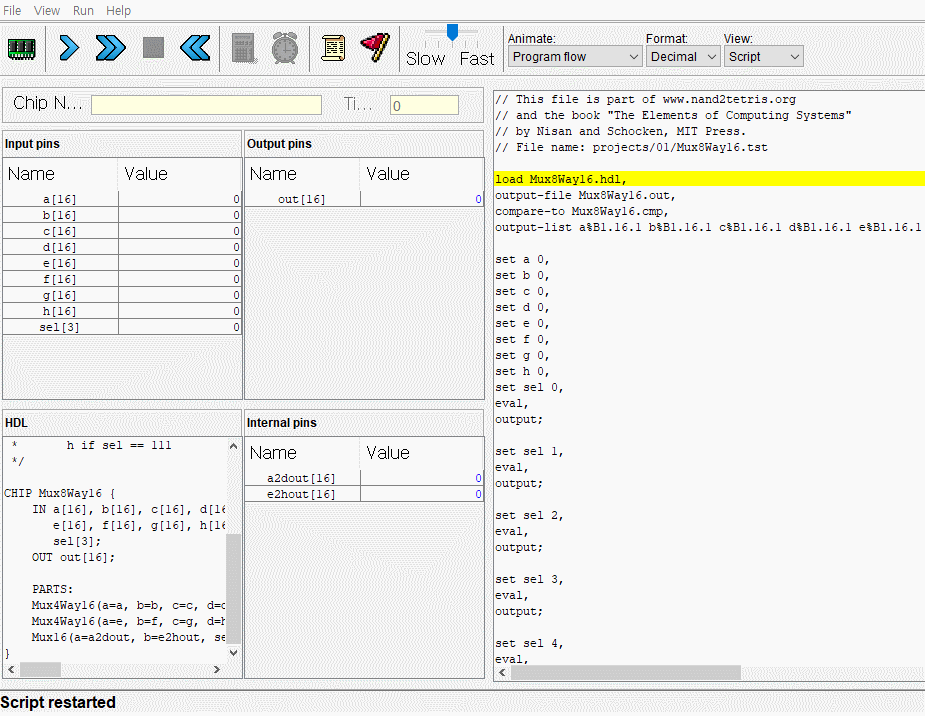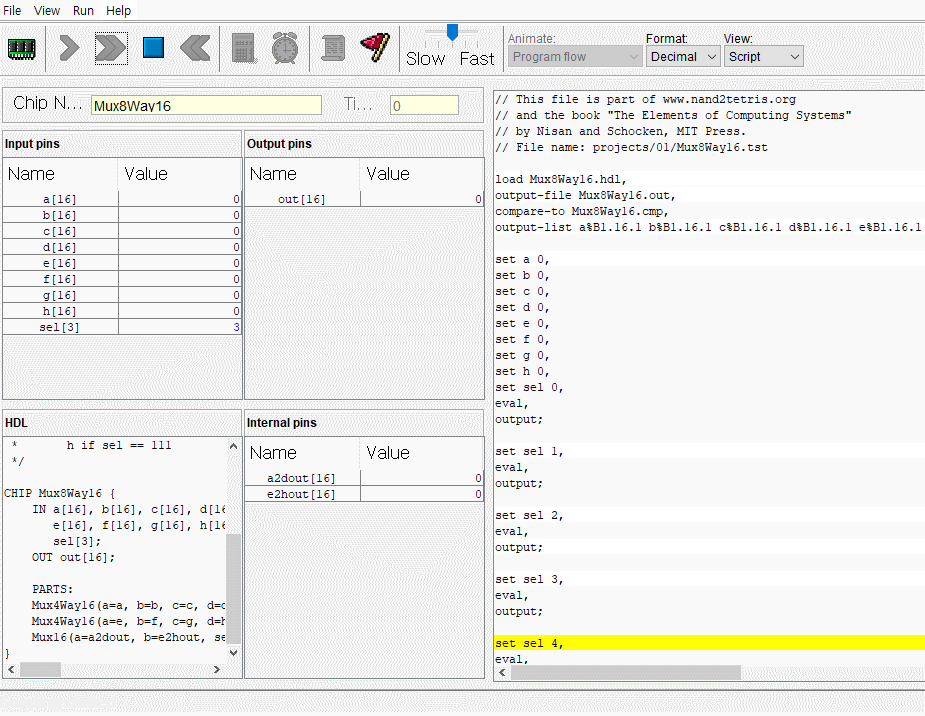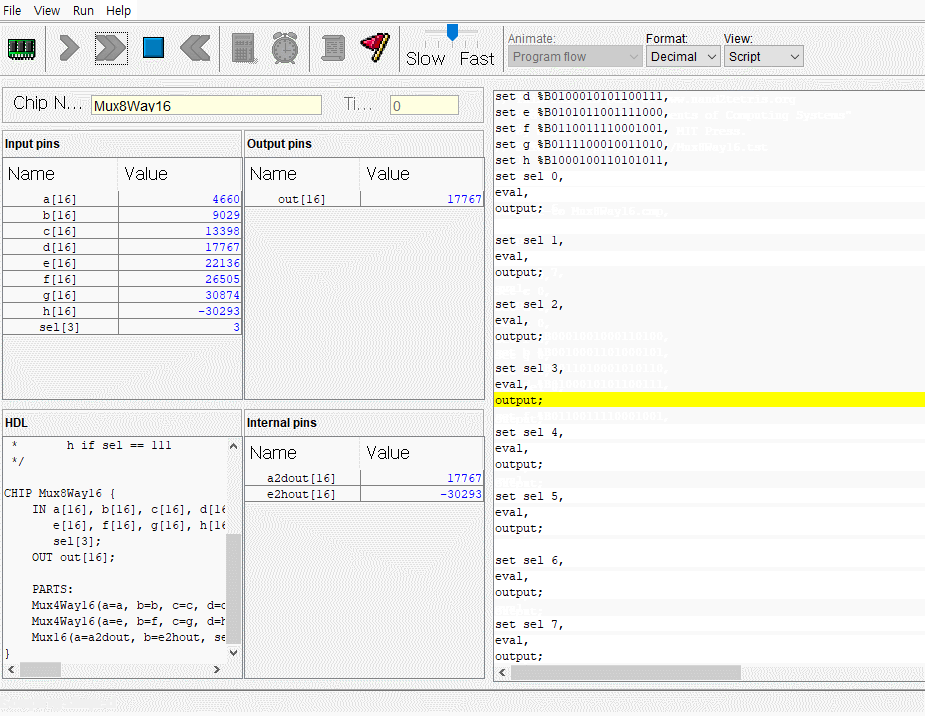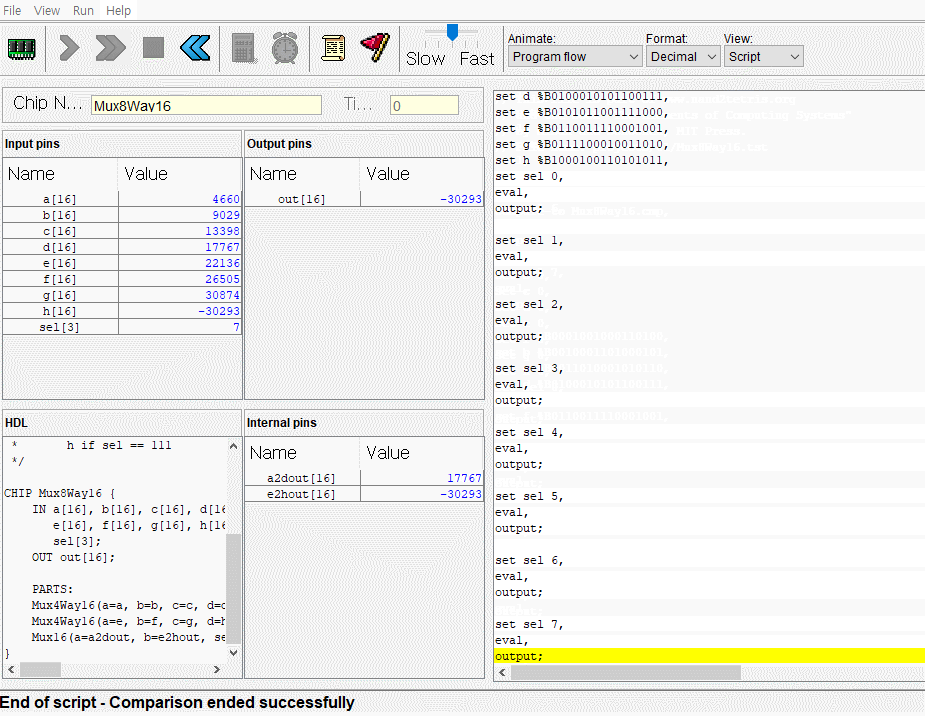
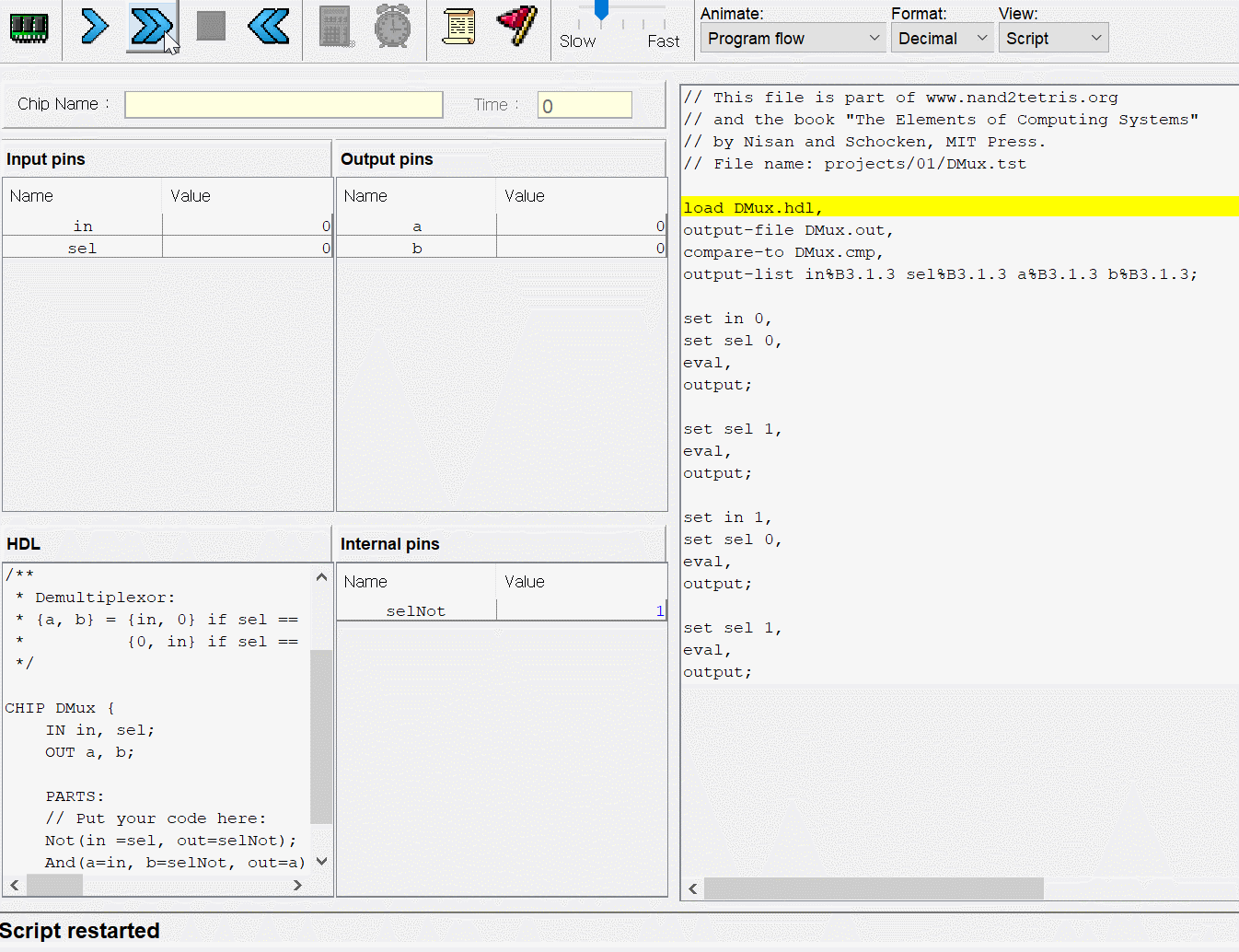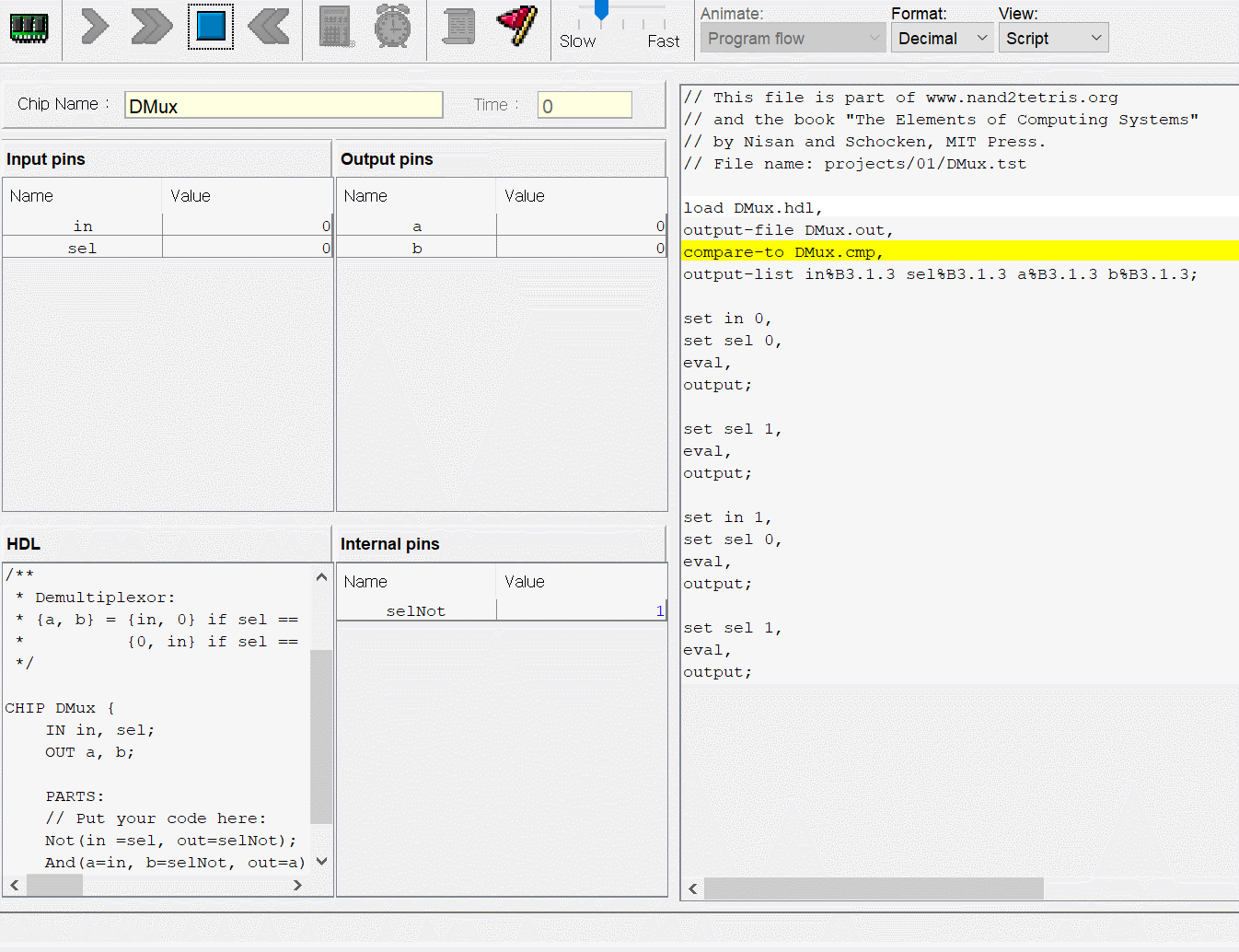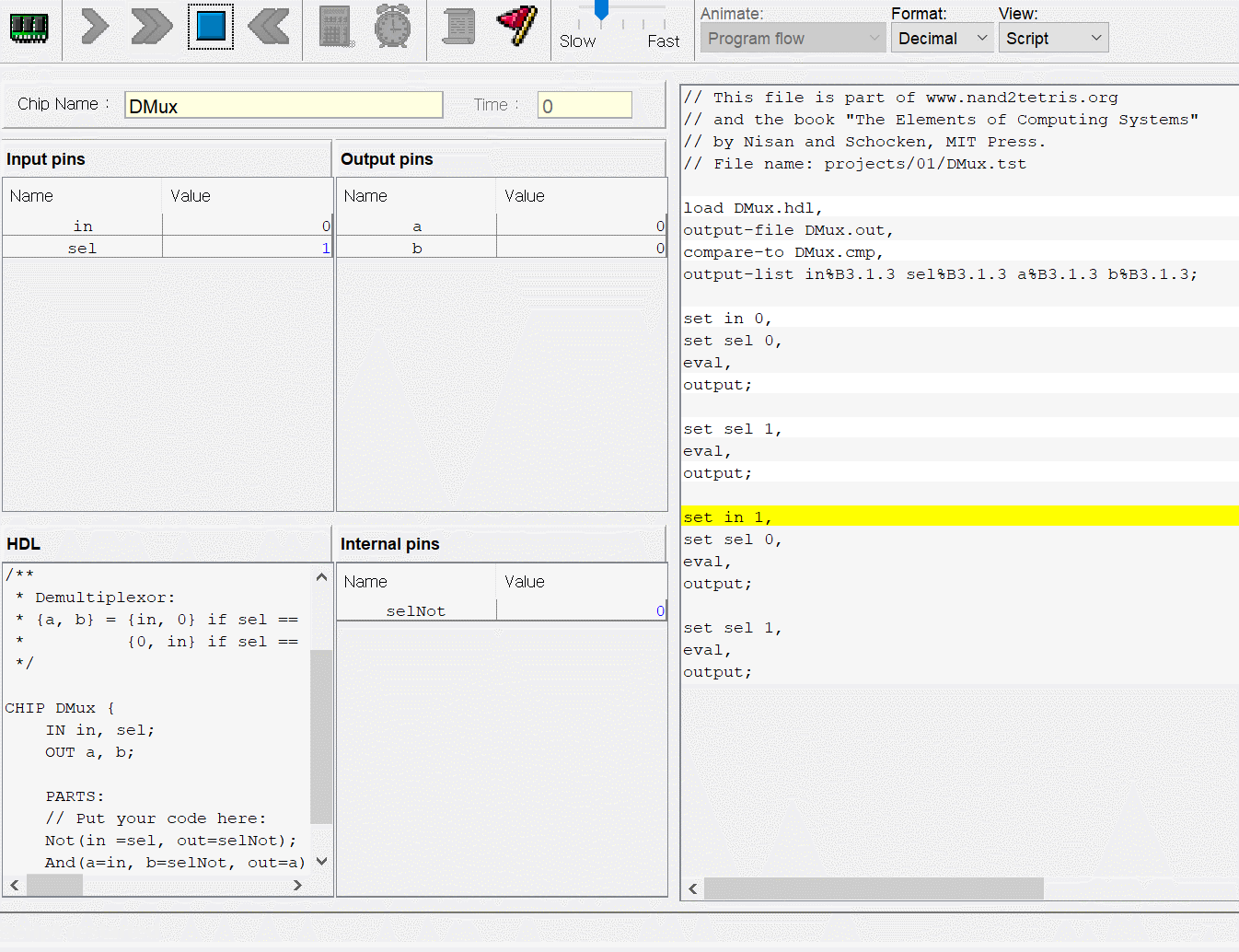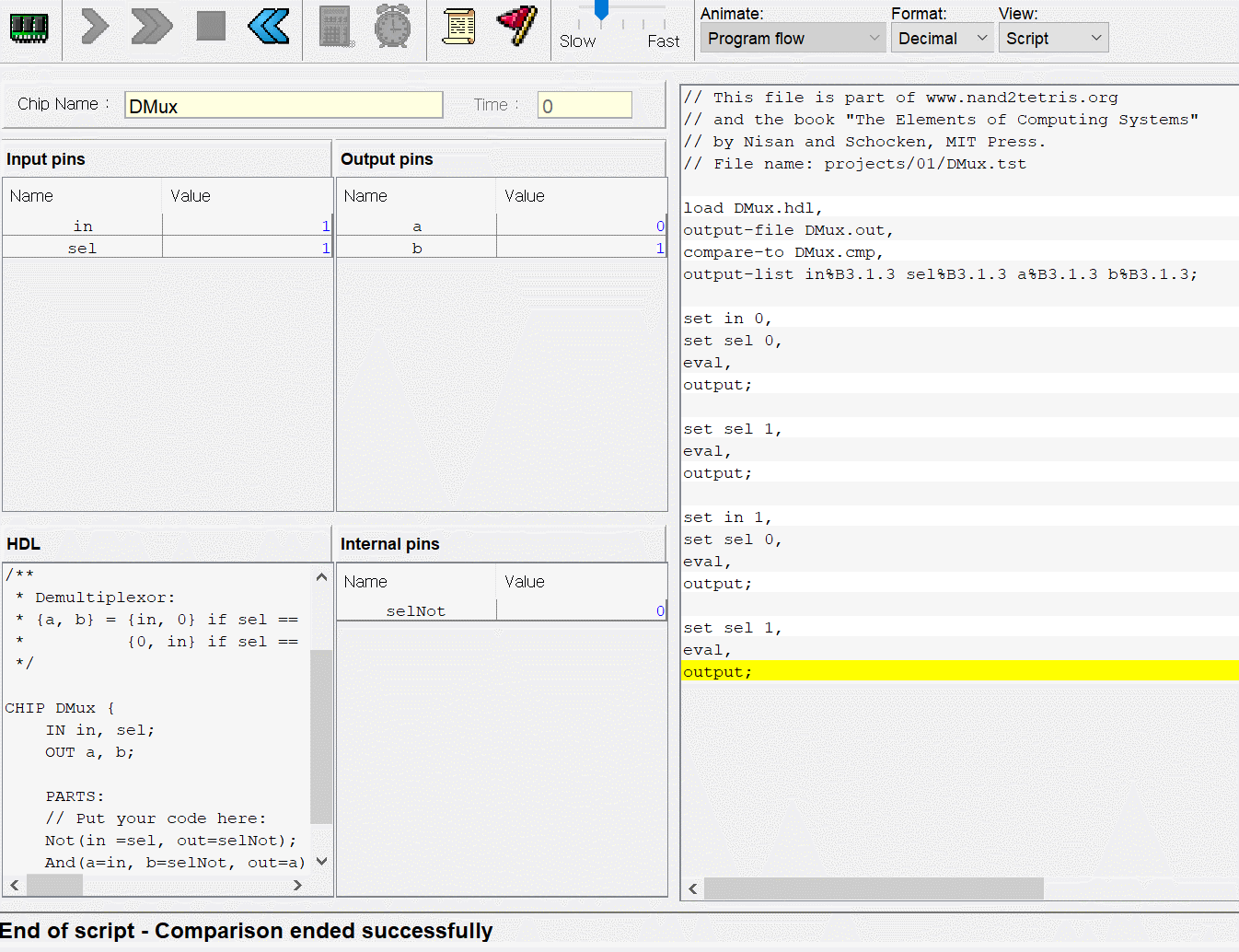
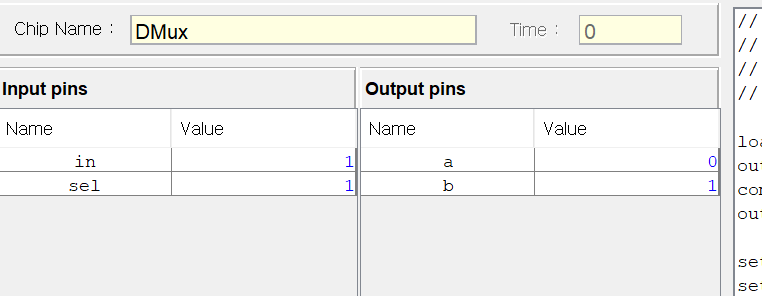
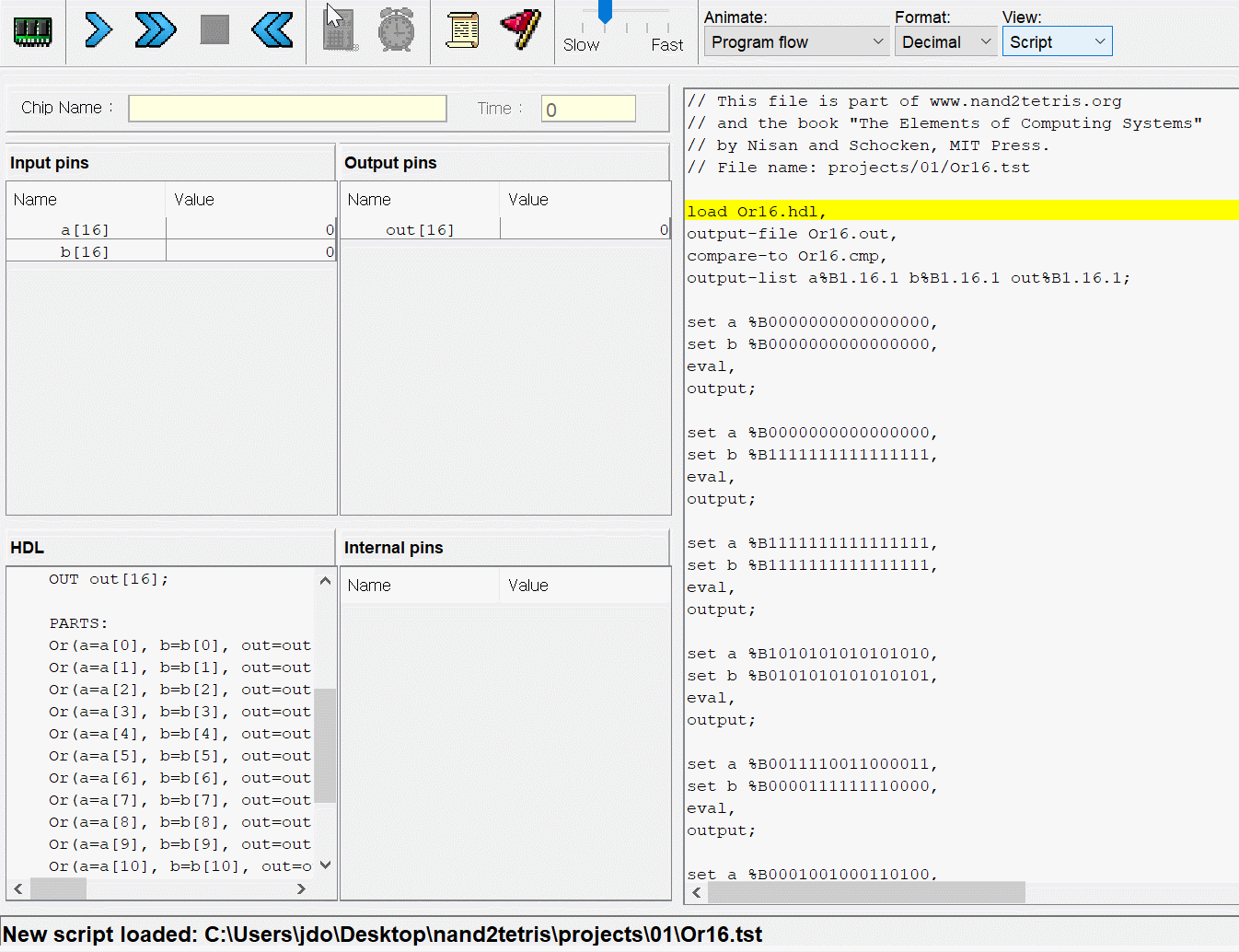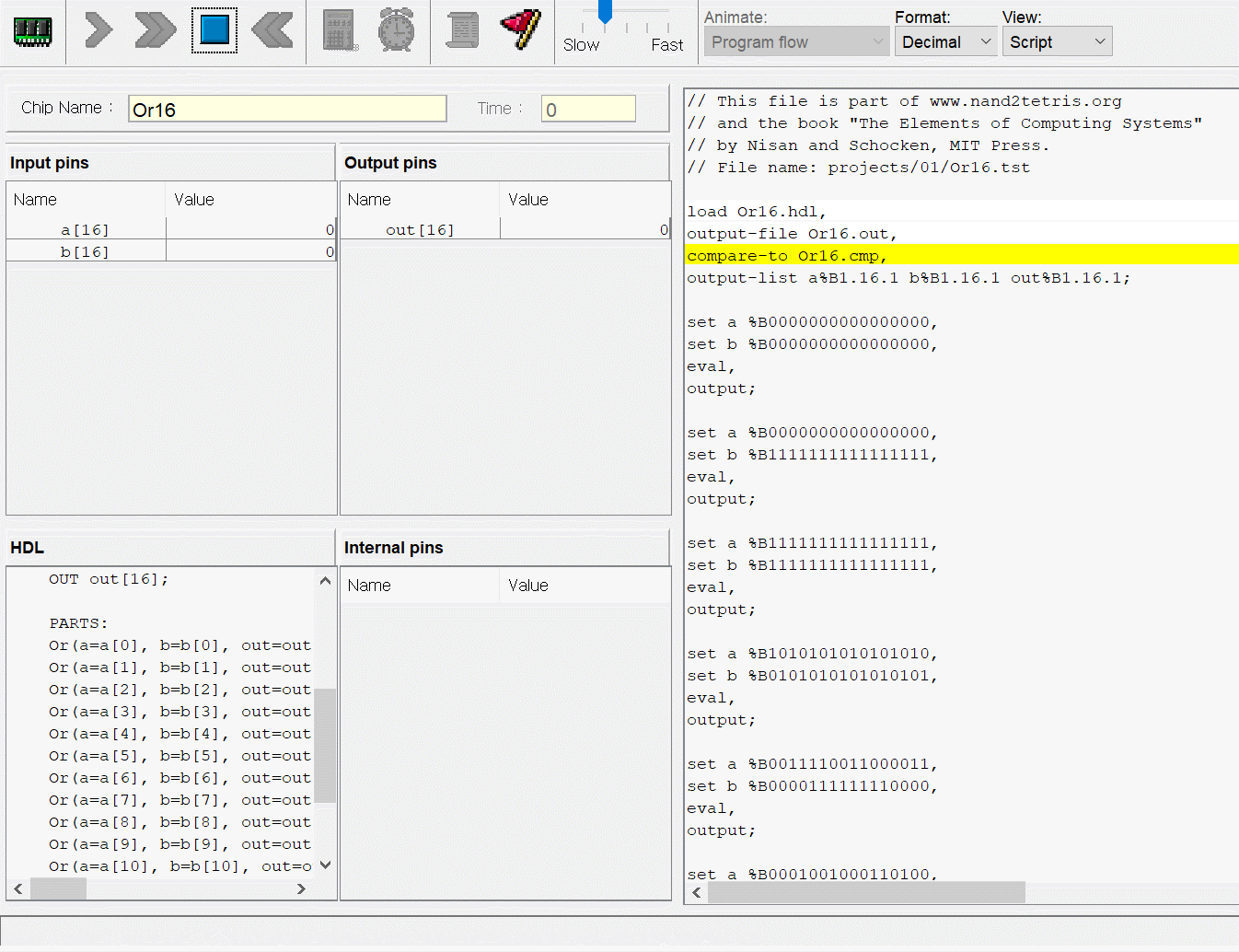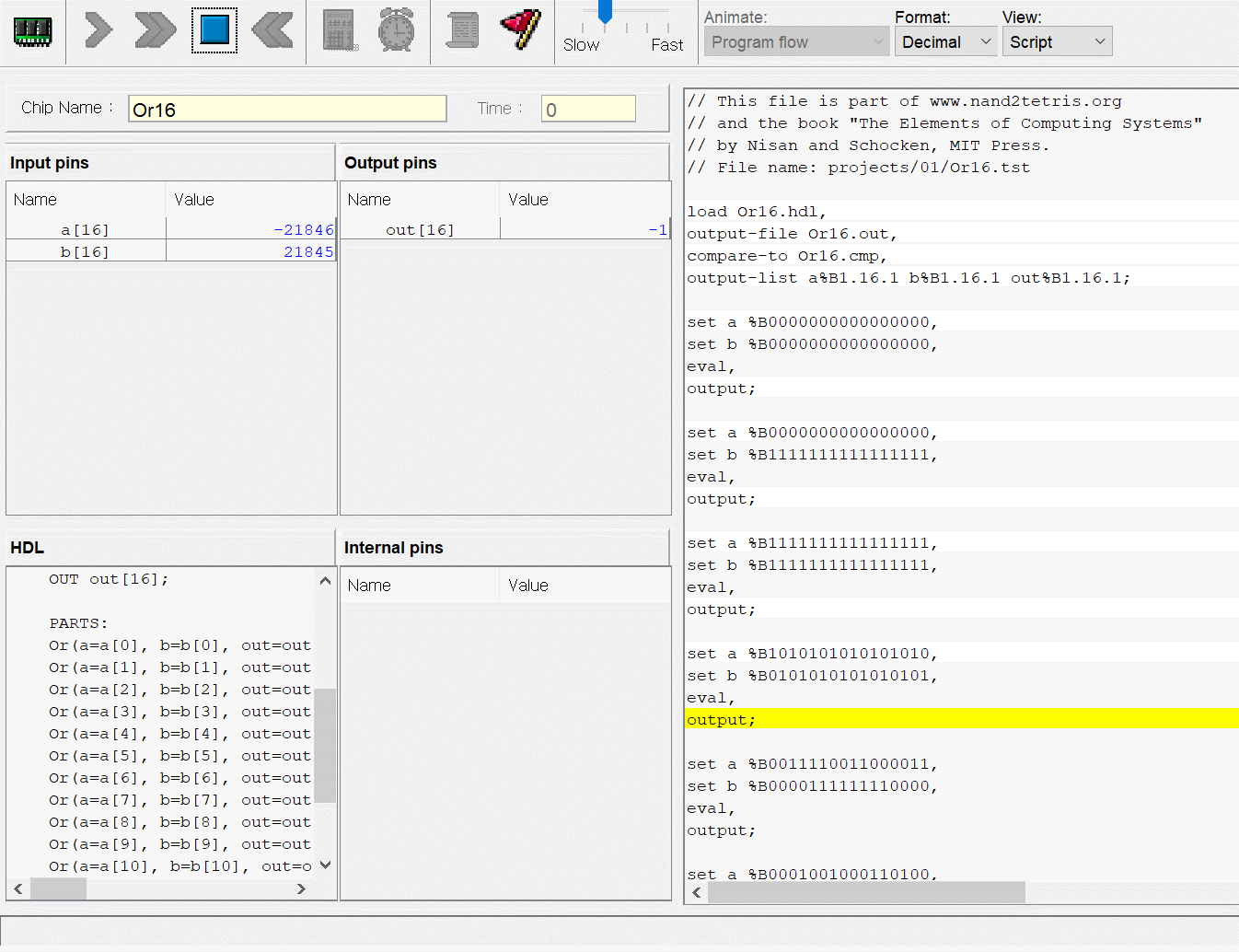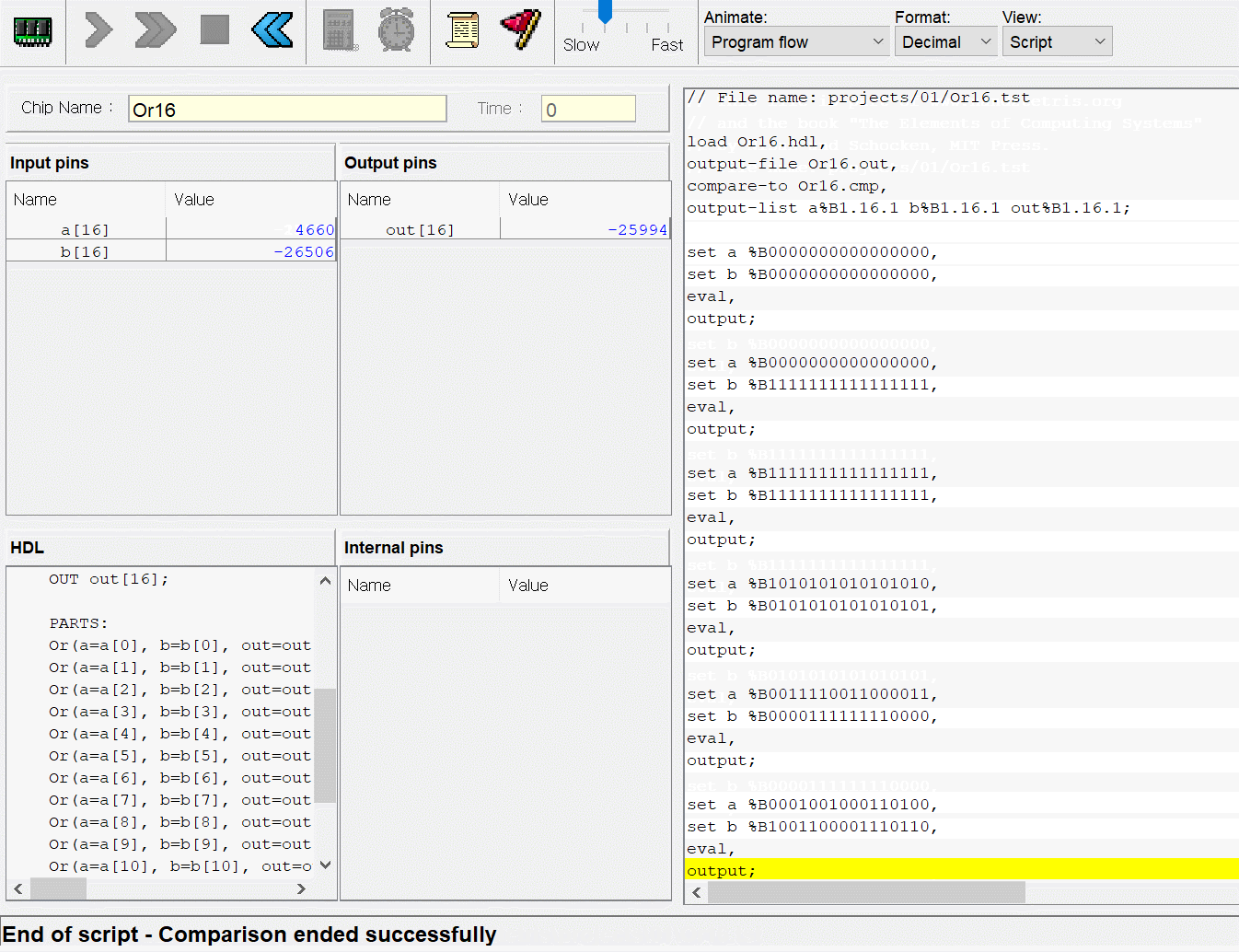
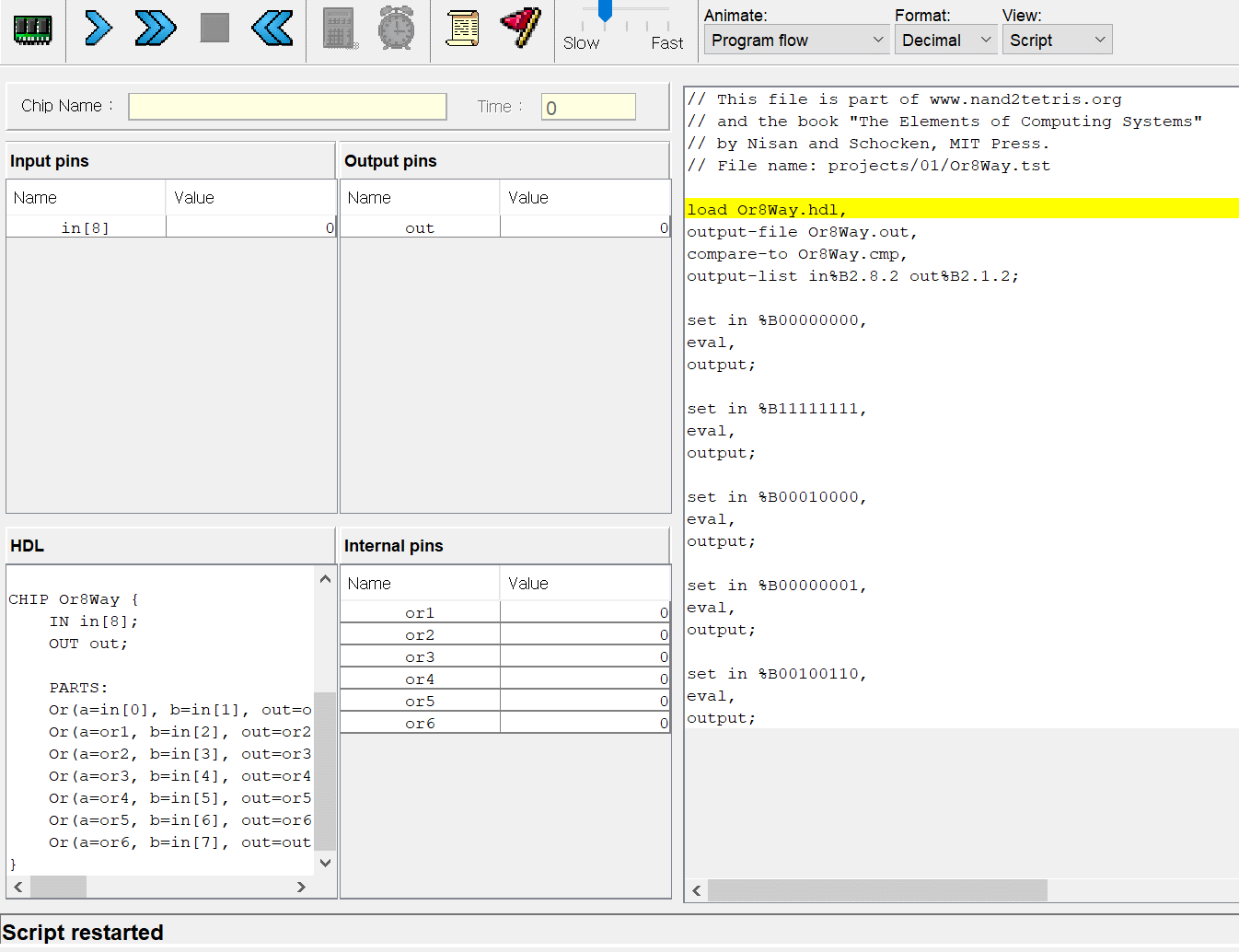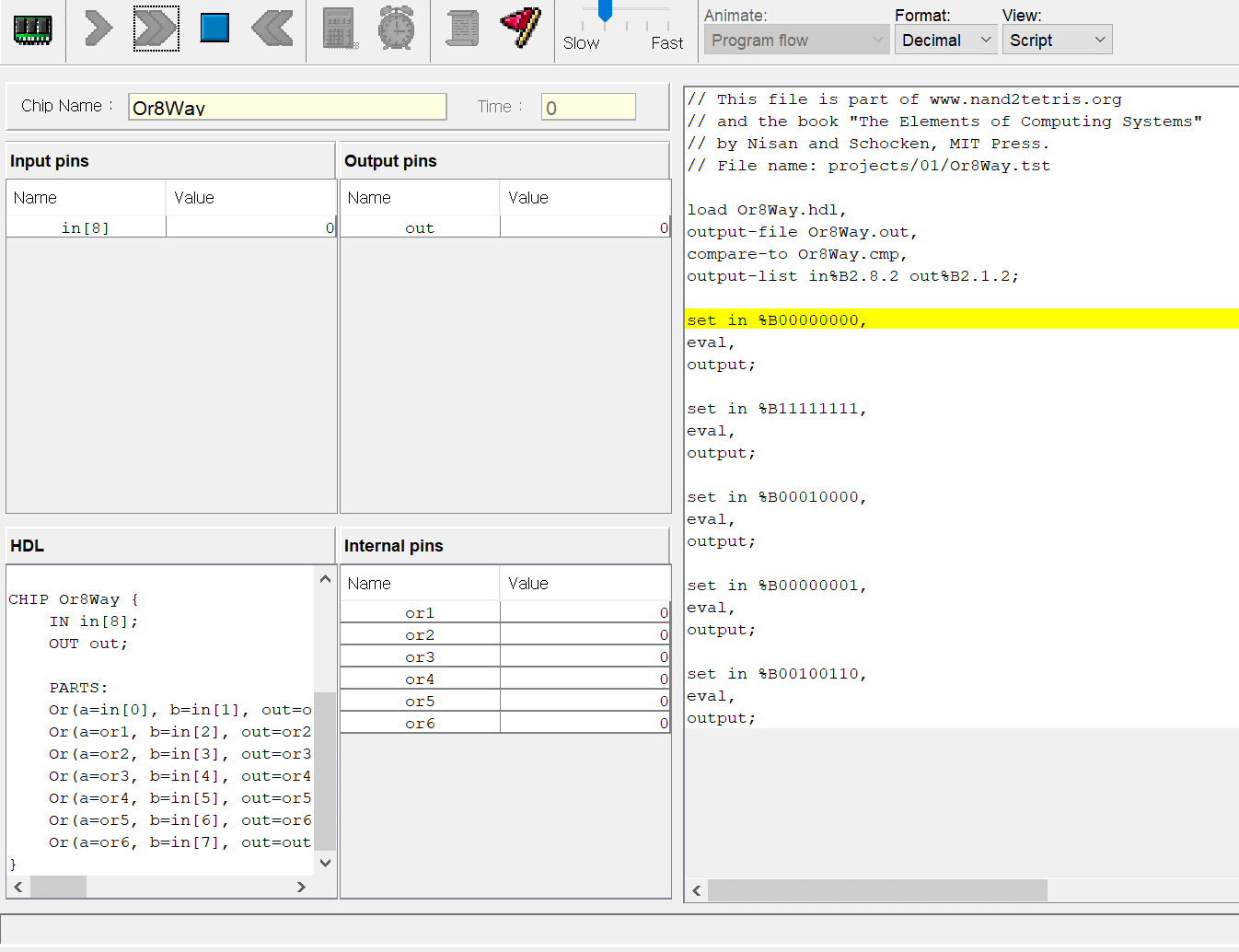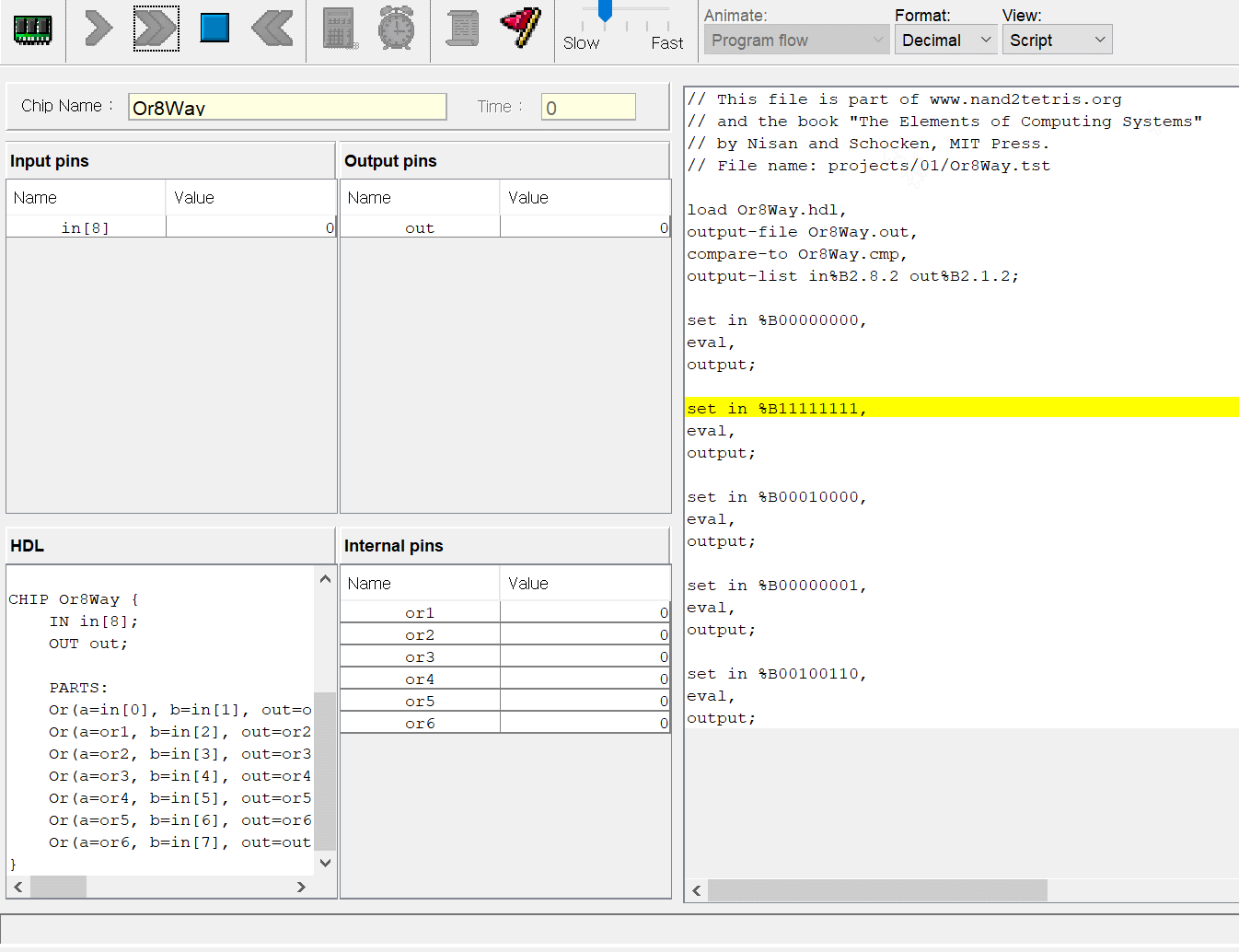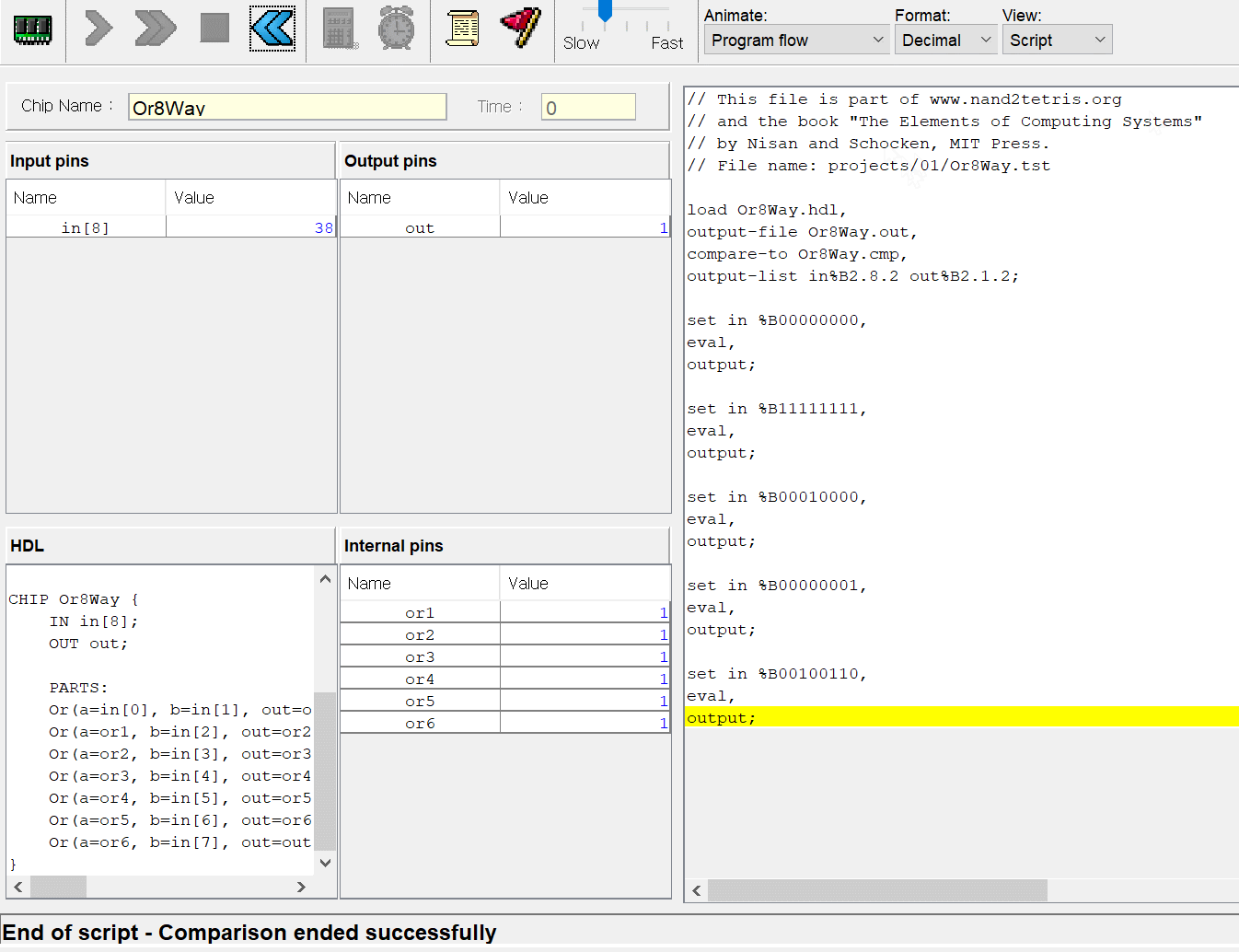
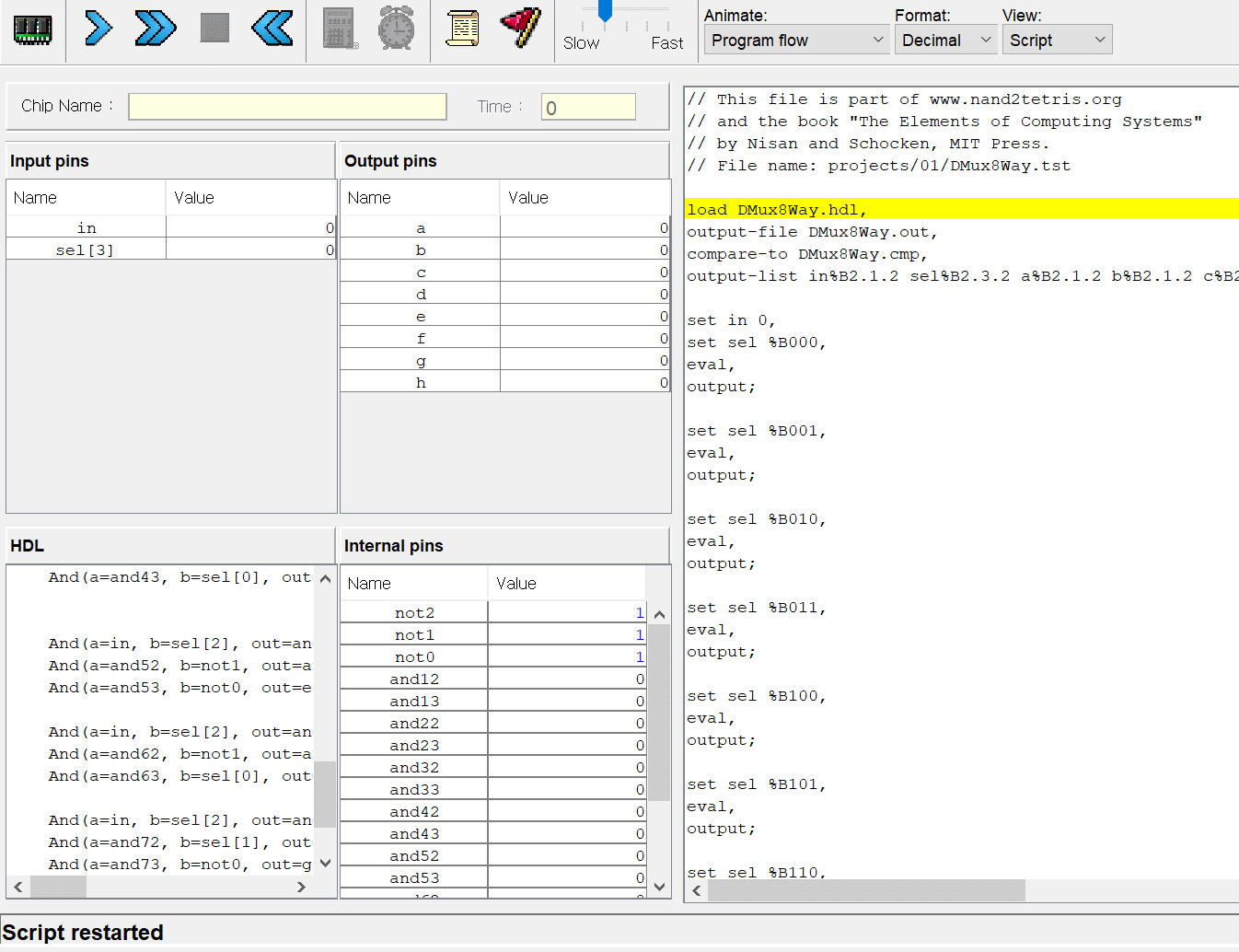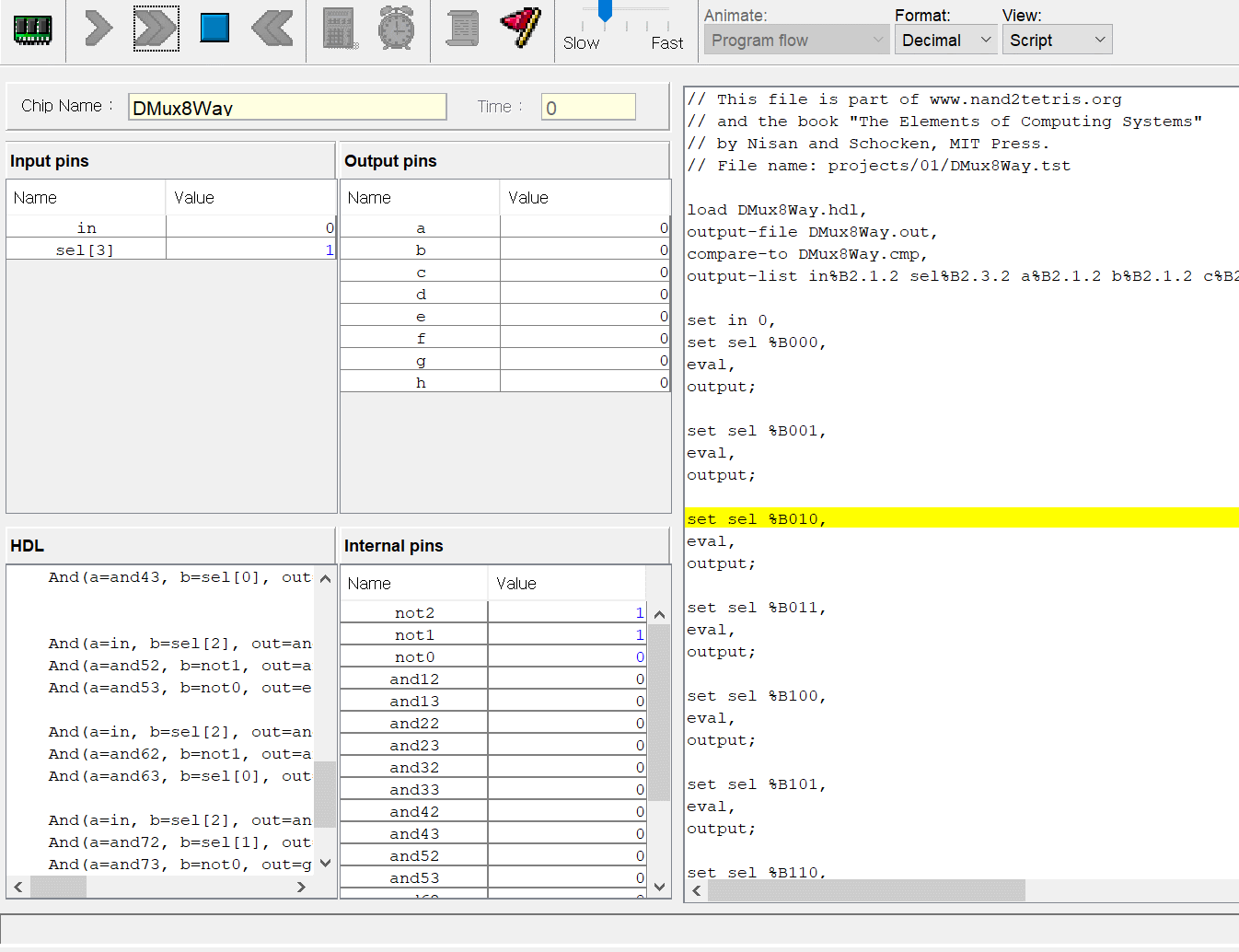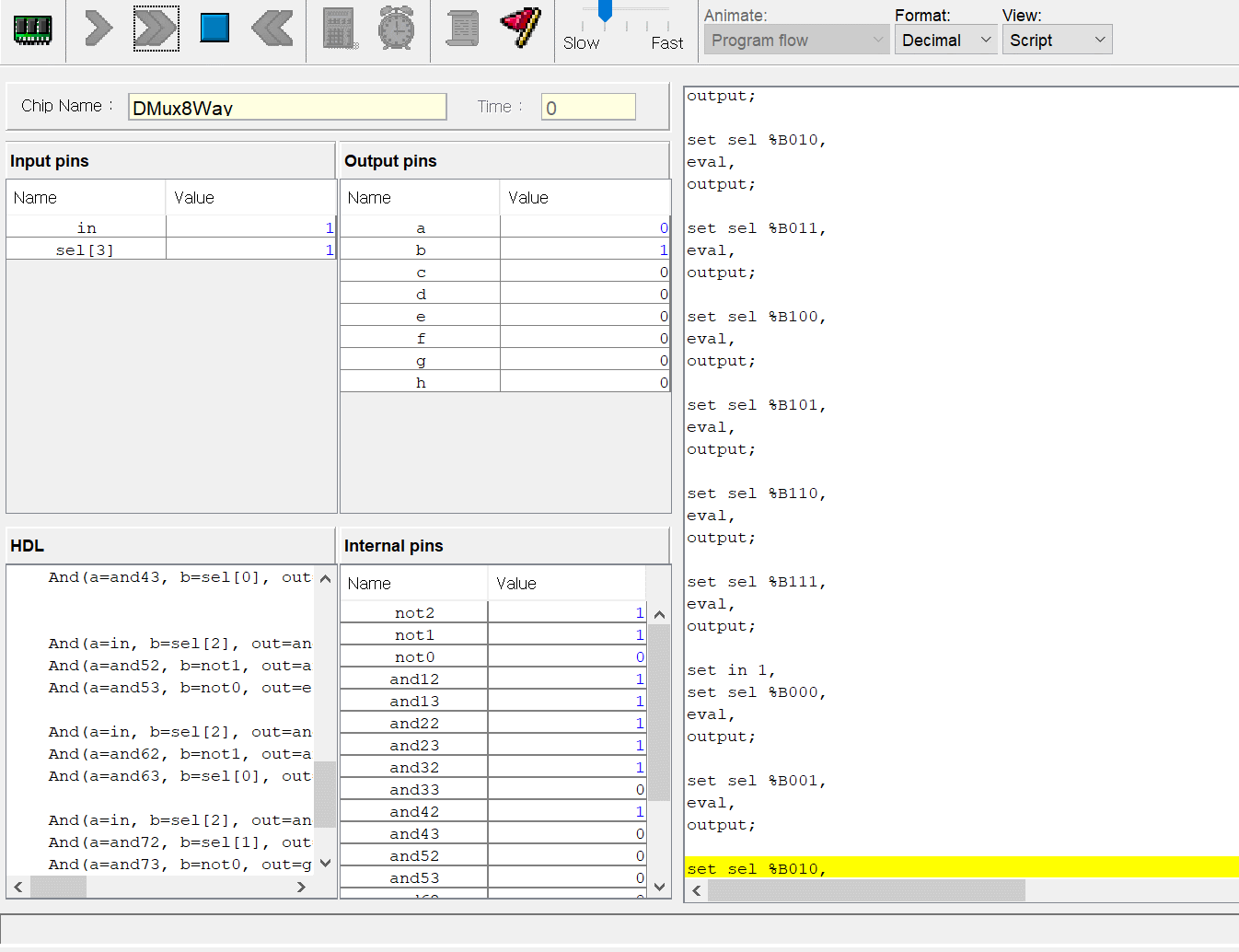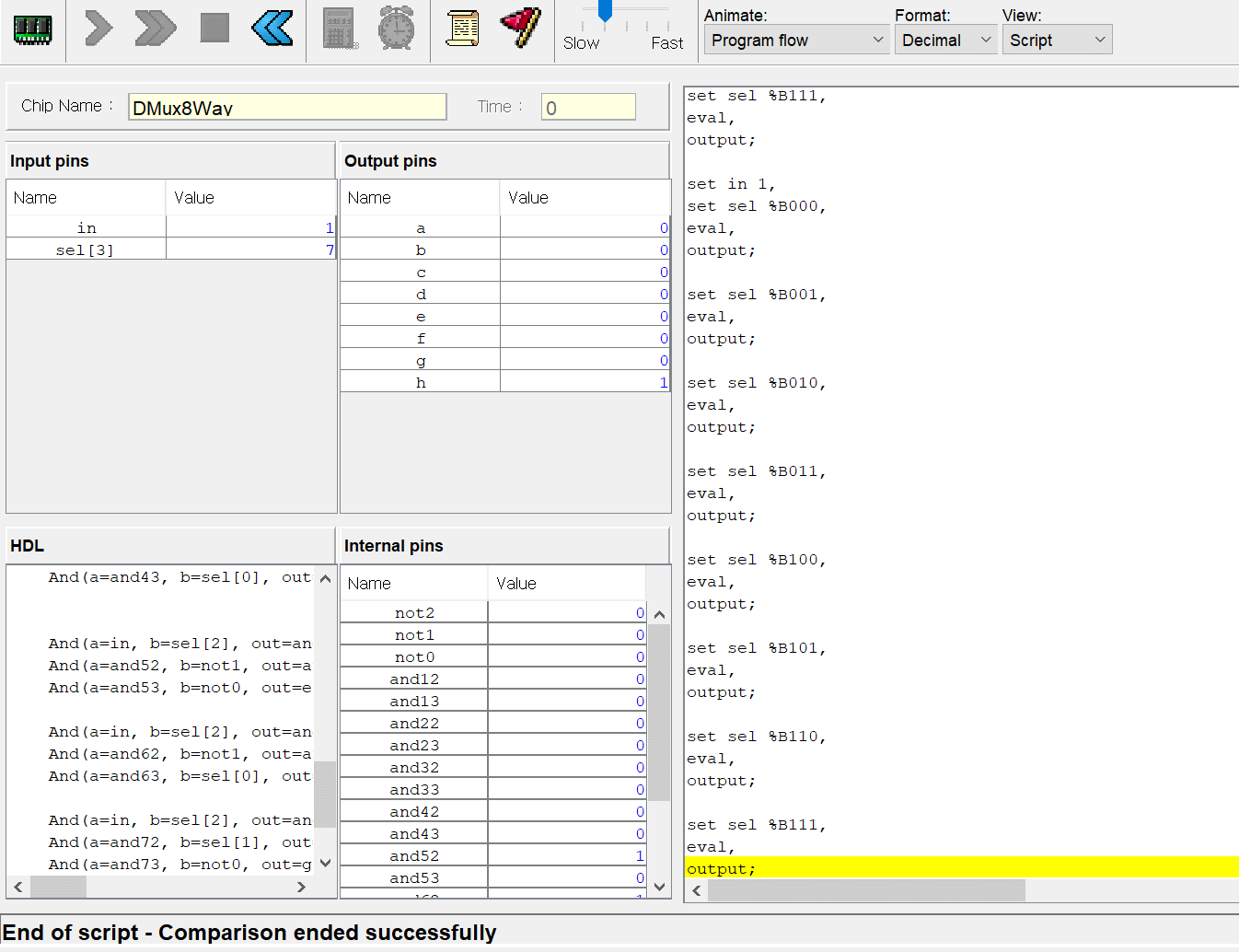
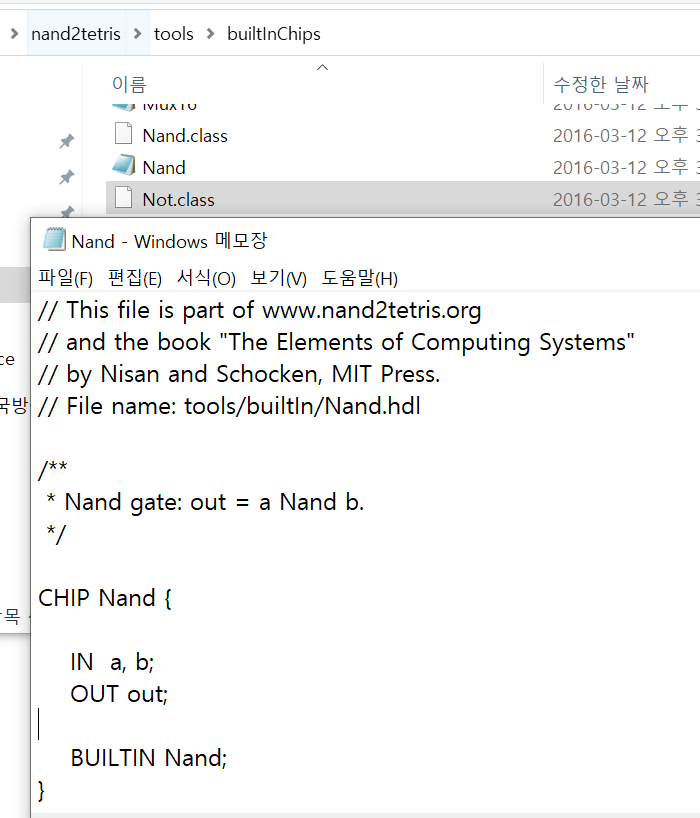
CPU는 ALU와 세 레지스터 - 어드레스 레지스터, 데이터 레지스터, 프로그램 카운터로 만들면 된다. 각각이 뭐하는건지는 직접 만들기도 하고 수차례 시뮬레이션도 돌렸으니 넘어가고 고맙게도 아래의 그림처럼 연결하면 된다고 알려준다. 동작 과정은 다음과 같다.
1) 명령어 해독 : CPU 입력 - 명령어 instruction은 A 명령어(MSB가 0, op-code라고도 했던거같은데), C 명령어(MSB가 1일때) 올수 있고, C 명령인 경우 111accccccccdddjjj 6개의 제어 비트 ccccccc와 a로 선택된 연산을 수행하고, ddd로 지정한 곳에 연산 결과를 저장한다. jjj가 000이 아닌 경우 연산 결과에 따라서 jjj의 조건(0과같거나, 크거나, 작거나 등)에 따라 어드레스 레지스터에 입력된 명령어 주소로 점프한다.
2) 명령어 실행 : 들어온 명령어가 A 명령어인 경우 A 레지스터에 담는다. C 명령어의 경우 해독된 명령어의 연산을 수행한다.
3) 명령어 가져오기 : 명령어가 실행되면 프로그램 카운터는 다음에 실행할 명령어의 주소를 준비하고, 현재 명령어가 끝나면 PC에 지정된 주소의 명령어가 실행된다. 하지만 앞서 보았듯이 "@LOOP\n 0;JMP" 처럼 라벨 심볼로 점프할때는 어드레스 레지스터 A에 담겨진 라벨 심볼 (LOOP)의 주소로 점프하여 명령어를 수행하게 되고, PC도 이를 따라가 다음 실행할 주소를 담아서 수행한다.
이제 CPU 구현에 필요한 내용은 대강 정리했는데
어디부터 시작하는게 좋을지가 고민이다.
프로그램 카운터나 각 먹스, 레지스터에는 제어 비트를 어떻게 넣어야 하는건지
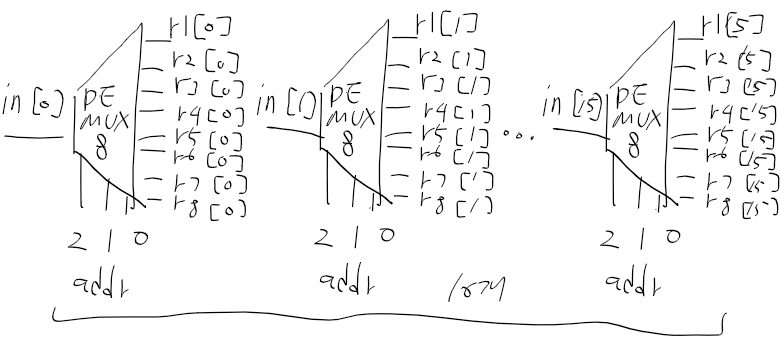
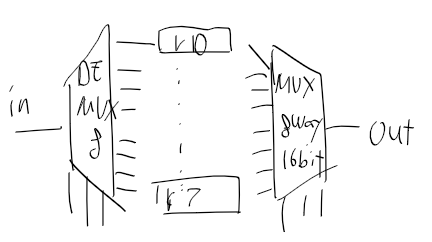
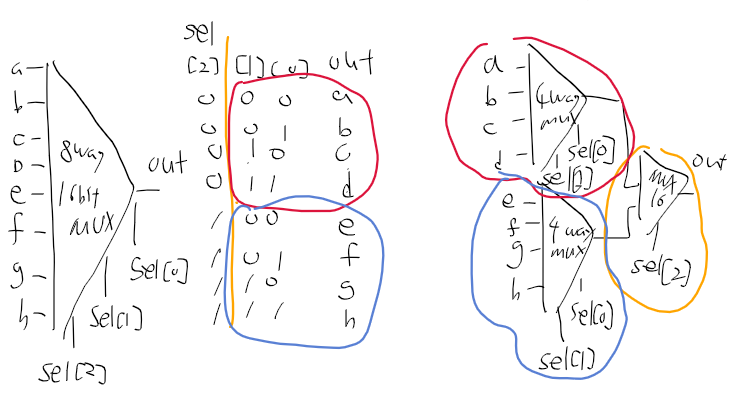
위 그림을 보고 사용해야할 회로들의 인터페이스를 정리해보자
CPU = ALU + D/A registor + PC +(Mux 16 2개)
1. ALU
- 입력 : 16비트 x(D), y(M/A), 제어 비트 6개
- 출력 : 상태 출력 비트 2개 zr ng, alu 연산 출력 16비트 outM
2. PC
- 입력 : 16비트 입력(다음 실행 주소 A-점프시), 제어 비트 3개(reset, load, inc-이 순서대로 조건에따라 수행)
