지금까지 칼만 필터 공부하면서
EKF까지만 갔지 따로 무향 칼만필터 이해하고 싶어도 이해를 못했는데 이제 무향 칼만필터 정리해보려고 함.
일단 EKF 문제가 비선형 함수를 아까 선형화 해서 자코비안만들어서 썻지만
선형화 하는 만큼 짧은 타임 스탭 동안 어느 정도 움직임을 잘 추종해내지
큰 동작이 일어나면 선형화 오차가 심해지는 문제가 있었다.
그래서 무향 칼만 필터는 선형 근사를 사용하지 않고
데이터 샘플링 하고, 무향 변환을 통해 추정 상태와 추정 오차 공분산 X_est, P_est를 구해낸다.
여기서 샘플링 되는 데이터, 대표 값을 시그마 포인트, 그리스어 표기로는 kai_i들을 선정해서 추정 상태와 오차 공분산 판단
그러면 시그마 포인트는 어캐 선정하냐는 좀 더보자

UKF 로직은 이런식
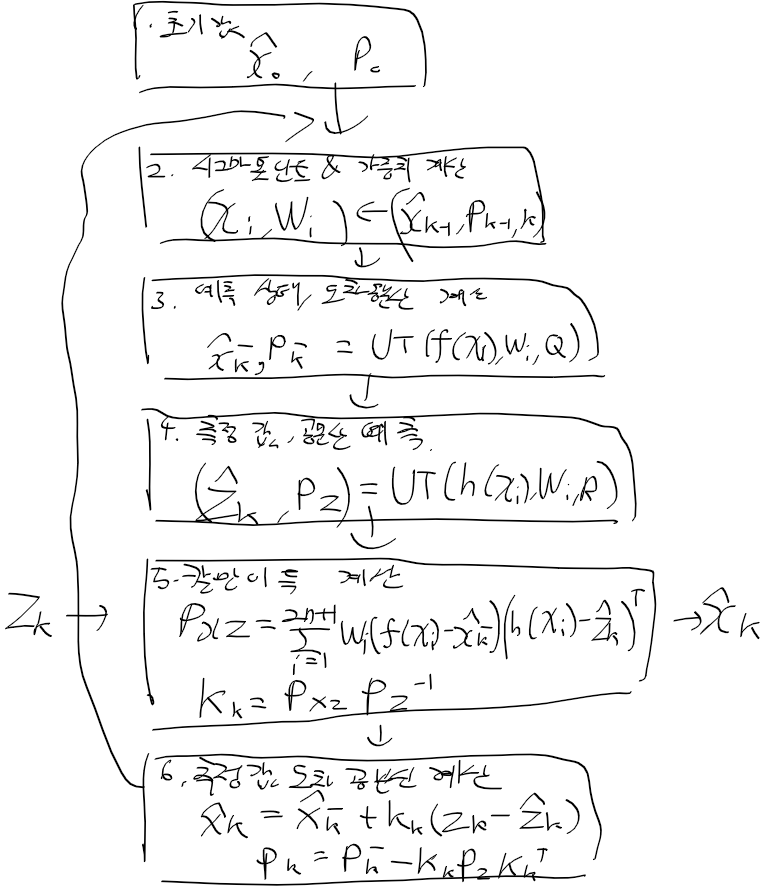
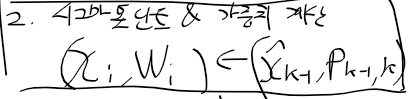
초기값 선정 다음에는 이전의 추정과 오차 공분산을 표현하는
시그마 포인트들과 각 포인트들의 가중치를 구하여야 함
\
예측 상태, 오차 공분산은 시스템 모델을 기존에 사용한 함수 f(x)가 아닌 시그마 포인트로 UT 무향 변환으로 구함
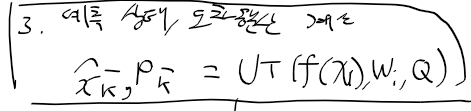
예측 측정값과, 측정 오차 공분산도 UT 변환으로 구함

칼만 이득 계산시 먼저
상태와 관측값의 공분산 P_xz 부터 계산
P_xz와 inv(P_z)의 행렬곱으로 칼만이득을 구함

이후 추정 상태와 오차 공분산은 지금까지 동일한 방식으로 계산

