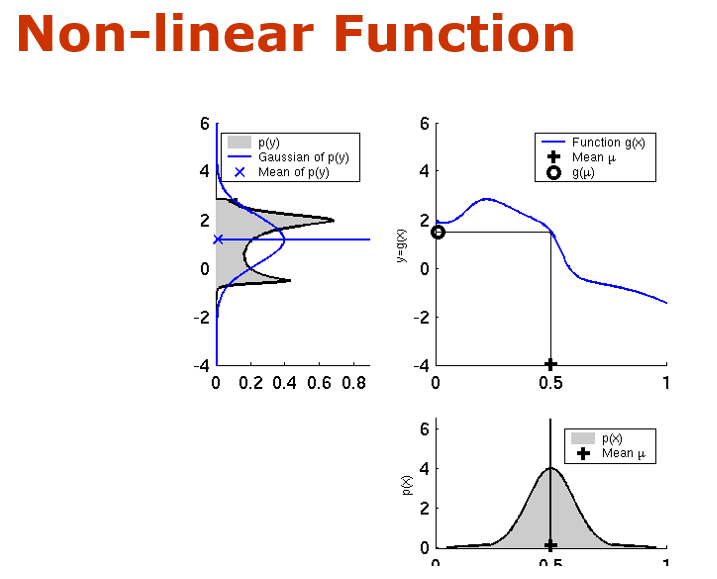
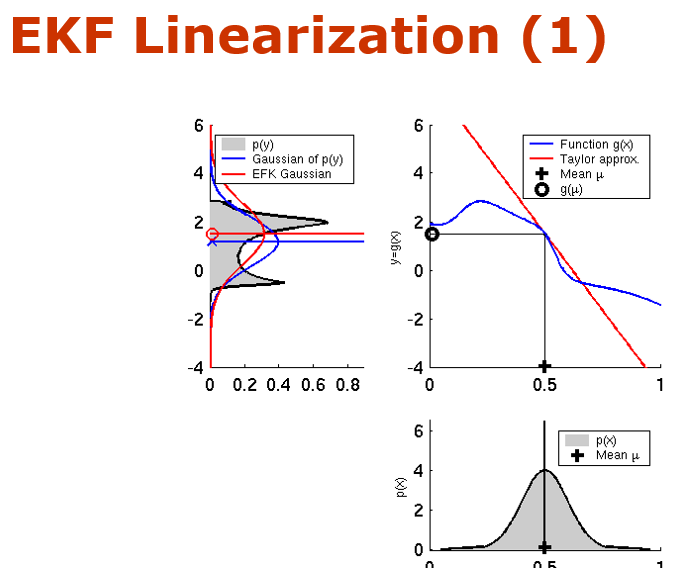
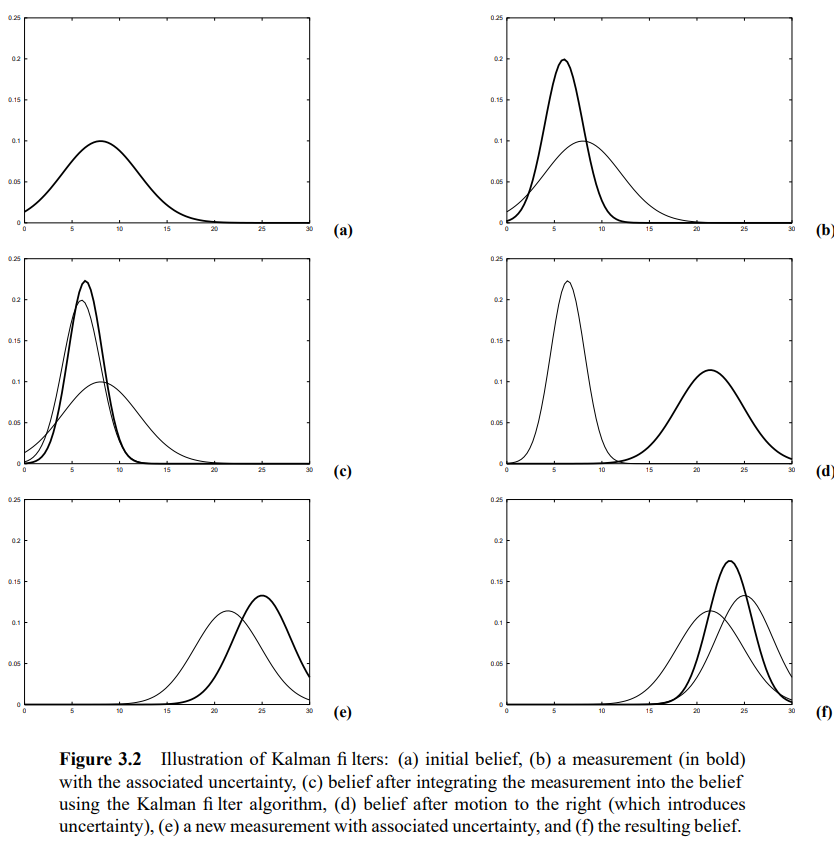
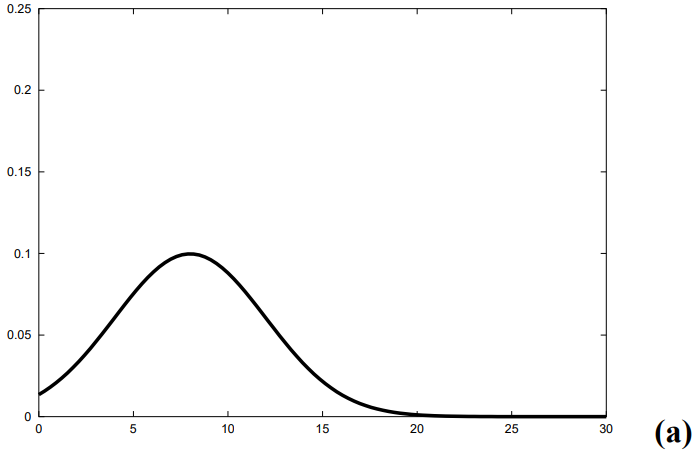
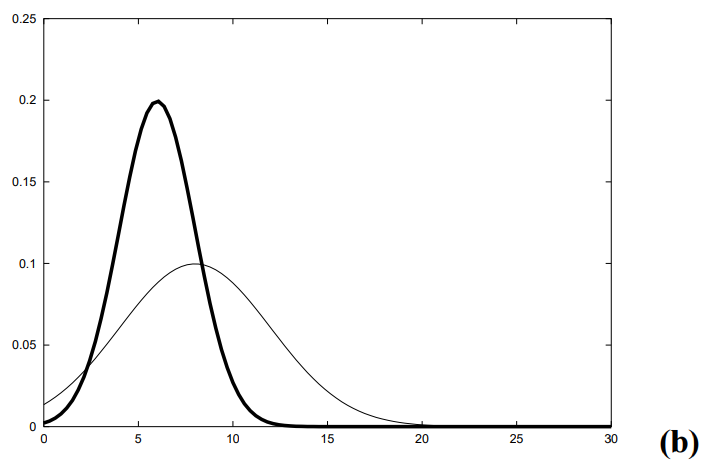
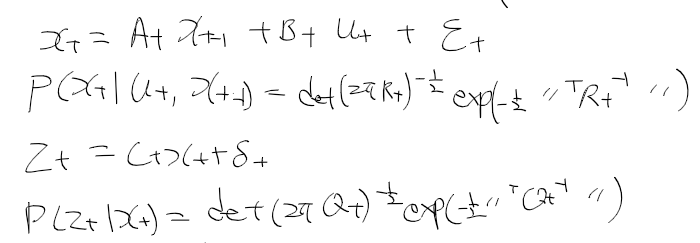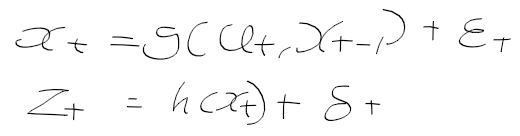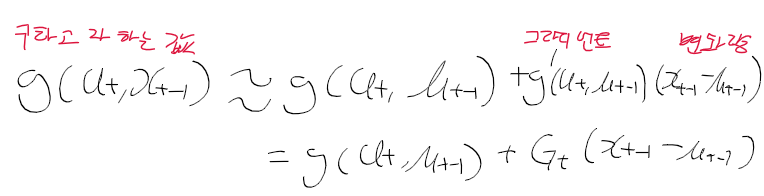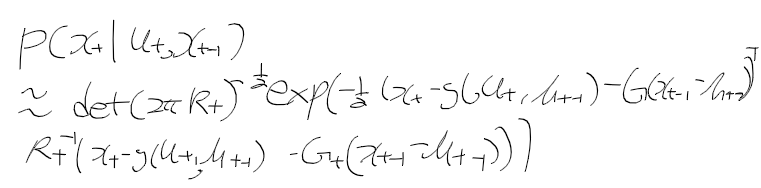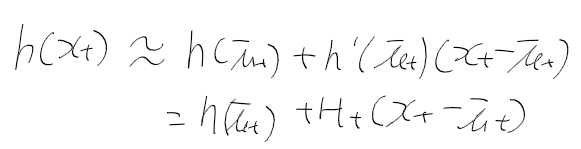