- 출력 : 제어 비트에 따라 리셋시 0, 로드시 점프할 주소, 증산시 다음 명령어, 이도저도 아닐땐 상태 유지
3. Regsitor
- 입력 : 16비트 입력 in, 로드 제어비트 load
- 출력 : 현재 값 out, 입력 로드시 out[t+1] = in[t]가 된다.
4. MUX 16
- 입력 ; 16비트 a, b
- 출력 : sel이 0인경우 a, sel == 1일때 b
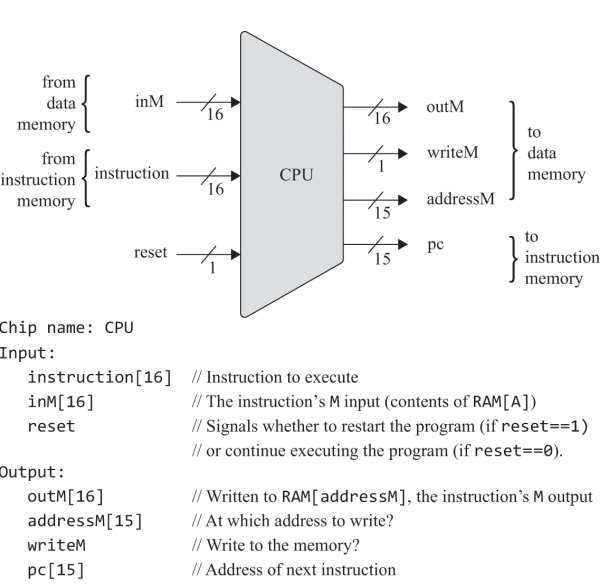
CPU
- 입력 : inM(데이터 메모리에서 읽어온 값), instruction(현재 실행할 명령어)
- 출력
outM : RAM[addressM]에 쓰여진 결과
addressM : 값이 쓰여질 주소, A 레지스터의 출력
writeM : 메모리에 쓸지 읽을지 여부
pc : 다음 명령의 주소
1.1 PC 구현하기
1. reset 입력 : PC의 제어비트 같은 경우에는 reset을 바로 연결시켜주면 될거같기는 한데 ..
2: inc 입력 : inc는 reset이 0이 아니면 1이니까 Not(in=reset, out=resetNotOut) 해서 넣어주면 될거같다.
3. load 입력 : load 의 경우에는 명령어의 j 비트가 000인 경우에만 점프하는게 아니니까3bit or한 결과가 0이면 load는 0, 1이면 1로해야겠다. 일단 instruction의 LSB 3비트만 받아서 or 연산 후 jmp123or을 출력하여 load 자리에 넣는다고 생각하고 이 이름을 입력받도록 하자.
4. in 입력 : A 레지스터의 출력을 써야하니 일단 A 레지스터를 어떻게 할지 생각하지는 않았지만 aRegistorOut이란 이름으로 해놓자.
가장 먼저 PC를 만들면서 A의 입력을 받도록 했었으니까 이번에는 A 레지스터를 한번 보자
A Registor는 일단 좌측의 Mux16의 결과를 받아 우측의 Mux16과 PC로 보내고 있으며, 제어비트 c가 0인지 1인지에 따라 값을 읽기만 하거나 저장을 한다.
1. in 입력 : in의 경우 좌측 먹스의 출력을 받으니 일단 leftMuxOut 정도로 해놓자
2. 출력 : A 레지스터의 출력은 우측 먹스의 입력으로, PC의 입력으로도 사용하는데 일단 aRegistorOut 정도로 해놓자.
3. c 입력 : A 레지스터에 값을 쓸지 말지 여부는 명령어가 A 명령어인지 C 명령어인지에 따라 결정되었었다. 라벨 심볼이든, 변수든, 상수가 오던간에 A 명령어 이므로 instruction의 MSB를 보고 0이면 c에는 1, MSB가 1이면 c에는 0을 놓도록 Not 게이트(출력명은 opcodeOut)를 추가하여 연결해보자.
A 레지스터에는 A 명령어가 들어올때 외에도 C 명령어일 때, 첫번째 d비트의 값이 1인 경우 instruction[5]==1, 연산 결과를 A 레지스터에 담는다. 명령어가 C 명령어고 첫번째 d비트가 1인지 여부 ((instruction[15] && instruction[5]) 한 결과를 loadA라 하면, opcodeOut과 loadA 둘중 하나가 1이면 1이되도록 or 연산을 한 후 aRegistorLoad 라는 이름으로 전달해주자.
//A registor PARRTS
Not(in=instruction[15], out=opcodeOut); // A instruction == store to A registor
And(a=instruction[15], b=instruction[5], out=loadA); //if instruction is C, store outM to A registor
Or(a=opcodeOut, b=loadA, out=aRegistorLoad);
//if opcode is 0 (== A instruction) -> opcodeOut = 1 -> load = 1
Register(in=leftMuxOut, load=aRegistorLoad, out=aRegistorOut);
1.3 D registor
이번에는 D registor를 구현해보자. D 레지스터는 A명령어로 입력하지는 못하고, C 명령어의 ddd 값에 따라서 대입하도록 되어있었다. 그러면 D 레지스터에 입력하는 경우는 어떤 경우가 있었나?
