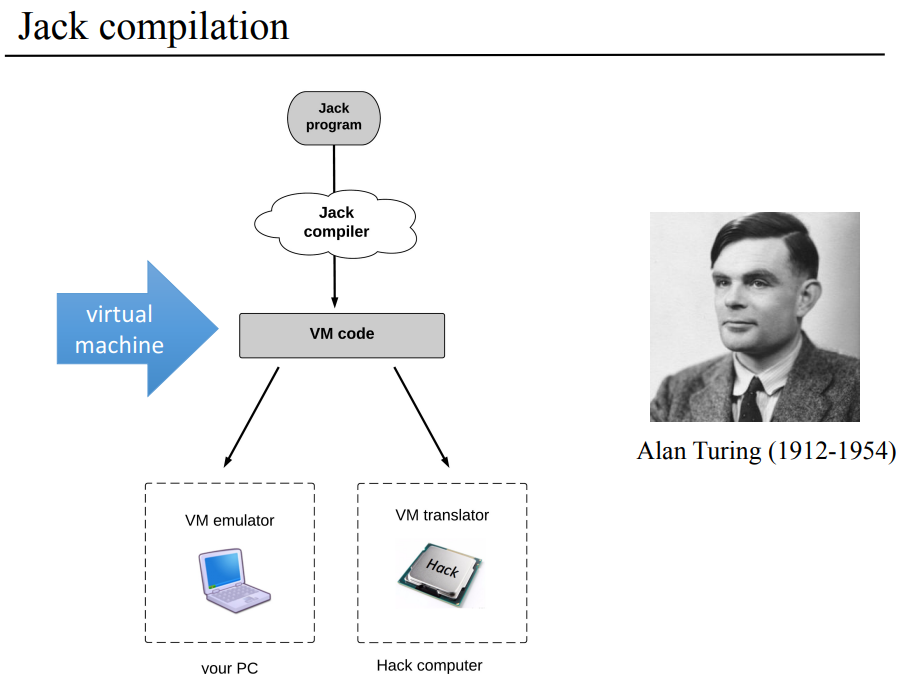
이 책을 보면서 7장에서 가장 햇갈렷던 부분에 VM 에뮬레이터랑 VM 번역기였는데, PPT로 보니까 좀 다르기는 하네. 글 순서에는 맞진 않는데 HACK 컴퓨터에 맞는 기계어를 만드는게 VM 번역기고, 지금 사용하는 PC에서 JACK 중간 언어를 돌릴수 있게하는게 VM 에뮬레이터인거같다. 잠깐 든 생각은 넘어가고 여기서 우선 VM 추상화? 추상 모델에 대해서 정리하면서 VM이 어떻게 된건지 어떻게 동작하는지를 보고 HACK에 맞는 VM 번역기 프로그램 구현에 대해서 다루게 된다.
그래서 계속 VM 코드가 나오는데 VM 코드는 산술, 논리 연산과 메모리 제어 명령인 push와 pop, 분기 명령, 함수 호출 반환 명령 등으로 이뤄져 있다. 이 장에서는 기본 VM 번역기를 만들면서 산술논리연산과 push/pop 연산을 다루고, 다음 장에서는 분기와 함수 관련 명령을 배워 기본적이지만 완전한 가상 머신을 구현하게 된다. 그리고 이번 장에서 가장 중요한 스택의 동작 과정을 정리해보자.
스택 머신과 동작 과정
저자 분은 앞으로 VM 코드는 컴파일러로 쉽게 생성할수 있을 만큼 충분히 "고급 언어에 가까"워야 하며, VM 번역기로 효율적으로 기계어를 생성할 수 있을 만큼 "저급"이 아니라 "기계어에 가까워야" 한다고 한다. 즉, VM 코드는 고급어와 저급어의 차이를 잘 매꿔줘야 하는데 이를 가장 잘 정리할수 있는 자료 구조가 스택이며, 이 스택으로 번역 과정을 처리하는 아키텍처/구조를 스택머신이라고 한다.
