어제도 봤었지만 이번 장 분량이 장난아니기도 하고, 어제 짚고 넘어갔어야 했는데 빨리 진행한다고 안보고 넘어간게 있어서 오늘 안에 마무리 할수 있을지는 모르겠다.
오늘 오전에 마이컴 인터럽트 다루고, 오후에는 밀린 과제 숙제하느라 중간에 여유있을때 PPT 보면서 오늘 어떤 내용을 다뤄야할지 좀 보기는 했는데 하다보면 졸음이 가든가하겠지 생각하고 정신차려야지.
함수
모든 고급 프로그래밍 언어에서 일정한 연산 과정을 하나로 모은 것을 함수라고 한다. CS 공부하다보면 마주치는 서브루틴, 프로시저, 메서드 같은것들도 결국에는 함수같은거라 할수 있다.
잠깐 함수 파트를 하기전에 지난 시간에 정리를 제대로 안한
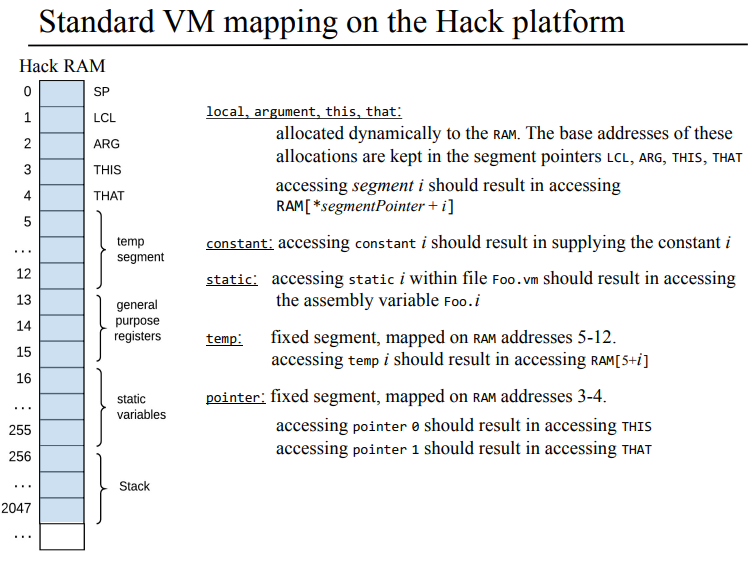
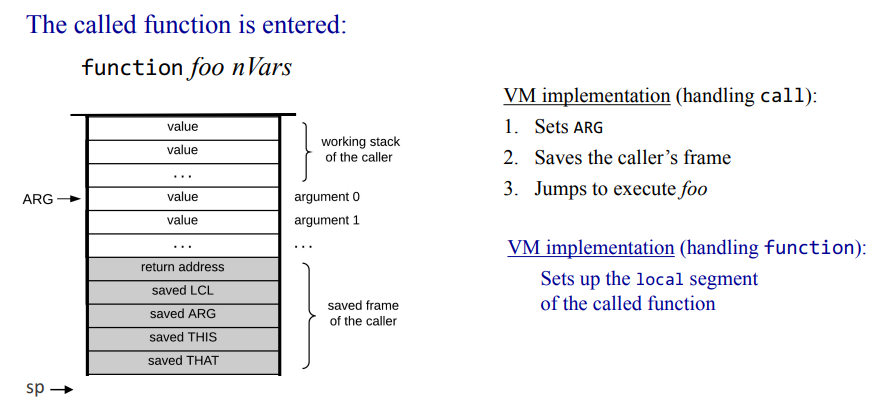
HACK 플랫폼에서의 표준 가상머신 맵핑을 잠깐 짚고 넘어어가야 할거같다.
이걸 뭐라고 해야할까. 그냥 메모리 맵처럼 변수가 RAM의 어디에 위치하게 되는지를 나타낸다고 하면 될거같은데 좀 더 잘표현할수 있을거같긴한데 아직은 잘모르겠다.
local, argument, this, that이야 이전 글에서 봤다시피 각 가상 메모리 세그먼트의 베이스 주소값을 보관하고 있다. 위에는 없는데 SP야 스텍 베이스 어드레스에서 시작해서 push, pop에 됨에 따라 바뀌는 주소를 보관하는 곳이고, constant는 어짜피 연산을 할때 담을 곳이 줘서 그런가 별 말이없다.
static 변수 경우의 설명이 좀 특이한데 Foo.vm에 있는 static i에 접근하기 위해서는 파일 이름을 붙여서 Foo.i라는 변수를 사용해야한다고 한다. 정적 변수이다보니 초기화는 되는데, 동일한 변수명으로 덮어씌워지는걸 방지하기 위해서 저런가 싶다. temp는 5-12 번지를 차지하고 있다 하고, 아 THIS와 THAT이 뭐하는건가 싶었는데 그냥 포인터 역활을 하는거였구나 이제 이해했다.
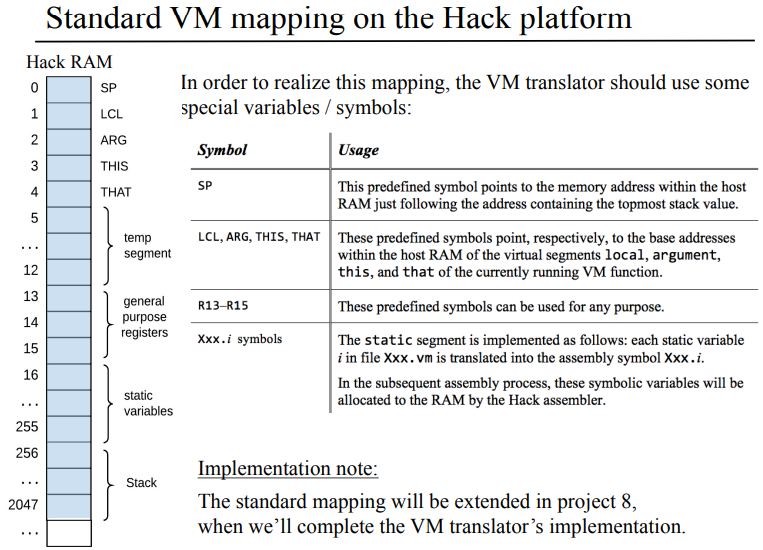
결국에는 HACK 플랫폼에서 돌아가는 가상머신, 가상머신 번역기를 만들어내려면 이런 선정의된 심볼들을 쓸수 있도록 고려해서 구현해야한다. 이 내용도 어셈블러 파트에서 봤는데 정적 세그먼트 부분이랑 스택이 추가된게 다르네.
다시 돌아와서
가상 머신 언어에서의 함수
가상 머신에서의 연산이라 하면 기본 연산인 add, sub 같은 것들과 추상화된 연산(함수) multiply, sqrt같은 것들이 있다. 이 기본 연산과 함수는 둘다 스택의 맨 위에 있는 값들을 매개변수로 쓰고 연산 결과를 스택의 위에다가 놓는건 똑같다.