위 표를 보면 2번째 d비트가 1일때만 D 레지스터에 입력하도록 되어있었다. 그러니까 A D M 순서니까 instruction[5], instruction[4], instruction[3] 순이 되겠다. 근데 지금보니까 d의 첫번째 비트가 1인 경우에도 A 레지스터에 값을 저장하도록 하고 있다. 그러니까 A 명령어인 경우 외에도 instruction[5] == 1일때도 A 레지스터의 load = 1이 되도록 해줘야 하는거같다. 일단 처음에 쓴 부분 뒤에다가 추가로 표기해놔야겠다.
1. in 입력 : D Registor는 ALU의 연산 결과를 담을수 있으므로 outM을 연결해주면 될거같은데, outM은 외부로 나가므로 루프할수 없으니 outMLoop 라는 루프 출력을 만들어서 in에다가 넣자.
2. c 입력 : 앞서 설명한것 처럼 명령어가 C 명령어이고 5번째 비트가 1일때 c에 넣도록 구현하자.
3. 출력 : A 레지스터때 처럼 dRegistorOut 정도로만 하자.
//D registor PARTS
And(a=instruction[15], b=instruction[4], out=loadD); //if instruction is C and dest is d, store outM to A registor
Register(in=outMLoop, load=loadD, out=dRegistorOut);
이제 PC, A, D, 레지스터는 전부 구현했고, ALU 하기전에 먹스부터 정리해보자.
1.4 좌측 MUX16(한참 삽질하여 뒤에 다시 정리함)
일단 좌측 먹스부터 생해보자. 왼쪽 먹스의 경우에는 a 자리에 ALU의 출력 outM, 이건 루프가 안되니 D 레지스터의 입력으로한 outMLoop를 사용하고, b 자리에는 instruction을 그대로 넣어주면 될거같다. MUX16은 sel이 0일때 a, 1 일때 b를 내보냈었는데 평소에는 A 레지스터에 A 명령어를 넣고, 아니다 C instruction[5]가 1일때만 outM을 A 레지스터에 넣었으니 이걸 sel 기준으로 잡으면 될거같다.
먹스는 sel이 0일때 a를 출력으로 하지만, C instruction[5] == 1일때 A레지스터에 저장해야하니 Not(C instruction[5]) 한것을 sel에 넣어야 alu의 출력이 A 레지스터로 넣어지고, C instruction[5]가 0이라면 not 연산으로 sel에 들어가는 값이 1이되고 instruction이 A 레지스터로 전달 되겠다.
잠깐 A 레지스터는 값과 주소를 저장한다 했는데, 값은 지금까지 한걸보면 A 명령어와 C 명령어의 목적지에 따라 ALU의 결과를 값으로 넣어주도록 했다. 하지만 C 명령어인데 instruction[5]가 아닌 경우는 A registor에 넣어도 되는건지 햇갈리기 시작했다.
지난번에 ALU, PC 구현할때는 완벽하게 동작을 이해하지 않더라도 표만 보고, 동작 조건만 따라서 연결만 해줬어도 어떤 흐름인지 따라가지는 못하지만 원하는 동작을 하기는 했었다. 지금도 A 레지스터에 먹스 a를 넣는 조건을 찾았으니 전처럼 해야할까? 그냥 그랬다가는 나중에 놓친 부분이 있으면 엄청 해맬거같은데 고민된다.
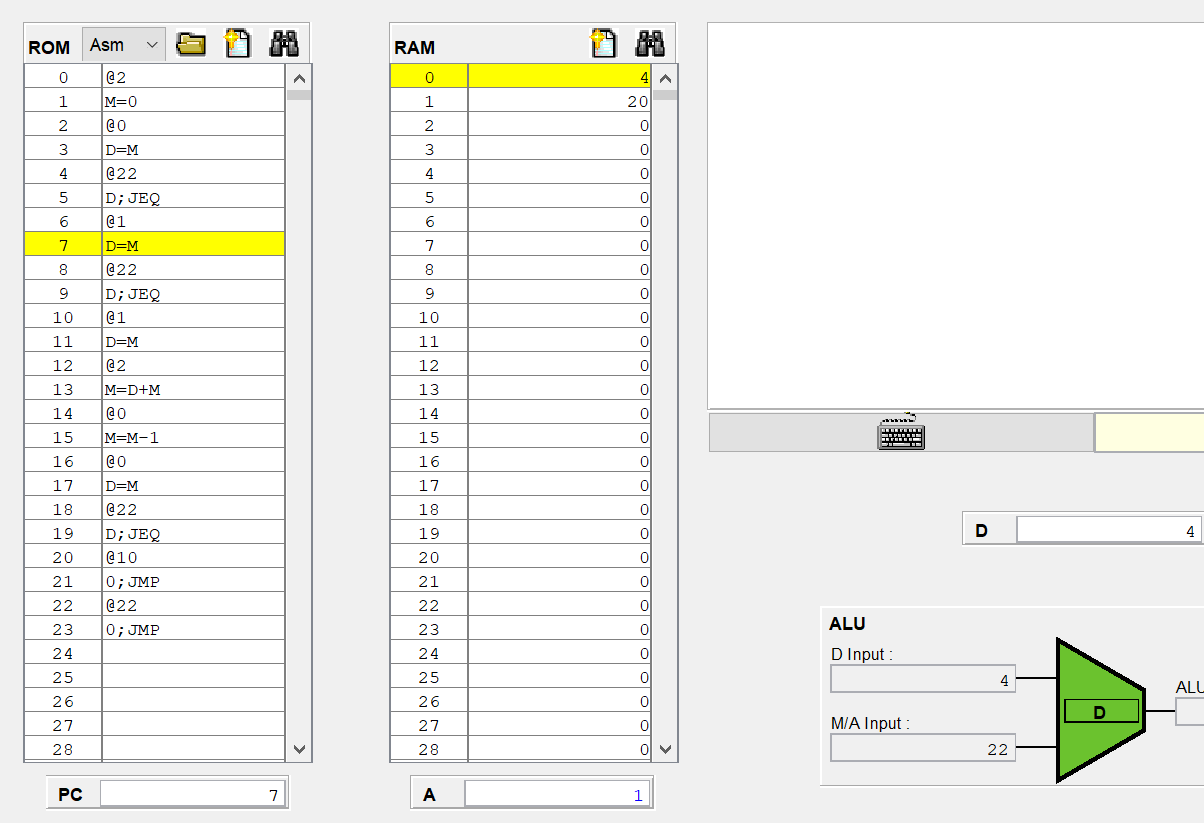
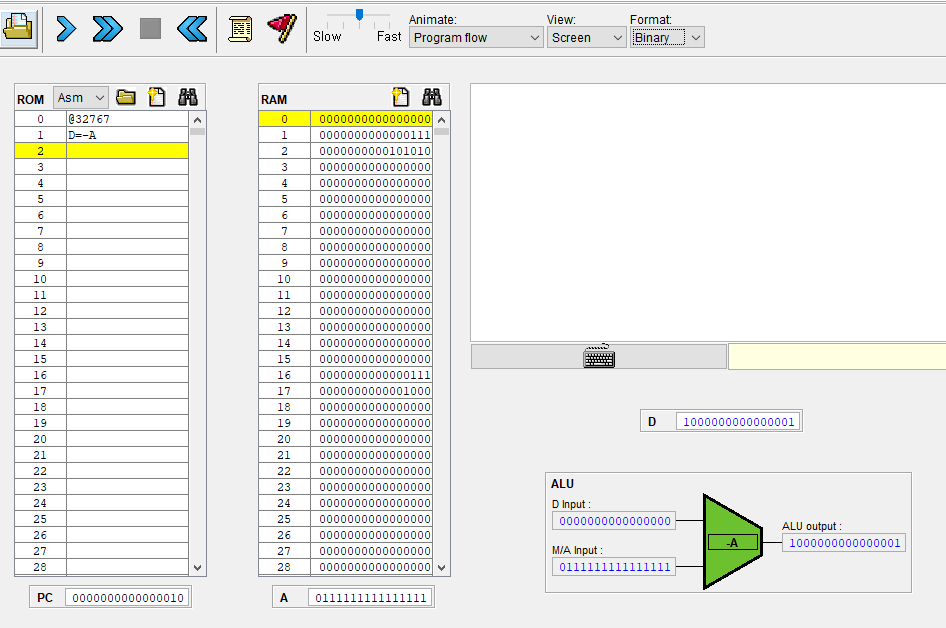
C 명령어가 (A=)가 아닐때 잠깐 곱셈 어셈블리어로 CPU 에뮬레이터를 보니
@1 //이때 A에는 1이 들어가고, 현재 1번지의 값은 20이다.
D=M //그러면 M에는 20이 들어갈 것이고, A 레지스터는 명령어를 저장하는게 아니라 기존의 1을 유지해야한다.
D=M 연산한 결과 A 레지스터는 1로 그대로 유지되고 있고,
D의 값이 RAM[1]의 값으로 덮어씌워졌다.
아 지금 보니까 생각난게 이래서 A 레지스터의 load를 조절해줘야 되구나.
아까 수정한 A 레지스터에는 C 명령어이고, instruction[5]가 1인 경우에만 load=1이 되도록 했으니
어셈블리어에서 A=이 아닐때는 load에 0이들어가 기존 값을 유지하는게 된다.
