칼만필터 파이썬 하는것도 이제 거의 다 되간다.
파티클 필터도 전에 공부했던거라 대충 이해하고 있다.
무향 칼만필터와 차이라면
무향 칼만필터에서는 시그마포인트라고 하는 점 몇개를 기준으로 관측치랑 다뤘다면
파티클필터는 많은 양의 파티클들을 생성해서 관측치를 보고
가중치를 조절해서 리샘플링을 반복하는 방식이었던걸로 기억하는데
컨셉 이해뒤 매트랩 코드 돌려본것 말곤 안했던거같은데
이번엔 파이썬으로 구현
파티클 필터 로직부터 보자
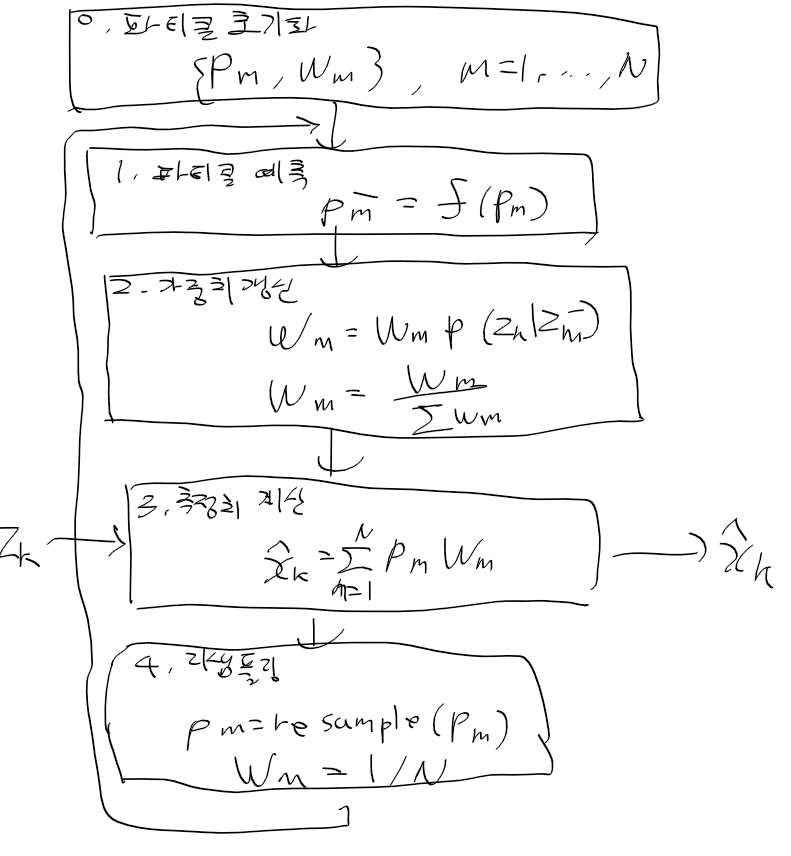
맨 처음에는 파티클들을 보통 균일 분포로 전체 영역에 뿌리고,
가중치는 1 / N(파티클 전체 수) 만큼 할당한다
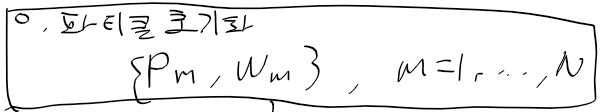
그리고 fx로 전체 파티클들에 대해 적용해서 파티클의 다음 상태를 예측한다

현재 관측치와 각 파티클의 예상 관측치를 비교해서
각 파티클들의 가중치를 조정한다.
실제 관측치와 파티클에서 예상 관측치 오차가 작을수록 더 큰 가중을 받는다.
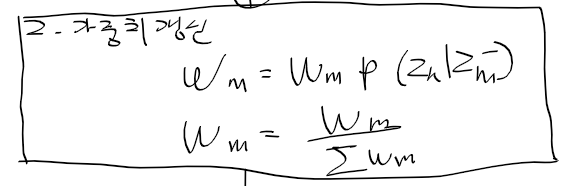
전체 파티클들의 가중 평균을 구하여
현재 상태 추정치를 구해낸다.