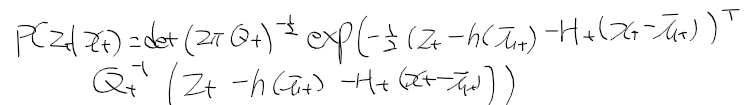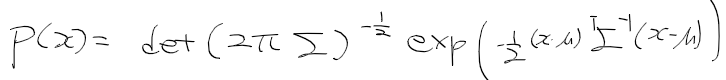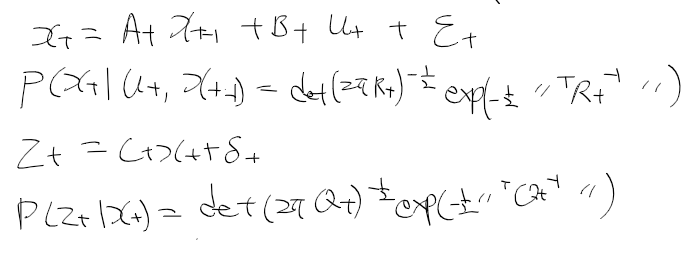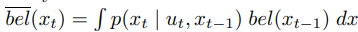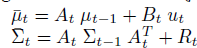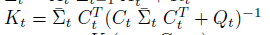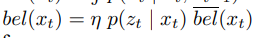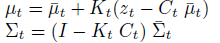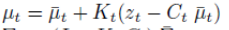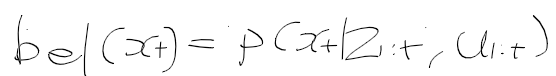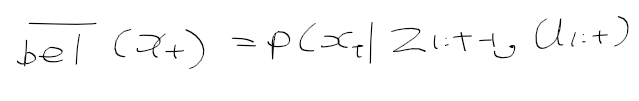음 파이썬 로보틱스에서 제공하는 예제들은 probabilisitc robotics 내용들을 파이썬으로 구현한 것들인데
이론 내용을 짚고 넘어갈까,
아니면 바로 구현들어가면서 내용정리할까 고민하다가
사용되는 기초 이론들을 먼저 정리해야할것 같아서
내가 이해한 것이 정확하지는 않더라도 대강 느낌이라도 정리를 먼저하고 시작하려고함
확률로 다루는 로보틱스
- 보통 센서 데이터들을 특정한 정확도의 값(정량 데이터)을 가짐
초음파 거리계 : 거리
가속도, 자이로계 : 각속도, 선가속도
gps : 경도, 위도 위치 좌표 등
- 하지만 이런 센서들 데이터들은 노이즈로 잘못되어있을 수 있으며, 로봇의 상태를 특정한 정확한 값으로 표현은 곤란
=> 센서 데이터를 그대로 쓰기보단 로봇의 상태를 확률 모델로 표현
상태를 확률 변수로 모델링 한다는 것은?