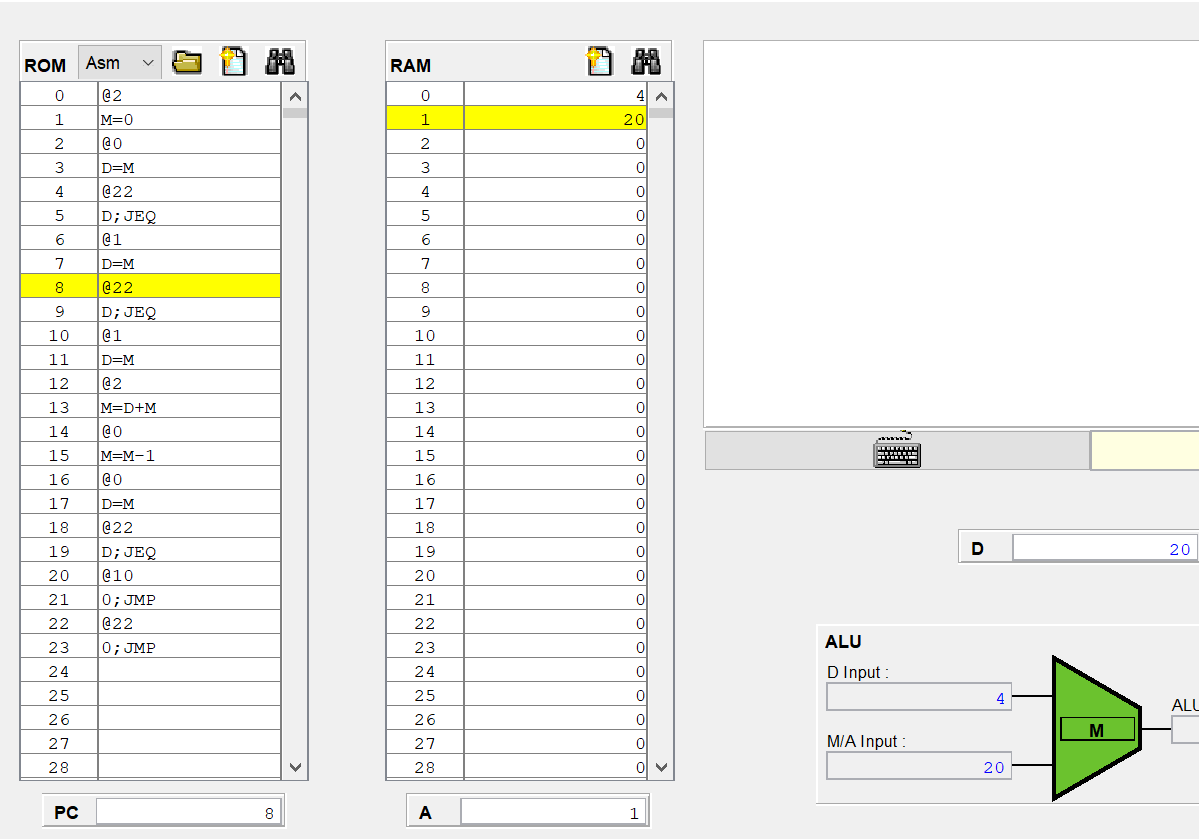
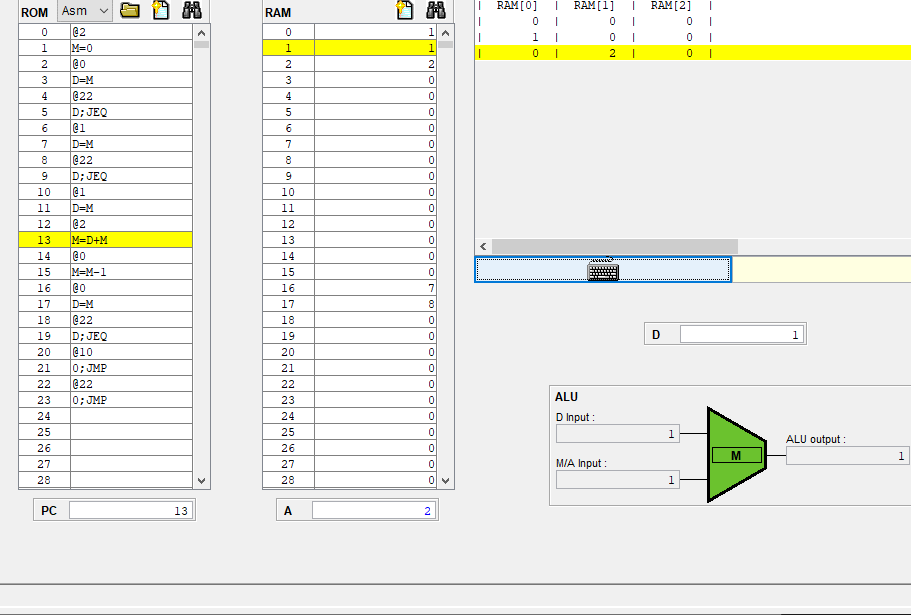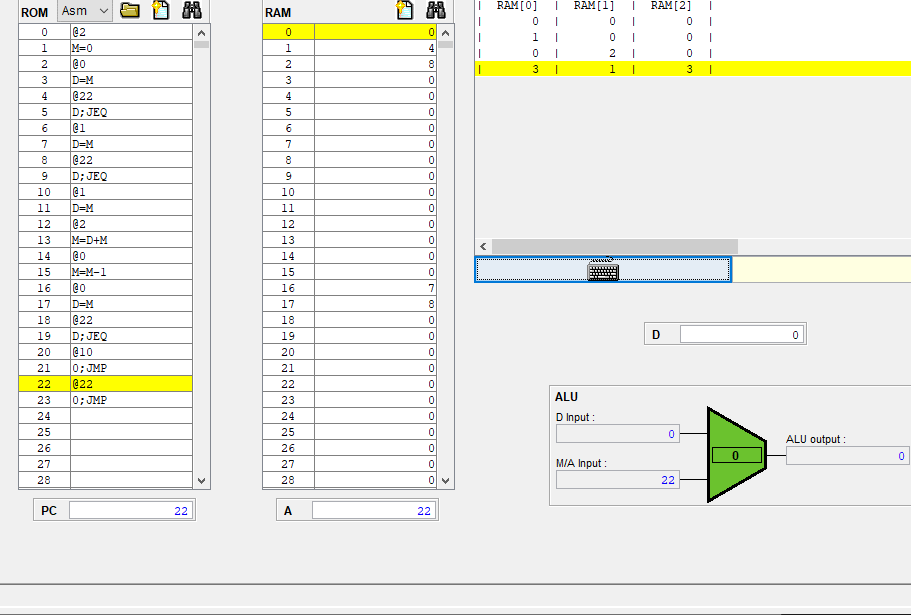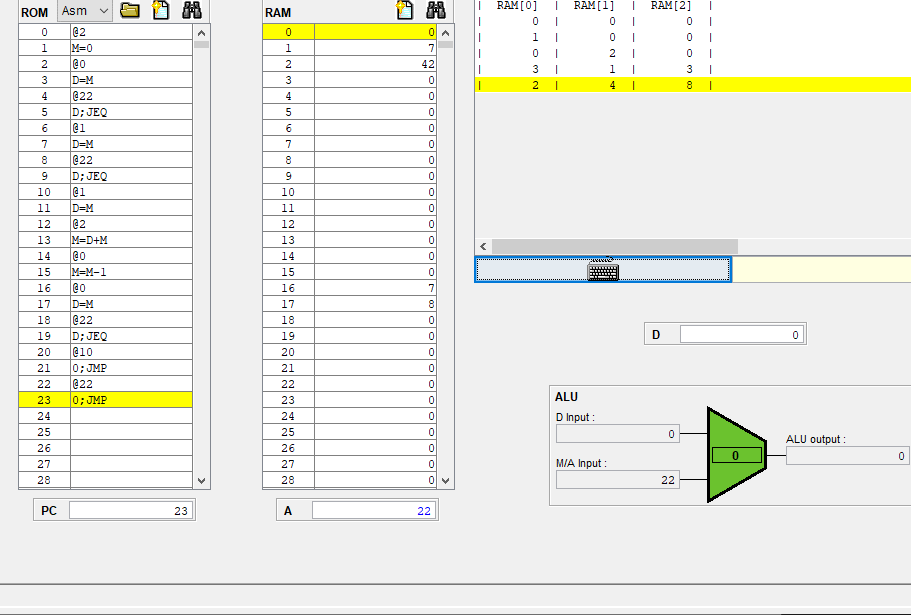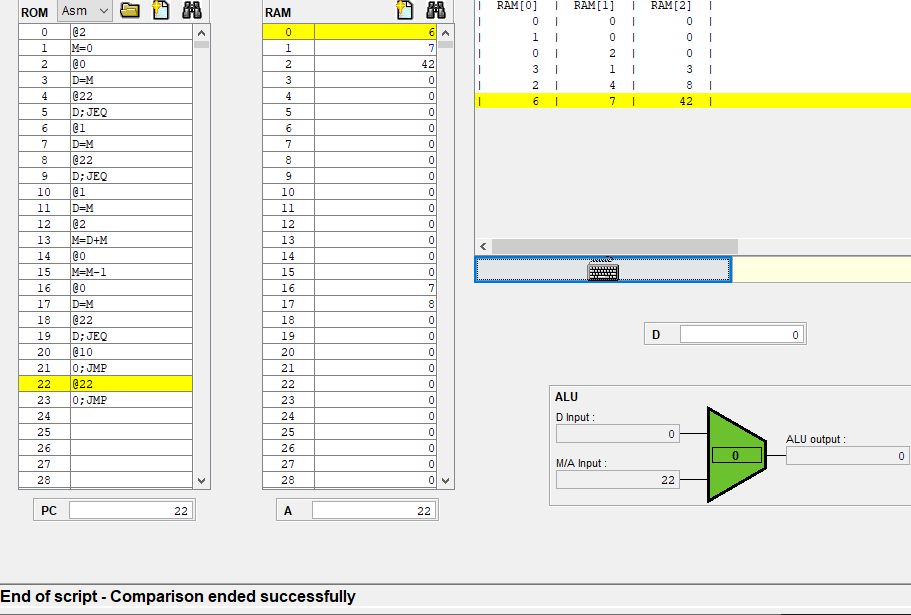
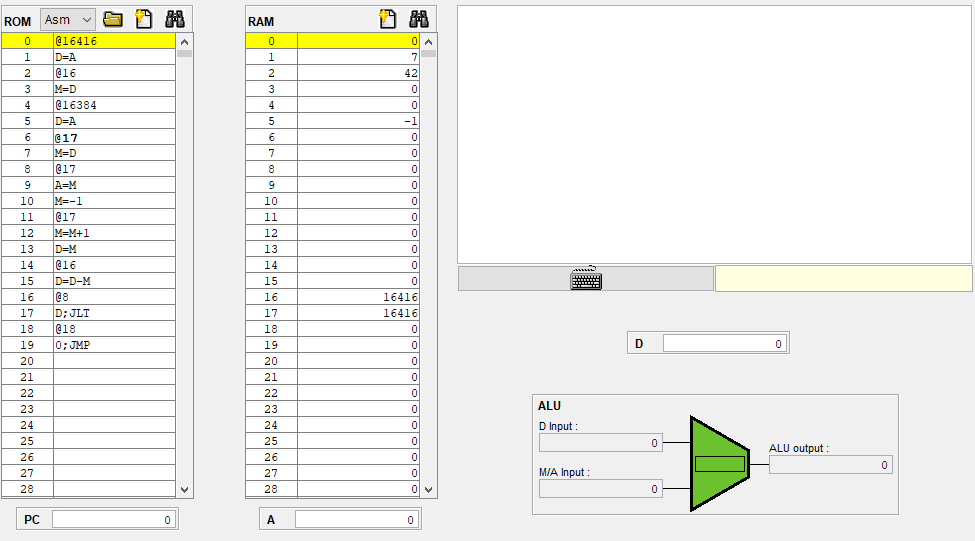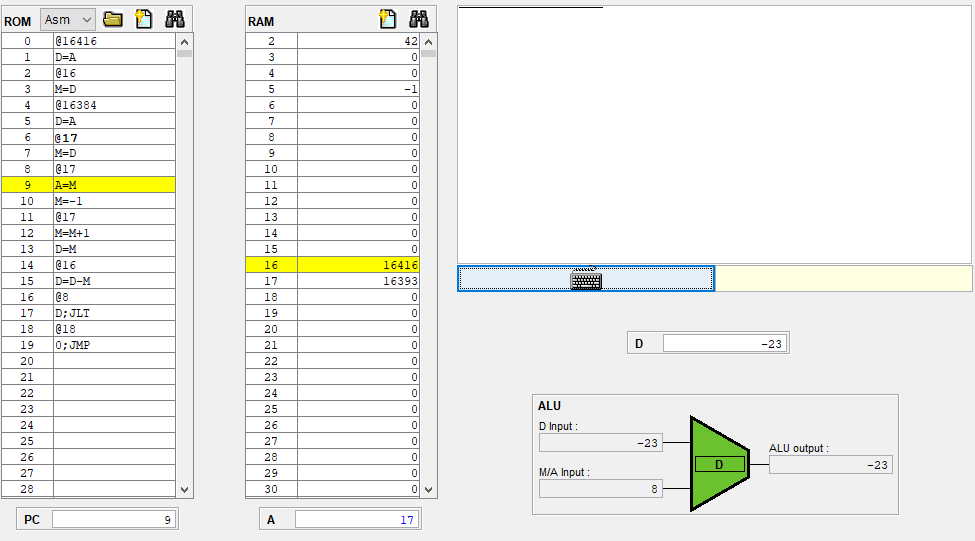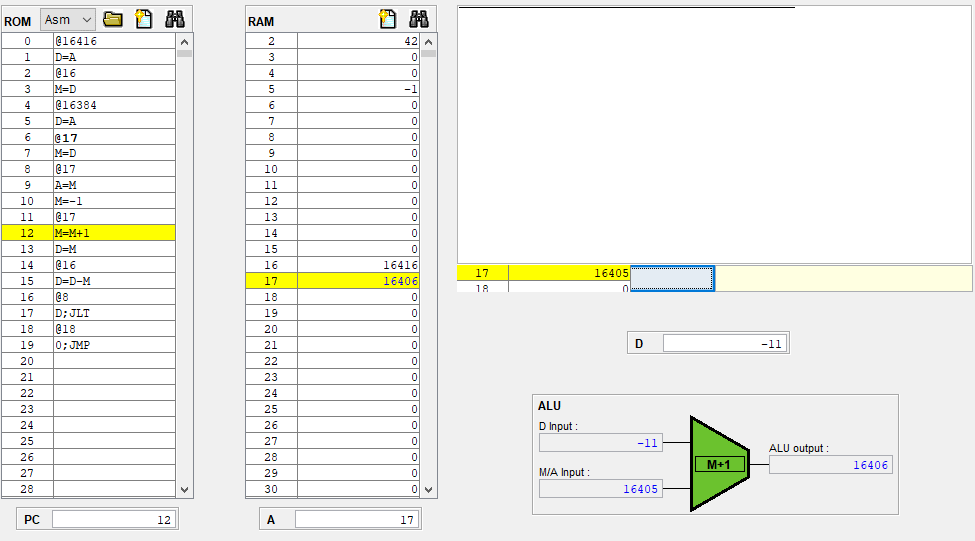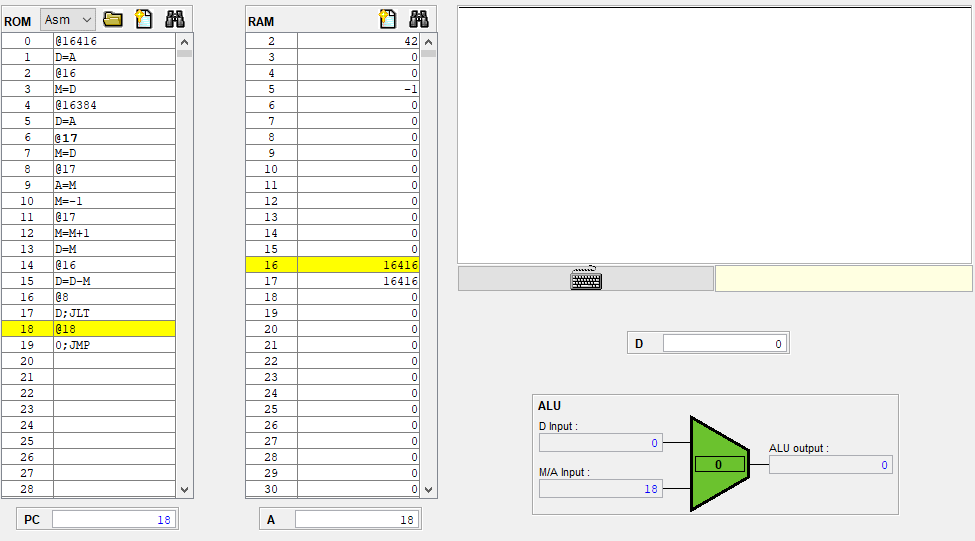
그리고 위에 사진에는 @22에 노란줄이 되어있는데 이 명령어는 A 명령어이고, A 레지스터는 순차 논리 회로이므로 다음 클럭때 A는 22로 반영이 될거같다.
실제로 A 레지스터의 값이 22로 변했다.
그런데 아직 ALU아 하단 입력 M/A가 20 그대로 유지되고 있다.
현재 22이니까 22이여야 하는데 안바뀐건 시간이 안지나서 그런걸까?
아니면 우측 먹스에서 inM이 들어와 아직까지는 아래에 20이 들어가는거같다.
8번 명령어는 값을 저장하는 A 명령어라 M이 반영이 안된건지
아 다시 처음부터 보니까 이해가 되는게
내가 그동안 노란줄을 현재 실행한 명령어로 오해하고 있었다. 실제로는 프로그램 카운터가 가리키는 주소라
다음에 실행하는 명령어인데도
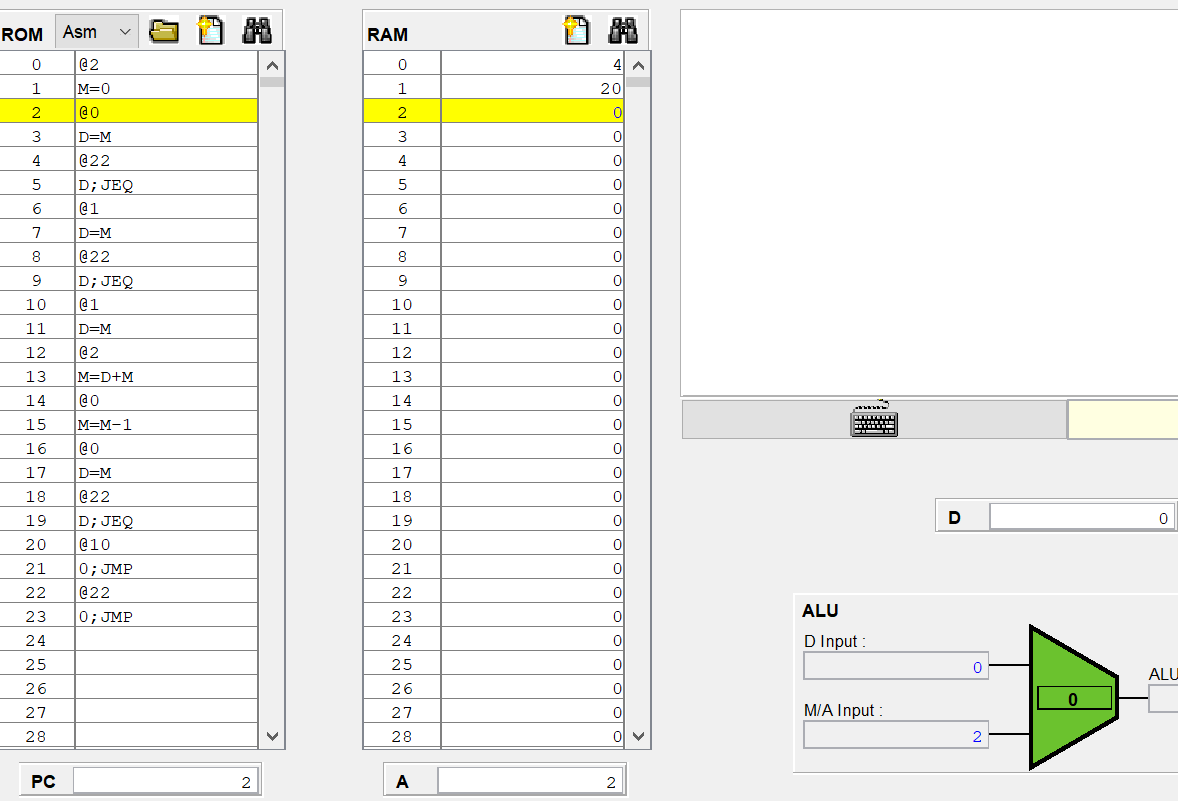
다시 이 코드를 한번씩 실행하면
PC가 0일때 모두 0이지만, 0번 명령어를 실행하는 즉시 PC는 1, A에는 A 명령어를 통해 2가 저장된다.
registor(load=1) out(t+1) = in(t) 이었으므로 아직 ALU의 M/A 입력이 0이고,
다음 클럭때(PC가 2를 가리킬때) 2를 출력하게 된다.
일단 오케이 아까보다는 PC니 A 레지스터 값 저장이니 더 이해된거같네
아까 햇갈렷던 A 레지스터의 값이 22인데 ALU에 반영안된 이유는
현재 실행한 명령어는 8번 명령어라 A에는 즉시 저장되었지만 출력이 아직 안되었기 때문이고
8번 시점에 M/A 입력이 20인건, 7번 시점에서는 A가 1이지만 우측 먹스에 의해서 inM이 전달되서 그런거같다.
좌측 먹스를 정리하면서 좀 많이 해매버렸는데, A에 A 명령어든 C 명령어 연산 결과를 저장하든 말든간에 우측 먹스에 의해서 alu 아래 단자 값이 정해지니 이게 중요한거같다.
먹스 하나가 내용 정리하는데 어쩌다 보니 다른 회로 합친거보다 길어졌다.
잠깐만 다시 정리하자
outMLoop와 instruction을 A 레지스터로 저장 조건과 전달 조건
A 레지스터 저장 조건
1. 명령어가 A레지스터인 경우 - instruction을 저장한다.
2. 명령어가 C 명령어이고, instruction[5] = 1인 경우 - outMLoop를 저장한다.
A 레지스터 전달 조건
1. 명령어가 A레지스터인 경우 - instruction을 저장한다.
-> 좌측 먹스로 명령어를 전달한다.
2. 명령어가 C 명령어이고, instruction[5] = 1인 경우 - outMLoop를 저장한다.
-> 좌측 먹스로 outMLoop를 전달한다.
3. 그외 경우 : C 명령어이나 instruction[5] = 0인 경우
-> 저장 하지 않아 기존의 저장된 값을 출력하므로 무관하다.
그러므로 ((instruction[5] == 1) && (instruction[15] == 1)) ==1일때만 outMLoop를 A 레지스터로 전달하도록 하고
범용 목적 컴퓨터는 우리가 사용하는 PC나 휴대폰처럼 게임이든, 인터넷이든, 음악이든 하나의 목적이 아닌 다양한 용도로 사용할수 있는 컴퓨터를 말하며,
범용 목적 컴퓨터 외 다른 분류로 특수 목적/단일 목적 컴퓨터가 있다.
단일 목적 컴퓨터의 경우 처음 이 단어를 보는 사람에게는 막연할거같은데 나도 그랬었고,
우리 주위를 보면 신호등, 엘리베이터, 밥솥, 냉장고 등 다양한 기계, 전자장치들이 존재한다.
아직 시퀀스에 대해서 잘 아는건 아니지만 이런 기계 중에서는 엘리베이터나 자동 수양장치, 자기 유지 회로 등 프로세서없이 만들어서 사용할 수 있는 시퀀스 시스템도 있고,
아날로그 시퀀스 만으로는 구현하기는 어려워 프로세서를 이용한 디지털 시스템이 있는데 우리가 사용하는 PC나 휴대폰 외에도 TV나 밥솥, 냉장고도 내부에 프로세서가 들어가 있고 프로그래밍을 하여 사람이 쉽게 사용할수 있고, 원하는 동작을 하도록 되어있다.
이런 냉장고, 식기세척기, 밥솥 등과 같이 아날로그 회로만으로는 구현하기 어려워 사용한 프로세서를 특수 목적/단일 목적 컴퓨터라 하며, 단일 목적 컴퓨터는 PC같은 범용 목적 컴퓨터와는 다르게 밥솥은 밥솥역활만 하도록, 냉장고는 냉장고 역활만 하도록 특정 용도에 한정한 컴퓨터를 의미한다.
범용 목적 컴퓨터와 차이점이라면 다양한 작업을 할 필요가 없으니 계산 성능이나 메모리 공간, 주변 장치등이 범용 목적 컴퓨터에 비해 적이며 저렴하다는 점이다.
정도로 이해하고 있는데, 당장은 이 정도만 이해해도 답답하거나 막히는 일은 없었다.
외장 프로그램 방식과 내장 프로그램 방식
컴퓨터 구조를 공부하다 나오면 자주 보는 폰 노이만 구조니 하버드 구조랑 더불어 내장 프로그램 방식이란 단어를 종종 보곤 했었다. 그런데 처음 컴퓨터를 공부 할때는 당연히 프로그램은 컴퓨터 안에 있으니까 원래 내장된거 아닌가? 왜 내장 프로그램이라는 용어가 나온건지 잘 이해가 되지를 않았었다.
전기랑 디지털 논리 회로를 배우면서 동기 카운터를 만들고, 난드투 태트리스에서 ALU, 램 만들면서 이전보다는 좀 더 와닿았는게, 특히 직접 만든 ALU를 시뮬레이터로 테스트를 할때/기계어 어셈블리어 작성한걸 돌리면서 상태 비트 레지스터/C명령어에 따라 +1 연산하기도 -1 연산하기도하고 D+A M+D 든 연산을 하는걸 봤었다.
지난 장에서는 어셈블리어로 곱셈기 프로그램을 짜서 CPU 에뮬레이터로 돌렸었는데, 그 때는 직접 만든 바이너리 코드를 ROM에다가 저장해서 돌린덕에 PC로 지정한 명령어 실행하고, 그다음 명령어 가져와서 ALU에 넣어 실행하고를 반복했었다.
하지만 이런식으로 프로그램을 기억장치에 넣어서 사용하기 전에는 직접 프로세서가 원하는 동작을 하도록, 원하는 값을 넣을 수 있도록 하드웨어를 조작(선을 뺏다 꽂앗다)하여 만들었으며 이를 하드웨어로 프로그래밍 하는 방식을 외장 프로그램 방식이라 하더라.
잠깐 찾아보니 최초의 전자식 컴퓨터인 애니악이 이런 외장 프로그래밍 방식이라 한다. 디지털 논리회로를 지금 만큼 모르고 애니악이 최초의 컴퓨터니 에드박이니 하는걸 들을때는 그냥 연도 외우는 문젠갑다 싶어 억지로 외웠었는데 애니악과 우리가 현재 쓰는 컴퓨터가 이런 차이가 있다더라.
당장에 FPGA로 앞서 만든 ALU를 구현한다 하더라도 입력 두개나 상태 입력 비트에다가 +1, -1, +M, 0, not 연산을 하도록 전선을 일일이 연결해서 전원을 줬다면 얼마나 어려웠을까?
하드웨어를 이용한 동작 구현과 소프트웨어를 이용한 동작 구현
그리고 내장 프로그래밍 방식의 장점은 간단한 명령어들을 합쳐서 복잡한 명령어를 구현할 수 있다는 점이다. 가장 최근에 본 예시로 곱셈 연산일거같은데, 위의 ALU 제어 테이블이나 HACK의 어셈블리어 명령어 테이블을 봐도 하드웨어적으로는 곱셈 연산을 만든 적이 없고, 덧셈 뺄샘 그리고 논리 현산 몇개 뿐이다.
그런데 어떻게 곱셈 연산을 해냈던가? sum = D+M 연산을 D 횟수 만큼 하도록 루프를 돌면서 곱셈한것과 동일한 결과가 나오도록 어셈블리어를 만들었다. 거기다가 명령어 테이블에도 없던 입출력 제어도 ROM에다가 넣어둔 어셈블리어로 할수 있었다. 명령어 테이블에 없는 동작을 어셈블리어, 그러니까 소프트웨어 적으로 구현했는데 하드웨어로 구현할수 없을까?
곱셈기
잠깐 찾아보면 곱셈이나 나눗셈도 논리 곱셈기, 논리 나눗셈기가 나오는데 직접 하드웨어로 구현할수가 있다. 그런데도 사용하고자 하는 모든 연산을 하드웨어적으로 구현안하는 이유가 ALU로 원하는 모든 연산을 할수 있도록 각 연산들을 하드웨어로 구현해 짚어넣으면 하드웨어로 구현하기 힘든 연산도 있을 것이고, 그 만큼 비용도 비싸지고, 크기도 커진다.
하지만 곱샘 연산 구현때와 같이 ALU에서 제공하는 단순한 연산들로 소프트웨어 적으로 구현하는 것이 하드웨어로 구현하는것 보다 쉽고, 프로세서가 커질 필요도 없으며 소모하는 비용도 늘진 않는다. 지금 당장은 이정도로 이해하고 있고, 이게 RISC와 CISC의 차이인거 같은데 뒤에 또 보자
컴퓨터 구조 : 튜링 머신과 폰 노이만 구조
아 내장 프로그램 생각 정리하다가
외장 프로그램으로 넘어가고, RISC CISC 얘기까지 가버렸는데,
결국에는 이 내장 프로그램 방식이 대표적인 컴퓨터 모델인 튜링 머신이나 폰 노이만 구조같은 컴퓨터 구조의 핵심이 된다.
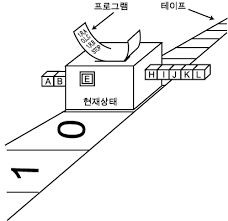
튜링 머신은 컴퓨터 공부하면서 몇번 들어봤지만 자주 까먹던 개념인데, 실제 물리적인 컴퓨터는 아니고 어떻게 프로그램을 읽고 처리할지 판단하는 추상적인 개념의 컴퓨터라 한다(만든 것도 있긴한데).
잠깐 나무 위키를 봤는데 (위 그림과는 조금 다르지만) 튜링머신은 테이프, 헤드, 상태 기록기, 행동표 등으로 구성되어있다고 한다. 지금 하는거와 빗댄다면 테이프는 기억 장치, 메모리 역활, 헤드는 어드레스 레지스터 역할, 상태 기록기는 상태 레지스터 쯤 되는거 같고, 행동표는 행동을 지시한다니까 프로그램 카운터쯤? 비슷한게 아닌가 싶기도 하다.
결국에는 헤드를 통해 테이프의 값을 읽거나 쓸수 있다는 점에서 튜링 머신도 내장 프로그램 방식이라고 하는거같다.