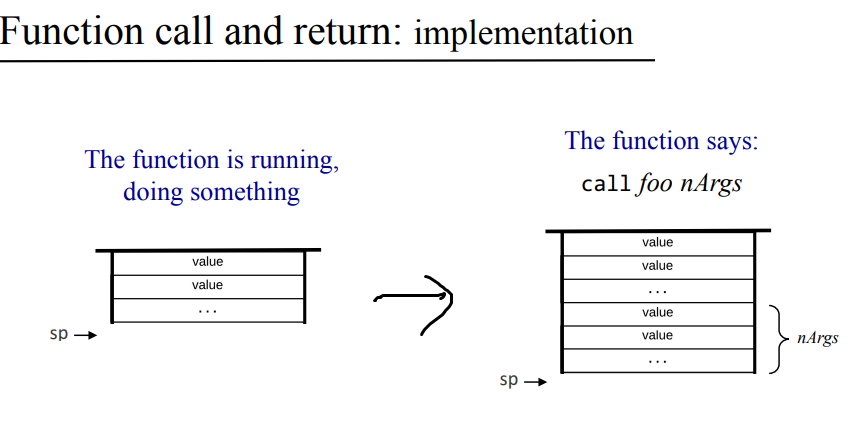
한번 세 함수로 이뤄진 VM 언어가 런타임에서 어떻게 돌아가는지 보자 우측의 스택은 전역 스택이 아닌 각 함수만의 공간을 나타내고 있다. main 함수의 call hypot을 통해 hypot 함수로 매개변수인 3, 4를 가지고 갔다.
hypot의 첫번째 곱샘 연산인 call mult의 경우 x를 스택에 2번 넣고 곱샘 연산을 수행하게 되는데 곱샘 연산한 뒤에는 3 두개는 더이상 없고 결과인 9만 남는다. 그 다음에 yy를 스택에다가 넣고 곱 연산을 하게 되어 결국에는 9, 16이 스택에 들어와있다.
그러면 mult의 private 스택에서는 어떨까. mult(3, 3)을 호출했을때 19번 줄 시점에서는 막 시작하면서 스택은 비어있고, 로컬 메모리 세그먼트에 sum, i 변수가 0으로 초기화 되어있다. 이 함수가 연산 수행 되고 나면 끝날때 쯤인 36번 명령 실행 후를 보면 mult 함수의 private 스택에는 곱샘 연산 결과인 9가 나오고 이 값이 hypot으로 반환된다.호출한다고 하자. 그러면 그 결과 hypot의 8번 라인 실행 후 private stack에는 9들어오게 된다.
콜링 체인 : 위의 예시 처럼 한 실행 시점에서 main -> hypot -> mult 같은 함수들의 관계가 나타나는대 이를 콜링체인이라고 부른다. 위에서 main, hypot, mult 이외에도 sqrt가 있었지만 현재는 실행되지 않았듯이, 컴퓨터 프로그램은 수 많은 함수로 이뤄지고 있지만 실행 시점에는 콜링 체인으로 이뤄진 일부 함수들만 일을하고 있는 상황이 된다. 근데 실제로는 콜릭 체인의 함수들은 자기가 호출한 함수가 동작이 종료되고 값을 반환할 때까지 기다리기 때문에 실제로는 콜링 체인의 맨 끝에 있는 함수가 활동하며 이 함수를 현재 함수 current function(현재 실행중인 함수)이라 한다.
위 main -> hypot -> mult 하는 예시에서 나왔드시 각 함수는 함수마다 고유의 지역 변수와 매개 변수를 가지고 있는데, 이 변수들은 함수가 호출되고 반활할때까지만 유지된다. 그러면 콜링 체인이 깊어지고, 재귀적이면 엄청 복잡할탠대 어떻게 메모리 관리를 해줄수 있을까?
호출과 반환 로직
이를 구현한 방법이 호출과 반환 로직인데 call and return logic 스택에서 이게 잘 동작한다. 이 호출과 반환 로직을 사용하기 위해서 포인터인 LCL, ARG, THIS, THAT을 사용한다. 책이랑은 조금 다르지만 위 예시의 hypot 함수에서 yy를 매개변수로 mult 함수를 호출한다고 생각해보자.
mult 함수로 넘어가기전에 hypot 함수를 중지하고 넘어간다고 했는데 mult 함수의 동작이야 hypot의 작업 스택에 간섭없이 mult 함수만의 작업 스택을 이용한다. 위 그림에서 나와있듯이 hypot의 작업 스택과 mult의 작업스택은 완전히 분리되어있다. 그러니 hypot함수의 내용들을 덮어씌울 일이 없으니 걱정할 필요가 없고 중지한 함수의 내용을 잘 보관만 하고 있으면 된다.