이거 하다보니까 파티클 필터할때 파티클 리샘플링하고 업데이트하고 했던 느낌인데
일단 무향 변환 UT는
변수 x가 x ~ N(x_m, P_x)인 정규 분포를 따름
그러면 각 시그마 포인트 kai_i와 가중치 W_i는

여기서 u_i는 다음을 만족하는 행렬 U의 행벡터라고 하는데 이건 구현중에 좀봐야할듯
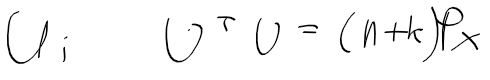
시그마 포인트의 가중 평균은 x_m
가중 공분산은 P_x 다음은 특성을 가짐
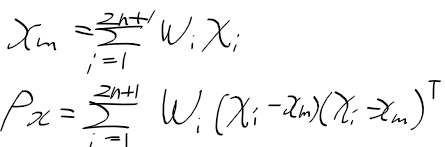
그러면 비선형 함수 y = f(x)에 시그마 포인트와 가중치를 적용해
다음의 결과를 얻을 수 있음
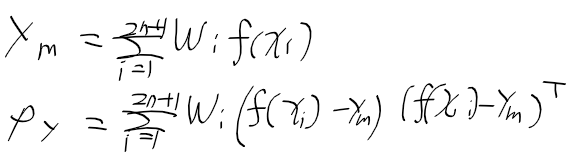
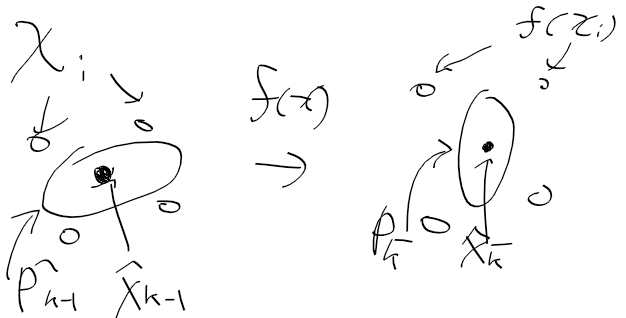
다시 맨 앞에 있던 그림들 가져오자
기존의 X_est, P_est가지고 시그마 포인트 만들고
비선형 시스템 모델 f(x)를 모든 시그마 포인트에 적용해서 이동한 시그마 포인트를 얻는다
그리고 이 시그마 포인트 가중합을 통해 다음 X_est, P_est를 구한다.
이거 그냥 파티클 필터랑 거의 비슷한데
시그마 포인트를 너무 어렵게 생각해서 이해를 못했던거같다
시그마포인트 구현하기
X_est, P_est, k_alpha 값을 주면 시그마 포인트와 가중피 반환 함수 구현
아까 시그마 포인트 계산에 u_i를 구해야했는데 다음 조건을 만족하는 U의 i번째 행을 나타냈다.