스택이 어떻게 된건지, 연산하는건지는 자료구조 공부하면 나오는거니 그냥 넘어가고, VM code를 stack에서 어떻게 산술 논리 연산을 하는지 보면
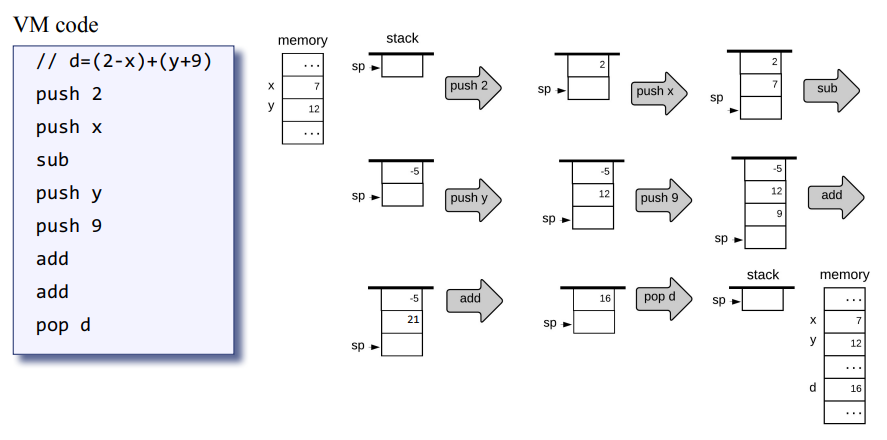
우선 산술 d = (2-x) + (y+9) 라는 산술연산의 과정을 보자.
1. push 2 : sp에 상수 2가 들어간다.
2. push x : sp에 변수 x의 값이 들어간다.
3. sub : 스택 최상위 2개의 값을 매개변수로 받아 뺀다. 2 - x
4. push y : sp에 변수 y의 값이 들어간다
5. push 9 : sp에 상수 9가 들어간다.
6. add : 스택 최상위 값인 y와 9를 꺼내 +연산 후 결과인 21를 push 한다
7. add : 최상위에 있는 -5와 21를 pop 한 뒤 -한 결과인 16을 push 한다.
8. pop d : 최상위에 있는 값을 pop 하여 메모리 변수 d 공간에 넣는다.
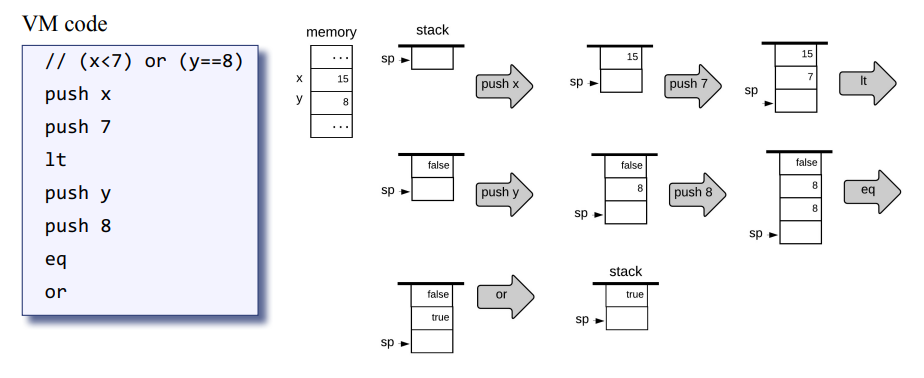
이번에 논리 연산 경우를 보자.
과정인 산술 연산과 동일하지만
논리 연산의 결과 true, false가 push 된다.
가상 메모리 세그먼트
특히 이 부분이 부족한 영어 실력으로 봐도 봐도 이해가 잘안가는 부분이었는데, ppt를 같이 봐야 이해가 좀 쉽더라

일단 메모리 세그먼트를 보기에 앞서 고급 언어를 공부하면 변수로 위의 소스코드 처럼 클래스 단의 static 변수나 함수 선언 문의 매개변수, 그리고 함수 안의 지역변수, 그리고 각 인스턴스의 속성 field 변수 등이 있다고 배웠을 것이다.
하지만 JVM이나 hack 플랫폼에서는 위의 s1, s2, a, b, c같은 심볼릭한 변수를 사용하지 않고, 가상 메모리 세그먼트의 일부로 표현하는데 이게 무슨소리냐면 static int s1, s2가 있으면 이 변수를 s1, s2라는 이름이 아닌 static 0, static 1 같은 식으로 변수로 사용하며, static 외의 변수 argument, local, static, constant, this, that, pointer도 뒤에 해당 변수의 번호를 붙여 쓴다.
