블라즈 핸드 사용하기위해
어파인 변환된 이미지와 역어파인변환 행렬, ROI 까지 준비다되었고
이제 블라즈핸드 추론 시작하면된다.
일단 파이썬으로
cvdnn로 블라즈 핸드 검출 결과를 출력시켜봄
import cv2
import time
import numpy as np
import traceback
def get_color_filtered_boxes(image):
# 이미지를 HSV 색 공간으로 변환
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 살색 영역을 마스크로 만들기
skin_mask = cv2.inRange(hsv_image, lower_skin, upper_skin)
# 모폴로지 연산을 위한 구조 요소 생성
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9, 9))
# 모폴로지 열림 연산 적용
skin_mask = cv2.morphologyEx(skin_mask, cv2.MORPH_OPEN, kernel)
# 마스크를 이용하여 살색 영역 추출
skin_image = cv2.bitwise_and(image, image, mask=skin_mask)
# 살색 영역에 대한 바운딩 박스 추출
contours, _ = cv2.findContours(skin_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
bounding_boxes = [cv2.boundingRect(cnt) for cnt in contours]
# 크기가 작은 박스와 큰 박스 제거
color_boxes = []
for (x, y, w, h) in bounding_boxes:
if w * h > 100 * 100:
# 약간 박스 더크게
#color_boxes.append((x - 30, y - 30, w + 60, h + 60))
center_x = int((x + x + w) / 2)
center_y = int((y + y + h) / 2)
large = 0
if w > h:
large = w
if w < h:
large = h
large = int(large * 0.7)
color_boxes.append((center_x - large, center_y - large, 2 * large, 2 * large))
return color_boxes
def landmark_inference(img):
img = cv2.resize(img, (lm_infer_width, lm_infer_height))
tensor = img / 127.5 - 1.0
blob = cv2.dnn.blobFromImage(tensor.astype(np.float32), swapRB=False, crop=False)
net.setInput(blob)
preds = net.forward(outNames)
return preds
# 살색 영역의 범위 지정 (HSV 색 공간)
lower_skin = np.array([0, 20, 70], dtype=np.uint8)
upper_skin = np.array([20, 255, 255], dtype=np.uint8)
img_width = 640
img_height = 480
lm_infer_width = 256
lm_infer_height = 256
net = cv2.dnn.readNet('blazehand.onnx')
#net = cv2.dnn.readNet('hand_landmark.onnx')
outNames = net.getUnconnectedOutLayersNames()
print(outNames)
cap = cv2.VideoCapture(1)
while True:
time_start = time.time()
try:
roi = None
ret, frame = cap.read()
frame = cv2.resize(frame, (img_width, img_height))
skin_image = frame.copy()
# 크기가 작은 박스와 큰 박스 제거
color_boxes = get_color_filtered_boxes(skin_image)
# 바운딩 박스를 이미지에 그리기
for (x, y, w, h) in color_boxes:
cv2.rectangle(skin_image, (x, y), (x + w, y + h), (0, 255, 0), 2)
for idx, color_box in enumerate(color_boxes):
x, y, w, h = color_box
cbox_ratio_width = w / lm_infer_width
cbox_ratio_height = h / lm_infer_height
roi = frame[y:y+h, x:x+w]
preds = landmark_inference(roi)
if cv2.waitKey(1) == ord('q'):
break
time_cur = time.time()
cv2.putText(frame, f"time spend: {time_cur - time_start}", (0, 50), cv2.FONT_HERSHEY_SIMPLEX, 2, (125, 125, 125), 2)