여기서 말하는 U는 촐래스키분해로 구할수 있음
촐래스키 분해를 하면 하삼각행렬과 삼상각행렬로 나누어짐
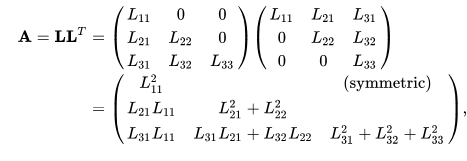
시그마 포인트 구현하다가 중간에 잠깐 찍은거
여기서 X_est 요소는 3개 므로
Xi 첫번째는 X_est 그대로
Xi 둘, 셋, 내 번째 까지는 X_est + U
Xi 다섯, 여섯, 일곱까지는 X_est - U하내
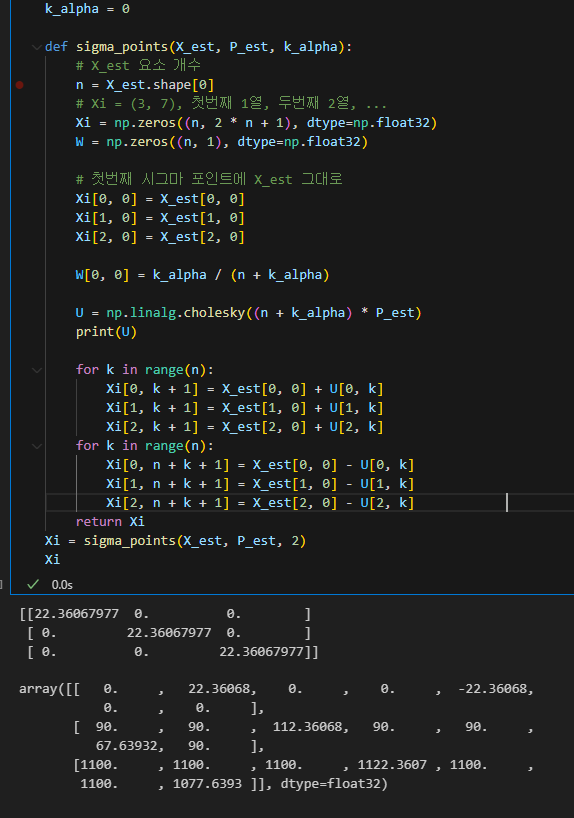
여기서 가중치 W도 추가해서 반환해주면 구현완료인데
가중치 구현하다보니 뭔가 이상한게
W = zeros(n, 1)을 줬었다.
X_est 요소는 3개라, 시그마포인트는 7개가 되는대
W은 3,1이 아닌 7, 1이여야 한다
일단 잘못된거면 나중에 고치고 이렇게 수정
k_alpha를 2로주고, 시그마 포인트가 7개여서 그런가
첫번째 시그마 포인트 X_est의 가중치는 0.4고 나머지 6개는 0.1로 되었다.
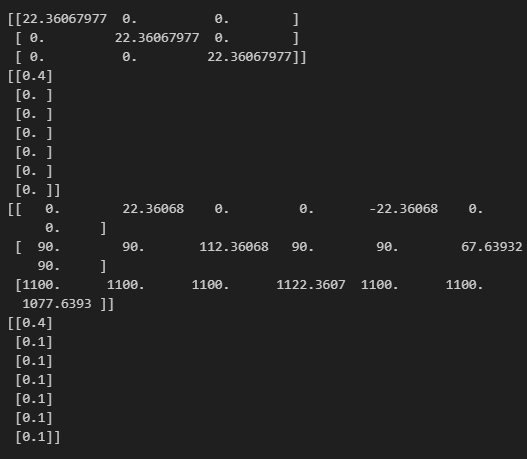
import numpy as np
X_est = np.array([[0, 90, 1100]]).T
P_est = 100 * np.eye(3)
k_alpha = 0
def sigma_points(X_est, P_est, k_alpha):
# X_est 요소 개수
n = X_est.shape[0]