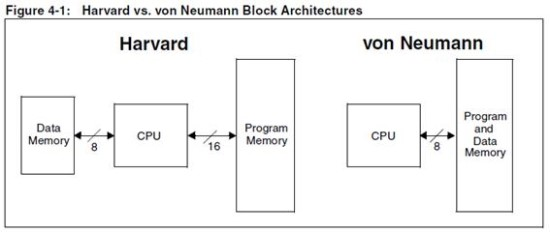
폰노이만 구조는 지난번에 하버드 구조와 같이 정리했던거 같은데, 내장 프로그램 방식인 만큼 메모리가 내장 되어있으며, 하버드 구조(데이터 메모리와 명령어 메모리가 다른 버스를 이용)와는 다르게 데이터 메모리와 명령어 메모리가 같은 버스를 통해서 CPU에서 읽고 썻었던게 특징이었다.
메모리
아무튼 우리가 만든 컴퓨터 HACK은 계속 봤지만 데이터 메모리 RAM과 명령어 메모리 ROM 두개로 나눠져 있으며 어드레스 레지스터 A를 이용하여 데이터 메모리의 값 M == RAM[A] 에 접근하기도 했었다. 근데 아직도 잘 이해안가는 건 어드레스 레지스터 A가 명령어 메모리의 현재 명령을 가리키고 있다고 하는데,
12: @23
13: D=A
위 연산에서 어드레스 레지스터 A는 23이란 값을 저장하고 있지, D=A란 연산의 주소를 가지고 있지는 않았던거같다.
다음에 실행할 거긴 하지만 명령어의 주소를 가지고 있는건 프로그램 카운터가 아니었나?
어드레스 레지스터 A가 어떻게 명령어 메모리의 명령어 주소를 가리키는가?
아 어셈블리어 천천히 돌리고 나서야 이해가 된다.
위 사진을 보면 지금 ROM의 16번지에서 A레지스터에다가 0을 담고
17번 명령어에는 RAM[0]의 값을 데이터 레지스터에 넣도록 하고 있다.
그런데 그 다음 줄을 보면 A 명령어와 C명령어로
@22
D; JEQ
가 있는데,
이 명령어를 진행하면 @22라는 A 명령어에 의해 A 레지스터에 22가 담기게 되고,
D에 있는 값에 따라 ROM의 22번지로 점프하게 된다.
그러니까 여기서 어드레스 레지스터 A는 점프해서 갈 명령어의 주소를 가리키고 있다.
해당 부분의 실제 어셈블리 코드는
@R0 D=M @END D;JEQ
인데 어셈블리어에서 작성한 @END가 어셈블리로인해 @22가 된후 기계어로 되어 롬에 올라갔고,
어드레스 레지스터에 담겨져 주소 역활을 한게 되었다.
이제야 이해된다!
그래서 어드레스 레지스터 A가
데이터의 주소, 명령어의 주소, 임시 데이터 보관 역활을 하는건가보다.
CPU
앞에서 메모리니, 어셈블리어니, 명령어니 계속 정리해왔는데, 이제 CPU를 다룰 차례가 되었다. 계속 공부해왔지만 구현했던 ALU, 레지스터, 제어기 등으로 구성되어 있다.
ALU : 이름 그대로 산술 논리 연산하는 장치이며, 구현되지 않은 기능은 하드웨어로 구현해도되고 소프트웨어로 구현해도되며 비용이나 성능, 효율성을 고려해서 설계된다.
레지스터 : 레지스터는 CPU 안에 있는 작지만 고속의 기억 장치인데 CPU가 아주 빠르게 동작하다보니, 기억 장치 CPU 밖에 있는 메모리라 한다면 메모리에 값을 잠깐 저장한다거나 원하는 값이든 명령어든 가져 오려고 하면 CPU의 작업 속도에 비해 오랜 시간이 걸려 일을 못하고 지연되는데 이를 stavation 기아 상태라고 한다. 이런 기아 상태를 방지하고, 계산 속도를 늘리기 위해 CPU 내부에 작지만 고속으로 읽고 쓰기가 가능한 기억 장치를 둔 걸 레지스터라고 한다. 일반 컴퓨터에서는 레지스터가 많이 존재하지만 우리가 만들 HACK에는 어드레스 레지스터, 데이터 레지스터 그리고 프로그램 카운터 3개 뿐이다.
제어 : 어셈블리어를 보면 알수 있지만 명령어들은 ALU에 입력으로 쓰거나, 메모리에서 가져오거나, 레지스터에 잠깐 저장하는 등 각 하드웨어 장치에 읽고/쓰기 등의 동작들 중에서 어떤 동작을 프로그램 실행중에 할지를 의미한다.
가져오기 및 실행 : fetch-execute를 가져오기 및 실행이라 적었는데, 대강 의미는 맞으니까 CPU의 과정은 명령어를 가져오고 실행하기의 반복이라 할수 있을거 같다. 에뮬레이터에서 봤지만 CPU는 프로그램이 실행되는 동안 각 사이클(클럭 마다) 명령어 메모리 ROM에서 실행할 명령어(에뮬레이터상에서는 어셈블리어지만 실제로는 이진 기계어)를 가져오게 되고 C 명령어의 c 비트에 따라 어떤 동작을 할지 해석(판단)하여 그 동작을 실행/수행 execute한다. 그래서 이 과정을 fetch-execute 사이클이라고 부르나보다.
입출력 장치
지난 장에서 설명한거지만 컴퓨터 주변장치인 키보드와 화면을 memory mapped i/o 방식으로 ram 상에 화면과 키보드의 메모리맵에 접근해서 값을 읽거나 써왔다. 이런식으로 입출력 장치를 제어하는 이유는 실제 컴퓨터 주변 장치로 키보드, 화면 뿐만 아니라 마우스, 카메라도 있을 것이고, 프린트나 다른 센서 등 수 많은 장치들이 있다. 하지만 이런 장치들 각각을 어떻게 컴퓨터와 연결해서 사용할까 각 장치가 어떤지 다 알아야할까?
그런 번거로움을 줄이기 위해서 각 장치들의 메모리 맵을 RAM의 영역에 배당하여 해당 매모리맵 영역에 접근함으로서 주변장치들을 사용가능하도록 약속한게 memory mapped i/o 방식이고 이덕분에 지난 과제에서 간편하게 스크린과 화면을 제어할수가 있었다.
오늘 새벽에 그 과제를 하면서 너무 피곤하기도 하고 시간이 늦어서 제대로 설명하지는 않았지만, 클럭 사이클마다 각 주변장치의 매모리맵을 보고 (ex. 키보드 입력이 들어오면 화면에 검은칠을 하라)원하는 동작을 하도록 처리하다보니 사람이 보기에는 알아차릴수 없을 만큼 빠르게 반영된다.
그리고 화면은 2차원 배열 형태로 되어있는데, 메모리는 1차원 주소로 접근 했었다. 그런데도 입출력 메모리 맵핑 방식으로 스크린에 접근할수 있었던건 스크린의 2차원 주소를 1차원으로 직렬화를 했기 때문이다. 일일히 적기는 번거로워서 안했지만 1차원으로 변형한 주소를 이용해서 스크린의 모든 픽셀에(정확히는 각 픽셀들을 담은 레지스터에) 접근할수 있었다.
입출력 매모리 맵핑 방식을 사용하기로 약속/표준화 하여 컴퓨터든 주변장치든 서로 상관없이 만들더라도 이런 약속을 지킨 덕분에 주변 장치의 매모리 맵을 할당하고 사용할수 있게 되었다고 이해하면 될거같다.
주변장치 인스톨러 : 그래서인가 예전에 카메라든 프린터든 새로사서 컴퓨터에서 쓰려면 그런 장치를 쓸수 있도록 설치 프로그램을 돌렸는데, 이런 설치 프로그램을 설치하면서 컴퓨터가 새 장치의 메모리 맵과 베이스 주소를 가져서 사용할수 있게 되는거고
디바이스 드라이버 : 리눅스를 공부하면서 보게되는 디바이스 드라이버도 이것도 인스톨러와 해당 입출력 장치의 메모리맵을 설정하고 물리적인 주변장치에서 값을 어떻게 가져올지를 정리하는 프로그램이라고 한다.
이제 이번장 이론 마지막으로 HACK 컴퓨터의 구성 요소들을 간단하게 보고 과제를 좀 해야겠다.
그래도 이번 장은 생각보다 빨리 정리 끝낼거같네.. 과제가 얼마나 걸릴지는 모르겠지만 ㅋㅋㅋㅋㅋㅋㅋㅋ
HACK 컴퓨터
HACK 컴퓨터는 확장자명을 hack으로 하는 기계어 프로그램을 동작시키는 16비트의 폰 노이만 구조의 컴퓨터다. 데이터 메모리인 RAM과 명령여 메모리인 ROM이 컴퓨터에 내장되며 같은 버스, 어드레스 레지스터 A로 접근해서 값 혹은 주소를 읽고 썻었다.
CPU
1) 입력
- inM은 이름 그대로 데이터 메모리에서 가져오는 값
- instruction인 A 명령어 혹인 C명령어로 A 명령어일때는 A=값, C명령어일땐 명령을 수행 or A/D/M 레지스터 중 지정된 곳에 저장(C 명령어의 목적지가 M이면 writeM은 쓰기 명령을 위해 1이되고, 그렇지 않으면 0이된다. 결과는 outM)
- reset이 0이면 다음 명령을 하지만 1이되면 프로그램 카운터가 0을 가리킨다.
* 주의사항 : 출력 outM과 writeM은 조합 논리회로로 구현되서 명령어 실행 즉시 반영된다!
출력 addressM과 pc은 순차 논리회로로 구현되어 다음 타임 스탭, 클럭에서 반영된다.
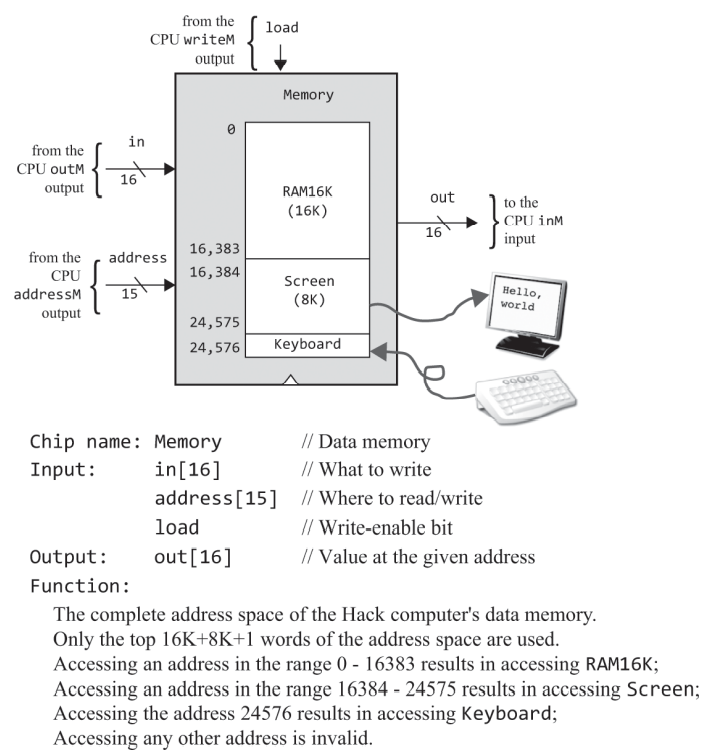
명령어 메모리
ROM32K이기도 하며, 0000 0000 0000 0000 ~ 0111 1111 1111 1111 2^15(32K)만큼 접근할수 있고, 한 레지스터가 16비트로 이뤄지다보니 출력은 16비트 크기를 갖는다. ROM이다 보니 어드레스로 접근은 해도 쓰기 작업은 없어 in이나 load 단자는 없다.
입출력 장치
화면과 키보드는 데이터 메모리 RAM에 매핑되어 사용되고, 클럭마다 반영되는데 이 장치들의 매모리 맵을 별도의 빌트인 칩인 Screen과 Keyboard으로 다룬다고 한다. 이것들이 따로 있다는건지 아니면, 램 상에 들어있는걸 칩이라고 부르는지는 잘 이해는 안되지만 일단은 좀 더보자
화면 메모리 맵 : 쓰기 작업을 하다보니 전에 구현한 RAM과 비슷하게 address와 load 입력을 받는다. 차이라면 스크린 공간이 8K다보니 주소가 13비트 입력으로 되어있다.
키보드 메모리 맵 : 키보드 베이스 어드레스의 위치에 있는 레지스터 하나의 값으로 키보드 입력을 나타내다보니, 입력 값이나 주소가 필요없고, 16비트 출력만 내보낸다.
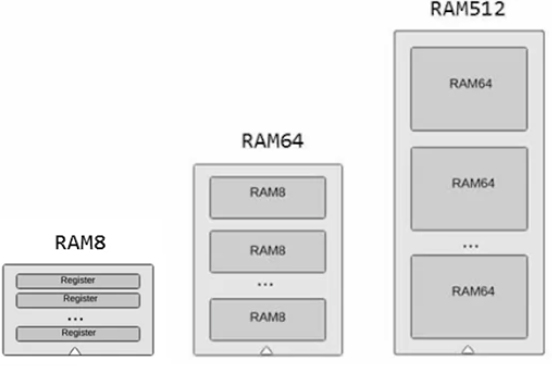
데이터 메모리 RAM
앞서서 스크린과 키보드를 칩으로 나타내고 있으니까 순간 혼동했는데 RAM4K, RAM16K를 구현할 떄 처럼 저만 스크린, 키보드 칩은 그냥 저 크기를 가지는 주변장치의 입출력을 저장하는 기억장치였다. 이 주변장치들이 RAM 안에 포함되어 있어서 16K와 합친다고 별도의 칩으로 표현해놓은 것이고, 결국에는 RAM = RAM16K + 스크린(RAM8K) + 키보드(레지스터, 읽기전용) 하여 데이터 메모리를 구현하나보다.
컴퓨터
드디여 난드 투 테트리스의 마지막 하드웨어인 컴퓨터를 구현할 차례다. 프로그램을 어떻게 집어 넣는지는 아직 잘은 모르겠지만 앞서 만든 CPU와 RAM, ROM을 잘 조합한게 컴퓨터이고, 이 컴퓨터는 reset 입력만 받는다. 0일때는 그대로 프로그램 카운터 진행되는데로 연산하지만 reset 1이 되었다가 0이되면 프로그램 카운터가 0이되어 다시 시작한다.
와 벌써 하드웨어 마지막 과제라니 내가 이걸 주말부터만들기 시작해서 이제서야 5장까지 왔다.
책 페이지로는 1/3 조금 넘게 밖에 못온게 너무 충격이긴한데,
디지털 논리회로만 넘기면 나머지는 쉬울줄 알앗지만 장난아니었다.
2년전에 ALU하다가 포기하기도 했었고
이번에 다시하면서 처음에 논리회로 만들때만 해도 포기하고 싶었는데 계속 하다보니까 컴퓨터 구현까지
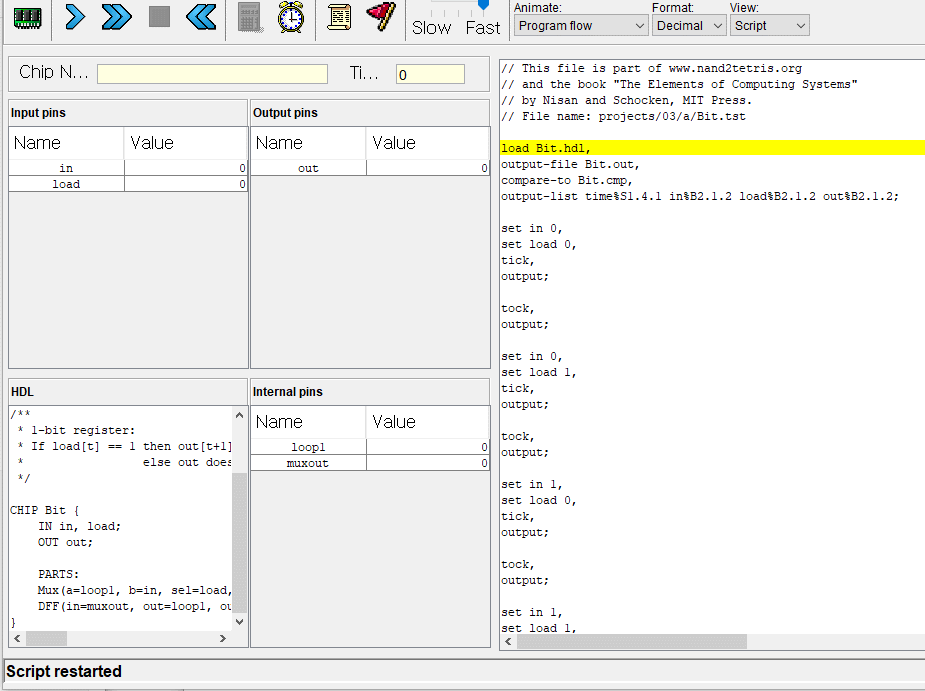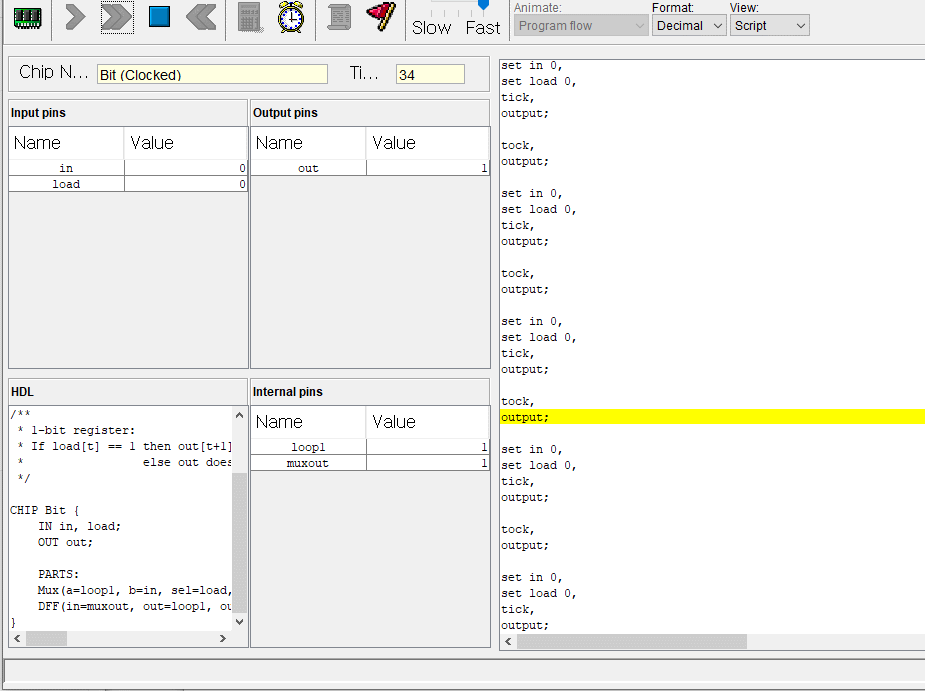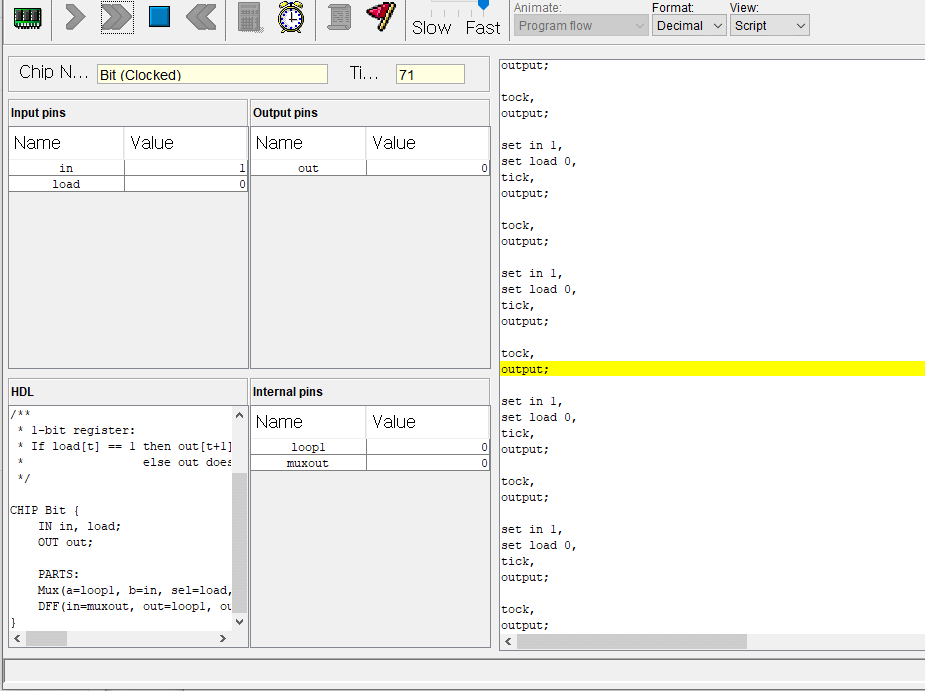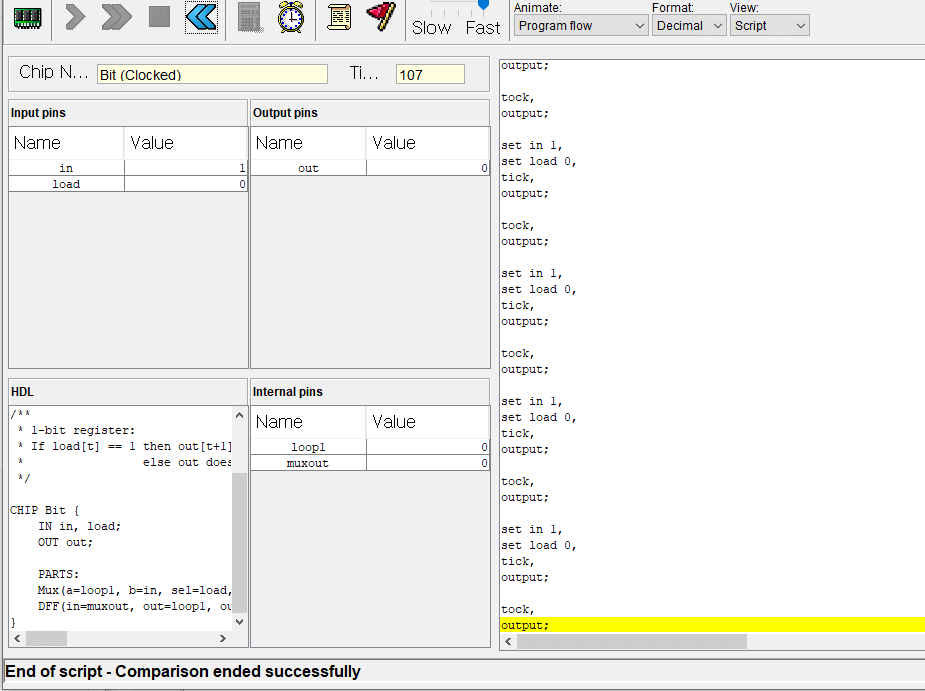
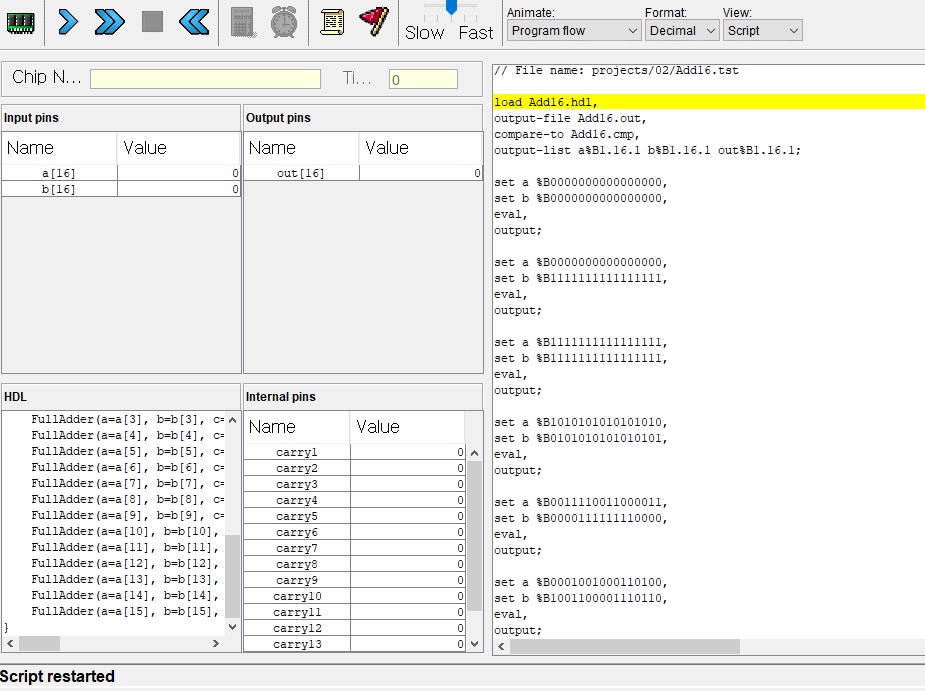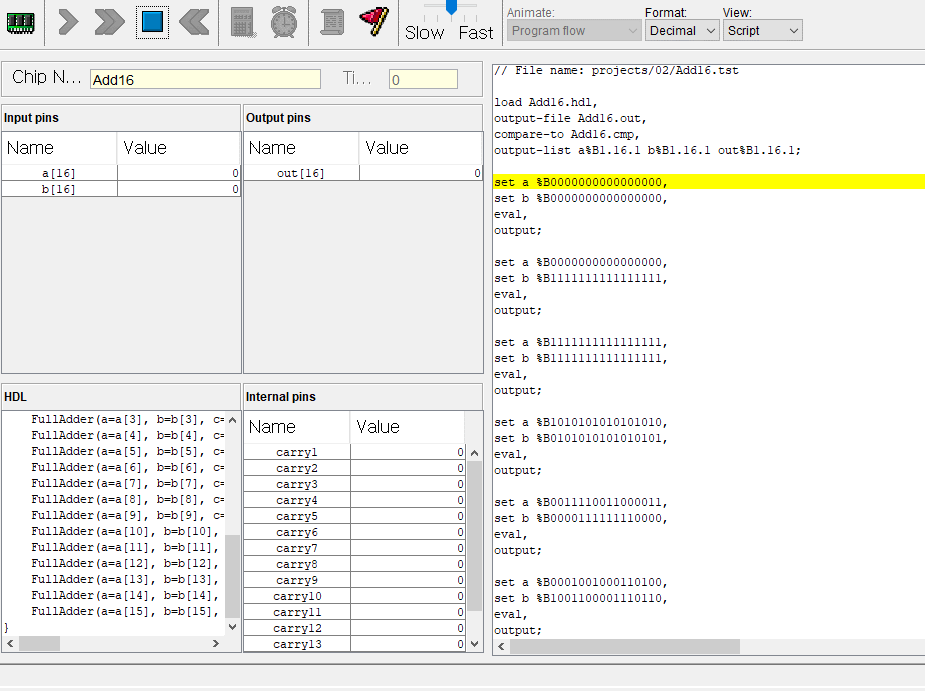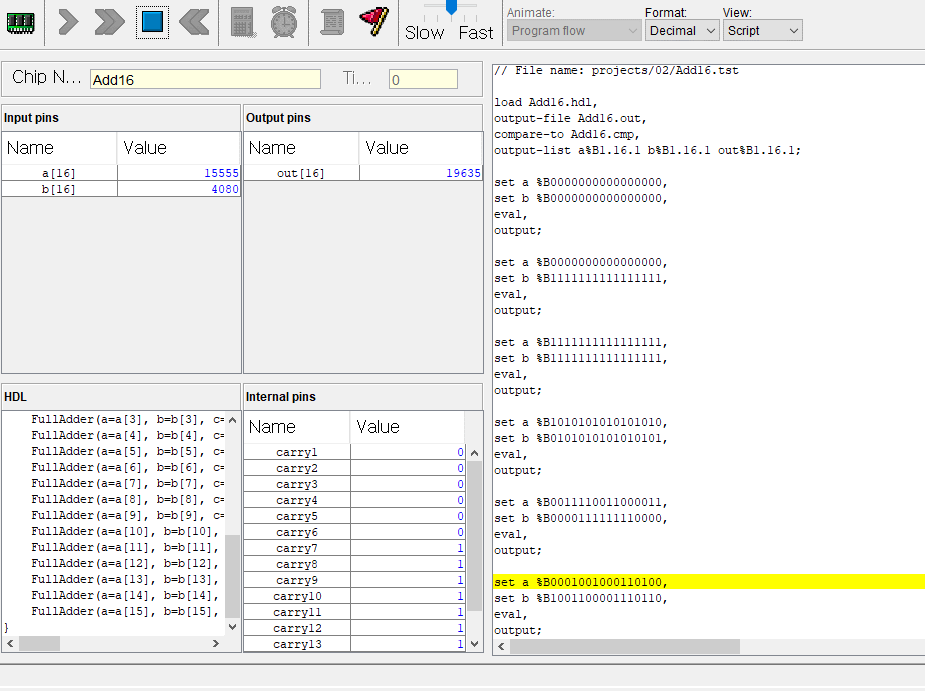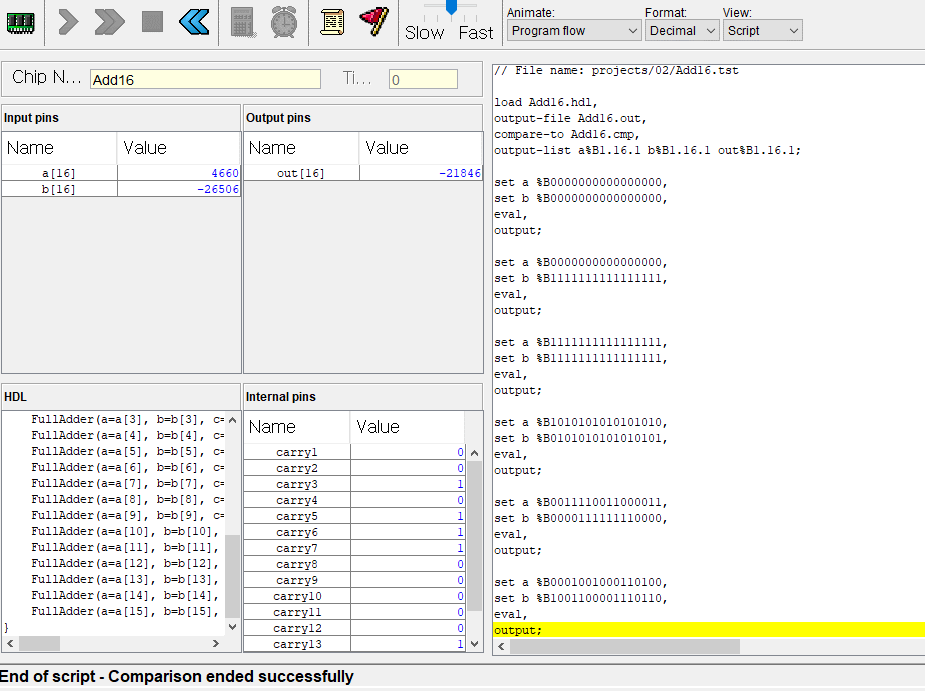