- 초음파 데이터가 대충 10cm 거리에 있는 물체를 감지해서 아래와 같은 값을 받앗다고 치자
- 이를 확률 변수 p(x)는 평균 10, 분산 1인 정규분포 X ~ N(10, 1) 를 따른다른다 라는 식으로 데이터 분포를 확률 밀도 함수로 표현한다.(대충 값이 맞든 틀리든)
| 10.7 |
10.4 |
9.2 |
8.4 |
11.6 |
11.0 |
8.9 |
- 로봇과 관련된 상태 값들이 노이즈가 포함되어도 확률 분포로 나타내어 베이즈 필터에 활용된다.
확률 개념 정리
- 확률 변수 X가 사건 x일 확률을 다음과 같이 표현
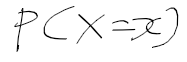
- 확률 변수 X에서 발생할 모든 사건에 대한 확률들의 합은 1
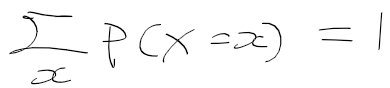
- 앞으로 사용할 확률 분포들은 가우시안 분포를 따른다고 가정함. x가 스칼라인 경우 1차 정규분포는 다음과 같음
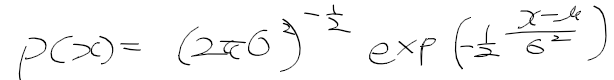
- x가 스칼라가 아닌 벡터인 경우 정규 분포는 다음과 같이 표현

- 두 확률 변수 X, Y가 주어지고, X=x, Y=y인 사건이 동시에 일어날 확률/결합확률분포는 다음과 같음
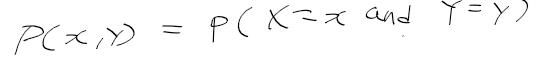
- 만약 두 확률 변수 X, Y가 독립인 경우 두 사건이 동시에 일어날때 결합확률분포는 각 두 확률의 곱
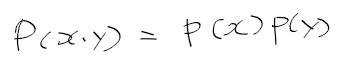
- Y=y 임을 알고있을때 X=x가 발생할 확률(조건부 확률), 맨 우측은 X,Y가 독립인 경우 성립
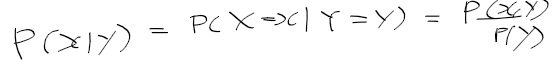
- 조건부 확률 정의에 따라 다음의 전체 확률 정리가 성립함
-> p(x|y)는 y가 발생했을때 p(x, y)가 발생할 확률
-> p(x|y)에서 전체 y 사건들이 발생한 경우(이산합, 적분)를 곱하여 합하면 p(x)에 대한 확률이 나온다
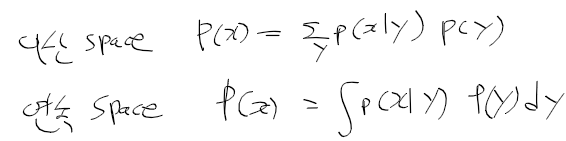
- 조건부 확률은 역확률과 관련 있음
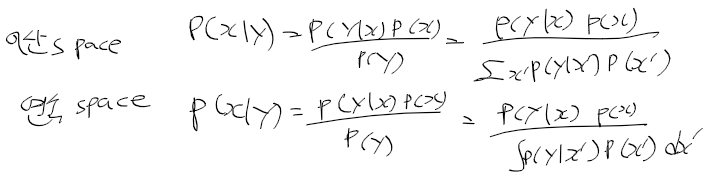
- 확률 변수 X의 기댓값은 다음과 같이 계산
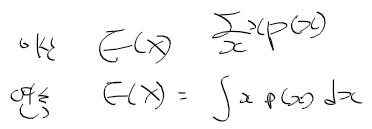
- 기댓값을 선형 함수로 표현시 다음과 같이 정리됨
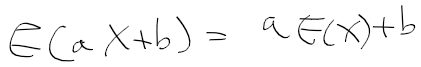
- 확률 변수 X의 공분산은 다음과 같음
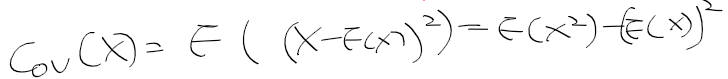
- 엔트로피는 x가 갖는 기대 정보량으로 -log2 p(x)는 x 인코딩에 가장 적당한 비트 수를 의미함
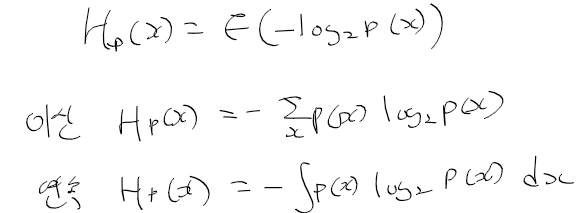
지금 왜 조건부 확률과 역확률을 다루는가
- 역확률 p(y | x)를 이용해 p(x | y)를 계산하기 위함
* y는 센서 데이터를 의미, p(y | x)는 특정 상태 x에서 y를 얻었을때의 확률 분포, p(x | y)는 센서데이터로 얻은 상태 분포
* 지금 로봇의 상태값들을 표현하기 위해 확률 분포를 사용하고 있는데, 실제 코드로 구현한걸 봐야 좀더 와닿음. 지금은 어쩔수가 없다.