#frame = cv2.resize(frame, (320, 240))
if roi is not None:
cv2.imshow('roi', roi)
cv2.imshow('Camera Streaming', frame)
cv2.imshow('Skin Extraction', skin_image)
except Exception as e:
traceback.print_exc()
cap.release()
cv2.destroyAllWindows()
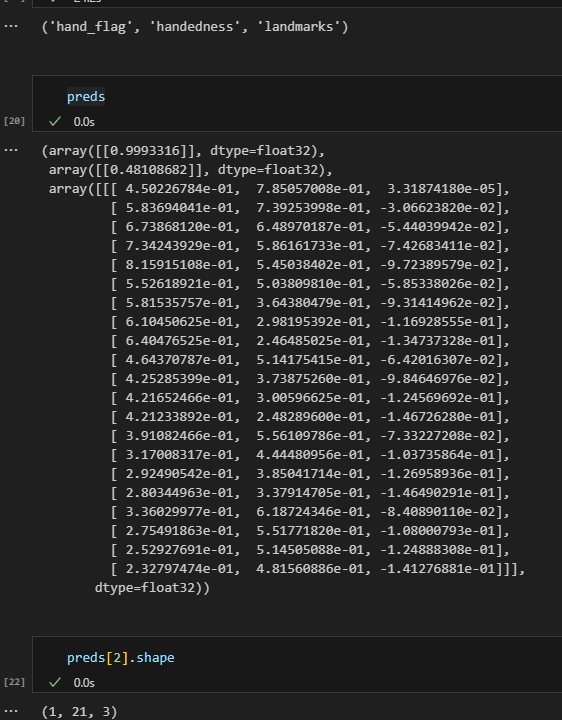
핸드 플레그와 핸디드니스 랜드마크가 나오는데
핸드플래그는 1에 가까운거봐서 손 점수일거같고
랜드마크는 1 x 21 x 3인거봐선 손 랜드마크 일듯 싶은데
핸드니스는 모르겟다.
미디어파이프파이토치 코드보면 여기도
플래그, 핸디드, 노말라이즈드 랜드마크로 받는다.
그 뒤에 보면 플래그는 손유무 점수가 맞아보이고
랜드마크를 그대로 반정규화후 드로잉해주는데 반정규화에는 역어파인변환 행렬을 사용한다.
내가 맨위에 사용한 코드의 경우
컬러박스로 손 검출해서 하는거라 어파인 행렬이 존재하지 않는다.
cv2.imshow("Image", image)
flags2, handed2, normalized_landmarks2 = hand_regressor(img.to(gpu))
landmarks2 = hand_regressor.denormalize_landmarks(normalized_landmarks2.cpu(), affine2)
for i in range(len(flags2)):
landmark, flag = landmarks2[i], flags2[i]
if flag>.5:
draw_landmarks(frame, landmark[:,:2], HAND_CONNECTIONS, size=2)
반정규화 랜드마크 코드보면 해상도(256)으로 곱해준후
랜드마크를 역어파인 변환 시켜주는 내용인듯 싶은데
일단 맨 위 코드에 반정규화 해서 시각화하는걸로 일단 작성해보면
(일단 해상도로만 반정규화시켜서 실제 입력이미지가 아닌 256 x 256에 맞는 좌표가 나올듯)
def denormalize_landmarks(self, landmarks, affines):
landmarks[:,:,:2] *= self.resolution
for i in range(len(landmarks)):
landmark, affine = landmarks[i], affines[i]
landmark = (affine[:,:2] @ landmark[:,:2].T + affine[:,2:]).T
landmarks[i,:,:2] = landmark
return landmarks
일단 기존의 데모 코드와 내가 만든 코드랑 섞어서 블라즈 핸드를 돌렸는데
좀 아쉬운 결과가 나옴 전처리 문젠것 같다
를 주석 했을땐 완전 망했는데
주석안하고 사용하니 좀 나아진걸 봐선 전처리 문젠거같기도하고

import cv2
import time
import numpy as np
import traceback
def get_color_filtered_boxes(image):
# 이미지를 HSV 색 공간으로 변환
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 살색 영역을 마스크로 만들기
skin_mask = cv2.inRange(hsv_image, lower_skin, upper_skin)
# 모폴로지 연산을 위한 구조 요소 생성
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9, 9))
# 모폴로지 열림 연산 적용
skin_mask = cv2.morphologyEx(skin_mask, cv2.MORPH_OPEN, kernel)
# 마스크를 이용하여 살색 영역 추출
skin_image = cv2.bitwise_and(image, image, mask=skin_mask)
# 살색 영역에 대한 바운딩 박스 추출
contours, _ = cv2.findContours(skin_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
bounding_boxes = [cv2.boundingRect(cnt) for cnt in contours]
# 크기가 작은 박스와 큰 박스 제거
color_boxes = []
for (x, y, w, h) in bounding_boxes:
if w * h > 100 * 100:
# 약간 박스 더크게
#color_boxes.append((x - 30, y - 30, w + 60, h + 60))
center_x = int((x + x + w) / 2)
center_y = int((y + y + h) / 2)
large = 0
if w > h:
large = w
if w < h:
large = h
large = int(large * 0.7)
color_boxes.append((center_x - large, center_y - large, 2 * large, 2 * large))
return color_boxes
def landmark_inference(img):
tensor = img / 127.5 - 1.0