예를 들어 지역 변수 x가 local 1, 인스턴스 속성 y를 this 3이라 할때 let x = y를 한다면, 스택에다가 y라는 값을 넣은 후(push), 스택의 값을 꺼내서(pop) x에다가 저장해야한다. 다시 정리하면 let x = y 연산은 아래와 같다.
push this 3 // 인스턴스 속성 변수 y(=this 3)을 스택에 넣어라
pop local 1 // 지역 변수 x(local 1)에다가 스택 최상위 값을 꺼내서 넣어라
위 내용만 봐서 가상 메모리 세그먼트가 뭔가 싶은데, ram 안에 argument, local, static, constant, this, that 등 각각의 메모리 세그먼트(일부 공간)이 존재한다고 보면 될거같다. 아래의 그림을 보면 이해가 더 잘될거 같은데 고급 언어 코드가 어떻게 VM 코드로 변환되는지 각 가상 메모리 세그먼트와 같이 정리되어있다.
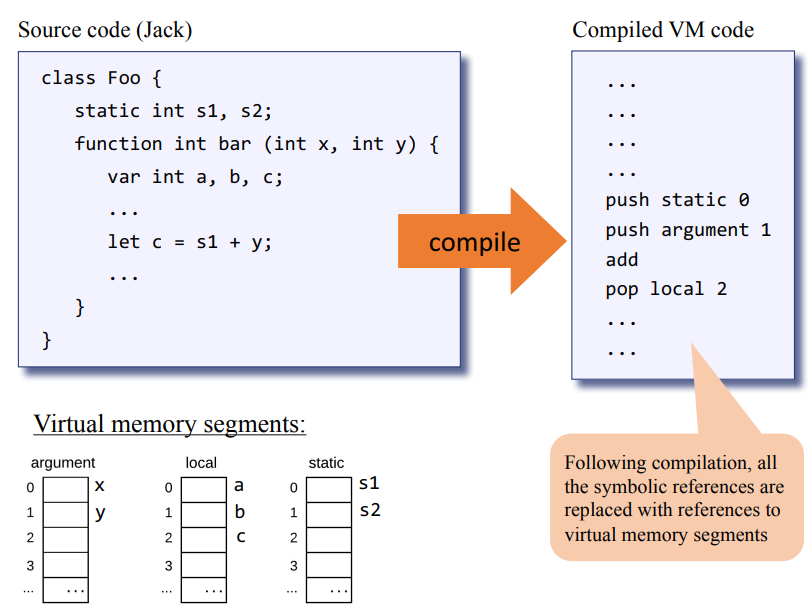
그러면 위 그림의 고급언어 소스코드 let c = s1 + y; 부분을 컴파일한 VM Code 결과가 우측과 같이 된다.
차례를 정리하면 우측 항(s1 + y)를 한 후 좌측 항(let c)에다가 대입 해야하므로 다음과 같이 정리할수 있을거같다.
s1 + y 연산
1. push static 0 // static 가상 메모리 세그먼트의 0번째 값(s1)을 stack에다가 넣는다.
2. push argument 1 // argument 가상 메모리 세그먼트의 1번째 값 y를 넣어라.
3. add // stack 최상단 2개 값을 꺼내(pop), 덧셈 연산한 뒤에 스택에다가 다시 넣어라(push).
let c = s1 + y 연산
4. pop local 2 //스택 최상단 값(s1 + y)을 꺼내 local 2에다가 넣어라
스택 연산과 가상 메모리 세그먼트
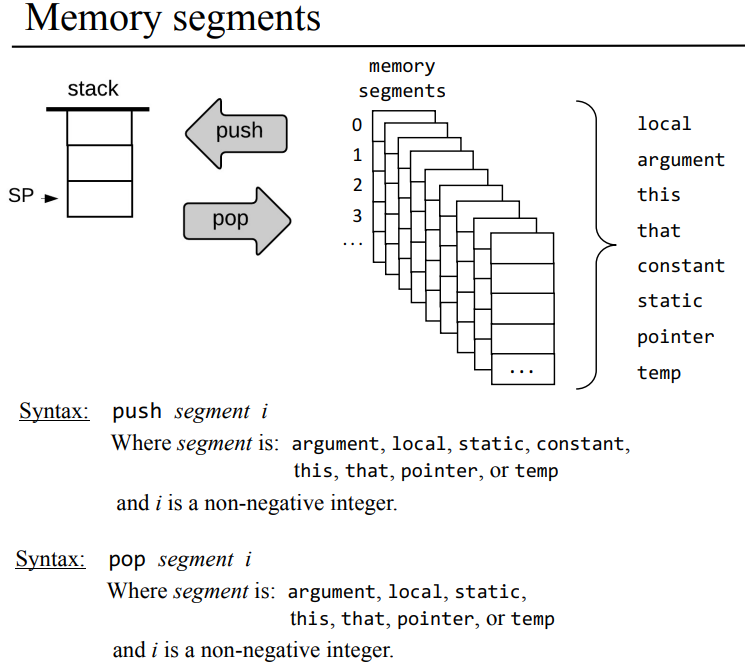
스택과 가상 메모리 세그먼트 두가지만 놓고 본다면 위 처럼
push segment i
pop segment i
같은 문법으로 스택과 메모리 세그먼트 간에 값을 넣고, 꺼내고의 연산이 수행된다.