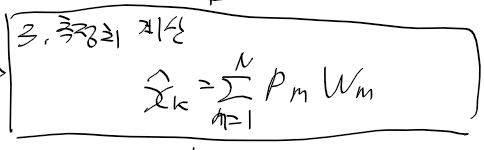
파티클들을 리샘플링을 수행한뒤 다음 타임 스탭으로 넘어간다
보통 리샘플링 알고리즘에선 가중치가 높은 쪽에 가까운 파티클들을 재생성해내는 식으로 감.
여기선 SIR 순차적 중요도 리샘플링을 쓴다고하는데
파이썬 코드로 어캐 할수있을랑가 싶네

파티클 필터를 이용한 라이더 물체 추적
상태 변수, 시스템 모델, 측정 모델을 정리하면 다음과 같다
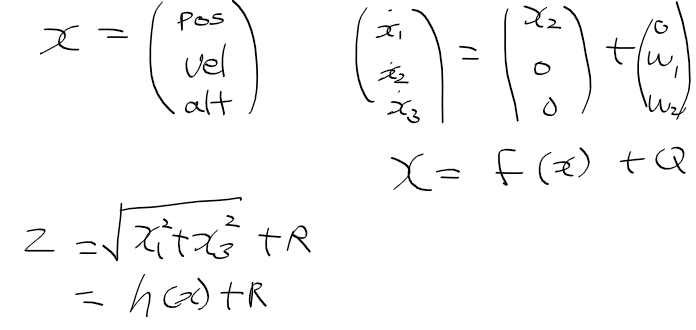
일단 파티클 필터를 구현하기 앞서 초기 파티클과 가중치 부터 초기화하자
전에 로보틱스에서 파티클필터를 다룰땐 균일분포로 했던거같은데
지금은 다른 문제라 그런가 정규 분포로 사용함
대충 초기 값들이 잘 구해짐

import numpy as np
X_est = np.array([[0, 90, 1100]]).T
N_particle = 1000
particles = np.random.normal(0, 1, (3, N_particle))
particles[0, :] = X_est[0][0] + 0.1 * X_est[0][0] * particles[0, :]
particles[1, :] = X_est[1][0] + 0.1 * X_est[1][0] * particles[1, :]
particles[2, :] = X_est[2][0] + 0.1 * X_est[2][0] * particles[2, :]
W = np.ones((1, N_particle)) * 1 / N_particle
시스템 함수를 이산 시스템으로 만들고, 관측 함수도 구현
def fx(X_est, dt):
A = np.array([
[0, 1, 0],
[0, 0, 0],
[0, 0, 0]
])
A = np.eye(3) + dt * A
X_pred = A @ X_est
return X_pred
def hx(X_pred):
x1 = X_pred[0][0]
x3 = X_pred[2][0]
Z_pred = np.sqrt(x1**2 + x3**2)
return Z_pred
이번엔 가중치 갱신 구현할 차례인데
여기 적혀있는 normpdf가 정규밀도 함수라
여기다 x 값을 넣으면 정규밀도 함수값이나오는거같다
아래 매트랩 예시보면 mu = 2, sigma = 1일때 x = 2인 위치의 확률이 가장 높은 0.4정도가 나온다.
즉 실제 z와 다양한 k 중 pt로부터 얻은 hx = z가 가장 가까울 수록 높은 값을 갖는다.