# Xi = (3, 7), 첫번째 1열, 두번째 2열, ...
Xi = np.zeros((n, 2 * n + 1), dtype=np.float32)
W = np.zeros((2*n+1, 1), dtype=np.float32)
# 첫번째 시그마 포인트에 X_est 그대로
Xi[0, 0] = X_est[0, 0]
Xi[1, 0] = X_est[1, 0]
Xi[2, 0] = X_est[2, 0]
W[0, 0] = k_alpha / (n + k_alpha)
U = np.linalg.cholesky((n + k_alpha) * P_est)
print(U)
print(W)
for k in range(n):
Xi[0, k + 1] = X_est[0, 0] + U[0, k]
Xi[1, k + 1] = X_est[1, 0] + U[1, k]
Xi[2, k + 1] = X_est[2, 0] + U[2, k]
W[k + 1, 0] = 1 / (2 * (n + k_alpha))
for k in range(n):
Xi[0, n + k + 1] = X_est[0, 0] - U[0, k]
Xi[1, n + k + 1] = X_est[1, 0] - U[1, k]
Xi[2, n + k + 1] = X_est[2, 0] - U[2, k]
W[n + k + 1, 0] = 1 / (2 * (n + k_alpha))
return Xi, W
Xi, W = sigma_points(X_est, P_est, 2)
print(Xi)
print(W)
무향 변환 구현하기
이번에는 시그마 포인트들의 평균과 공분산을 계산해내면 된다
size는 아마 행렬 크기 반환함수일텐데
n, kmax 반환한다는건 무슨 말일까
kmax 가 열 자리니까 시그마 포인트 개수 받는다는 소린거같은데
지금 Xi가 3, 7이니 그냥 넘파이 쉐이프로 뽑아내면 될듯
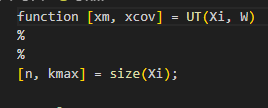

가중평균 구현은 이거 참고하면될듯
아 ... 참 곤란한게 매트랩은 행렬 알아서 맞추니 그냥 변수 그대로 준거같은데
파이썬에선 이런식으로 똑같이 구현할수가 없다
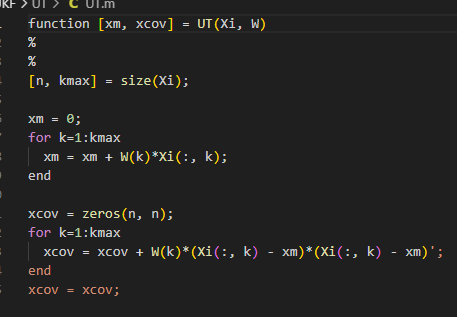
가중 평균 계산하는 로직 자체는 간단한데 잠깐 좀 해맴
원래 이렇게 루프 두번 할게 아니라 넘파이 선형 연산하면 되는데 머리가 안따라간다.
일단 이렇게 진행함
가중 공분산도 계산하긴 했는데 이게 맞는건진 잘 모르겠다
결과가 맞는지나 봐야지 ㅜ
일단 무향 변환도 구현 끝
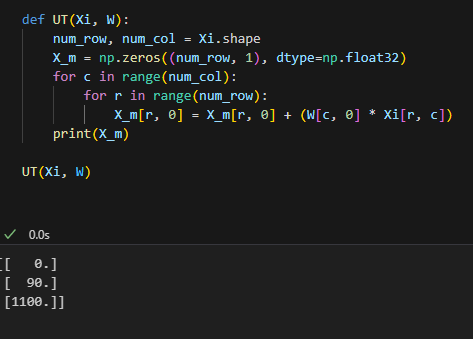
def UT(Xi, W):
num_row, num_col = Xi.shape
X_m = np.zeros((num_row, 1), dtype=np.float32)
for c in range(num_col):
for r in range(num_row):
X_m[r, 0] = X_m[r, 0] + (W[c, 0] * Xi[r, c])
X_cov = np.zeros((num_row, num_row), dtype=np.float32)
for c in range(num_col):
X_cov = X_cov + W[c, 0] * (Xi[:, c].reshape(-1, 1) - X_m) @ (Xi[:, c].reshape(-1, 1) - X_m).T
return X_m, X_cov
UT(Xi, W)
UKF로 라이다 물체 추적하기
지금까지 시그마포인트랑 무향 변환도 구현했다.
UKF 구현 과중에서 필요한게 시그마 포인트를 함수 f(x)에 대입, 가중화를 해서
동작후 예측상태,예측 오차 공분산 Y_m, P_y를 구해야한다.
일단 여기서 사용하는 f(x)는 이전에 라이더 추적 구현할때 쓴대로 다음을 이산 시스템으로 구현하면 된다.
대충 함수 fx는 이런식인데
우리가 쓸껀 그냥 상태 x를 넣고 끝내느게아니라
시그마 포인트들을 사용하므로 시그마 포인트 전체에 대한 가중 평균, 공분산 구현으로 만들어줘야한다ㅣ..