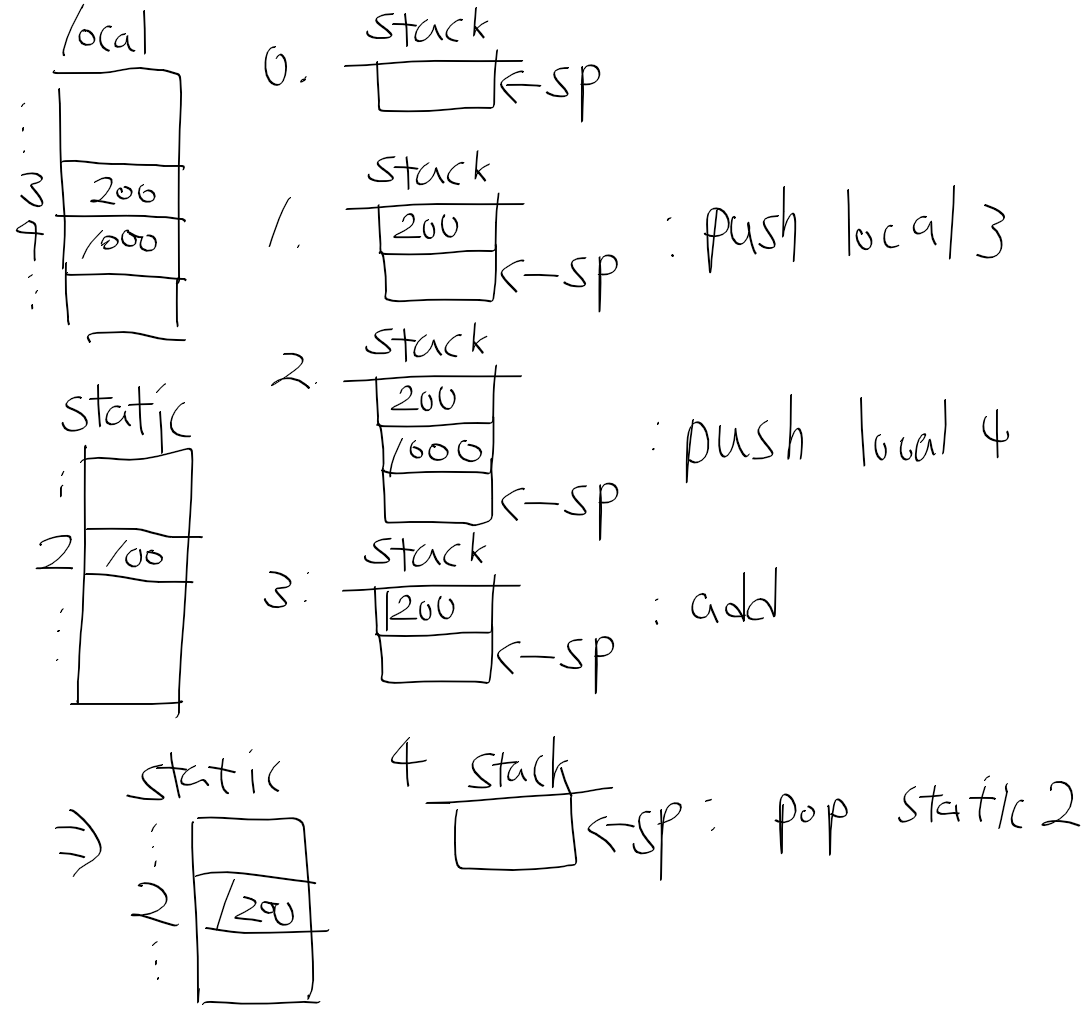
로컬 메모리 세그먼트의 3번지 값(200)과 4번지 값(1000)을 더한 후 static 메모리 세그먼트의 2번지에다가 넣는다면 다음과 같이 쓸수 있을거같다. (진작에 PPT랑 같이 볼껄, 괜히 잘 이해도 안되면서 그동안 책만 보느라 너무 해맨거같다.)