적다보니 말이 이상한데 가장 실제에 가까운 파티클의 가중치를 높이는 혁활
일단 z 자리가 x 값
mu 자리는 파티클 기준 관측 예측치
분산은 10
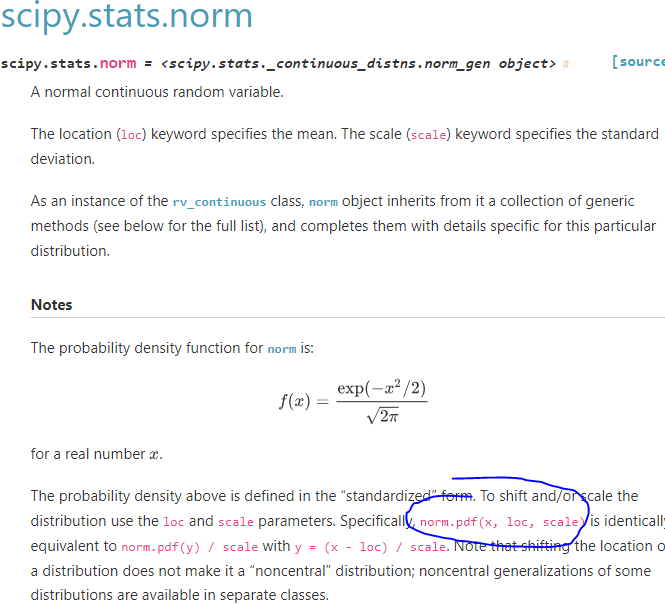
그러면 파이썬에선 이를 대체할 함수가 뭐가 있나..
for k = 1:Npt
wt(k) = wt(k)*normpdf(z, hx(pt(:,k)), 10);
end
wt = wt / sum(wt);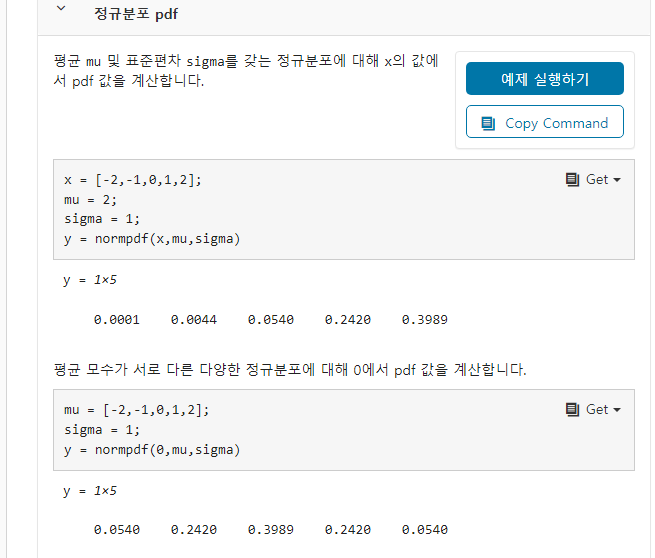
대충 찾아보니 사이파이에 있는 걸 쓰면 될듯하다.
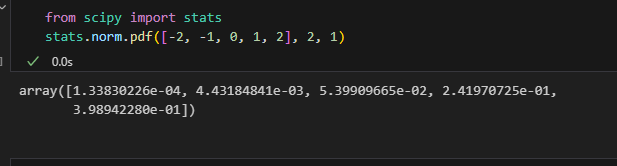
위에서 본 매트랩 예제랑 동일하게 만들어봤는데
값이 비슷한거 봐서 맞는것같네
이제 추정 상태 구현 차례
파티클은 3x 1000
가중치는 1 x 1000
가중합을 구하려면 P 행렬곱 W.T 하면
X에 알맞게 3 x 1 행렬이 나온다.
이제 거의다 구현하긴 했는데
가장 어려운 리샘플링 로직이 남았다.