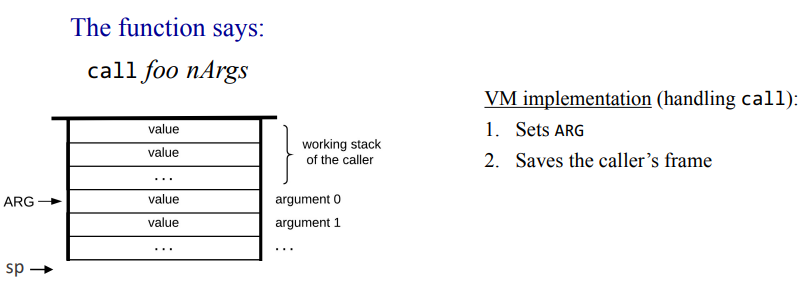
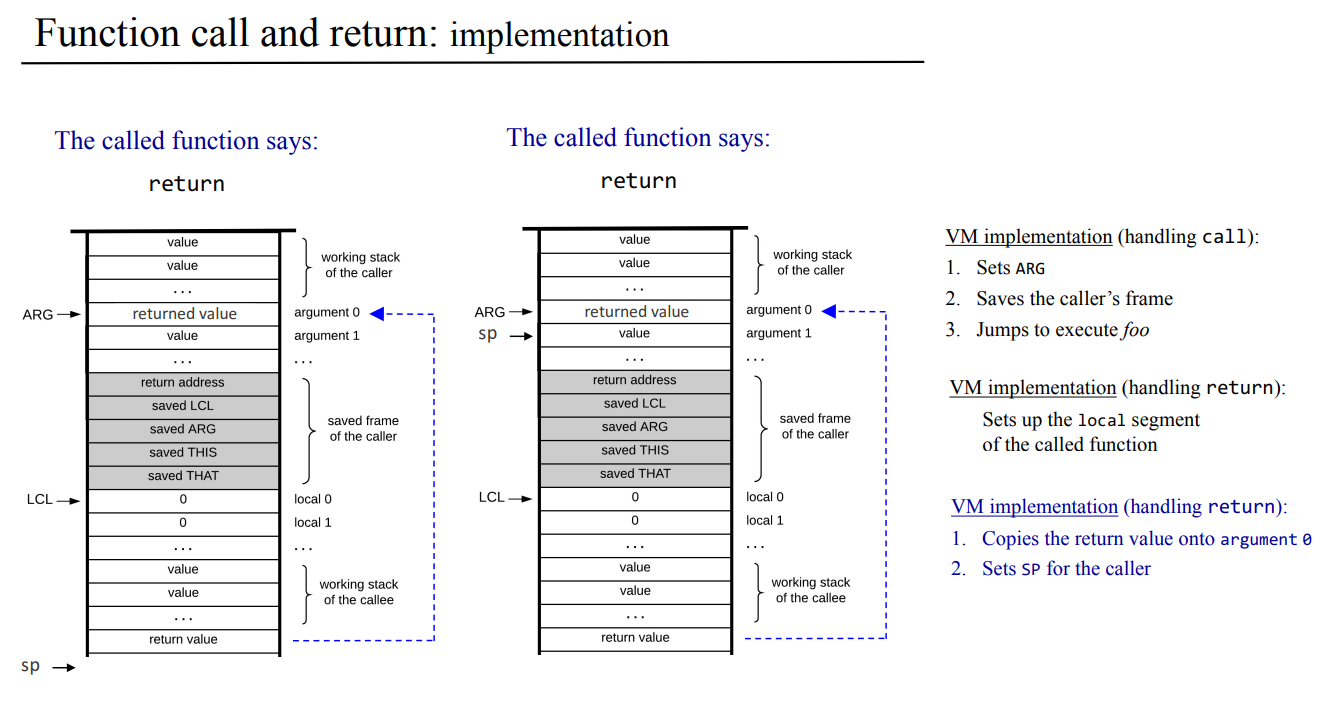
전역 스택에서의 호출 제어 handling call 과정
그러면 호출과 반환이 어떻게 스택에서 동작하는지 조금 더 자세히 보자. 전역 스택에서 프로그램이 돌아가다가 값들이 쌓아 놓고 아래의 값 몇개를 매개변수로 지정해서 foo 라는 함수를 호출했다. 그러면 어디서 부터가 매개변수인지 콜리에서 알수 있도록 표기해두어야 한다.
어디서부터가 매개변수인지는 포인터인 ARG에다가 매개변수 시작점의 주소를 담아두면 된다. 즉, 현재 호출하는 함수 foo의 매개변수 메모리 세그먼트를 만들었다! 그런데 이 다음에는 콜리에서 콜리만의 지역 변수, 콜리안에서 새로운 매개변수, this, that 같은 포인터가 사용되면서 콜러의 것을 덮어씌우면 안되니 콜러만의 정보를 저장해 두어야 한다. 콜러의 정보인 프레임을 스택에다가 추가하여 저장하면 아래와 같이 된다.
매개변수 뒤에다가 돌아와야 할곳의 (스택이자 메모리상의)주소인 return address, 다음에는 현재 함수의 LCL 어드레스, 현재 지정한 ARG 어드레스, 그외 THIS와 THAT 포인터까지 5개의 값(프레임)을 저장해두면 호출 제어는 끝나고, 이제 함수를 제어할 차례이다.
전역 스택에서의 함수 제어 handling function 과정
먼저 콜리의 로컬 세그먼트부터 설정해주고, 호출된 함수 동작을 하며 워킹 스택을쌓아나간다. 그러다가 반환해야할 값을 만들었다. 이제 반환 제어를 하면 된다. 반환이 되면 콜리의 내용은 필요 없으므로 나중에 재사용한다. 반환하려면 결과 값을 어디에다가 넣으면 될까?
전역 스택에서의 반환 제어 handling return 과정
1. 콜리의 리턴 값은 콜리의 매개변수 세그먼트 베이스 주소, 그러니까 콜러에서 첫번째 매개변수 자리에다가 넣으면 된다. 콜리를 호출할때 쓴 매개변수랑 콜리 내용들은 이제 필요없다.
2. 콜리의 결과를 기존 콜러의 워킹 스택 맨위에다가 넣었으니 콜리의 맨 위에있던 스택 포인터도 결과값 다음으로 위치를 옮겨주자.
이렇게 하면 콜리에서 연산한 결과를 콜러로 잘 가져왔다! 그러면 이게 끝인거 같지만 콜러의 정보를 저장해둔 프레임이 남아있다.
3. SP를 원래 자리로 옮긴 뒤에 기존에 콜러의 프레임에 있던 LCL, ARG, THIS, THAT을 복원 시키면서 그림 상에 있었던 콜리의 LCL과 ARG는 사라졌다.
4. 그 다음에는 return address로 점프하면 되는데, 이 부분이 정확하게 이해가 잘 되지는 않는다. 스택 포인터로 원 자리에 되돌렸으니 끝난게 아닌가 싶기는한데, 콜리의 어셈블리 명령을 마치면서 워킹 스택 상 데이터 정리는 끝났으니 콜리 호출했던 부분 다음의 어셈블리어 명렁어로 점프해서 나머지 명령어가 실행되도록 하라는 뜻인가 싶다.