- p(x | y)는 y라는 데이터가 주어졌을때 로봇의 상태 x에 대한 확률 분포를 나타낸다.
센서 관측 데이터 y를 얻은 후 상태 x를 구한것이므로 이를 사후 확률 분포라 한다.
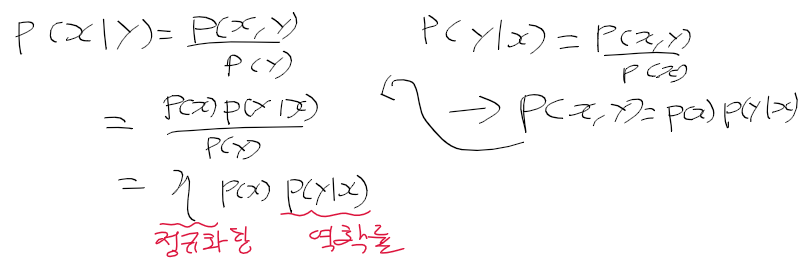
뒤에 구현할 예시랑 비슷하게 설명하자면 랜드마크로부터 거리 y가 주어졌을때 로봇의 위치 x가 어디인가를 의미한다
좀더 1차원 공간에서의 (대충) 예시를든다면 남산타워가 4인 지점에 있다는걸 알고 있다.
그리고 나는 거리 측정 센서로 남산타워(랜드마크)까지 거리를 재어보니 2.5, 2.3, 2.7, 2.6, 2.4 같은 식으로 값이 나온다.
나는 아직 내 위치가 어딘지 모른다.
하지만 지금 위치 기준으로 측정 데이터 p(y | x) = X ~ N(2.5, 0.1) 쯤 나온다고 칠수 있을것이고
4 - 2.5를 하면 1.5가 되니 나의 위치는 1.5쯤에 있다를 알수 있는데, 이게 p(x|y)가 된다.
=> p(x | y)를 바로 구할수는 없지만 확률 p(y | x)로부터 구할수 있으므로 p(y | x)를 생성모델이라 부른다.
| 원점 |
|
나의 위치 |
|
랜드마크
(남산타워) |
|
|
|
|
|
| 0 |
1 |
?? |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
- 내가 방금 작성한 설명이 p(x|y)에 대한 식을 계산하는것과 정확하게 일치한것 같지는 않은대 역확률 p(y | x)로 사후확률 p(x | y)를 구한다는것은 이런 느낌인데, 1차원 복도 예제를 봐야 왜 이런식으로 계산되는지 조금 더 와닿을것 같다.
상태, 제어, 관측
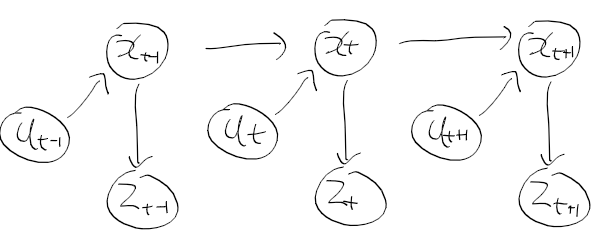
- x는 상태, u는 제어 데이터, z는 관측 데이터를 의미
- 시간 t1~t2까지 모든 제어, 관측 데이터를 다음과 같이 표현
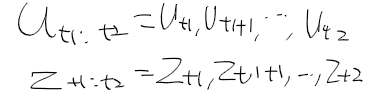
- 시간 t에서의 상태 x_t는 시간 t-1에서의 상태 x_t-1에 제어 데이터u_t로부터 얻을 수 있음
x_t-1는 0~t-1까지의 상태와 제어를 합한 결과로 얻을수 있으며, x_t는 우항과 같이 정리하여 구할수 있다.