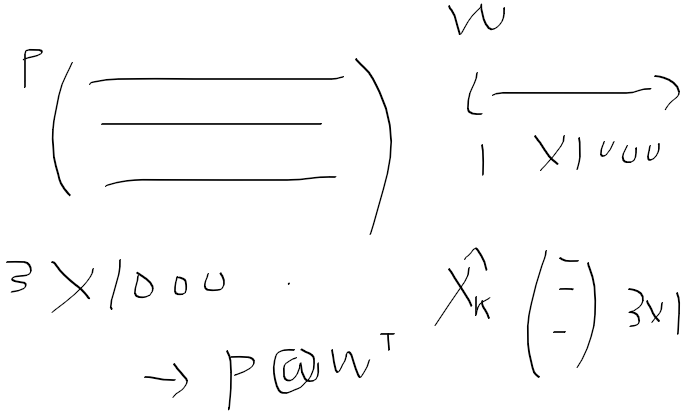
def pf(z, dt):
global particles, W
for k in range(N_particle):
particles[:, k] = fx(particles[:, k], dt) + np.random.normal(0, 1, (3))
for k in range(N_particle):
W[0, k] = W[0, k] * stats.norm.pdf(z, hx(particles[:, k].reshape(-1, 1)), 10)
W = W / sum(W[0,:])
X_est = particles @ W.T
SIR 로직 이거 처음봤을때 뭔소린가 이해하기 정말 어려웠는데
지금은 대충은 이해된다.
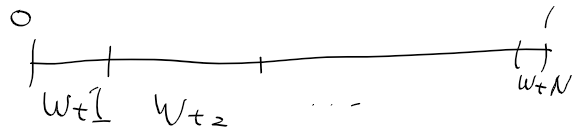
가중치는 지금 1 x 1000 형태 행렬인데
정규화를 해서 전체를 합하면 1이된다.
이를 누적확률 분포 구간별로 구분하면 이런식이 된다.
이 구간 전체에다가 균일 분포를 따르는 점들을 놓자
그러면 좁은 구간에는 점들이 적을 것이고
넓은 구간에는 점들이 많다.
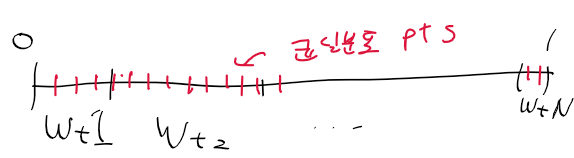
점이 많은 구간은 중요한 파티클
점이 작은 구간은 안중요한 파티클로 보고
중요도가 높은 파티클들 중심으로 리샘플링을 수행한다.

로직은 대충 알지만 이걸 어케 파이썬으로 구현하냐
일단 매트랩 함수를 찾아가면서 비슷한거 찾아쓰거나 만들어야지.
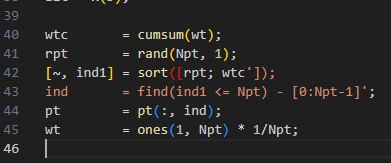
일단 cumsum은 누적 확률 분포 같은걸 만드는데
shape는 그대로 유지된다.

근대 보통 이런거 넘파이에 대부분 구현되어있다.
W 누적 분포 구하기위해 일단 임시로 관측치, 직선거리 z = 1101로 놓고 한번 가중치 누적 분포 출력하면 이런식
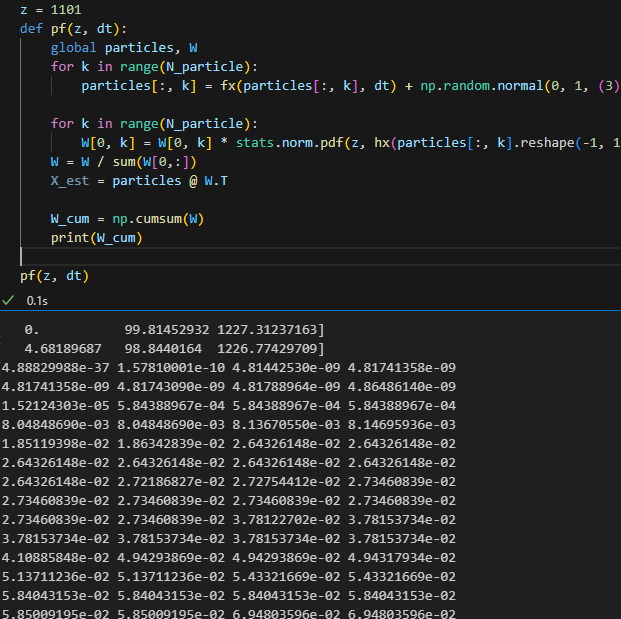
균일 분포랑 누적분포를 만들긴 했는데 매트랩 코드 그대로 구현하기가 좀 어려운데
아 파이썬 데이터 타입떄문에 되게 골치아프다.