blob = cv2.dnn.blobFromImage(tensor.astype(np.float32), swapRB=False, crop=False)
net.setInput(blob)
preds = net.forward(outNames)
return preds
def denormalize_landmarks(landmarks):
landmarks[:,:,:2] *= 256
return landmarks
def draw_landmarks(img, points, connections=[], color=(0, 255, 0), size=2):
points = points[:,:2]
for point in points:
x, y = point
x, y = int(x), int(y)
cv2.circle(img, (x, y), size, color, thickness=size)
for connection in connections:
x0, y0 = points[connection[0]]
x1, y1 = points[connection[1]]
x0, y0 = int(x0), int(y0)
x1, y1 = int(x1), int(y1)
cv2.line(img, (x0, y0), (x1, y1), (0,0,0), size)
HAND_CONNECTIONS = [
(0, 1), (1, 2), (2, 3), (3, 4),
(5, 6), (6, 7), (7, 8),
(9, 10), (10, 11), (11, 12),
(13, 14), (14, 15), (15, 16),
(17, 18), (18, 19), (19, 20),
(0, 5), (5, 9), (9, 13), (13, 17), (0, 17)
]
# 살색 영역의 범위 지정 (HSV 색 공간)
lower_skin = np.array([0, 20, 70], dtype=np.uint8)
upper_skin = np.array([20, 255, 255], dtype=np.uint8)
img_width = 640
img_height = 480
lm_infer_width = 256
lm_infer_height = 256
net = cv2.dnn.readNet('blazehand.onnx')
#net = cv2.dnn.readNet('hand_landmark.onnx')
outNames = net.getUnconnectedOutLayersNames()
print(outNames)
cap = cv2.VideoCapture(1)
while True:
time_start = time.time()
try:
roi = None
ret, frame = cap.read()
frame = cv2.resize(frame, (img_width, img_height))
skin_image = frame.copy()
# 크기가 작은 박스와 큰 박스 제거
color_boxes = get_color_filtered_boxes(skin_image)
# 바운딩 박스를 이미지에 그리기
for (x, y, w, h) in color_boxes:
cv2.rectangle(skin_image, (x, y), (x + w, y + h), (0, 255, 0), 2)
for idx, color_box in enumerate(color_boxes):
x, y, w, h = color_box
cbox_ratio_width = w / lm_infer_width
cbox_ratio_height = h / lm_infer_height
roi = frame[y:y+h, x:x+w]
roi = cv2.resize(roi, (lm_infer_width, lm_infer_height))
preds = landmark_inference(roi)
landmarks = preds[2]
flag = preds[0]
denorm_landmarks = denormalize_landmarks(landmarks)
for i in range(len(flag)):
landmark, flag = denorm_landmarks[i], flag[i]
if flag>.5:
draw_landmarks(roi, landmark[:,:2], HAND_CONNECTIONS, size=2)
if cv2.waitKey(1) == ord('q'):
break
time_cur = time.time()
cv2.putText(frame, f"time spend: {time_cur - time_start}", (0, 50), cv2.FONT_HERSHEY_SIMPLEX, 2, (125, 125, 125), 2)
#frame = cv2.resize(frame, (320, 240))
if roi is not None:
cv2.imshow('roi', roi)
cv2.imshow('Camera Streaming', frame)
cv2.imshow('Skin Extraction', skin_image)
except Exception as e:
traceback.print_exc()
cap.release()
cv2.destroyAllWindows()
미디어파이프 파이토치 데모코드에서 입력으로 사용하는 이미지 125,125 포인트 출력하면
0 ~ 1사이 값이 나온다.