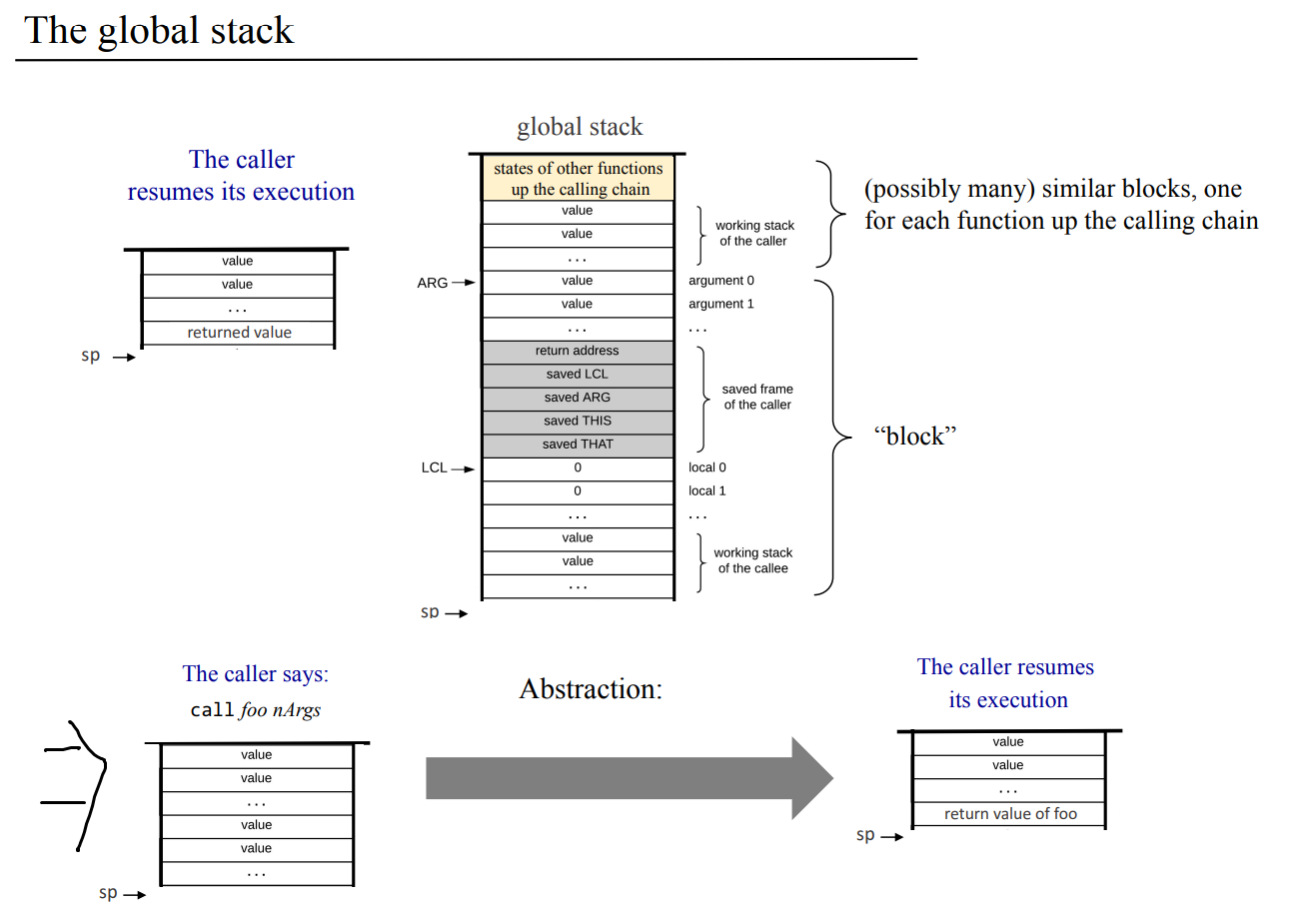
콜리 함수 연산을 마치고 값도 반환받고 스택 포인터와 명령어 위치도 되돌리고 나면 콜러가 다시 실행이 되는데, 기존에 매개변수 세그먼트나 프레임, 콜리 내용들은 이후 콜러 연산 과정에서 덮어씌우면서 재사용 된다. 그런 의미에서 우측 상단에서 블록이라 적어놓은거같다. 아무튼 call foo 매개변수 한 결과는 아래처럼 정리된다.
고급 언어 -> VM 코드 -> 런타임 상 동작과 전역 스택의 변화
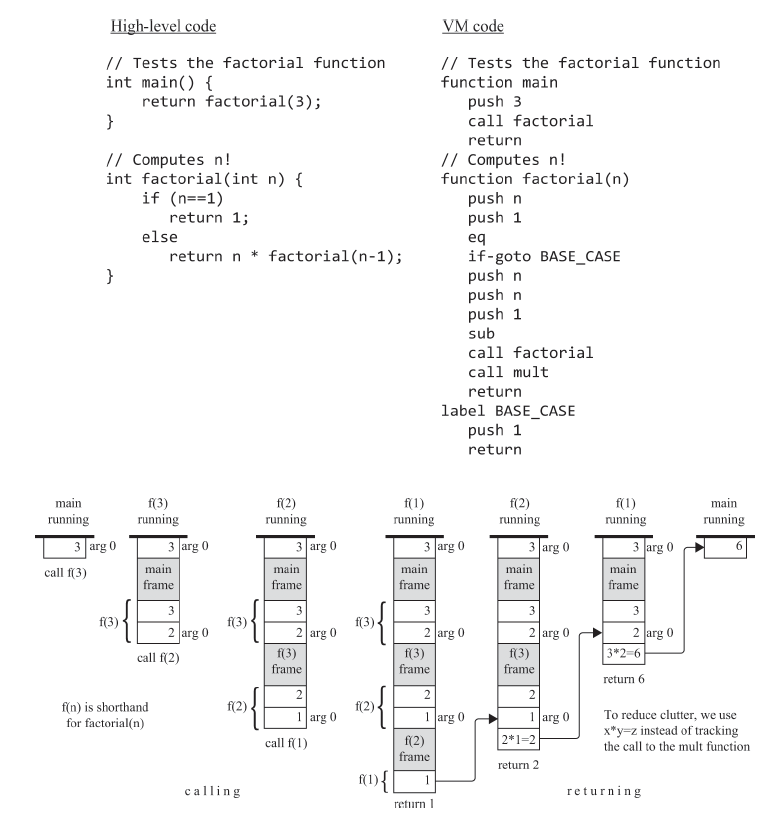
위 그림은 고급 언어로 구현한 팩토리얼 코드를 VM 코드로 컴파일 한 후에, 어떻게 전역 스택 상에서 동작되는지를 보여준다.
동작 과정을 쭉 적었는데 이렇게 정리할수 있을거같다.
1. 메인 함수에서 factorial(3)을 하면서 3을 매개변수 세그먼트로 잡고 호출했다.
2. f(3)을 연산하기 전에 메인 함수의 정보들인 메인 프레임을 저장해두고, 연산하며 3 -1 한 2를 매개변수 세그먼트에 잡고 f(2)를 호출했다.
3. f(2)을 호출하면서 f(3) 프레임을 저장하고, 전역 스택이 깊어지며 매개 변수 1 세그먼트 잡은 채 f(1)을 또 호출했다.
4. f(1)에서 f(2) 프레임을 저장했지만 바로 1을 반환한다.
5. f(2) 함수에서 2와 f(1)에서 받은 1을 곱한 결과를 구하고, f(2) 프레임을 복원한뒤 값을 반환한다.
6. f(3) 함수에서 3과 f(2)로부터 전달 받은 2를 곱하여 결과를 구하여 메인 함수로 반환하고, f(3) 프레임을 복원한다.
7. 메인 함수는 f(3) 함수로부터 값을 반환받고, 메인 프레임을 복원하며 프로그램이 종료된다.
좀 피곤하니까 8장을 빨리 마무리 하고 자야지 싶었는데, 8장 ppt 자료만 182페이지나 된다
7장께 120페이지 정도만 해도 장난아니게 많았는데;;
아무래도 오늘 8장을 정리 다하려고하면 잠은 좀 늦게 자야할거같긴한데 피곤해서 할수있는데까지는 해야겠다. 빠르게 진행하기 위해서 책 내용보다는 PPT 자료를 가지고 잘못 된 부분이 있더라도 그냥 넘어가야될거같다.
지난 장에서 가상머신의 기본적인 내용과 추상화와 구현에 대해서 봤다면 이번 장에서는 위의 ppt와 같이 분기와 함수, 그리고 함수 호출과 반환 마지막으로 HACK 플랫폼에서 가상 머신 구현 등의 내용을 다루고 있다.