파티클이 1000개다 보니까 소숫점 매우 낮은데까지 가는데
저 로직은 이해 안되고
그냥 위에서 중요 가중치 인덱스 찾는 로직을 억지로 루프 돌려서 만들긴 했다.
인덱스별로 균일 분포 포인트가 몇개 있는지를 구했는데
다음 문제는 파티클을 어떻게 새로 생성하는가다
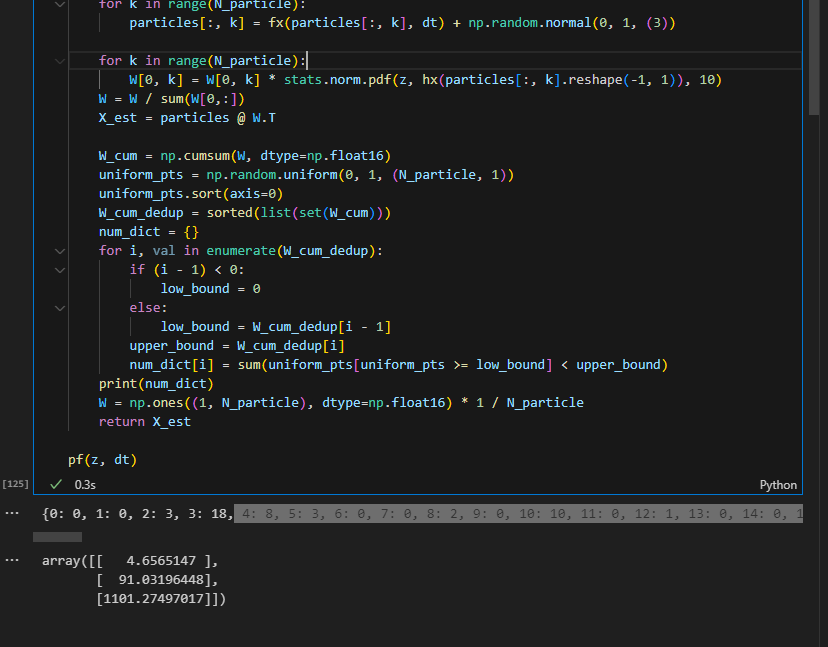
0이 아닌 인덱스들을 모아서
그 인덱스에 해당하는 파티클을 + 정규분포해서 균일분포 속한 갯수만큼 생성시키자
10번 파티클이 가장 가중치 많이 받았는데
이 가중치 구간에 균일분포 점이 100개가 들었다.
그러면 10번 파티클을 베이스로 정규분포 노이즈 추가해서 100개 만드는것으로
하는식으로 구현해야겟다.
ㅈ버ㅑㅐㅍㅂ주ㅑ잽풉재ㅑㅍㅂ주ㅑㅐㄼ우ㅐㅑ재ㅏㅂㅈ타ㅐㅔㅈ바ㅐㅔㅂ
어거지로 만들긴했는데
제대로 동작할지 모르겠다.