push local 3
push local 4
add
pop static 2
타겟 플랫폼(HACK)을 고려한 VM 구현
앞서 언급한 VM과 스택 머신에 대한 내용은 특정한 하드웨어 플랫폼을 고려하지 않은 추상화/요약한 것이라. 실제로 만들어 내려면 특정 하드웨어 플랫폼을 고려해서 표현해야 한다. 여기서는 VM 번역기를 구현하려고 하는데, 이를 만들려면 스텍과 타겟 플랫폼의 가상 메모리 세그먼트를 어떻게 할것인지를 고민해야하고, 또 VM 코드를 어떻게 타겟 플랫폼의 저급언어인지를 정리해야한다.
추상화와 구현의 차이 : 다시 정리하자면 이 앞의 내용은 VM 코드를 타겟 플랫폼의 어셈블리어를 고려하지 않은체 어떤 가상 메모리 세그먼트가 있고, 어떻게 연산할 것인지 대략적으로 정리했는데 어느 플랫폼에 한정하지 않고 대략적인 동작을 정리한 앞의 내용들을 VM 추상화 한것이라 하고, VM 코드와 타겟 플랫폼의 어셈블리어를 고려해서 맞춰 나가는걸 VM 구현이라 하는 거 같다.
만들고자 하는 플랫폼이 폰 노이만 아키텍처를 따르고, VM 스택이 메모리 공간의 블록이며 이 VM 스택 블록은 고정된 베이스 주소에서 시작한다고 하자. 그리고 스택이 쌓일 수록(= 위에서 스택 연산 그림처럼 내려가는걸) RAM 상의 주소가 증가하고, 스택을 초기화/처음 만들면 스택 포인터를 스택 베이스로 지정해놓자.
그러면 이제 vm 코드인 push x과 pop x를 슈도 코드로 다음과 같이 표현 할수있다.
RAM[sp++] = x // push x = RAM[sp]에다가 x를 대입 후 sp를 1증가시켜라
x = RAM[sp--] // pop x = 변수 x에다가 RAM[sp]를 대입 후 sp를 1 낮춰라
이렇게 슈도 코드를 작성했으니 이번에는 이걸 어셈블리어로 표현시켜보자. 우리가 만들 HACK 컴퓨터는 스택 베이스 주소를 256로 잡고 있다. 그래서 SP = 256으로 설정해서 어셈블리어로 스택 초기화부터 시켜주면
@256
D=A
@SP
M=D
를 하면 SP 라는 가상 메모리 레지스터(R0)에다가 스텍 베이스 어드레스 256가 등록된다.
=> RAM[0] = 256 // ram 0번지가 스택 포인터이며, 베이스 어드레스 256 등록
그럼 이제 push x와 pop x는 아래의 연산이므로
1. RAM[256] 번지에 x를 넣고, sp++
2. RAM[256] 번지 값을 변수 x에다 넣고, sp --
어셈블리어로 표현하면 다음과 같을거 같다(책에 있는게 아니라 그냥 내가 짠거라 맞는지는 모르겠지만 대강 고급 언어랑 비슷한 슈도 코드를 위 SP 초기화 부분을 참고해서 이렇게 어셈블리어로 써봤다.)
1. RAM[SP++] = x
@x
D=M
@SP
A=M //SP(RAM[0])에 있는 값인 M(256)을 꺼내서 어드레스 레지스터 A에다가 넣어라
M=D //RAM[256]번지에 데이터 레지스터의 값(변수 x의 값)을 넣어라
@SP
M=M+1 //SP++
**
@SP
M=D
위 코드처럼 해버리면 R[0] = D가 되버리는거같아서 @SP에 있는 값인 256을 어드레스 레지스터 A에다가 담은 후 M으로 RAM[256]에 접근해 RAM[256] =D가 되도록 썻다.