아까 스택가지고 산술 논리 연산을 어떻게 하는지 봤지만 이번에는 이걸 가지고 어떻게 중첩 함수 호출, 파라미터 전달, 재귀, 메모리 할당, 테스크 재활용 등 프로그램 동작에 필요한 복잡한 작업들이 이뤄지는 지볼 건데, 그동안 당연한 것이라고 생각했던것들이 어떻게 동작하고 있는지 알아보자.
아 PPT 자료를 추가해놓자면 이번 장에서는 고급 언어를 컴파일 하면 나오는 VM 코드에서 나오는 분기와 함수 관련 명령어들을 다루는거같다.
런타임 시스템
모든 컴퓨터 시스템은 런타임 시스템 보델을 따르는데, 어떻게 프로그램을 실행하고, 프로그램을 언제 종료해야하고, 어떻게 함수에서 다른 함수를 호출할때 매개변수를 넘길지, 함수를 돌릴때 어떻게 매모리를 관리해야할지, 그리고 더이상 필요없을때 어떻게 메모리 자원을 해재해야하는지 전부 구체화 할수 있어야 한다.
이 책 nand 2 tetris에선 이 문제들을 HACK 플랫폼의 표준 맵핑을 이용해서 VM 언어 상세화 vm language specification를 다루고자 한다. VM 번역기가 이 규칙을 따르도록 만든다면, 런타임 시스템에서 동작할수 있게 되며 push, pop, add 같은 단순한 VM 명령어를 어셈블리어로 번역할 뿐만 아니라 프로그램이 동작하면서 감싸진 내용들에 대한 어셈블리 코드 전체를 만들어 낼수 있개 된다. 이 내용들이 어떻게 프로그램을 시작하고, 함수 호출과 반환을 처리할지에 대한 내용은 이 동작을 하는 완전한 어셈블리 코드를 만들어 내면 이해할수 있을거다.
(완전히 이해하기가 힘들어 편하게 번역체로 썻다.)
고급 언어의 효과(?) magic
고급 언어를 이용하면 아래와 같은 분모가 1인 근의 공식같이 루트나 제곱이 들어간 복잡한 수식도 sqrt(), power()같은 함수를 이용해서 프로그램으로 쓸수가 있다. 이와 같이 함수를 이용해서 무한히 늘릴수 있는게 고급 언어의 중요한 특징이라 할수 있는데, 더 나아가 sqrt, power 같은 이름으로 구현하면 이게 어떻게 만들었는지랑은 상관없이 응용 어플리캐이션 개발자들은 이게 뭘하는지 알고 사용할수 있을거다.
그리고 분기의 효과도 큰데, 분기를 이용하면 복잡한 로직/알고리즘도 코드로 표현할수가 있다. 예를들어 a== 0이 아닐때는 위의 이차식을 a가 0일때는 아래의 1차식의 근을 구하도록 구현이 가능하다.
근대적인 프로그래밍 언어들은 개발자들이 쓰기 쉽게 만들어져있어서 쉽고 강력한 추상화를 쓸수가 있지만 결국에는 고급 언어가 얼마나 고급스럽던지간에/ 사람이 쓰기 쉽던지간에 결국에는 어느 하드웨어 플랫폼에 동작할수 있는 기계어로 되어있다보니까 결국에는 컴파일러와 VM 개발자들이 분기와 함수 호출, 반환 명령어들을 구현해서 저수준 언어로 변활 할수 있도록 만들어야한다.
함수는 함수 하나 하나가 각자의 동작을 가지고 있는 독립적인 기능 단위라고 할수 있다. solve라는 계산 하는 함수가 있는경우 이 함수는 sqrt() 함수를 호출하고, 또 호출하고, power() 함수를 호출 할수도 있을 것이고, 어떤 경우에는 재귀적으로 아주 깊이 들어갈수도 있다. 이런 호출하는 함수를 콜러 caller라 부르며, 호출 받는 함수를 콜리 callee라고 한다.
콜러는 콜리를 호출하면 콜리가 작업을 끝낼때 까지 중지하고, 콜리는 매개변수가 있거나 없을수도 있지만 매개변수를 이용해서 연산을 하고 계산 결과가 있을지 없을지는 모르지만 콜러에게 반환해주면서 콜러가 다시 실행하게 된다.
컴파일러, VM 설계자가 고려해야하는 오버해드들
* 네이버에 검색해보니 개발에서 오버해드란 결과를 얻는데 추가적인 자원, 요소들이라고 한다.
- 콜리가 연산을 마치고 결과를 반환해야하는 주소의 저장
- 콜러의 자원 저장
- 콜리에서 필요한 메모리 할당하기
- 콜러의 매개변수를 콜리로 전달하기
- 콜리 코드를 시작하기
콜리가 연산이 끝나고 값을 반환시에는 다음의 오버해드들도 다뤄야한다.
- 콜리의 반환 결과를 콜러에서 사용할 수 있도록 하기
- 콜리에서 썻던 메모리 공간을 재활용하기
- 콜리 연산을 하기전에 콜러를 멈추면서 저장했던 메모리 자원들을 다시 사용하기
- 이전에 저장해둔 반환 주소를 찾아내기
- 콜러를 다시 실행하기
그리고 보통 함수를 쓰면서 위와 같은 오버해드가 발생하고는 하는데, 보통의 응용 어플리케이션 개발자들은 어셈블리어 코드야 컴파일러가 만들어주고, 2단계 컴파일 모델에선 컴파일러의 백앤드 단, VM 번역기가 알아서 다뤄주니 알필요가 없다. 하지만 지금 VM에대해서 배우면서 이것들이 어떻게 VM 상에서 동작하고 처리되는지를 알아보자.