def pf(z, dt):
global particles, W
for k in range(N_particle):
particles[:, k] = fx(particles[:, k], dt) + np.random.normal(0, 1, (3))
for k in range(N_particle):
W[0, k] = W[0, k] * stats.norm.pdf(z, hx(particles[:, k].reshape(-1, 1)), 10)
W = W / sum(W[0,:])
X_est = particles @ W.T
W_cum = np.cumsum(W, dtype=np.float16)
uniform_pts = np.random.uniform(0, 1, (N_particle, 1))
uniform_pts.sort(axis=0)
W_cum_dedup = sorted(list(set(W_cum)))
num_dict = {}
for i, val in enumerate(W_cum_dedup):
if (i - 1) < 0:
low_bound = 0
else:
low_bound = W_cum_dedup[i - 1]
upper_bound = W_cum_dedup[i]
num_dict[i] = sum(uniform_pts[uniform_pts >= low_bound] < upper_bound)
particles_tmp = np.zeros((3, N_particle), dtype=np.float16)
cum_idx = 0
for key, val in num_dict.items():
if val == 0:
continue
for idx in range(val):
particles_tmp[:, cum_idx + idx] = particles[:, key] + 0.1 * particles[:, key] * np.random.normal(0, 1, (3))
cum_idx += val
#print(key, cum_idx, val)
# cum idx가 1000이 안된다면(파티클 1000개 다 안채우면) 기존 파티클 재사용
if cum_idx < 1000:
particles_tmp[:, cum_idx:] = particles[:, cum_idx:]
particles = particles_tmp
W = np.ones((1, N_particle), dtype=np.float16) * 1 / N_particle
return X_est
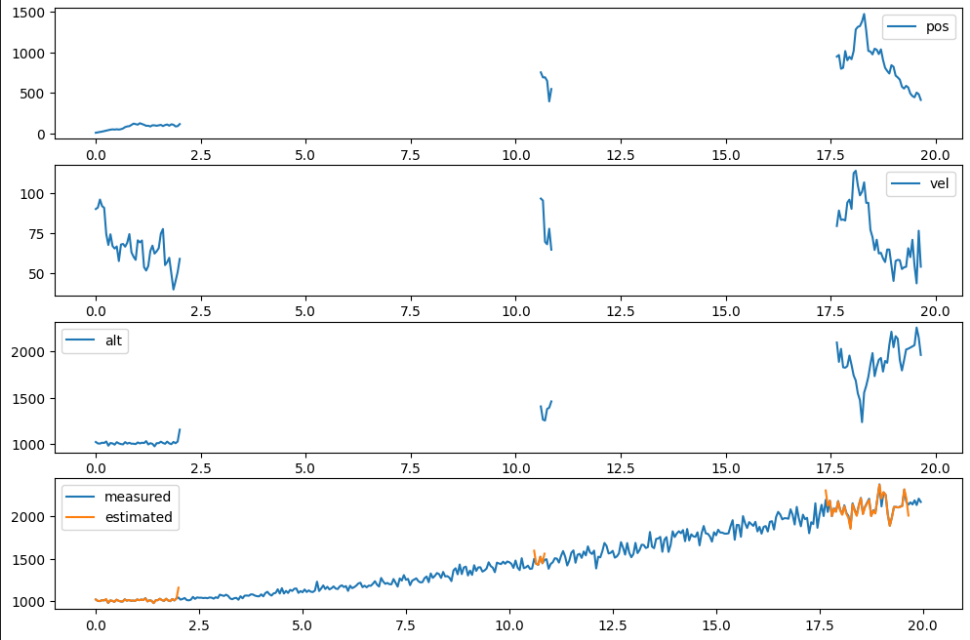
ㅠㅠ 파티클 필터 만들기는 실패
리샘플링이 문젠가
아니면 다른 중간 로직이 문제였을까
일단 구현한 코드는 아래 첨부
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
from math import sqrt
def fx(X_est, dt):
A = np.array([
[0, 1, 0],
[0, 0, 0],
[0, 0, 0]
])
A = np.eye(3) + dt * A
X_pred = A @ X_est
return X_pred
def hx(X_pred):
x1 = X_pred[0][0]
x3 = X_pred[2][0]
Z_pred = np.sqrt(x1**2 + x3**2)
return Z_pred
def get_radar():
global pos
vel = 100 + 5 * np.random.normal()
alt = 1000 + 10 * np.random.normal()
pos = pos + vel * dt
v = 0 + pos * 0.05 * np.random.normal()
r = sqrt(pos ** 2 + alt ** 2) + v
return r
dt = 0.05
X_est = np.array([[0, 90, 1100]]).T
N_particle = 1000
pos = 0
particles = np.random.normal(0, 1, (3, N_particle))
particles[0, :] = X_est[0][0] + 0.1 * X_est[0][0] * particles[0, :]
particles[1, :] = X_est[1][0] + 0.1 * X_est[1][0] * particles[1, :]
particles[2, :] = X_est[2][0] + 0.1 * X_est[2][0] * particles[2, :]
#print(particles.shape)
W = np.ones((1, N_particle), dtype=np.float16) * 1 / N_particle