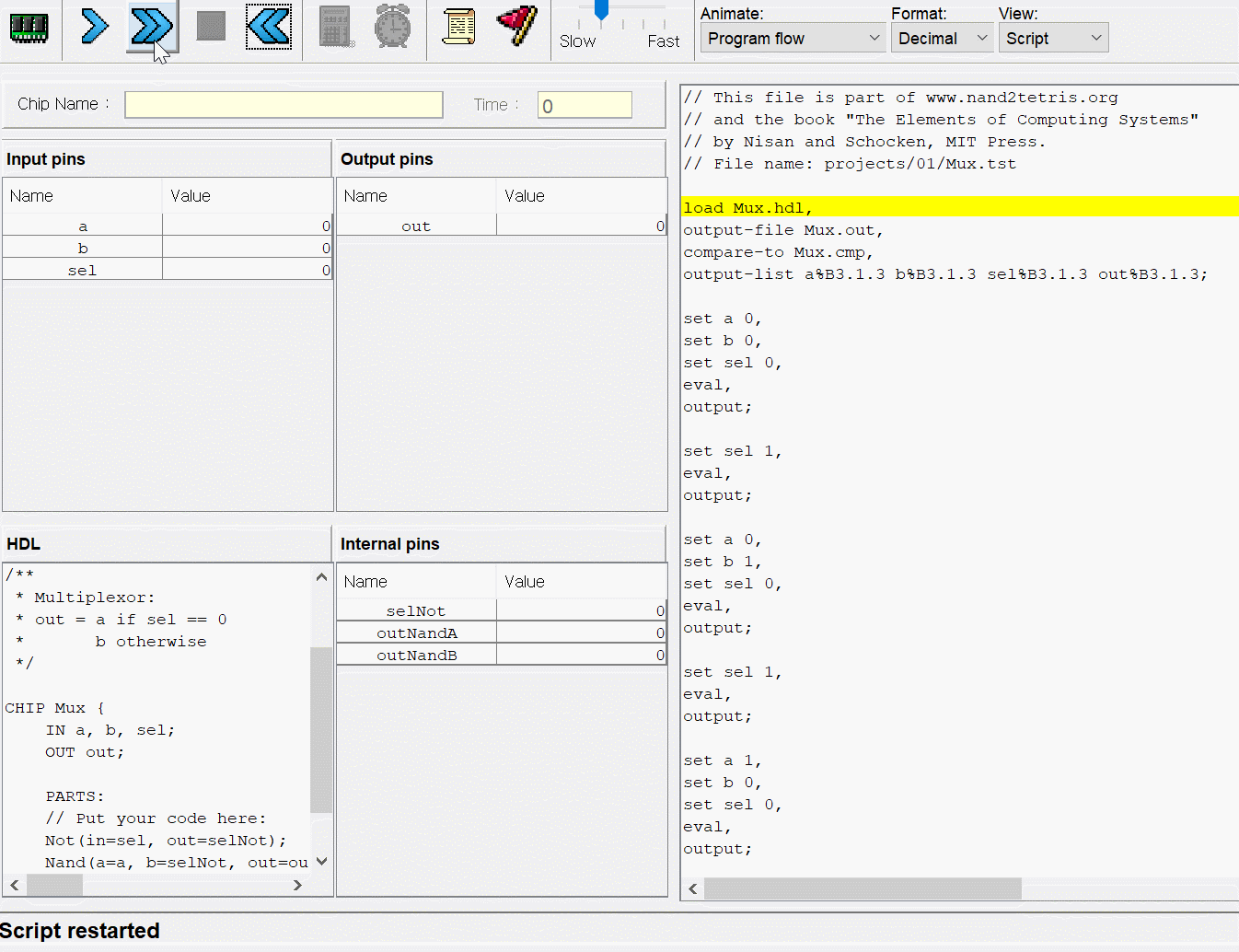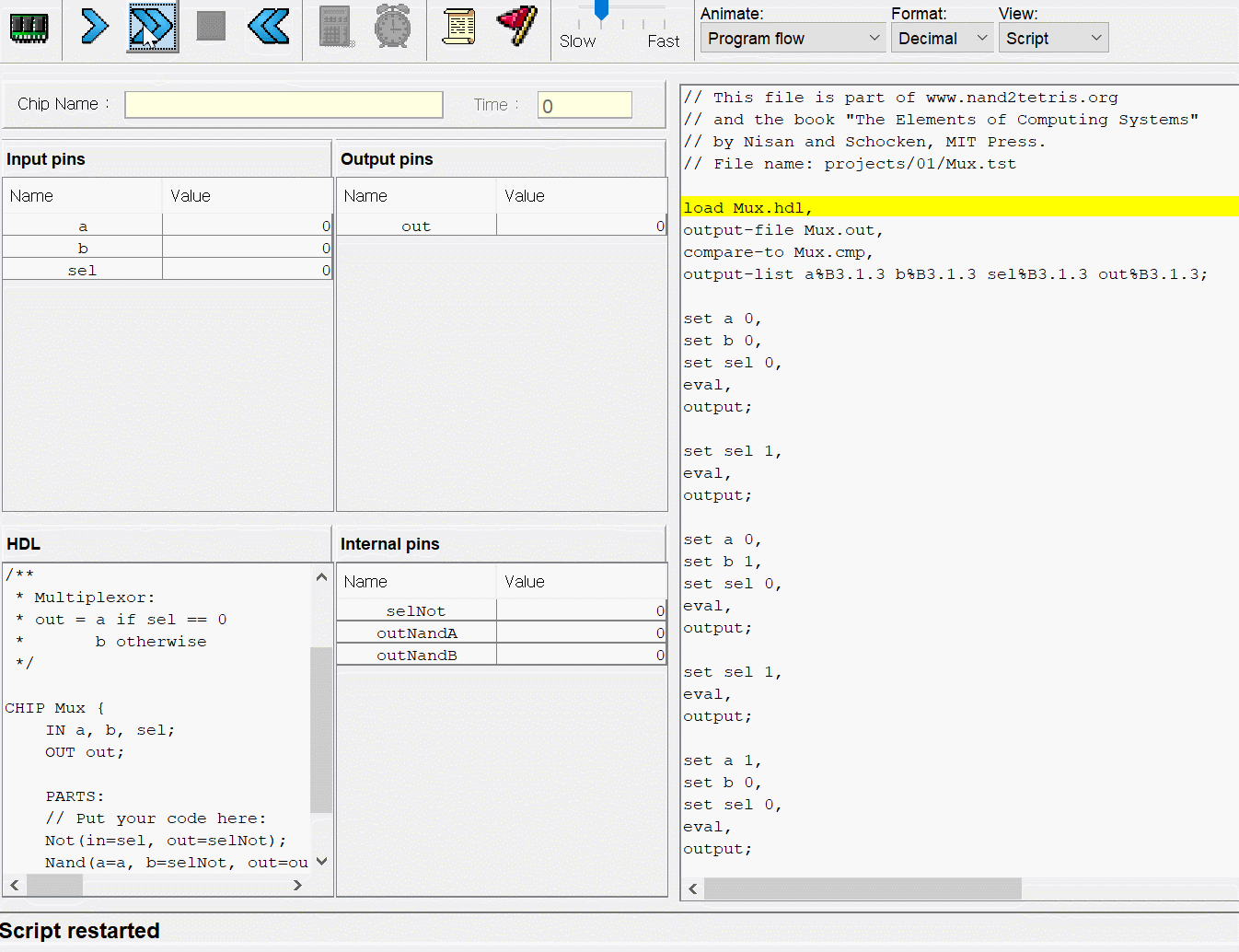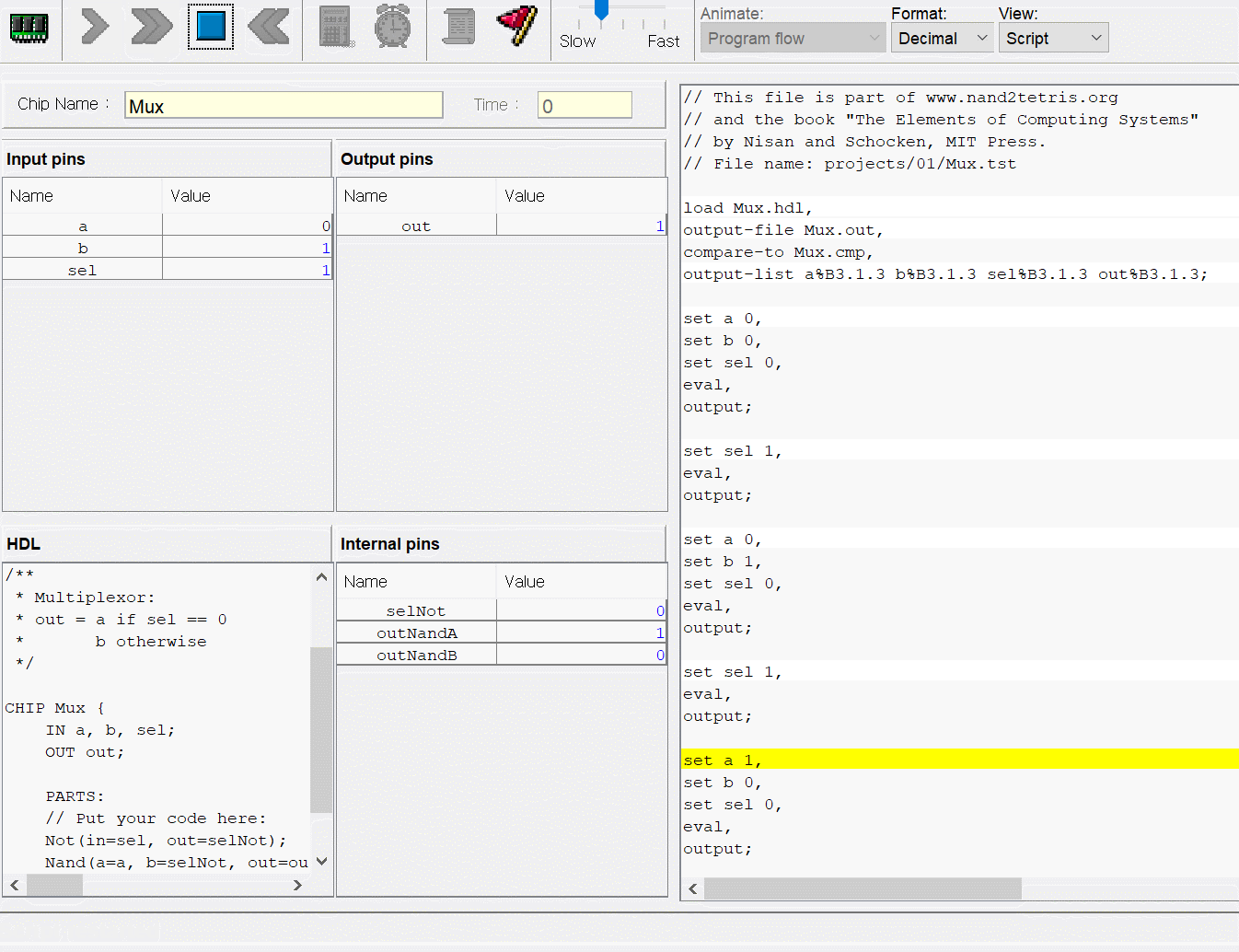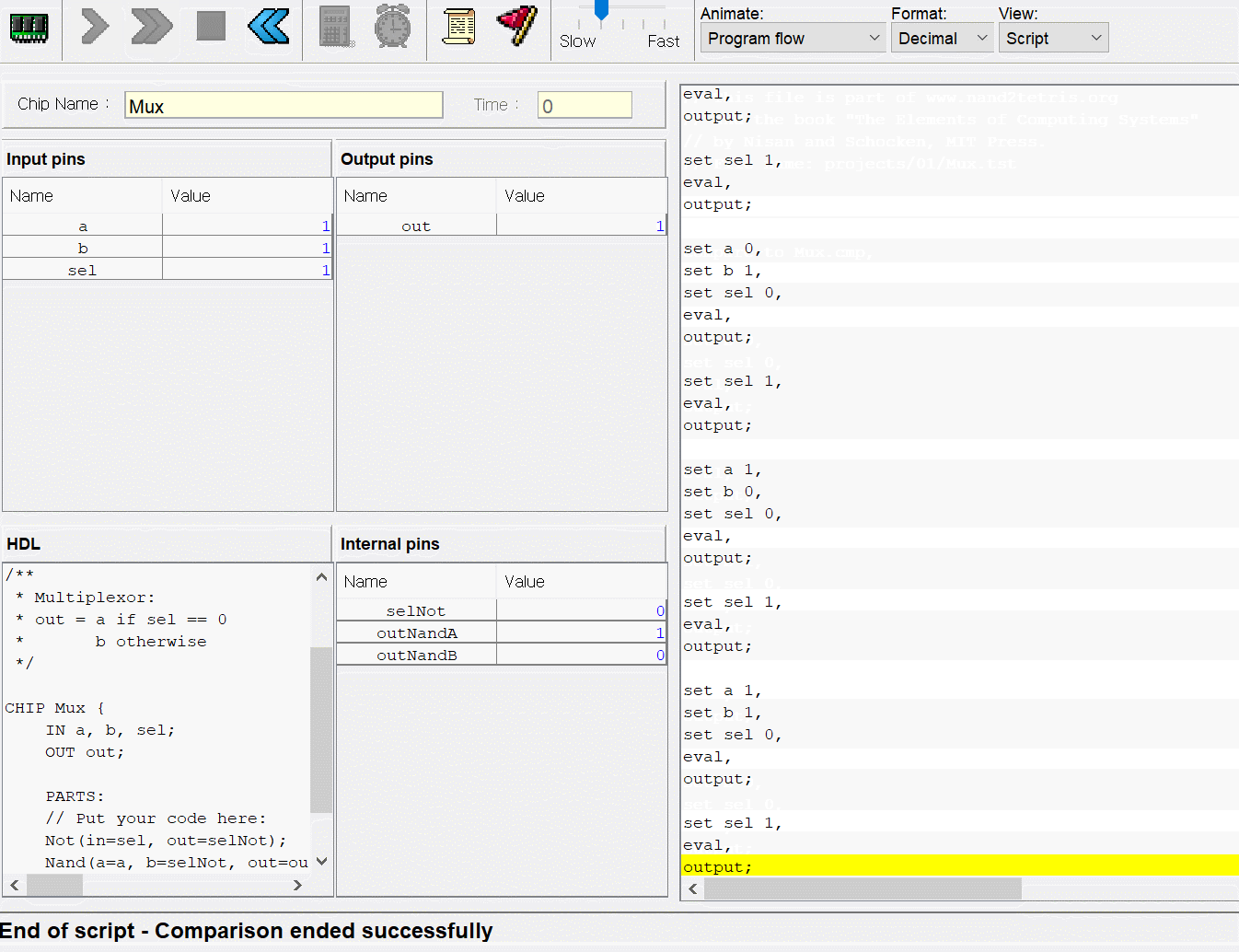
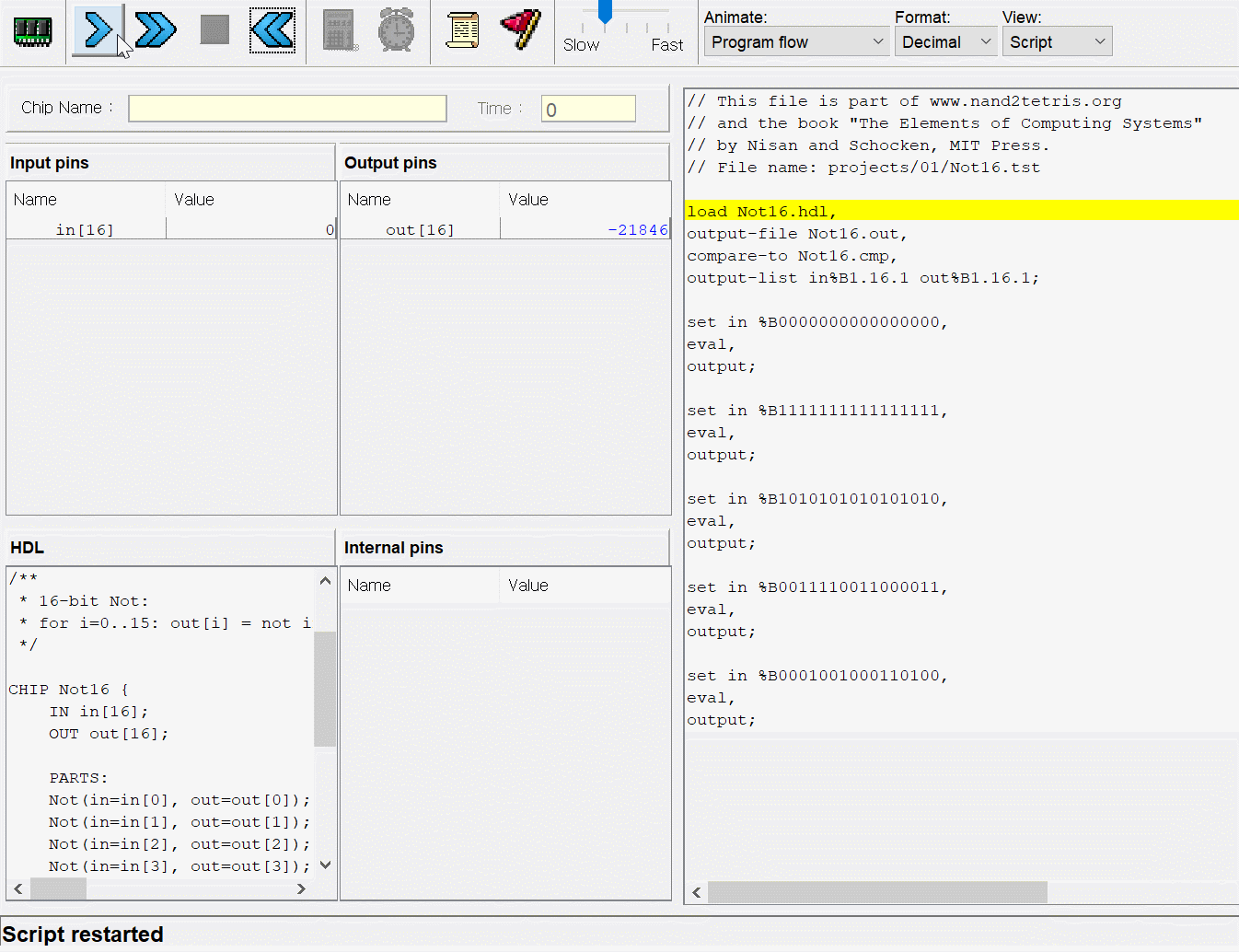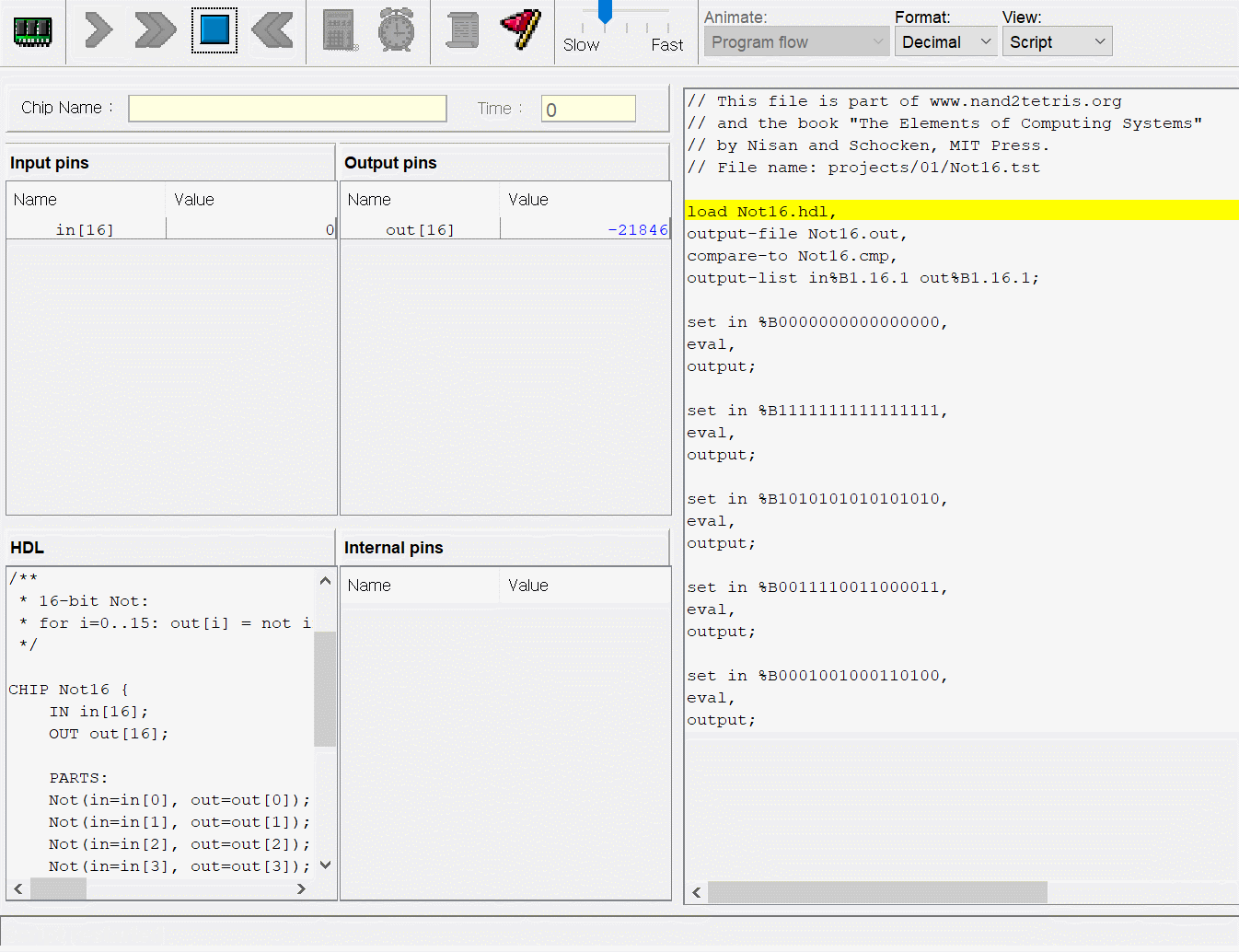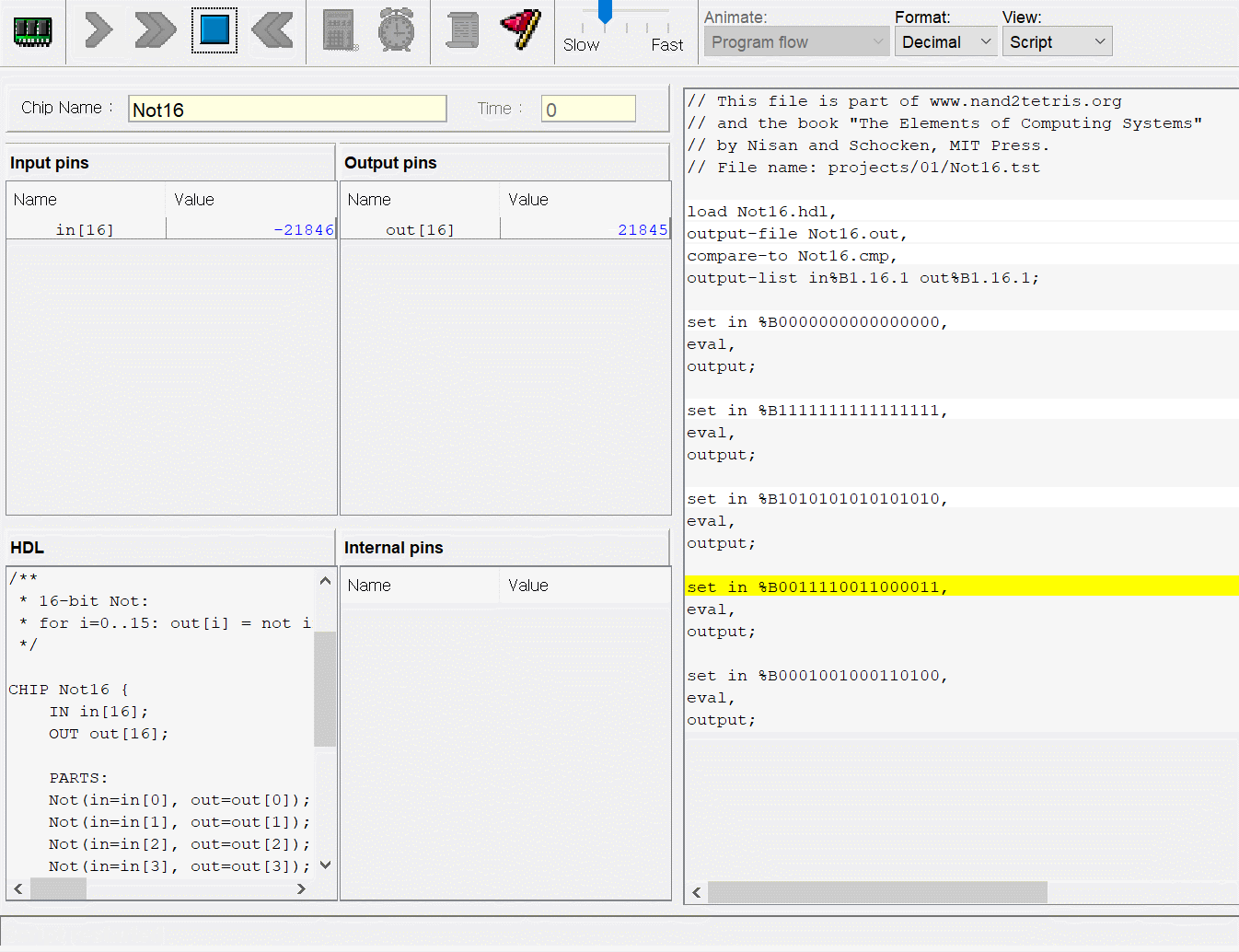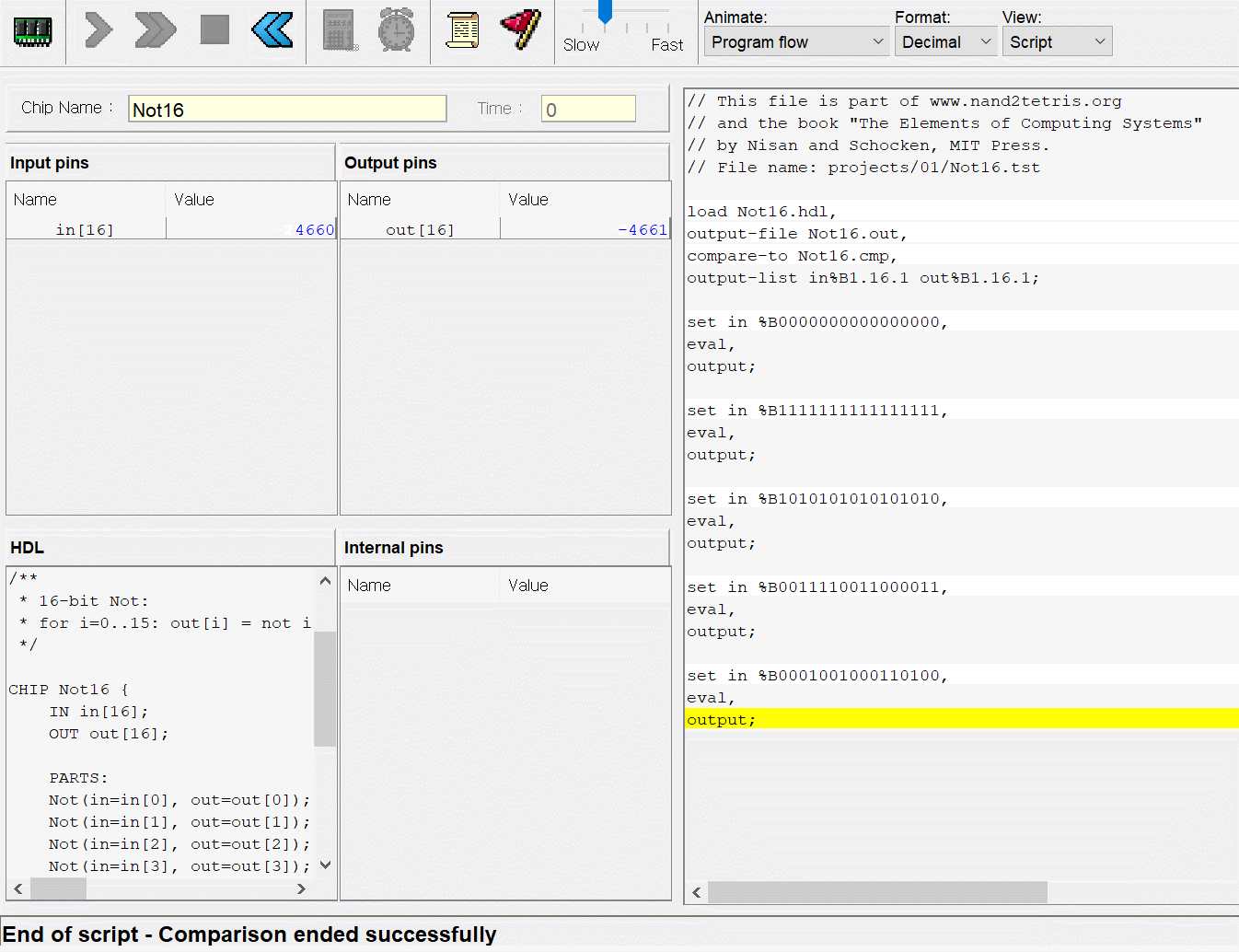
// This file is part of www.nand2tetris.org// and the book "The Elements of Computing Systems"// by Nisan and Schocken, MIT Press.// File name: projects/04/mult/Mult.tst
load Mult.asm,
output-file Mult.out,
compare-to Mult.cmp,
output-list RAM[0]%D2.6.2 RAM[1]%D2.6.2 RAM[2]%D2.6.2;
set RAM[0] 0, // Set test argumentsset RAM[1] 0,
set RAM[2] -1; // Test that program initialized product to 0repeat20{
ticktock;
}set RAM[0] 0, // Restore arguments in case program used them as loop counterset RAM[1] 0,
output;
set PC 0,
set RAM[0] 1, // Set test argumentsset RAM[1] 0,
set RAM[2] -1; // Ensure that program initialized product to 0repeat50{
ticktock;
}set RAM[0] 1, // Restore arguments in case program used them as loop counterset RAM[1] 0,
output;
set PC 0,
set RAM[0] 0, // Set test argumentsset RAM[1] 2,
set RAM[2] -1; // Ensure that program initialized product to 0repeat80{
ticktock;
}set RAM[0] 0, // Restore arguments in case program used them as loop counterset RAM[1] 2,
output;
set PC 0,
set RAM[0] 3, // Set test argumentsset RAM[1] 1,
set RAM[2] -1; // Ensure that program initialized product to 0repeat120{
ticktock;
}set RAM[0] 3, // Restore arguments in case program used them as loop counterset RAM[1] 1,
output;
set PC 0,
set RAM[0] 2, // Set test argumentsset RAM[1] 4,
set RAM[2] -1; // Ensure that program initialized product to 0repeat150{
ticktock;
}set RAM[0] 2, // Restore arguments in case program used them as loop counterset RAM[1] 4,
output;
set PC 0,
set RAM[0] 6, // Set test argumentsset RAM[1] 7,
set RAM[2] -1; // Ensure that program initialized product to 0repeat210{
ticktock;
}set RAM[0] 6, // Restore arguments in case program used them as loop counterset RAM[1] 7,
output;
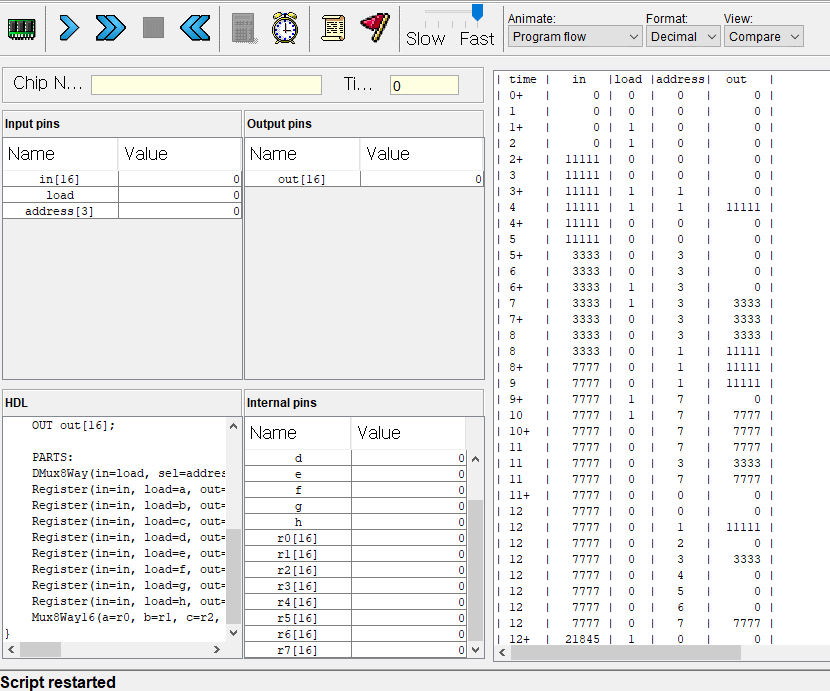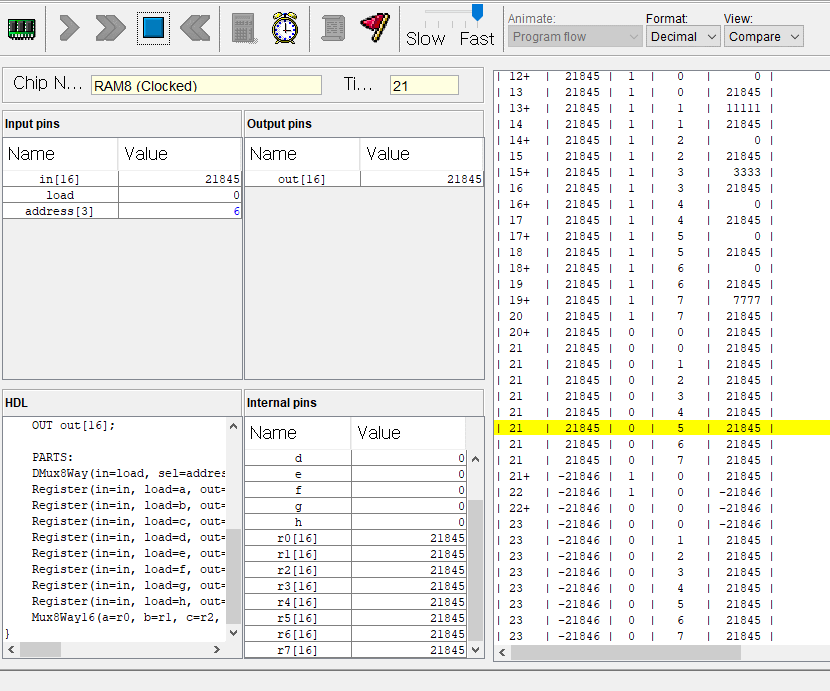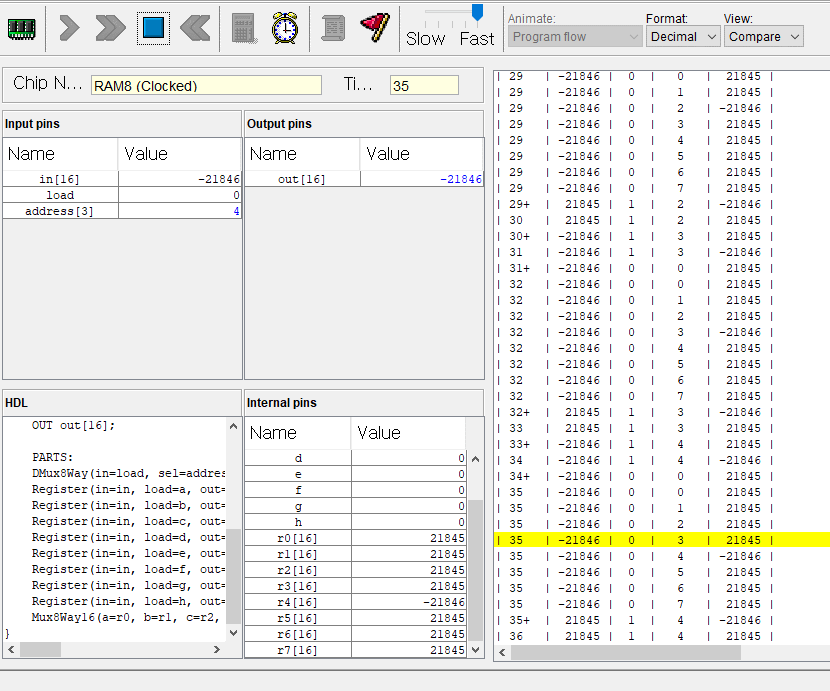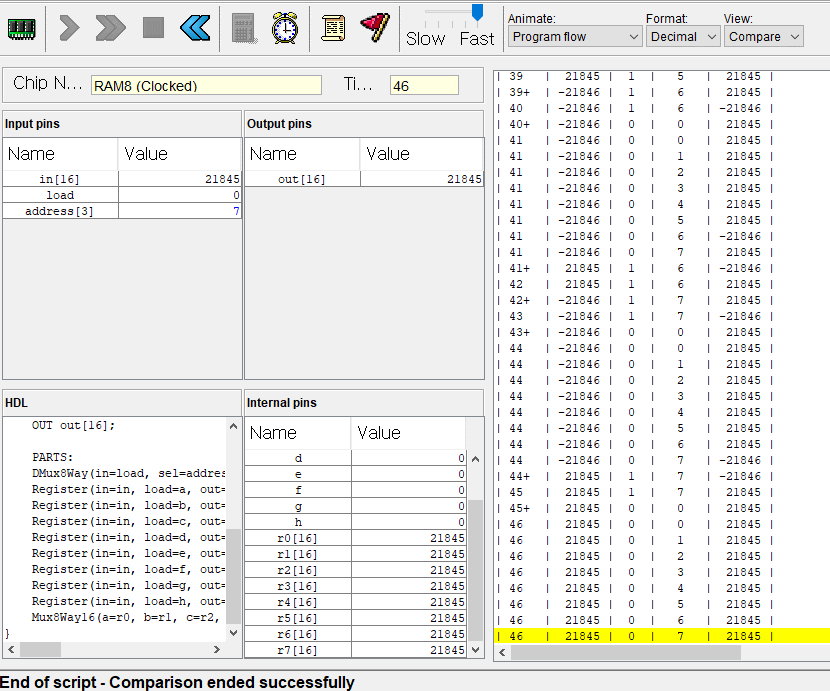
사용한 테스트 스크립트는 이건데
ALU로 M=M+D 연산이 가능한걸 잊어버리고,
+1연산으로 이중루프를 만들어 곱셈 연산을 구현하느라
클럭 루프를 너무 많이 돌아버렸고,
앞에 작은 수를 다루는 경우는 문제 없었지만
마지막 6 * 7 예제에서 210회 클럭안에 수행해야하는데
M=M+D 연산으로 하면 금방할걸
+1연산으로 구현해 놓으니 210회 클럭안에 연산을 마치지 못해서 자꾸 에러뜨길래
이게 라인 수가 너무 많아서 그런갑다 싶어 라인 수를 줄이느라 시간낭비했다.
그러다가 갑자기 +1 안해도 되는게 생각나서 했더니 20분도 안걸리고 해결했다 ㅜㅜ
아아아아아ㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏ
이거에서 해매지만 않았어도 진작에 입출력 제어 끝내고 다음 장으로 넘어갈텐데
곱셈 연산 해결한게 밤 11시 30분이라
입출력 헨들링까지 하고 글 정리하고 가면 좀 더 지나야 갈수있을거같다.
Mult_v1.asm
Mult_v2.asm
Mult_v3.asm
//210 클럭안에 6 * 7 곱연산을 마무리하지 못해 실패 @0 // init R2 as 0 D=A @R2 M=D @R0 // if R0 or R1 == 0 -> end D=M @BIG_STOP D;JEQ @R1 D=M @BIG_STOP D;JEQ @j // init j(=R0) - j * i = result M=1 (BIG_LOOP) //--start of big loop-------------------------------- @j // make big loop end condition value D=M @R0 D=M-D @BIG_STOP // if (R0 - j < 0 ) goto BIG_STOP r0 = 3, d = 4 => 3-4 < 0 D;JLT @i M=1 (SMALL_LOOP) // -----------start of small loop-------------- @i //make small loop end condition value D=M @R1 D=M-D @SMALL_STOP // if (R1 - i < 0 ) goto SMALL_STOP r1 =5, i = 6 -> 5 - 6 < 0 D;JLT @R2 //small loop start M=M+1 @i M=M+1 @SMALL_LOOP // goto small loop 0;JMP (SMALL_STOP) // -----------end of small loop-------------- @j //start big loop M=M+1 @BIG_LOOP 0;JMP //goto big loop (BIG_STOP) //--end of big loop-------------------------------- @BIG_STOP 0;JMP
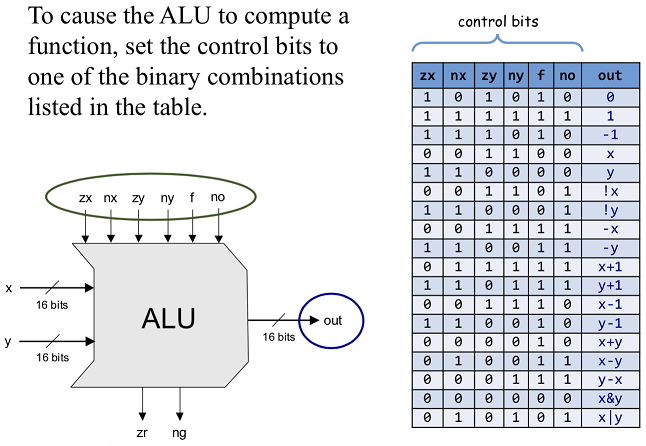
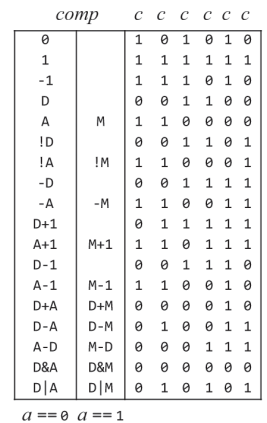
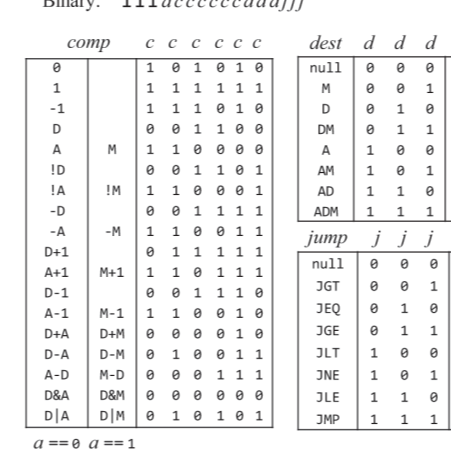
C명령어는 연산 비트(comp, 7비트), 목적지 비트(dest, 3비트), 점프 조건 비트(jmp, 3비트) 세 부분으로 111accccccdddjjj 같이 구성된다.
(1) acccccc : 7비트로 ALU가 수행할 연산을 결정하는 comp 비트
* 위 표에 나오다 시피 a가 0일때와, 1일때 수행하는 연산이 따로 나눠져있다.
(2) ddd : 3비트로 ALU 연산 결과를 담을 목적지를 나타내는데 저장하지 않을지(null), M에 담을지(RAM[A]), D 레지스터에 담을지, A레지스터 D레지스터 둘다에 연산 결과를 담을지 등 이 세 비트의 값으로 결정한다.
(3) jjj : 3비트로 이뤄진 어떤 조건에 따라 점프를 할지를 의미하는 비트로 000인경우 점프 안함, 001 인경우 JGT로 연산 결과가 0보다 클때 점프, 111일때는 연산 결과에 상관없이 무조건 점프하는 JMP 명령이된다.
C 명령어의 연산 comp
2장에서 ALU 구현한걸 다시 떠올리면, 두 16비트 입력을 받도록 되어있었다. 그러면 이 두 입력을 가지고 어떻게 기계어로 연산을 할수 있을까? 첫번째 입력 x는 데이터 레지스터 D에 있던 값을, 두 번째 입력 y는 어드레스 레지스터 A로 지정한 데이터 메모리 레지스터 M에 담아둔 값을 사용한다.
(이부분이 조금 햇갈리긴한데 그냥 진행한다)
한번 comp의 입출력, ALU 상태 비트의 입출력 테이블을 같이 보면
comp 명령에서는 a가 0이고, cccccc가 001100일때 D의 값을 가져오고
ALU 상태 입력이 comp의 c비트와 동일하게 001100일때 x를 출력으로 하는걸 볼수있다.
그러니까 c가 001100 이더라도 a가 0일때는 데이터 레지스터 D, 1일때는 데이터 메모리 레지스터 M에있는 값을 가져온다.
ex) 심볼릭과 기계어로 D에 31, RAM[24]에 13이 들어있을때 D + M 연산해서 RAM[24]에 저장하자.
=> RAM[24] = 31 + 13
심볼릭
기계어(가독성을 위해 4비트씩 띄워쓰기함)
//1. RAM[24]에 13넣기 @13 D=A @24 M=D
//2. D = 31 @31 D=31
//3. D+M 후 RAM[24]에 쓰기 @24 M=D+M
0000 0000 0000 1101 // A명령어 13 1110 1100 0001 0000 // C 명령어 A를 로드해서(110000), D에다 저장(010), jmp안함(000) 0000 0000 0001 1000 // 24 1110 0011 0000 1000 // D의 값을 M에 쓰기 RAM[24]에 13넣기 끝
// 변수 i, sum 초기화 @i M=1 @sum M=0 (LOOP) // loop문 시작 @i D=M // D(i)-M(R0) = 0이면 i가 R0의 값과 같다 = i가 N까지 도달하였다. @R0 D=D-M // 모든 수를 더하였으므로 루프를 그만하고 (STOP) 문으로 넘어간다. @STOP D;JGT // STOP으로 점프하지 않았다면 루프를 진행하면 되니 sum = sum + i 연산 하자
@sum D=M @i D=D+M @sum D=M // sum + i 연산을 한 뒤 i = i+1을 하자 @i M=M+1 // 다시 루프 시작으로 가자 @LOOP 0;JMP (STOP) // 루프 종료 조건 충족시 아래의 루틴 진행 @sum D=M @R1 M=D (END) @END 0;JMP