2. x = RAM[SP--]
이 코드의 경우 현재 SP가 257이지만 꺼내고자하는 값은 257번지가 아닌 256번지에 있으므로 SP--와는 다르게 먼저 SP부터 -1해주자
@SP
M=M-1 // SP-- => SP가 257에서 256이 된다.
@SP
A=M //어드레스 레지스터에 256을 넣어 RAM[256]에 접근가능하도록하자
D=M // RAM[256]의 값을 데이터 레지스터에 저장한 뒤
@x
M=D // 변수 x에 데이터 레지스터에 저장해둔 RAM[256]의 값을 넣자
내가 책만 보고 이해한 내용은 위와 같은데 강의 자료에서는 그림과 같이 보기 좋게 추상화와 구현을 보여주고있다.
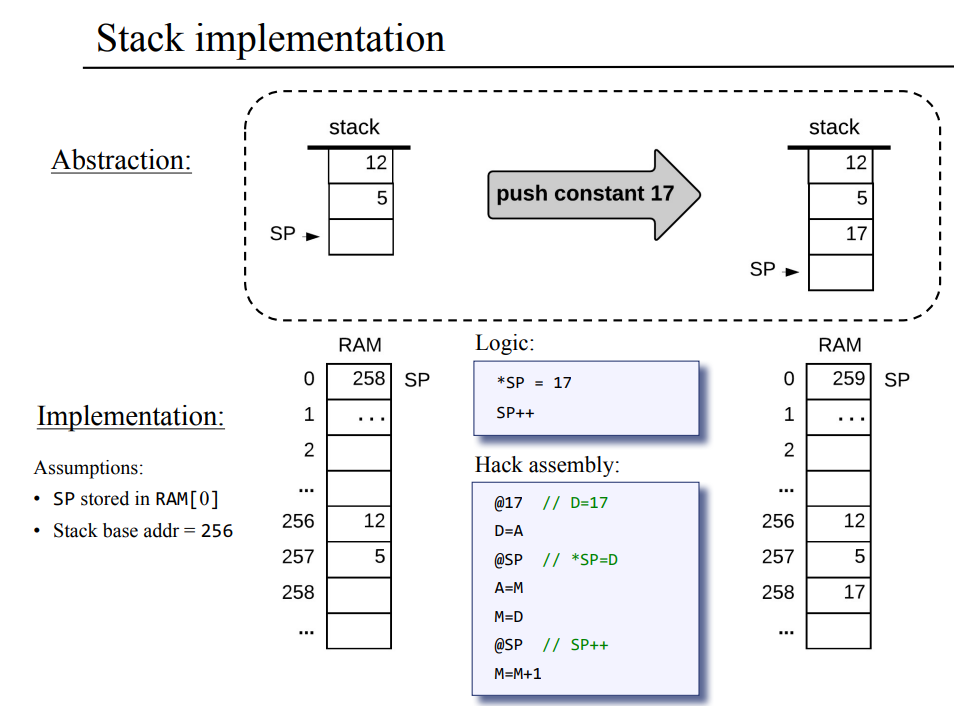
위 그림에서 보면 위의 abstaction 부분에서 push constant 17이라는 추상화된 VM 명령을
아래의 구현 파트에서 HACK 플랫폼에 맞게 어셈블리어로 정리하여 보여주고 있다.
구현 파트의 좌측 메모리를 보면 스택 포인터가 258을 가리키고, 258번지는 비어있었으나
push constant 17을 한 결과 sp는 259으로 +1이 되고, 스택 포인터가 가리키던 258번지에 17이 들어가 져있다.
다시 정리하자면 이와 같이 추상적인 VM 명령어들로 특정한 타겟 하드웨어에 맞는 저급언어를 만들어 내는것을 VM 구현 혹은 VM 번역기라 한다.
VM 프로그램
VM 프로그램은 다음 장에서 제대로 정리할거지만 VM 명령으로 이뤄진 프로그램이고, 확장자는 .vm으로 한다. 이 프로그램은 가상 머신 번역기로 한줄 한줄 읽어서 저급 언어로 번역되어 foo.vm을 번역후에는 foo.asm 파일이 나오게 된다.