t_list = np.arange(0, 20, 0.05)
pos_list, vel_list, alt_list, z_list, dist_list = [], [], [], [], []
z = 1101
def pf(z, dt):
global particles, W
for k in range(N_particle):
particles[:, k] = fx(particles[:, k], dt) + np.random.normal(0, 1, (3))
for k in range(N_particle):
W[0, k] = W[0, k] * stats.norm.pdf(z, hx(particles[:, k].reshape(-1, 1)), 10)
W = W / sum(W[0,:])
X_est = particles @ W.T
W_cum = np.cumsum(W, dtype=np.float16)
uniform_pts = np.random.uniform(0, 1, (N_particle, 1))
uniform_pts.sort(axis=0)
W_cum_dedup = sorted(list(set(W_cum)))
num_dict = {}
for i, val in enumerate(W_cum_dedup):
if (i - 1) < 0:
low_bound = 0
else:
low_bound = W_cum_dedup[i - 1]
upper_bound = W_cum_dedup[i]
num_dict[i] = sum(uniform_pts[uniform_pts >= low_bound] < upper_bound)
particles_tmp = np.zeros((3, N_particle), dtype=np.float16)
cum_idx = 0
for key, val in num_dict.items():
if val == 0:
continue
for idx in range(val):
particles_tmp[:, cum_idx + idx] = particles[:, key] + 0.1 * particles[:, key] * np.random.normal(0, 1, (3))
cum_idx += val
#print(key, cum_idx, val)
# cum idx가 1000이 안된다면(파티클 1000개 다 안채우면) 기존 파티클 재사용
if cum_idx < 1000:
particles_tmp[:, cum_idx:] = particles[:, cum_idx:]
particles = particles_tmp
W = np.ones((1, N_particle), dtype=np.float16) * 1 / N_particle
return X_est
for _ in range(len(t_list)):
z = get_radar()
X_est = pf(z, dt)
pos_list.append(X_est[0][0])
vel_list.append(X_est[1][0])
alt_list.append(X_est[2][0])
z_list.append(z)
dist_list.append(sqrt(X_est[0][0] ** 2 + X_est[2][0] ** 2))
plt.subplot(411)
ax1 = plt.subplot(4,1,1)
ax2 = plt.subplot(4,1,2)
ax3 = plt.subplot(4,1,3)
ax4 = plt.subplot(4,1,4)
ax1.plot(t_list, pos_list, label="pos")
ax2.plot(t_list, vel_list, label="vel")
ax3.plot(t_list, alt_list, label="alt")
ax4.plot(t_list, z_list, label="measured")
ax4.plot(t_list, dist_list, label="estimated")
ax1.legend()
ax2.legend()
ax3.legend()
ax4.legend()
plt.gcf().set_size_inches(12, 8)
'컴퓨터과학 > 필터' 카테고리의 다른 글
| 칼만필터 파이썬 - 9. 무향 칼만 필터 (0) | 2023.10.04 |
|---|---|
| 칼만필터 파이썬 - 8. 확장 칼만 필터 (0) | 2023.10.04 |
| 칼만필터 파이썬 - 7. 칼만필터를 이용한 가속도계와 자이로 센서 퓨전 (0) | 2023.10.04 |
| 칼만필터 파이썬 - 6. 칼만 필터를 이용한 추적기 구현 (0) | 2023.10.03 |
| 칼만필터 파이썬 - 5. 칼만 필터를 이용한 위치로 속도 계산 (0) | 2023.10.02 |