extract_roi에서 정규화에 대한 내용은 못봣는데
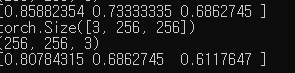
해매다 보니 전처리 과정 어캐해야하는지 이해됫다.
bgr2rgb 하고 /256으로 나눠주면 끝

import cv2
import time
import numpy as np
import traceback
def get_color_filtered_boxes(image):
# 이미지를 HSV 색 공간으로 변환
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 살색 영역을 마스크로 만들기
skin_mask = cv2.inRange(hsv_image, lower_skin, upper_skin)
# 모폴로지 연산을 위한 구조 요소 생성
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9, 9))
# 모폴로지 열림 연산 적용
skin_mask = cv2.morphologyEx(skin_mask, cv2.MORPH_OPEN, kernel)
# 마스크를 이용하여 살색 영역 추출
skin_image = cv2.bitwise_and(image, image, mask=skin_mask)
# 살색 영역에 대한 바운딩 박스 추출
contours, _ = cv2.findContours(skin_mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
bounding_boxes = [cv2.boundingRect(cnt) for cnt in contours]
# 크기가 작은 박스와 큰 박스 제거
color_boxes = []
for (x, y, w, h) in bounding_boxes:
if w * h > 100 * 100:
# 약간 박스 더크게
#color_boxes.append((x - 30, y - 30, w + 60, h + 60))
center_x = int((x + x + w) / 2)
center_y = int((y + y + h) / 2)
large = 0
if w > h:
large = w
if w < h:
large = h
large = int(large * 0.7)
color_boxes.append((center_x - large, center_y - large, 2 * large, 2 * large))
return color_boxes
def landmark_inference(img):
#tensor = img / 127.5 - 1.0
tensor = img / 256
blob = cv2.dnn.blobFromImage(tensor.astype(np.float32), swapRB=False, crop=False)
net.setInput(blob)
preds = net.forward(outNames)
return preds
def denormalize_landmarks(landmarks):
landmarks[:,:,:2] *= 256
return landmarks
def draw_landmarks(img, points, connections=[], color=(0, 255, 0), size=2):
points = points[:,:2]
for point in points:
x, y = point
x, y = int(x), int(y)
cv2.circle(img, (x, y), size, color, thickness=size)
for connection in connections:
x0, y0 = points[connection[0]]
x1, y1 = points[connection[1]]
x0, y0 = int(x0), int(y0)
x1, y1 = int(x1), int(y1)
cv2.line(img, (x0, y0), (x1, y1), (0,0,0), size)
HAND_CONNECTIONS = [
(0, 1), (1, 2), (2, 3), (3, 4),
(5, 6), (6, 7), (7, 8),
(9, 10), (10, 11), (11, 12),
(13, 14), (14, 15), (15, 16),
(17, 18), (18, 19), (19, 20),
(0, 5), (5, 9), (9, 13), (13, 17), (0, 17)
]
# 살색 영역의 범위 지정 (HSV 색 공간)
lower_skin = np.array([0, 20, 70], dtype=np.uint8)
upper_skin = np.array([20, 255, 255], dtype=np.uint8)
img_width = 640
img_height = 480
lm_infer_width = 256
lm_infer_height = 256
net = cv2.dnn.readNet('blazehand.onnx')
#net = cv2.dnn.readNet('hand_landmark.onnx')
outNames = net.getUnconnectedOutLayersNames()
print(outNames)
cap = cv2.VideoCapture(1)
while True:
time_start = time.time()
try:
roi = None
ret, frame = cap.read()
frame = cv2.resize(frame, (img_width, img_height))
skin_image = frame.copy()
# 크기가 작은 박스와 큰 박스 제거
color_boxes = get_color_filtered_boxes(skin_image)
# 바운딩 박스를 이미지에 그리기
for (x, y, w, h) in color_boxes:
cv2.rectangle(skin_image, (x, y), (x + w, y + h), (0, 255, 0), 2)
for idx, color_box in enumerate(color_boxes):
x, y, w, h = color_box
cbox_ratio_width = w / lm_infer_width
cbox_ratio_height = h / lm_infer_height
roi = frame[y:y+h, x:x+w]
roi = cv2.resize(roi, (lm_infer_width, lm_infer_height))
lm_input = cv2.cvtColor(roi, cv2.COLOR_BGR2RGB)
preds = landmark_inference(lm_input)
landmarks = preds[2]
flag = preds[0]
denorm_landmarks = denormalize_landmarks(landmarks)
for i in range(len(flag)):
landmark, flag = denorm_landmarks[i], flag[i]
if flag>.5:
draw_landmarks(roi, landmark[:,:2], HAND_CONNECTIONS, size=2)
if cv2.waitKey(1) == ord('q'):
break
time_cur = time.time()
cv2.putText(frame, f"time spend: {time_cur - time_start}", (0, 50), cv2.FONT_HERSHEY_SIMPLEX, 2, (125, 125, 125), 2)
#frame = cv2.resize(frame, (320, 240))
if roi is not None:
cv2.imshow('roi', roi)
cv2.imshow('Camera Streaming', frame)
cv2.imshow('Skin Extraction', skin_image)
except Exception as e:
traceback.print_exc()
cap.release()
cv2.destroyAllWindows()
블라즈팜도 언리얼에 비해서 잘된다.