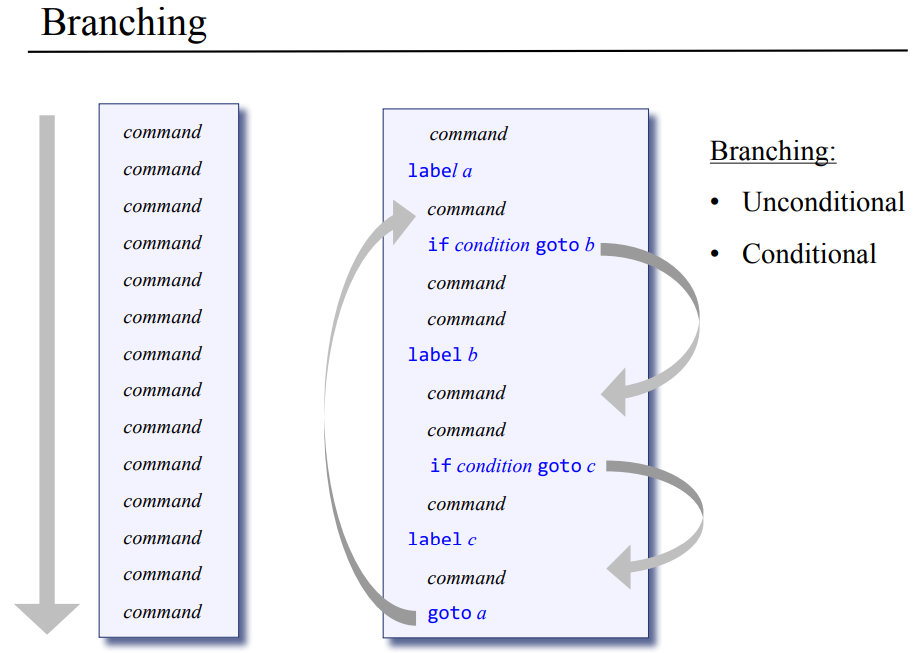
분기 branching
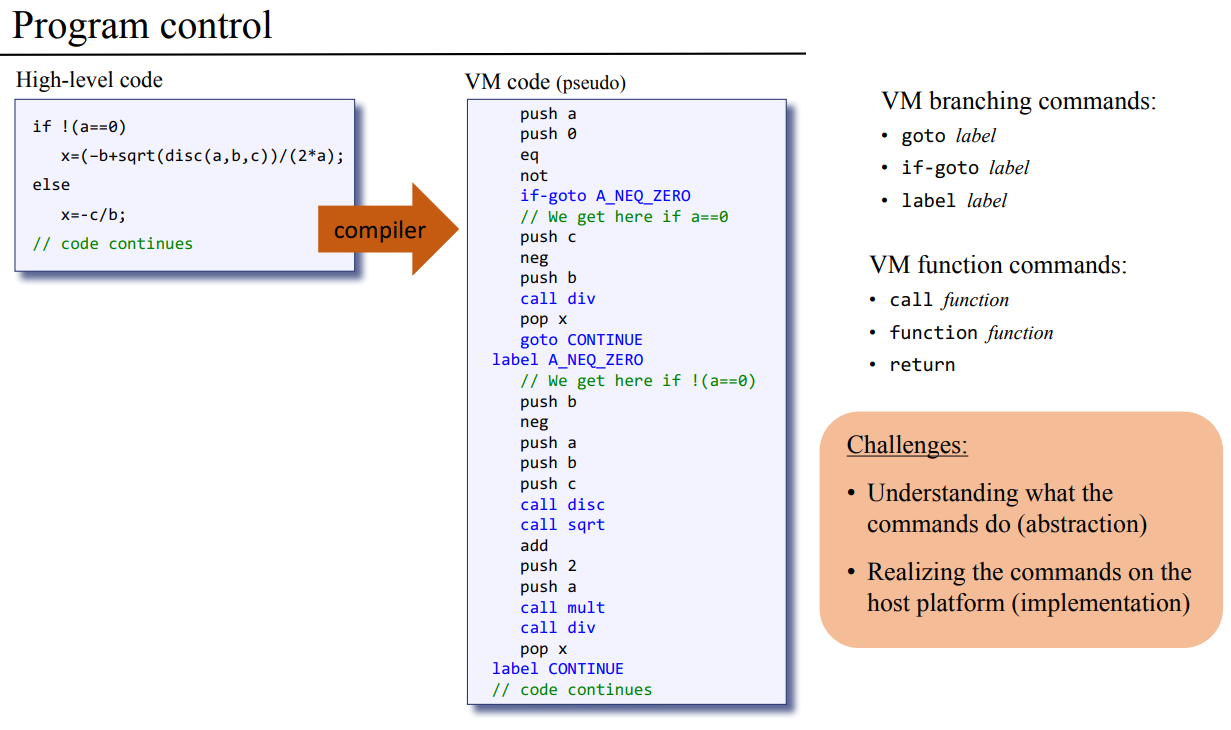
어셈블리어를 봤다시피 프로그램은 한줄 한줄 읽어가면서 순서대로 진행하는데 어느 과정을 반복하도록 루프를 사용하기도 하고, 조건을 주기위해 분기 명령을 주기도 했었다. 이전에 사용한 goto 그러니까 조건에 따라서 JUMP한게 분기의 예시라고 할수 있을거 같은데 이전 장에서는 라벨 심볼을 이용해서 어셈블리어를 만들었다가 이게 실제 주소로 바뀐걸 봤었다.
VM에서도 이런 라벨 심볼로 분기를 처리할 것이고, 무조건적인 분기는 goto를 조건부 분기의 경우는 if goto 심볼 명령을 사용할 거고 이때 스택의 맨 꼭대기에 있는 값이 참인지 거짓인지를 보고 판단한다. 위의 장은 고급 프로그램에서 컴파일한 결과 VM code 상에서 어떻게 표현되는지가 나온다. 이건 컴파일러의 영역이니까 지금 다루는건 아니고, 이번 장에서 구현해야하는 VM 번역기로 위의 분기 명령을 어떻게 타겟 플랫폼에서 어셈블리 명령어로 바꿀지를 고민해야한다.
지금까지 VM 언어로 산술 논리연산 명령어와 메모리 세그먼트 명령어 그리고 분기 명령어에 대해서 까지 알아봤고, 이제 함수 명령어가 남았다.
잠깐 분기 파트를 넘어가기전에 책의 내용을 조금 더 짚고 넘어가면, 위의 VM 코드로 표현한 곱셈 연산의 경우 VM 프로그램인 만큼 컴파일러가 만들어내고 그 다음에 VM 번역기로 어셈블리어로 만들어 동작시키고, 저 코드는 비트 단위를 이용한 곱셈 나눗셈 알고리즘을 쓴게 아니라서 비효율 적이다. 이 알고리즘은 OS 장에서 Math 클래스의 함수를 구현하면서 다룰 건데 그 코드를 JACK 컴파일러에 돌리면 Math.vm이 나온다.
이 외에도 OS에서는 수학 연산 뿐만이 아니라 메모리 관리를 위한 Memory.vm, 문자열 처리를 위한 String.vm, 배열 처리를 위한 Output.vm, 화면 처리를 위한 Screen.vm, 키보드 출력을 위한 Keyboard.vm, OS API를 제공하는 Sys.vm까지 8개의 파일로 컴파일된다.
욕심 같아서는 오늘 가상머신을 끝내고는 싶었는데, 생각보다 VM 2장 내용이 장난아니게 많아서 좀 일찍 자고, 내일 일찍 일어나서 해야되겠다.
지금까지 공부한 내용으로 컴퓨터라는 블랙박스가 하드웨어적으로 어떻게 구성이 된건지 알수 있었고, 앞으로는 이 블랙박스가 소프트웨어로 어떻게 원하는 동작을 하게 되는지 배우게 된다.