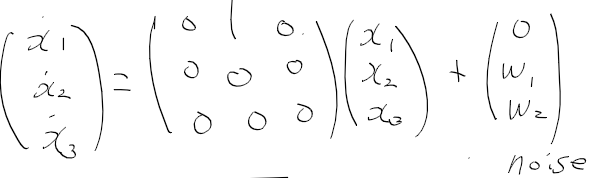
def fx(X_est, dt):
A = np.array([
[0, 1, 0],
[0, 0, 0],
[0, 0, 0]
])
A = np.eye(3) + dt * A
X_pred = A @ X_est
return X_pred
시그마 포인트들의 fx, 이들을 모은 3 x 7 형태의 fxi 변수를 만들려고하는데
이런식으로 넣으려고 해도 브로드캐스트 에러때매 안된다.
다른 방식이야 있겠지만, 지저분하게라도 구현해야할듯
1. 기존 X_est, P_set로부터 시그마 포인트 취득
2. 시그마 포인트들을 함수 f(x)에 대입해서 fxi를 구한다.
3. 시그마 포인트들의 무향변환으로 X_pred와 P_pred를 얻어낸다.
이제 무향 칼만필터의 중간까지는 왔다.
관측을 추가하고 테스트 돌리면 끝
def UKF(X_est, P_est, z, dt):
Xi, W = sigma_points(X_est, P_est)
fxi = np.zeros((n, 2 * n + 1), dtype=np.float32)
for k in range(0, 2 * n + 1):
fx_xi = fx(Xi[:, k].reshape(-1, 1), dt)
fxi[0, k] = fx_xi[0, 0]
fxi[1, k] = fx_xi[1, 0]
fxi[2, k] = fx_xi[2, 0]
X_pred, P_pred = UT(fxi, W, Q)여기서 관측도 무향변환을 하긴 할건데
라이더 예제에선 관측할게 직선 거리 1개 뿐이였다.
n 대신 m = 1로 놓고 hxi 도 구해보자 hxi shape는 m x 2n + 1 = 1 x 7이되겟다
(관측치 1) x (시그마 포인트 7개)
여기서 사용하는 함수 hx는 직선 거리 반환하는 함수
fxi[:, k]하면 (3,) 1차원이 들어가버려서 리쉐이프로 2차원으로 만들어 넣어줌
def hx(X_pred):
x1 = X_pred[0][0] # width
x3 = X_pred[2][0] # height
z_pred = sqrt(x1 ** 2 + x3 **2)
return z_pred
def UKF(X_est, P_est, z, dt):
Xi, W = sigma_points(X_est, P_est)
fxi = np.zeros((n, 2 * n + 1), dtype=np.float32)
for k in range(0, 2 * n + 1):
fx_xi = fx(Xi[:, k].reshape(-1, 1), dt)
fxi[0, k] = fx_xi[0, 0]
fxi[1, k] = fx_xi[1, 0]
fxi[2, k] = fx_xi[2, 0]
X_pred, P_pred = UT(fxi, W, Q)
hxi = np.zeros((m, 2 * n + 1))
for k in range(2 * n + 1):
hxi[0, k] = hx(fxi[:, k].reshape(-1, 1))