가상 머신과 RAM
앞 장에서 이미 봤었지만 Hack의 RAM은 32K 16비트 워드로 이뤄져 있었다.(하드웨어 만들때 16K RAM에다가 8K 스크린, 1개의 키보드 레지스터를 합쳐서 만들었던거 같긴한데 그냥 넘어가자) 여기서 RAM 주소 상 0 ~ 15는 가상 레지스터, 16 ~ 255는 정적 변수, 256 ~ 2047 은 스택 영역으로 사용하고 있으며, RAM[0]에서 RAM[4]번지 까지를 SP, LCL, ARG, THIS, THAT이라는 심볼릭한 변수 명으로 접근해서 쓸수 있고 이 주소들에 대한 내용은 아래의 표를 참고하자.
| 이름 | 위치 | 내용 |
| SP | RAM[0] | R0으로도 접근 가능하며, 스택 포인터 역활로 처음에는 스택 베이스 어드레스 256을 넣어 초기화한다. |
| LCL | RAM[1] | local 메모리 세그먼트의 베이스 주소를 담는다. |
| ARG | RAM[2] | argment 메모리 세그먼트의 베이스 주소를 담는다. |
| THIS | RAM[3] | this segment의 베이스 주소를 담는다. |
| THAT | RAM[4] | that segment의 베이스 주소를 담는다. |
| TEMP | RAM[5-12] | temp segment |
| R13, R14, R15 | RAM[13-15] | VM 번역기로 어셈블리어 코드 생성 시 별도 변수가 필요한 경우 이 레지스터를 쓴다. |
local 메모리 세그먼트 구현
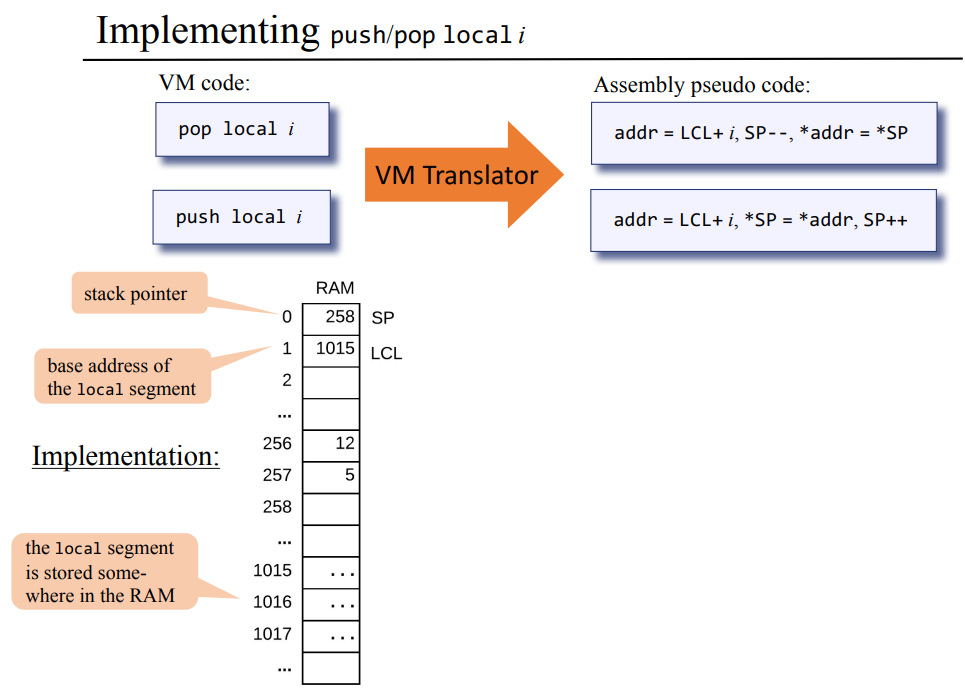
앞서 스택의 상수 연산을 어셈블리어를 통해 구현한것 처럼 로컬 변수를 사용한 VM code를 번역한 결과 우측의 어셈블리 슈도 코드처럼 만들수 있다. 실제 위 슈도 코드를 어셈블리어로 정리하는건 시간 부족으로 그냥 생략하고 넘어간다. 그래도 잠깐 내용을 언급하고 넘어가면 LCL은 RAM[1]에 위치하고 있으며 베이스 어드레스가 1015가 된다.
LCL의 경우 값을 넣거나 뺄때마다 +1 혹은 -1 되던 SP와는 다르게 항상 고정된 값, 로컬 메모리 세그먼트의 베이스 주소를 가지고 있고 이 값은 변하지 않는다. 대신 pop/push local i 명령어가 올때마다 addr=LCL + i를 하듯이 기존 베이스 어드레스에서 해당 로컬 변수의 번호를 더한 주소에다가 값을 넣거나 가져온다.