9장에서는 hack 컴퓨터에서 사용가능한 객체지향언어 JACK에 대해서 알아볼 것이고, 이 언어로 게임이나 OS 같은 것들을 만들 예정이다. 그리고 고급 언어로 응용 어플리케이션과 운영체제 구현으로 넘어가기 전에 여전히 어샘블리어와 고급 언어 사이에 공부하지 못해서 잘 모르는 중간 다리가 있는데 어떻게 하길래 우리가 구현한 고급 언어가 어샘블리어로 로 컴파일하는지 컴파일러, 가상머신, 운영체제 등에 대해서 배우게 된다.
JACK 언어에 대해서 공부 한 뒤에는 JACK 컴파일러를 알아볼건데 이 컴파일러는 신텍스 분석과 코드 생성 파트로 구성되어 있어 10장, 11장에서 다루게 된다. 그리고 근데 이 컴파일러가 뭘 하냐면, C 언어 컴파일러처럼 타겟 플랫폼에 맞는 컴파일러를 선택하여 바로 그 플랫폼에서 쓸수있는 저급 언어를 생성하는게 아니라 자바 가상머신이나 C#처럼 가상 머신을 돌릴 수 있는 VM 코드를 만들어 내고, 컴파일러가 만들어낸 VM 코드를 각 플랫폼의 가상 머신에서 돌려 어셈블리어로 만들고 이 어셈블리어를 번역하여 컴퓨터를 동작하게 되는 과정이 된다.
이와 같이 고급언어 -> 저급언어로 바로 컴파일 하는 컴파일러를 1단계 컴파일러라 하고, 고급 언어 -> VM 언어 -> 저급 언어와 같이 2번 컴파일하는 과정을 거치는걸 2단계 컴파일러(2 tier compiler)라고 한다. 내가 앞에서 어딘가에다가 가상머신과 관련된 내용을 정리했던거 같기도 하고, 기억이 가물가물한데 아ㅏ.. 그때 C언어 이식성과 어셈블리어에 대해서 설명하면서 정리했던거 같다.
뒤의 책 내용 본 바로는 C언어의 이식성과 가상 머신이 결국 한 언어로 여러 플랫폼에서 사용한다는 큰 틀에서는 같아보이긴한데 조금 더 들어가서 보면 차이가 있었던거 같다. 아무튼 좀더 정리하면서 다시 봐야될거같고. 가상머신이 VM code를 기계어로 바꾸게 된다.
가상화.. 컴퓨터 가지고 이것저것하면서 vm player, 버추얼박스에서 라든가, 가상 메모리라든가, 앞에서 공부하면서 가상 레지스터에 대해서 잠깐 봤고, 클라우트 컴퓨팅에서도 가상화가 쓰이면서 가상화라는 개념이 엄청 중요한거라고 한다. 이 가상화에 대해서 7, 8장에서 살펴볼수 있을거같다.
9장에서 JACK 언어, 10, 11에서 컴파일러(신텍스 분석과 코드 생성), 7, 8장에서 가상머신에 대해서 배운다고 했고 그러면 이제 OS만 남는거 같은데 이 OS는 정처기나 운영체제 수업을 들어도 OS가 프로세스니 응용과 하드웨어 사이를 연계해주니 자원 관리하는다고 배웠던거 같기는한데 그렇게 와닿지는 않았었다.
당장 여기서는 OS가 라이브러리들을 모은 것이라고 설명하고 있다. 문자열 처리나, 메모리 관리, 그래픽 처리, 유저 인터페이싱 등을 처리하는 라이브러리들의 모음. OS라고 하면 프로그래밍 언어로 컴파일해서 돌아가는 뭔가라 생각했는데, 라이브러리의 집합이라고 하니 조금 생소하게 느껴지긴하다. 아무튼 이 OS가 저급 언어와 JACK 사이의 그동안 아무리 들어도 외우기만 했지 막연했던 연결고리 같은 역활을 한다고 하며,
JACK이라는 프로그래밍 언어를 쓸수 있게 만드는 프로그램(OS를 말하는건지는 아직 잘 모르겠지만)을 어떻게 JACK으로 구현하는지를 배우게 되는데 이 방법을 부트스트래핑이라고 한다. 이 부분의 말이 잘 이해가 가지는 않는데, JACK을 VM 코드로 변환해주는 컴파일러를 JACK으로 만드는 방법을 배운다고 이해하면 되는건지 아직 감은 잘 안잡히지만 지금은 그냥 넘어가야 될거같다.
아무튼 12장에서 OS를 만드는 과정에서 하드웨어와 주변 장치를 효율적으로 제어 할수있게 하는 자료 구조와 알고리즘 기법들에 대해서 배우고 JACK으로 구현하는게 소프트 웨어 파트 전체적인 틀인거 같다.
중간에 JACK 코드 예시나
운영체제가 뭔지 컴파일러가 뭔지 조금 나오는데 보고 싶은 부분만 잠깐 짚고 넘어가면
OS : main 함수 단에서 문자열을 출력할때, 여기다가 코드가 어떻게 된지는 적지는 않았지만, output.printString 이라는 함수를 쓰는데, 이 함수가 OS API, OS에서 에서 제공하는 표준 클래스? 라이브러리 내용이란다. 그리고 객체를 생성할때 RAM 상에 새 객체의 주소가 어딘지, 어떻게 프로그램 동작 과정에 메모리를 효율적으로 관리할지가 OS의 영역이다.
컴파일 : 심볼릭한 고급 언어를 돌리려면 기계어로 바꿔야하는데 이 과정이 컴파일이며, 고급 언어 프로그램을 컴파일하는 프로그램이 컴파일러가 된다. 근데 아까 2 단계 컴파일에 대해서 언급했는데, JAVA, C#, python 등이 이런 2단계 컴파일을 하는 고급언어라고 한다. JAVA의 경우에는 컴파러로 컴파일을 하면 bytecode라고 하는 중간 코드가 나오고 이를 타겟 플랫폼의 JVM에서 기계어로 번역되어 동작한다.
2단계 컴파일을 하는 이유는 7장 끝에서 자세히 나오니 지금은 넘어가야지
nand 2 tetris PPT에서 이해하기 좋게 나와있으니 좀 복사해와서 쓰면
7장 가상머신 동작에서 배울 내용들을 아래와 같다.
굳이 한글로 다시 정리한다면 이럴거같은데.