패딩을 넣은게 문제인가

import cv2
import time
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def draw_rect(frame, regressor, classificator, stride, anchor_count, column, row, anchor, offset):
index = (int(row * 128 / stride) + column) * anchor_count + anchor + offset
score = sigmoid(regressor[index][0])
if score < 0.5: return
x, y, w, h = classificator[index][:4]
x += (column + 0.5) * stride - w / 2
y += (row + 0.5) * stride - h / 2
x = int(x)
y = int(y)
w = int(w)
h = int(h)
frame = cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 0, 0), 1)
net = cv2.dnn.readNet('palm_detection.onnx')
outNames = net.getUnconnectedOutLayersNames()
print(outNames)
cap = cv2.VideoCapture(0)
while True:
time_start = time.time()
ret, frame = cap.read()
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
frame = cv2.resize(frame, dsize=(128, 128))
#tensor = (frame / 127.5 - 1.0).reshape((128, 128, 3)).transpose(2, 0, 1)
tensor = (frame / 127.5 - 1.0).reshape((128, 128, 3))
print(tensor.shape)
blob = cv2.dnn.blobFromImage(tensor.astype(np.float32), swapRB=False, crop=False)
print(blob.shape)
#blob = cv2.dnn.blobFromImage(tensor.astype(np.float32), 1.0, (128, 128), (127.5, 127.5, 127.5), swapRB=True)
net.setInput(blob)
preds = net.forward(outNames)
regressor = preds[0]
classifier = preds[1]
"""
print(regressor.shape)
print(classifier.shape)
print()
"""
for y in range(16):
for x in range(16):
for a in range(2):
draw_rect(frame, regressor[0], classifier[0], 8, 2, x, y, a, 0)
for y in range(8):
for x in range(8):
for a in range(6):
draw_rect(frame, regressor[0], classifier[0], 16, 6, x, y, a, 512)
frame = cv2.resize(frame, dsize=(640, 480))
if cv2.waitKey(1) == ord('q'):
break
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
time_cur = time.time()
cv2.putText(frame, f"time spend: {time_cur - time_start}", (0, 50), cv2.FONT_HERSHEY_SIMPLEX, 2, (125, 125, 125), 2)
cv2.imshow('Camera Streaming', frame)
cap.release()
cv2.destroyAllWindows()
'컴퓨터과학 > 언리얼' 카테고리의 다른 글
| HandDesktop10 - blazehand c++, unreal 적용 (0) | 2024.01.29 |
|---|---|
| HandDesktop09 - 기존 문제들 원인 찾음, blaze 갈아엎기, 블라즈팜 문제해결 (0) | 2024.01.26 |
| HandDesktop07 - blaze hand 사용 준비하기 (0) | 2024.01.26 |
| HandDesktop06 - blaze palm 사용하기 (0) | 2024.01.25 |
| HandDesktop05 - 손 추정을 위한 blaze 추론 코드 살펴보기 (0) | 2024.01.24 |