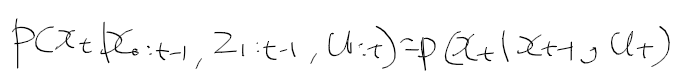
이게 무슨소리냐 대충이라도 계산해보자
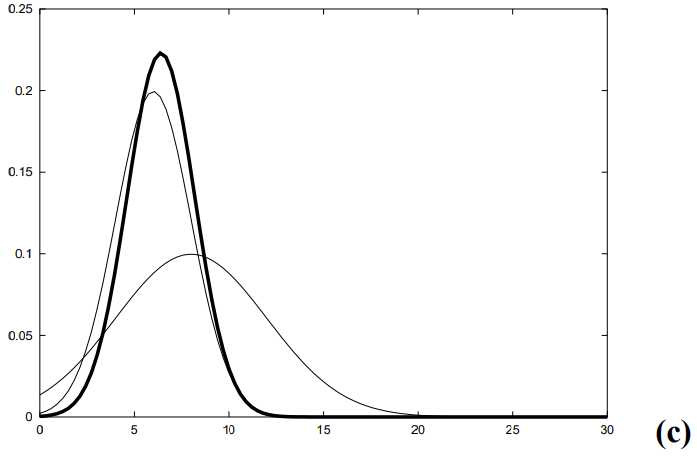
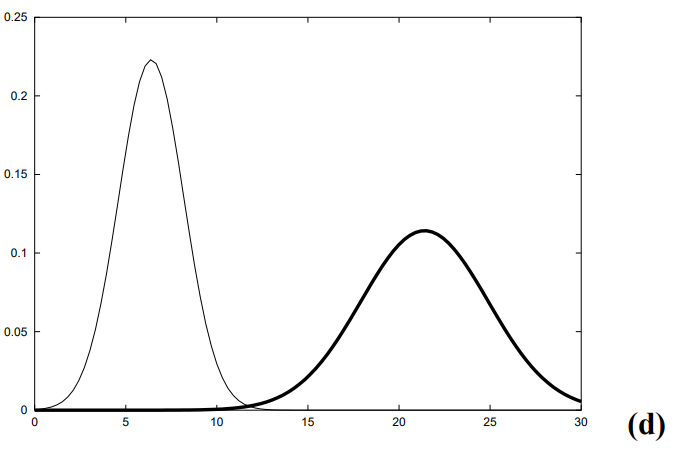
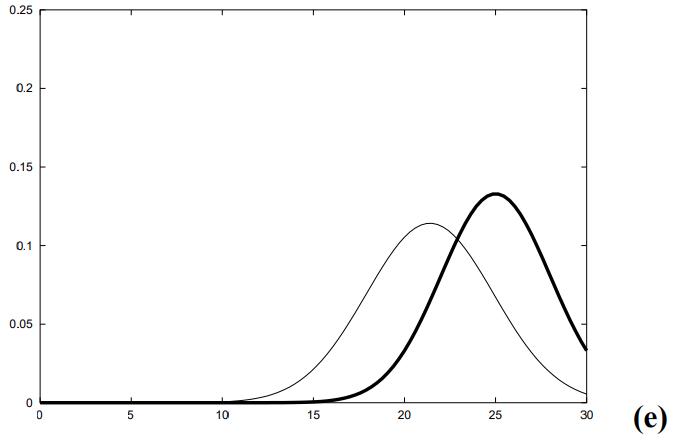
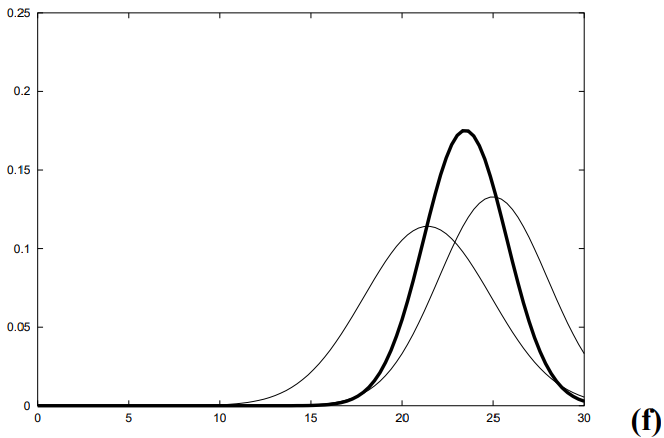
1차원 공간에서 t-1 시점에 로봇은 X ~ N(10, 1) 그러니까 10에 있다고 치자
+5 만큼 이동하는 제어 신호를 줬다고 하자 제어 신호에 대한 상태 전이 확률 분포를 N(5, 2)라 한다면
t 시점에 로봇은 15에 있을 것이다.