이제 UKF도 다끝나간다 상태 x, 관측 z에 대한 오차공분산
P_xz만 구현하면
칼만 이득이 나오고, 최종 추정치도 계산 가능
아ㅡ자읒빏즈앚부페뱌ㅜ대릅댜ㅐ으쟁ㅈㅂㄹㅈ브ㅔㄹㅈ브벶
ㅇ나므ㅐ푸냡훕재ㅐ이,ㅈㅂ[ㅐㅐㅇ재ㅔ주랴ㅐㅈ부랴ㅐ,ㅂ
행렬 형태 떄문에 이게 맞나 좀 해매고 다녔는데
잘못 만든것 같으면서도 동작은 잘 된다
칼만 게인 shape이 3 x 1이고, P_z가 z가 한개뿐이라 1 x 1이다
P_est 계산할때 K @ P_z @ K.T 행렬 계산이
(3 x 1) @ ( 1 x 1) @ (1 x 3) 이런식인데 내가 생각했던 행렬곱과는 좀 아니여서 맞는건지 아닌지 긴가민가 했느데
일단 동작은 잘되는것 같아보이니까 그냥 여기서 마무리
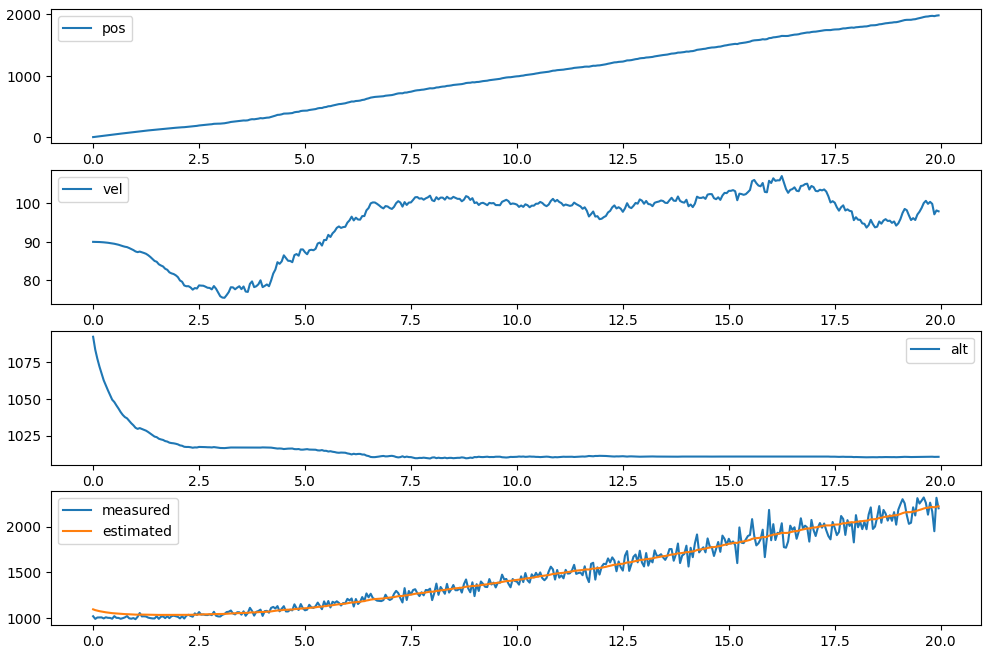
데이터 취득과 UKF, 차트 플로팅까지 아래 코드에 다 모아둠
import numpy as np
import matplotlib.pyplot as plt
from math import sqrt
def get_radar():
global pos
vel = 100 + 5 * np.random.normal()
alt = 1000 + 10 * np.random.normal()
pos = pos + vel * dt
v = 0 + pos * 0.05 * np.random.normal()
r = sqrt(pos ** 2 + alt ** 2) + v
return r
def hx(X_pred):
x1 = X_pred[0][0] # width
x3 = X_pred[2][0] # height
z_pred = sqrt(x1 ** 2 + x3 **2)
return z_pred
def fx(X_est, dt):
A = np.array([
[0, 1, 0],
[0, 0, 0],
[0, 0, 0]
])
A = np.eye(3) + dt * A
X_pred = A @ X_est
return X_pred
def UT(Xi, W, Q):
num_row, num_col = Xi.shape
X_m = np.zeros((num_row, 1), dtype=np.float32)
for c in range(num_col):
for r in range(num_row):
X_m[r, 0] = X_m[r, 0] + (W[c, 0] * Xi[r, c])
X_cov = np.zeros((num_row, num_row), dtype=np.float32)
for c in range(num_col):
X_cov = X_cov + W[c, 0] * (Xi[:, c].reshape(-1, 1) - X_m) @ (Xi[:, c].reshape(-1, 1) - X_m).T
X_cov = X_cov + Q
return X_m, X_cov
def sigma_points(X_est, P_est, k_alpha=0):
# X_est 요소 개수
n = X_est.shape[0]