진짜 A 명령어와 C명령어의 내용이 너무 햇갈린다. C 명령어의 dst와 jmp 둘다 쓸수 있지 않은지, 둘다 동시에 쓴다면 C 명령어 앞에 @R3이 있다면 R3의 값을 가져와서 1. dst 비트에 따라 M or A or D 에다가 C명령어의 연산 결과를 담고, 2. R3으로 JMP 간다고 생각하면 될까? 아니면 dst와 jmp를 동시에 쓰지 않고 dst만 하던가 jmp만 하는지. 지금까지 본 내용들을 보면 jmp와 dst 를 동시에 쓰는것 같지는 않다.
또 A 명령어의 값이 RAM과 ROM의 주소를 동시에 나타대나보니 C 명령어와 함께 너무 햇갈리게 되는데, 뒤에 오는 C 명령어에 M이 존재하는지 여부에 따라 A가 RAM 혹은 ROM의 주소를 나타내는지 판단할 수 있다.
뒤에 오는 C 명령어가 M을 사용하는 경우 => A 명령어의 값을 RAM의 주소로 쓴다
C 명령어로 점프를 사용하는 경우 => A 명령어의 값을 ROM의 주소로 쓴다
위의 두가지 경우 정도로 이해하고 넘어가자
hack 어셈블리어의 심볼
지금까지 본 심볼들은 숫자, 상수와 달리 의미를 가진 알아볼수 있는 문자였다. 어느 위치에 접근할 때마다. 숫자를 주소로 하여 사용하기도 하고, 위의 예시에선 i나 sum 같이 변수를 이용해서 값에 접근하기도 하였다. 근데 지금까지 본 어셈블리어에서는 i, 4 같은 숫자와 문자 뿐만아니라 R1, R3, (LOOP), (END) 같은 다른 것들도 있었는데 이 심볼들은 무엇일까? hack 어셈블리어에는 우리가 만든 심볼 외에도 미리 정의된 심볼들이 있다.
미리 정의된 심볼들
1. R0, ..., R15(가상 레지스터)
hack cpu는 16개의 레지스터를 가지고 있으며 R0은 RAM[0] ~ R15는 RAM[15]이 주소를 가지고 있다. A 레지스터가 주소 값으로 사용 될 때 @3의 경우 @R3가 동일한 동작을 한다고 할수 있긴 하지만, 미리 정의된 심볼을 사용하여 @3은 (확실하진 않지만) 데이터 레지스터로 사용되고 있구나, @R3은 데이터 메모리 주소로 사용되구나를 짐작할수 있는 장점이 있다.
2. SP, LCL, ARG, THIS 등
가상 레지스터 이외에도 스텍 포인터를 나타내는 SP, LOCAL 등 다른 미리 정의된 심볼들이 있지만 가상 머신을 배울때 다루므로 일단 넘어가자.
3. SCREEN, KBD
hack 컴퓨터는 IO장치로 스크린과 키보드를 사용하고 있다. 이 장치들을 사용하기 위해서 memory maped IO, 그러니까 스크린의 메모리 영역에 값을 쓰면 화면상에 표시되고, 키보드의 특정 키를 누르면 해당 키와 매핑된 메모리 주소의 값이 1이되는 식의 형태인데 이 미리 정의된 심볼들은 스크린 매모리맵, 키보드 매모리맵의 시작 주소 base address를 나타낸다. 이 내용은 5장 쯤에 다룬다.
4. 라벨 심볼
이 외에도 앞서 루프문 예제에서 봤듯이 (LOOP), (STOP), (END)와 같이 (내용)과 같은 형태의 심볼을 봤는데 이러한 심볼들을 라벨 심볼이라 한다. 이 라벨 심볼은 바로 다음에 나오는 명령어의 주소를 가리키고 있어 점프 시 라벨 심볼 뒤의 명령어를 시작하게 된다. 그리고 이 라벨 심볼은 대문자로 써야한다.
일반 변수 심볼
앞서 4가지의 미리 정의된 심볼에 대해서 정리하였고, 이런 심볼들 외 i, sum, x같은 것들을 변수 심볼이라 하며 @3을 사용했을때는 숫자 주소라 했지만 @i 일때는 어느 주소를 의미하는지 아직 알아보지는 않았는데 이는 어셈블리 파트에서 배울 수 있다.
우리가 이미 만든 alu로 and 연산을 하든 +1 연산을 하는든 뭔 연산을 할때의 기계어와
수정한 프로세서로하는 and 연산, +1 연산을 하도록 하는 기계어가 다를 것이다.
그래서 한 프로세서의 기계어는 다른 프로세서에서 사용할수 없으며
이를 하드웨어에 의존적이다. 호환되지 않는다는 식으로 표현한다.
x86이니 x64니 arm이니 코어텍스가 뭐니 하는 내용까지는 제대로 정리해본적이 없어서 설명할수는 없지만
이런 이유로 저급언어는 각 프로세스마다 다르기 때문에 하드웨어에 의존적이라고 한다.
하지만 고급언어는 어떨까?
처음 C언어나 Java, 파이썬 같은 언어를 공부할 때 이식성이 좋다,
하나의 코드로 여러 플랫폼에서 사용가능하다는 식으로 설명한다.
나도 처음에 수업 들을때 아무도 이거에 대해서 제대로 설명해주질 않아서
이식성이 좋다는게 무슨 의미인지는 잘 모르지만, 그냥 그러려니 하고 넘어갔었다.
이걸 공부하면서 조금 더 와닿게 이해할수 있는데,
여기서 이식성이 좋다는 말은 어느 환경에서 코드를 작성하던 간에
이 프로그램을 리눅스면 리눅스, 윈도우면 윈도우, x86, atmega이든지
각 프로세서가 뭔지 동작 할 환경을 선택해서 컴파일하기 때문에
하나의 코드로도 사용하는 컴파일러나 가상머신에 따라
해당 프로세서에 적합하게 기계어/바이너리를 만들어내어
똑같은 코드지만 안드로이드에서도 돌아가고 윈도우에서 돌아가고, 다른 MCU 등
다양한 환경에서 실행가능하게 된다는 의미로 이식성, 호환성이 좋다고 하는 거더라
하지만 이런 고급언어와 컴파일러같은걸 생각안하고
직접 어셈블리어든 기계어를 바로 작성 한다면 프로세서 마다 다르게 작성해줘야 할거다.
기계어와 구성 요소
그러면 기계어에는 어떤 것들이 있을까?
이미 알겠지만 이진수로 된 바이너리와 알아볼수 있는 문자로 된(=심볼릭한) 어셈블리어가 있다.
저자가 말하기를 기계어로 직접 코딩하는 사람은 많진 않지만 이런 저수준 프로그래밍을 할 수 있다면
우리가 일반적으로 쓰는 고급 언어의 동작을 더 잘 이해하고 효율적으로 작성할수 있게 된다고 한다.
이미 앞에서 말한거지만 기계어는 단순한 0과 1의 조합에서 조금 더 정확하게 이야기하면
프로세서가 레지스터와 메모리 사이에 값을 읽고 쓰도록 제어하도록 만든 동작 과정인데
메모리는 명령어와 데이터들을 저장하는 장치로, 지난 장에서 메모리를 만들때 봤다시피 한 레지스터마다 고유의 주소를 가지고 있어 우리는 이 주소값을 이용하여 해당 메모리에 접근해 값을 읽거나 덮어씌운다.
프로세서(CPU)의 경우 구성요소 중 하나인 ALU를 구현했을때 봤다시피 산술, 논리 연산뿐만이아니라 기억장치에 접근하고, 분기 연산을 수행가능하도록 만든 장치라 할수 있다. 분기 연산이 어떻게 되는지는 아직 보지는 않았지만 2장 과제를 하면서 이 게이트, 저게이트 합쳐서 만든 ALU가 실제로 산술논리 연산하는것을 시뮬레이션을 돌리면서 봤었다.
프로세서는 레지스터라고 하는 작은 기억장치를 가지고 있는데, 레지스터의 경우 프로세서가 메모리를 접근해서 값을 읽고 쓴다고 했었지만 프로세서와 메모리 사이의 거리는 사람 기준으로 가깝다 해도 컴퓨터의 동작 클럭을 생각하면 너무 먼 거리고 시간도 오래걸릴것이다. 그래서 다양한 이유로 CPU 내부에 사용할수 있도록 만든 작지만 고속의 기억장치를 레지스터라 한다.
잠깐 딴 소리지만 레지스터에 대해서 정리하다가 생각난게 그 동안 이전에 컴공 공부하거나 자격증 준비하면서 SRAM은 정적인 비활성메모리다, DRAM은 동적인 비활성메모리다. 정도로만 이해하고 있다가. 전기 자격증도 준비하고, 폴리텍에서 공부하면서 SRAM과 DRAM에 대해서 조금 더 자세히 알게 되었었는데,
SRAM의 경우 플립플롭을 이용해서 만든 저용량이지만 고속의 기억장치로 케시메모리로 사용되고,
DRAM의 경우 캐패시터를 이용해서 만든 기억장치로 케시메모리에 비해 느리지만 큰 용량이라 메인 메모리로 사용된다고한다.
전처럼 아예 책 번역하는게 아니라 생각 정리하는건데도 생각보다 오래걸린다..
아무튼 다시 레지스터로 돌아와서 다른 cpu도 비슷하겟지만 hack의 레지스터로는 값을 저장하는 데이터 레지스터와 데이터 값 또는 메모리 주소를 저장하는 어드레스 레지스터 두 종류가 있고, 어드레스 레지스터가 가진 주소값에 접근하여 값을 읽고 쓰게 된다. 지난 렘 시뮬레이션때는 어드레스 레지스터의 값은 아니지만 .cmp 파일에서 지정한 주소에 접근해서 값을 읽고 쓰는고 원하는 결과가 나왔는지 비교하는 시뮬레이션을 돌렸었다.
기계어 : 바이너리와 심볼릭
아까 기계어는 2진수 바이너리와 사람이 알아볼 수 있는 심볼릭(=어셈블리어 같은거) 두 가지가 있다고 했다.
R1 + R2한 결과를 R1에다가 저장하라는 연산을 바이너리랑 심볼릭으로 적어본다고 하자.
기계어로 쓸때 덧셈 연산을 6비트로 101011, R1과 R2 레지스터는 각각 5비트로 00001, 00010이라 할때 이들을 합쳐 16비트 바이너리 코드로 만들면 1010110001000001 -> 101011(add)/00010(R2)/00001(R1)이 된다.
심볼릭 하게 쓴다면(어셈블리어는 아니지만, 뭔소린지 알수있게) set R1 = R1 + R2 같은 식으로 될거같다.
심볼릭을 보면 R, 1, 2, + 같은 심볼(상징, 부호, 기호라고 하는데 부호 정도로 해야지)이 여러 차례 나오게 될텐데 이들을 어셈블리어라고 하며, 이런 심볼들을 기계어로 바꾸는 번역기가 어셈블리어가 된다.
아까도 말한거지만 어떤 하드웨어에 상관없이 사용가능한 고급언어와는 다르게 저급 언어는 ALU나 메모리, 레지스터 등에 따라서 다르다지만 비슷한 CPU 제품군 끼리는 동일한 기계어를 쓸수 있도록 되어있다고 한다.
심볼릭 명령어의 예시
1. 산술 논리 연산
load R1, 17 //17을 R1에 넣어라
add R1, R1, R2 //R1, R2를 더해서 R1에 넣어라
load R1, true //R1에다가 true를 넣어라
and R1, R1, R2 //R1에다가 R1, R2 and 연산 결과를 넣어라
2. 메모리 접근 방법
다른 컴퓨터는 어떤지는 모르지만 hack 컴퓨터의 경우 어드레스 레지스터 A를 이용해서 메모리 접근을 한다.
메모리의 15번지에다가 1을 넣고 싶다면,
(1) load A, 15 명령으로 어드레스 레지스터 A에다가 1을 넣고
(어드레스 레지스터 A는 값을 임시로 저장하거나, A에 저장된 값은 메모리 레지스터 M의 주소를 의미한다. A에다가 값을 저장한건지 M의 주소를 담는 건지는 기계어에 따라서 구분하니 뒤에 참고하면 된다.)
(2) load M, 1 명령으로 메모리 레지스터 M에다가 1을 대입하면 된다.
왜 M에 저장이 안되고 15번지에 저장이 되었는지는 어드레스 레지스터 A에 입력된 값이 곧 메모리 레지스터 M의 주소이기 때문이다. (꼭 A에 저장된 값이 M의 주소값으로만 사용되는 건 아니다.)
3. 흐름 제어와 심볼
우리가 C언어를 공부할 때 goto나 어떤 언어를 공부하던간에 반복문을 배웠을거고 정말 자주 사용한다.
goto나 반복문에서는 어떻게든 간에 goto를 만나거나 반복문의 끝에 도달하면 지정한 곳이나
반복문의 앞으로 돌아갔지만 그러면 어셈블리어에서는 어떻게 사용할까?