하지만 상태 전이 분포의 분산이 2이므로 이동 노이즈가 가미되어 t 시점의 로봇은 X ~ N(15, 3)으로 표현된다.
만약 제어 신호의 노이즈가 작아서 상태 전이 확률 분포가 N(5,0.001)이라 치면
이동 후 t 시점에서의 로봇은 X ~ N(15, 1.001)에 위치할 것이다.
로봇이 정확하게 이동했으므로 로봇의 상태에 대한 확률 분포의 분산이 크지 않다.
- 시간 t에서 상태 x_t가 주어질때 관측치, 역확률 모델 p(y|x)은 다음과 같이 표현한다.
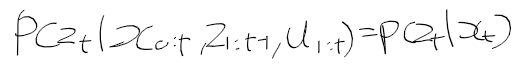
- 상태 전이 확률 p(x' | x, u) : 상태 x에서 제어 신호 u를 줬을때 얻은 새로운 상태 x'에 대한 확률 분포
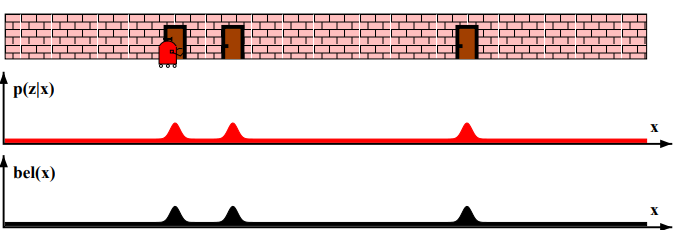
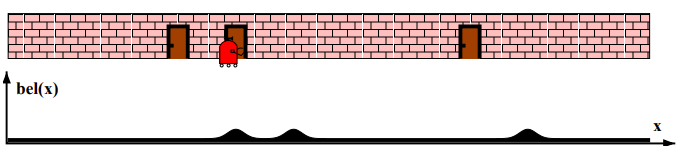
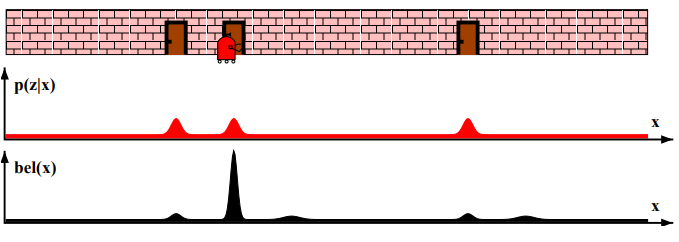
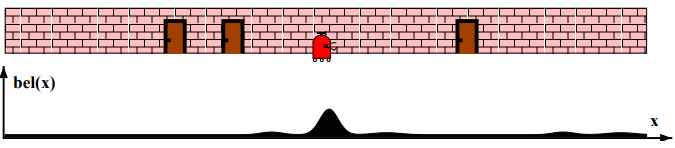
- 관측 확률 p(z | x) : 상태 x에서 관측치 z를 얻은 것이 대한 확률 분포
- 상태 x, 제어 u, 관측 z가 이산 시간 흐름에 따라 결정되어 동적 베이즈 네트워크라 부름