# Xi = (3, 7), 첫번째 1열, 두번째 2열, ...
Xi = np.zeros((n, 2 * n + 1), dtype=np.float32)
W = np.zeros((2*n+1, 1), dtype=np.float32)
# 첫번째 시그마 포인트에 X_est 그대로
Xi[0, 0] = X_est[0, 0]
Xi[1, 0] = X_est[1, 0]
Xi[2, 0] = X_est[2, 0]
W[0, 0] = k_alpha / (n + k_alpha)
U = np.linalg.cholesky((n + k_alpha) * P_est)
for k in range(n):
Xi[0, k + 1] = X_est[0, 0] + U[0, k]
Xi[1, k + 1] = X_est[1, 0] + U[1, k]
Xi[2, k + 1] = X_est[2, 0] + U[2, k]
W[k + 1, 0] = 1 / (2 * (n + k_alpha))
for k in range(n):
Xi[0, n + k + 1] = X_est[0, 0] - U[0, k]
Xi[1, n + k + 1] = X_est[1, 0] - U[1, k]
Xi[2, n + k + 1] = X_est[2, 0] - U[2, k]
W[n + k + 1, 0] = 1 / (2 * (n + k_alpha))
return Xi, W
n = 3
m = 1
dt = 0.05
pos = 0
t_list = np.arange(0, 20, 0.05)
pos_list, vel_list, alt_list, z_list, dist_list = [], [], [], [], []
def UKF(X_est, P_est, z, dt):
Xi, W = sigma_points(X_est, P_est)
fxi = np.zeros((n, 2 * n + 1), dtype=np.float32)
for k in range(0, 2 * n + 1):
fx_xi = fx(Xi[:, k].reshape(-1, 1), dt)
fxi[0, k] = fx_xi[0, 0]
fxi[1, k] = fx_xi[1, 0]
fxi[2, k] = fx_xi[2, 0]
X_pred, P_pred = UT(fxi, W, Q)
hxi = np.zeros((m, 2 * n + 1))
for k in range(2 * n + 1):
hxi[0, k] = hx(fxi[:, k].reshape(-1, 1))
z_pred, P_z = UT(hxi, W, R)
P_xz = np.zeros((n, m), dtype=np.float32)
for k in range(2 * n + 1):
x_error = fxi[:, k].reshape(-1, 1) - X_pred
z_error = hxi[:, k].reshape(-1, 1) - z_pred
P_xz = P_xz + W[k, 0] * x_error @ z_error.T
K = P_xz @ np.linalg.inv(P_z)
X_est = X_pred + K @ (z - z_pred)
P_est = P_pred - K @ P_z @ K.T
return X_est, P_est
Q = np.array([
[0.01, 0, 0],
[0, 0.01, 0],
[0, 0, 0.01]
])
R = 100
X_est = np.array([
[0, 90, 1100]
]).T
P_est = 10 * np.eye(3)
for _ in range(len(t_list)):
z = get_radar()
X_est, P_est = UKF(X_est, P_est, z, dt)
pos_list.append(X_est[0][0])
vel_list.append(X_est[1][0])
alt_list.append(X_est[2][0])
z_list.append(z)
dist_list.append(sqrt(X_est[0][0] ** 2 + X_est[2][0] ** 2))
plt.subplot(411)
ax1 = plt.subplot(4,1,1)
ax2 = plt.subplot(4,1,2)
ax3 = plt.subplot(4,1,3)
ax4 = plt.subplot(4,1,4)
ax1.plot(t_list, pos_list, label="pos")
ax2.plot(t_list, vel_list, label="vel")
ax3.plot(t_list, alt_list, label="alt")
ax4.plot(t_list, z_list, label="measured")
ax4.plot(t_list, dist_list, label="estimated")
ax1.legend()
ax2.legend()
ax3.legend()
ax4.legend()
plt.gcf().set_size_inches(12, 8)
'컴퓨터과학 > 필터' 카테고리의 다른 글
| 칼만필터 파이썬 - 10. 파티클 필터 구현하기(실패) (0) | 2023.10.05 |
|---|---|
| 칼만필터 파이썬 - 8. 확장 칼만 필터 (0) | 2023.10.04 |
| 칼만필터 파이썬 - 7. 칼만필터를 이용한 가속도계와 자이로 센서 퓨전 (0) | 2023.10.04 |
| 칼만필터 파이썬 - 6. 칼만 필터를 이용한 추적기 구현 (0) | 2023.10.03 |
| 칼만필터 파이썬 - 5. 칼만 필터를 이용한 위치로 속도 계산 (0) | 2023.10.02 |