물리적인 주소를 사용하는 경우와 심볼릭 주소를 사용하는 두가지가 있다.
일단 물리적인 주소를 사용하는 경우는 돌아갈 장소의 줄을 직접 써서 가고
9: add R2, R2, 1
...
13: goto 9
심볼릭을 사용하는 경우는 알아볼 수 있는 심볼을 써서 해당 심볼로 돌아가게 된다.
add r3, r3, 1
...
(LOOP)
...
goto LOOP
그러면 물리적인 주소와 심볼릭한 주소를 사용한 경우의 차이점은 무엇일까? 우리가 프로그래밍 언어를 배우면서 상수보다는 변수 쓰는것과 동일하다고 생각할수 있을거같은데,
간단한 출력 예시를 든다면
print(3)
print(a)
위의 경우는 상수 3을 쓴 만큼 동작 중에는 바뀔수가 없고, 3대신 2를 출력하고 싶을때 기존의 3을 모두 2를 고쳐야 하면서 코드 작성할때 이해하거나 나중에 디버깅하는데 불편하다.
하지만 아래의 심볼릭으로 a를 썻을때는 a 에 3이 들어있더라도 2를 출력하길 원하면 a에 2를 넣으면 전체 a에 반영이 되기도 하고, 프로그램 실행 중에 a를 변경 할 수 이를 재할당 가능하다고 한다. 그래서 이런 재할당 가능한 심볼릭을 쓰면 물리적인 상수 주소를 썻을때보다 조금더 동적으로 변화하는 상황에 알맞게 동작하며 다루기도 좋다.
HACK 컴퓨터 구조
앞에 기계어가 뭐고, 고급언어가 뭐고, 심볼릭이니 어셈블리어니 하느라 말이 많았지만 이번에는 HACK 컴퓨터의 기계어에 대해서 정리하려고 하는데 HACK 컴퓨터에 대해서 잠깐 말하자면 앞서 구현한대로 HACK은 16비트 단위로 처리하는 폰 노이만 구조의 16비트 컴퓨터이다. 렘 파트에서 마지막에 16K 구현하길래 HACK의 메모리가 16K인줄 알았지만 32K였다.. 16K까지만 구현한 이유가 있는 곧 나오니도 하고 컴퓨터 구조를 간단하게 복습하면
* 이책 어딘가에 봤었는데 어딘질 모르겟다.
대표적인 컴퓨터 구조로는 폰 노이만 구조와 하버드 구조가 있다.
두 구조의 가장 큰 차이점이라면 폰 노이만 구조는 데이터메모리와 명령어 메모리가 붙어있어 동일한 통로(버스)로 되어있고, 하버드 구조는 데이터 메모리와 명령어 메모리가 분리되 서로 다른 버스로 읽고 쓴다고 한다.
폰 노이만 구조에서는 이전에 하드웨어로 직접 프로그래밍을 했던 것과는 달리 메모리에 저장하여 사용하게 되었지만(내장 프로그래밍) 통로가 하나 뿐이라 명령어와 데이터를 한번에 가져 올수없어 상대적으로 느리며(병목현상),
하버드 구조에서는 명령어 메모리와 데이터 메모리를 분리하여 한번에 두개를 가지고 올수 있어 상대적으로 빠른 처리가 가능하나 더 많은 메모리와 버스로 많은 공간을 차지한다고 한다.
HACK의 메모리와 레지스터 그리고 주소
아무튼 HACK 컴퓨터는 32K의 메모리를 가지고 있는데 폰 노이만 구조로 데이터 메모리와 명령어 메모리가 각각 16K씩 공간을 차지하고 있다. 그래서 지난번에 16K까지만 구현했나 보다. 데이터 값들을 담는 데이터 메모리는 값을 읽고 쓰니 RAM, 명령어 메모리는 여기에 저장된 명령어들을 읽기만 하니 ROM이라고 한다. 근데 이거 RAM 16K로 구현하였으니 휘발성 이니 이것도 RAM이라 하는게 맞지 않나? 아니면 명령어를 읽기만 해서 ROM이라 한건지는 좀더 봐야알거같다.
메모리와 레지스터 : 위 그림을 보면 데이터 메모리와 명령어 메모리, 아까 레지스터를 설명할 때 이야기한 어드레스 레지스터 A와 데이터 레지스터 D가 있다. 다시 반복하면 어드레스 레지스터 A는 데이터 레지스터와 동일하게 어느 값을 저장하고 있거나 데이터 메모리와 명령어 메모리의 주소를 저장하는 역활을 하는데, A가 주소를 담고 있을때, M = 0을 하면 RAM의 해당 주소에다가 0을 대입하게 된다. 어드레스 레지스터로 지정된 RAM 상의 레지스터를 데이타 메모리 레지스터 M이라 한다. ROM은 이름 그대로 읽기 전용 기억 장치로 차후에 자세히 설명하고, ROM의 레지스터 값은 현재 명령어를 나타낸다.
어드레스 레지스터 A에다가 18을 넣고자 한다면 어셈블리어로 @18(현재 A는 주소가 아닌 값을 저장하는 역할을한다)
이 값을 데이터 레지스터 D에 담고자 한다면 D = A를 하면 된다.
잠깐 뒷 내용을 당겨와서 하면 hack의 심볼릭과 기계어에는 주소와 값을 지정하기 위한 A명령어, 제어 명령을 나타내는 C명령어 두 종류가 있고, 이 hack 컴퓨터는 폰 노이만 구조라 데이터와 명령어 메모리가 하나의 버스를 공유하고 있다보니 hack 컴퓨터의 기계어는 값을 지정하기위해 A 명령어 먼저, 지정한 값을 사용하기 위해 C명령어가 따라와 같이 사용된다.
* hack의 심볼릭 예시 - 데이터 레지스터에다가 18 넣기(A는 값 저장 역할)
@18 // A 명령어
D = A // C 명령어
* 주소 처리 : 어드레스 레지스터를 이용하여 RAM 200번지에다가 값 18을 넣기 예시
@18 // A명령어 - 어드레스 레지스터에다가 데이터 레지스터에 임시로 담을 값을 지정
D=A // C명령어 - 어드레스 레지스터 값을 데이터 레지스터에 대입
@200 // A명령어 - 어드레스 레지스터에 200 대입
M=D // C명령어 - RAM 200번지에다가 데이터레지스터의 값(18) 대입
위의 예시를 보면 A 명령어 다음에 C 명령어에 데이터 메모리(RAM) 레지스터M이 사용되는 경우 A 명령어는 어드레스 역활을 하고, M이 없는 경우 A는 값을 보관하는 역활을 하고 있다.
분기 : hack 심볼릭 언어에서 조건 혹은 무조건적으로 특정 위치로 넘어가기 위해 goto를 하는 JMP 명령이 있으며, 무조건적으로 분기/넘어가고자 한다면 C명렁어로 0;JMP를 사용한다. 만약 무조건 56번지에 간다면 A명령어와 같이사용하여 다음 처럼 쓰면 된다.
@56
0;JMP
하지만 조건에 따라(0과 같거나 JEQ, 크거나 JGT, 작거나JLT) 분기하고자 하는 경우도 가능하며, 조건이 주어질때의 분기는 다음과 같이 할수있다.
@56
D;JEQ //D가 0과 같은 경우 56번지로 점프한다.
변수 이용하기 : 앞서 A 명령어를 사용할때마다 @{숫자}를 넣어서 사용해왔는데, @뒤에는 상수 뿐만이 아니라 심볼도 올수 있다. 예를들어 심볼/변수 x를 26로 지정하여 사용하고자 한다면
@26
D=A
@x
M=D
이렇게 하면 심볼 x에다가 값으로 26을 넣게 된다. 그런데 이 변수 x의 주소가 어디인지는 좀 더 봐야 알수있을거같고 일단 변수에다가 이런 식으로 값을 넣을수있다 정도로만 알고 넘어가자.
빌트인 심볼 : 그리고 hack 어셈블리에는 기본적으로 미리 지정된 빌트인 심볼 16개가 있는데 R0, R1, ..., R15로 R0은 데이터 메모리 0번지, R1는 1번지 ..., R15는 15번지라 할수 있고, 다음 명령어를 수행하면
@14
D=A
@R6
M=D
RAM[6]에다가 14를 넣은것과 같다고 생각하면 된다. 이 빌트인 레지스터들을 가상 레지스터라 한다.
A명렁어와 C명령어
조금 전에 hack 어셈블리어를 설명하기 위해 간단하게 A 명령어와 C 명령어 그리고 두 명령어의 심볼릭에 대해서 설명을 했었는데 어셈블리어는 기계어와 1:1 매칭되는 만큼 심볼릭을 아래와 같이 기계어 바이너리로 바꿀수 있다.
A명령어와 C명령어 구분 : hack은 16비트 컴퓨터라 명령어 길이가 16비트인데, 앞에 시작하는 바이너리 수를 보고 A 명령어인지 C명령어인지 구분할 수 있다. 아 잠깐 놓친건데 기계어 바이너리는 2부분으로 나눌수 있는데 opcode와 오퍼랜드이다. opcode는 이 명령어가 할 동작을 나타내고, 오퍼랜드는 이 명령어의 값 혹은 주소를 나타낸다.
hack 기계어의 MSB, 즉 가장 좌측 비트가 0인 경우 A 명령어로 보고 나머지 15비트는 오퍼랜드가 되겠다. 만약 MSB가 1인 경우에는 C 명령어가 되는데, 뒤의 따라오는 11은 칸을 채워주기 위함이며 나머지 13개 비트가 오퍼랜드가 된다.
A 명령어 : A 명령어는 1비트를 이미 사용하고 있으므로 표현 가능한 숫자는 15비트, 부호없이 0 ~ 32767까지 표현이 가능하며 2^15만큼의 주소에 접근할수 있게 되겠다. RAM32K를 구현했지만 RAM과 ROM은 각각 16K이고, 16K = 2^10 * 2^4인데다가 실제로는 ROM 전체를 다 사용하지 않아 A 명령어를 통해 모든 메모리 주소에 접근 가능하다.
최적화 문제로 이전 장에서 만든것보다는 빨리 동작가능한 빌트인 된걸 사용한다고 나왔던거같다.
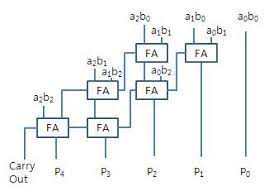
1. 반가산기
반가산기의 진리표, 입출력, 구조는 아래와 같다.
그대로 hdl을 작성해서 돌리면
CHIP HalfAdder {
IN a, b; // 1-bit inputs
OUT sum, // Right bit of a + b
carry; // Left bit of a + b
PARTS:
Xor(a=a, b=b, out=sum);
And(a=a, b=b, out=carry);
}
잘 된다.
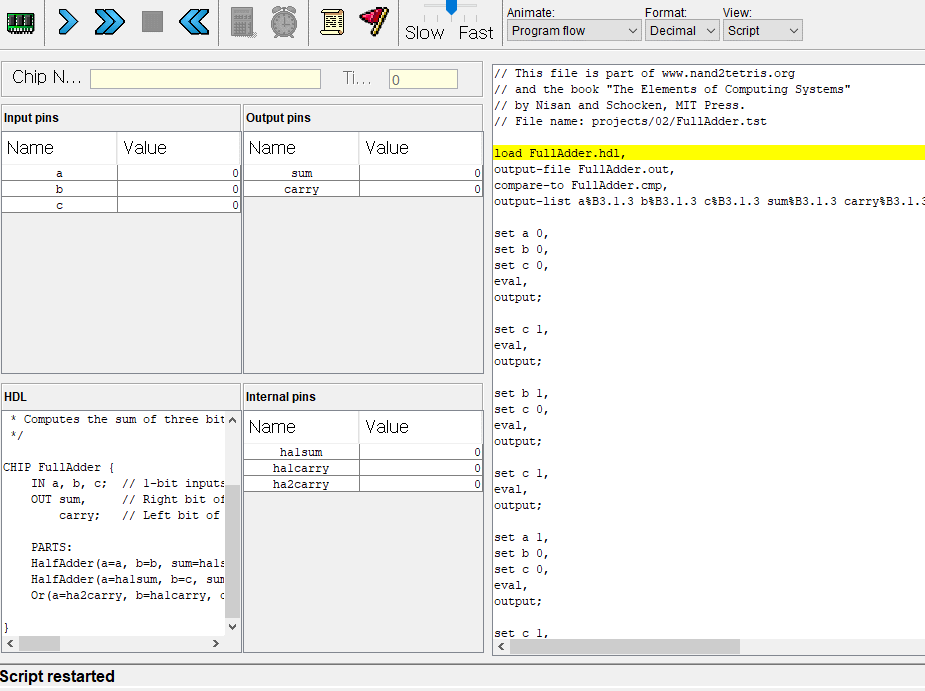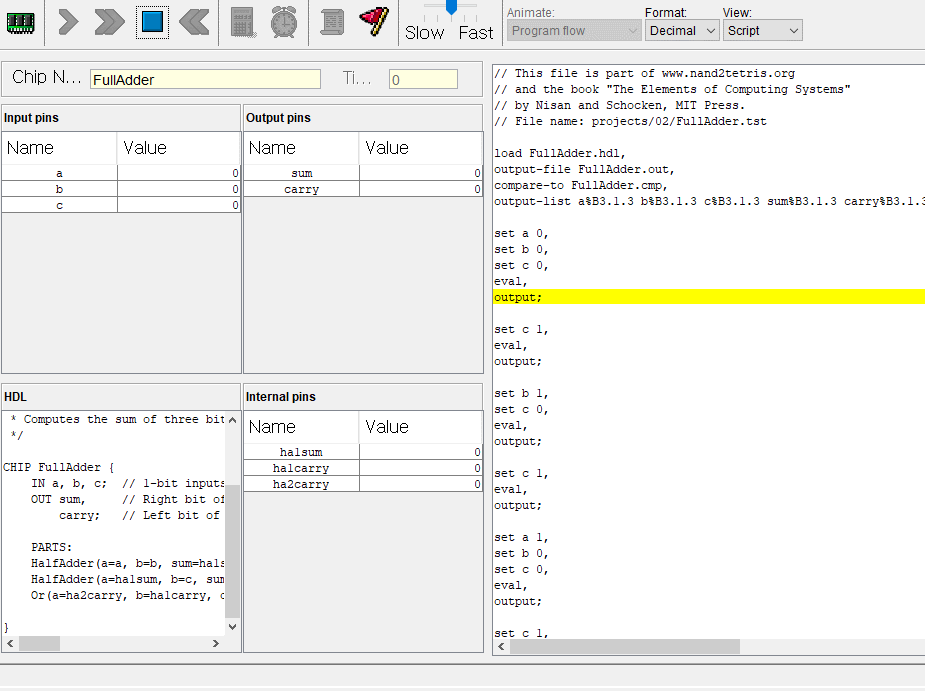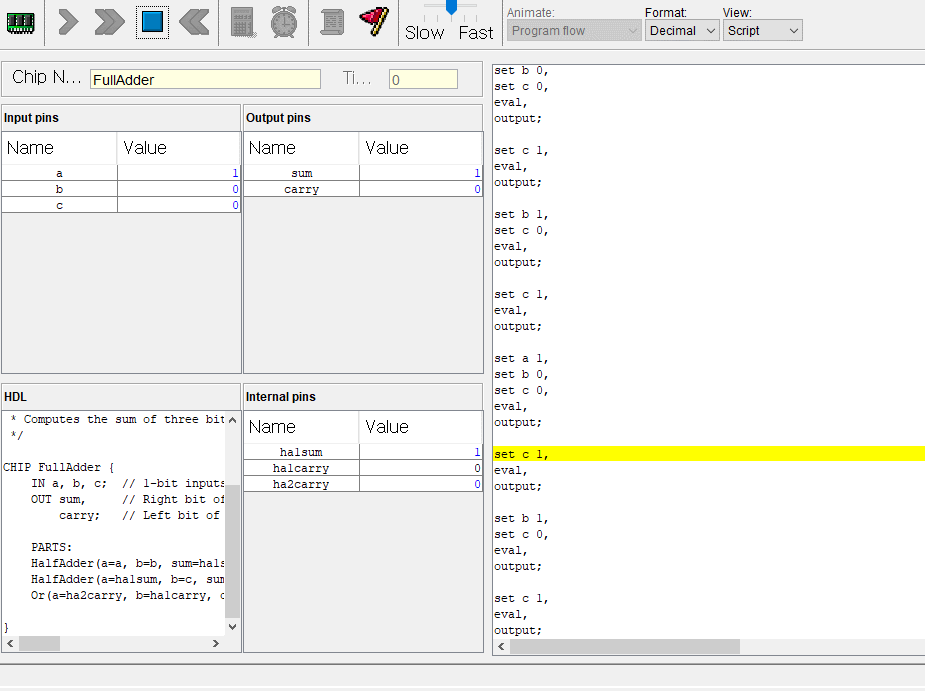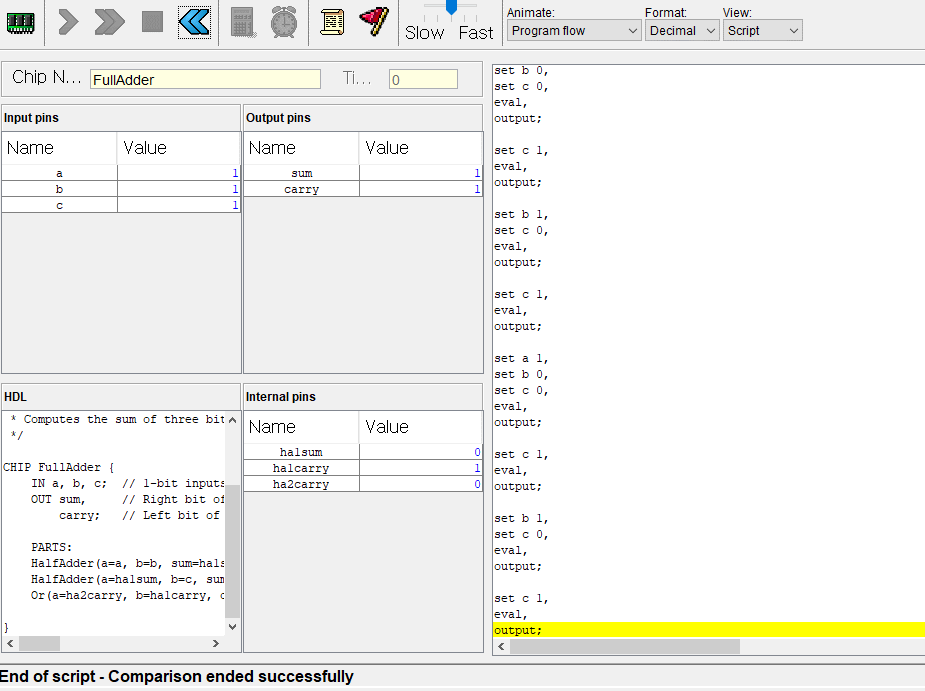
2. 전가산기
이번에는 전가산기
반가산기와 차이점이라면 캐리도 같이 입력받아서 가산연산을한다.
반가산기 2개와 or 게이트 1개로 만들 수있다.
진리표는 생략
CHIP FullAdder {
IN a, b, c; // 1-bit inputs
OUT sum, // Right bit of a + b + c
carry; // Left bit of a + b + c
PARTS:
HalfAdder(a=a, b=b, sum=ha1sum, carry=ha1carry);
HalfAdder(a=ha1sum, b=c, sum=sum, carry=ha2carry);
Or(a=ha2carry, b=ha1carry, out=carry);
}
캐리도 입력받지만 가산연산이 잘되고있다.
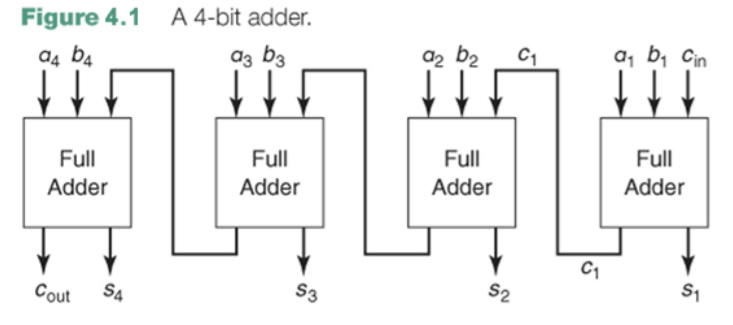
3. 16비트 전가산기
이번에는 16비트 전가산기. 처음에는 캐리가 없으니 반가산기 쓰고 뒤에서부터는 전가산기 15개 정도 쓰면될거같다.
zr의 경우 out이 0일때 1이 되고, ng의 경우 out이 음수인 경우 1이 되어 출력 결과의 상태를 나타낸다.
일단 zxy, nxy 논리연산부터 구현해보자.
z가 들어가면 0과 and16 연산을 하면되고
n이 들어가면 16비트 입력을 not16해주면 될거같다.
일단 zx값에 따라 0 or x가 나오도록 해봤다.
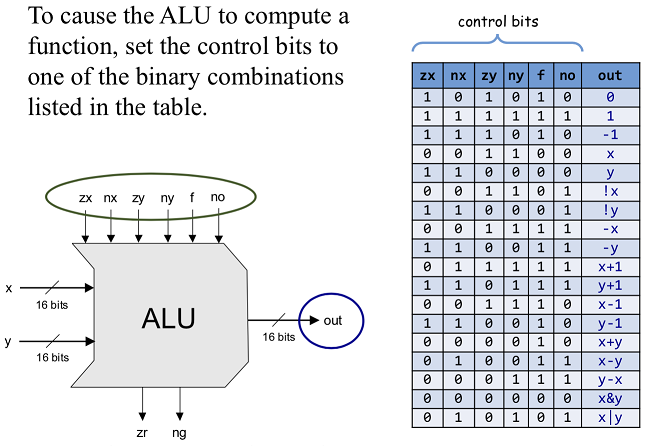
CHIP ALU {
IN
x[16], y[16], // 16-bit inputs
zx, // zero the x input?
nx, // negate the x input?
zy, // zero the y input?
ny, // negate the y input?
f, // compute out = x + y (if 1) or x & y (if 0)
no; // negate the out output?
OUT
out[16], // 16-bit output
zr, // 1 if (out == 0), 0 otherwise
ng; // 1 if (out < 0), 0 otherwise
PARTS:
Mux16(a=x, b=false, sel=zx, out=out); // zx == 0 ? x : 0000000..
}
제대로 구현한게 아니니까 진행 안되는게 맞기도하고 ,
생각한데로 x에 17이 들어갈때 zx=0이면 x가 나오고, 1이면 0이 뜬다.(mux16의 out을 바로 최종 출력으로보냇으니)
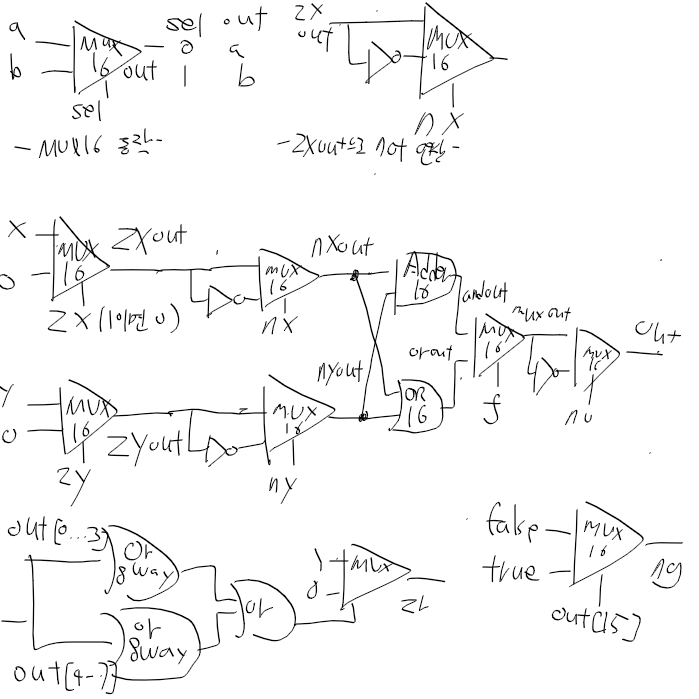
일단 이런 느낌으로 한번 그림으로 그리면
일단 nx, ny까지는 그렸다.
이제 f와 no만 고려하면 되는데,
no야 앞에서 zxout한거 처럼 not 돌리면되니까 문제없고 f랑 zr, ng 부분만 더 생각해보자
if f == 1 ? x + y : x & y이고, mux는 sel이 1일때 아래거(b)를 내보내니
mux a = and(x,y), b=or(x,y), sel=f 대강 이런식이면 될거같다.
zr, ng 빼고는 완성!
일단 out만 생각한데로 되는지 보자
CHIP ALU {
IN
x[16], y[16], // 16-bit inputs
zx, // zero the x input?
nx, // negate the x input?
zy, // zero the y input?
ny, // negate the y input?
f, // compute out = x + y (if 1) or x & y (if 0)
no; // negate the out output?
OUT
out[16], // 16-bit output
zr, // 1 if (out == 0), 0 otherwise
ng; // 1 if (out < 0), 0 otherwise
PARTS:
Mux16(a=x, b=false, sel=zx, out=zxout);
Mux16(a=y, b=false, sel=zy, out=zyout);
Not16(in=zxout, out=notzxout);
Not16(in=zyout, out=notzyout);
Mux16(a=zxout, b=notzxout, sel=nx, out=nxout);
Mux16(a=zyout, b=notzyout, sel=ny, out=nyout);
And16(a=nxout, b=nyout, out=andout);
Or16(a=nxout, b=nyout, out=orout);
Mux16(a=andout, b=orout, sel=f, out=fout);
Not16(in=fout, out=notfout);
Mux16(a=fout, b=notfout, sel=no, out=out);
}
계산이 되기는한데 생각한거랑은 좀 다르게 나온다..
자꾸 에러때문에 막혀서 일단 zr, ng부터 구현하고 다시 보자
zr은 연산 결과가 0인 경우 1이 되는거니
기존의 out을 mux sel단자에 넣어서 쓰려고 했는데
mux16 sel은 1비트, out은 16비트다.
out 모든 비트를 or연산한 결과가 0이면 zr = 1, 아니면 zr=0이 되도록
우선 out을 or16 돌린뒤에 sel에 넣으면 될거같다.
다시보니 or 16은 16비트 두입력 or연산이었네
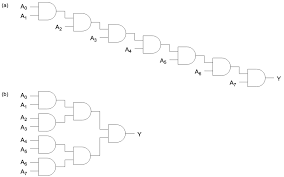
Or8way 두개, or 1개 쓰자.
CHIP ALU {
IN
x[16], y[16], // 16-bit inputs
zx, // zero the x input?
nx, // negate the x input?
zy, // zero the y input?
ny, // negate the y input?
f, // compute out = x + y (if 1) or x & y (if 0)
no; // negate the out output?
OUT
out[16], // 16-bit output
zr, // 1 if (out == 0), 0 otherwise
ng; // 1 if (out < 0), 0 otherwise
PARTS:
Mux16(a=x, b=false, sel=zx, out=zxout);
Mux16(a=y, b=false, sel=zy, out=zyout);
Not16(in=zxout, out=notzxout);
Not16(in=zyout, out=notzyout);
Mux16(a=zxout, b=notzxout, sel=nx, out=nxout);
Mux16(a=zyout, b=notzyout, sel=ny, out=nyout);
And16(a=nxout, b=nyout, out=andout);
Or16(a=nxout, b=nyout, out=orout);
Mux16(a=andout, b=orout, sel=f, out=fout);
Not16(in=fout, out=notfout);
Mux16(a=fout, b=notfout, sel=no, out[0..7]=out0to7, out[8..15]=out8to15, out=out);
Or8Way(in=out0to7, out=or8way1out);
Or8Way(in=out8to15, out=or8way2out);
Or(a=or8way1out, b=or8way2out, out=zrsel);
Mux(a=true, b=false, sel=zrsel, out=zr);
}
zr도 구현을 잘 했는데
컨트롤비트가 111111인경우 왜 1이 나오는지 잘 이해가 안된다.
계산도 해보니 ng는 그렇다쳐도 값이 좀 이상하게 나온다.
다시 진리 테이블을 보니
f=1 일때 or연산이 아니라 + 연산을 해야되더라. +라길래 or연산을 의미하는줄알았다.
Or16을 Add16으로 바꿔줫더니 out 결과는 잘나온다.
이제마지막으로 ng만 처리해주면된다.
ng야 MSB가 1이면 음수로 보면 되니까 mux에 바로연결하자.
sel = 1- > ng = 1
sel = 0 -> ng = 0
으아아아 드디여 진리표만 보고 그림그려서 alu를 구현했다
CHIP ALU {
IN
x[16], y[16], // 16-bit inputs
zx, // zero the x input?
nx, // negate the x input?
zy, // zero the y input?
ny, // negate the y input?
f, // compute out = x + y (if 1) or x & y (if 0)
no; // negate the out output?
OUT
out[16], // 16-bit output
zr, // 1 if (out == 0), 0 otherwise
ng; // 1 if (out < 0), 0 otherwise
PARTS:
Mux16(a=x, b=false, sel=zx, out=zxout);
Mux16(a=y, b=false, sel=zy, out=zyout);
Not16(in=zxout, out=notzxout);
Not16(in=zyout, out=notzyout);
Mux16(a=zxout, b=notzxout, sel=nx, out=nxout);
Mux16(a=zyout, b=notzyout, sel=ny, out=nyout);
And16(a=nxout, b=nyout, out=andout);
Add16(a=nxout, b=nyout, out=addout);
Mux16(a=andout, b=addout, sel=f, out=fout);
Not16(in=fout, out=notfout);
Mux16(a=fout, b=notfout, sel=no, out[0..7]=out0to7, out[8..15]=out8to15, out[15]=out15, out=out);
Or8Way(in=out0to7, out=or8way1out);
Or8Way(in=out8to15, out=or8way2out);
Or(a=or8way1out, b=or8way2out, out=zrsel);
Mux(a=true, b=false, sel=zrsel, out=zr);
Mux(a=false, b=true, sel=out15, out=ng);
}