다시말하면 LCL은 1015인 베이스 주소를 가지고 있고, push local 1을 한다면 addr = LCL+1, *SP = *addr, SP++ 연산을 하는데, RAM[1016]의 값을 스택 포인터가 가리키고 있는 위치에다가 대입하고, SP를 ++한다.
local, argument, this, that 메모리 세그먼트가 필요한 이유
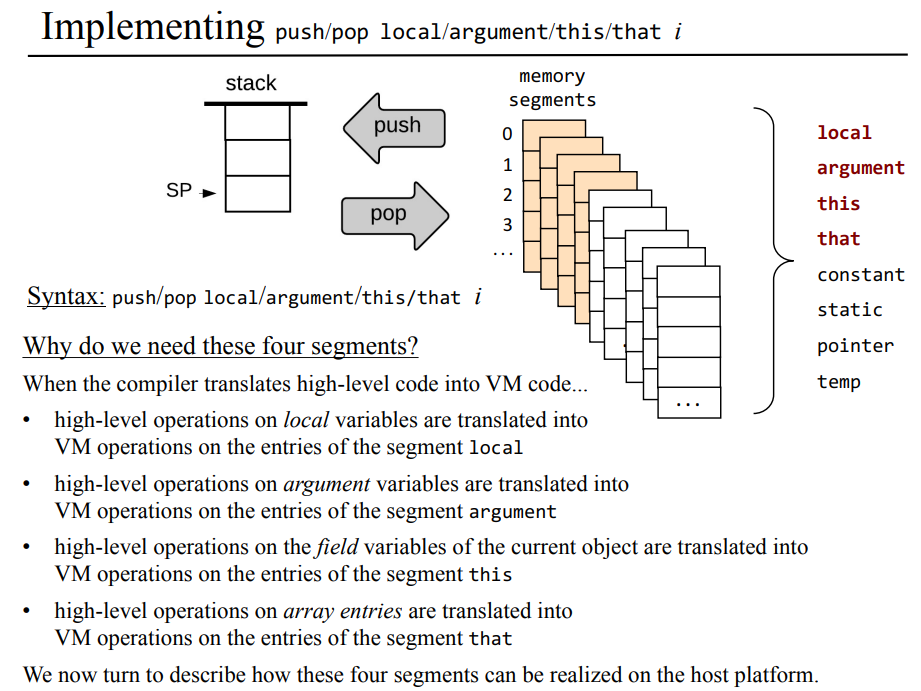
결국에는 이런식으로 메모리의 일부, 세그먼트를 만들어서 사용하는 이유는 뭘까. 각 가상 메모리 세그먼트 이름에서 알 수 있다시피 local 세그먼트는 로컬 변수들을 보관하기 위해서, argument는 매개변수를 보관하기 위해서 this의 경우 현재 객체의 속성값을 다루기 위해서, that은 각 객체들(인가?)을 배열 처럼 다루기 위해서 만든 공간인거 같다.
이번 장을 공부하면서 아직 제대로 파지 않은 부분도 있고, VM 구현도 하기는 해야되지만 한동안은 이론 내용을 전체적으로 전보다는 좀 빠르게 훑어보려고 한다. 그래도 책만 아니라 PPT도 같이 본 더분에 많은 내용이지만 생각보다 빠르게 진도 나갈수가 있었다.
7장 VM 동작
1. 스택 머신
2. 메모리 세그먼트
3. VM 추상화와 구현
이번 장에서 정리한걸 크게 구분하면 위 세가지가 될거같고, 어느 정도 이해한거 같으니 이제 넘어가자.
'컴퓨터과학 > 디지털회로' 카테고리의 다른 글
| nand2tetris - 17. 가상 머신을 이용한 제어 2 - 함수 (0) | 2022.05.24 |
|---|---|
| nand2tetris - 16. 가상 머신을 이용한 제어 1 - 분기 (0) | 2022.05.23 |
| nand2tetris - 14. hack 어셈블러 구현(pass) (0) | 2022.05.23 |
| nand2tetris - 13. hack 어셈블러 이론 (0) | 2022.05.20 |
| nand2tetris - 12. HACK 컴퓨터 구현하기 2(완성) (0) | 2022.05.19 |