개요
- 앞으로 배울거
- 컴파일
VM 요악
- 스택
- 메모리 세그먼트
abtraction 이걸 그냥 앱스트랙션이라 하는게 나을지, 요약이라 할지 아니면 인터페이싱이라고 할지 고민하다가, 다른데는 추상화라고 하는거같기는 한데, 추상화라고 하면 너무 막연한 단어인거같아서 요약이라고 적었지만 인터페이싱이 더 맞는 느낌인거 같다. 추상화나 인터페이싱이나 거기서 거기긴한데 abstrction 적힌걸 인터페이싱이라 하면 뜬금없는거같고, 추상화라고 하기에는 거부감이 좀 든다. 아무튼 추상화라 하면 실제 타겟 플랫폼에 맞게 구현하는건 아니지만 여러 플랫폼에서 사용 가능한 전체적인 틀을 짜는 정도?로 알고 넘어가면 충분할거같다.(1장인가 2장인가 쯤에서 이 개념을 입출력이 어떻게 되는지만 정의한거라고 썻던거 같은데 그게 그거지)
VM 구현
- 스택
- 메모리 세그먼트
VM 구현 플랫폼
- VM 에뮬레이터
- VM 번역기
VM 번역기
- 구현법
- 구현하기
JACK 언어로 Hello World를 하려면 알아야 할것들과 추상화
보통 코딩을 처음 공부할때 hello world를 치는 방법을 배울때 언어 기초 문법을 잠깐 배우고 바로 적어서 해내기는 했지만, 이 장을 시작하기 전에 JACK언어로 문자열을 출력하려면, OS API를 써야 된다고 짧게 말하고 넘어갔어도 실제로는 화면 띄우기, 클래스와 함수 처리하기, do와 while(와일은 위 jack 프로그램에 보이지는 않지만 os 라이브러리 어딘가에 있어서 넣은거같다.), 함수 호출과 리턴, 운영체제 등이 다뤄지고 있다.
하지만 프로그래밍 하는 사람들 중에서 하드웨어와 운영체제 단에서 이런걸 이해하고 코딩하는 사람은 비교적 적을거같다. 이런걸 몰라도 알아서 다해주니까, 위 내용들을 몰라도 output.printString()만 치면 알아서 자원 할당하고, 함수 호출해서 화면에 띄워주는데 맨 앞에만 알아도 되는걸, 다시 적으면 output.printString()이란 함수와 매개변수, 출력만 알아도 원하는 동작이 되는걸 추상화라 생각해도 충분할거같다. 아깐 abstraction을 요약이라고 했지만 요약이라고 하기에는 부족한거 같아서 앞으로는 추상화라고 하지만 그때 그때 병행해서 써야겠다.
이 글을 처음 쓸때는 책의 SOFTWARE 개요 파트만 보면서 정리했는데, 지금 강의 자료 앞부분을 보니 아까 적은 내용들이 나온다. 강의 자료 내용을 앞에다가 다시 끼워 넣으면 꼬이는 글이 더꼬일거같아서 그림이랑 같이 반복하면
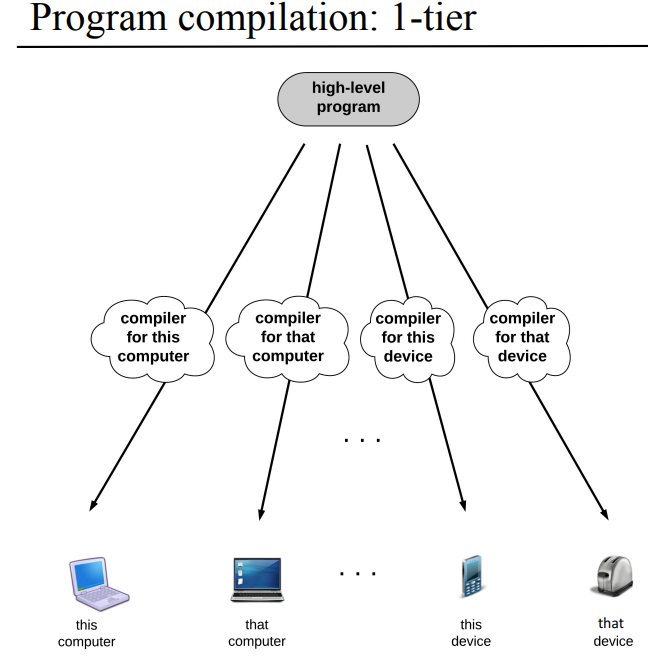
1단계 컴파일
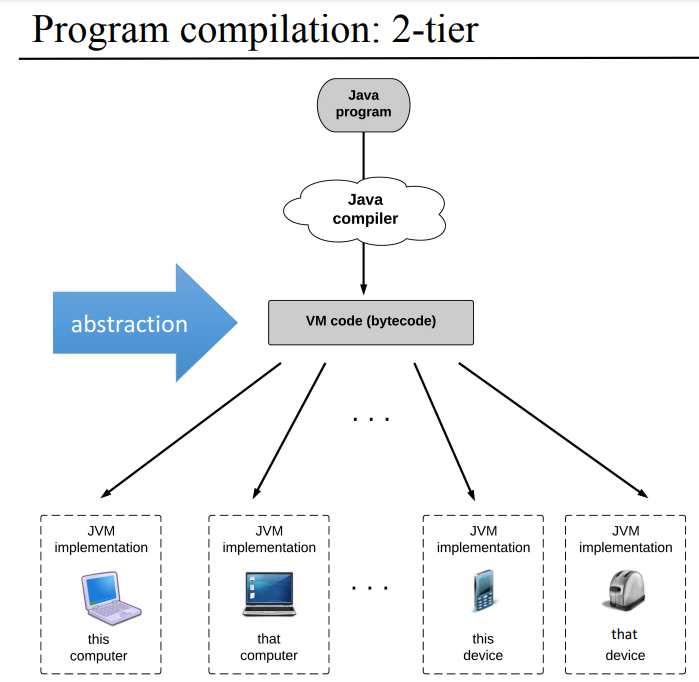
2단계 컴파일
1단계 컴파일에다가 gcc 예시를 갖다 붙이려 했는데 번거로울거같아서 그냥 생략하고, Atmega 128같은 마이크로 프로세서에다가 컴파일 해서 짚어넣으려고 하면 각 타겟 보드/플랫폼이 뭔지 선택해야하는데 각 타겟에 맞는 컴파일러를 써야하는게 1단계 컴파일의 특징이고
2단계 컴파일 같은 경우에는 자바로 프로그램 짜고 컴파일을 시키면 바이트 코드라고 하는 가상머신 코드(중간 언어)가 나오는데, 이걸 각 플랫폼에 맞게 구현한 JVM에 돌리면 프로세스가 동작할수 있는게 특징이 된다. 아, 다시 정리하면 2단계 컴파일에서 1번째 번역기를 컴파일러, 2번째 번역기를 가상머신(번역기)가 된다.
근데 이렇게 적었지만 여전히 각 플랫폼에 맞는 컴파일러를 작성한거나, 각 플랫폼에 맞는 JVM 을 만들어서 돌리는거나 결국에는 둘다 각각 컴파일러랑 가상머신이 필요하다는 점에서 뭔 차이인가 싶어서 그렇게 와닿지는 않는다. 책에서 계속 2단계 쓰는게 효율적이라고는 하는데, 각 플랫폼 컴파일러 짜는것 보다는 가상머신 만드는게 일이 적어서 그런건지. 아무튼 뒷부분에 역사적인 배경이 나오긴 하는데 그걸 다시 봐야 더 이해할수 있을거같다.
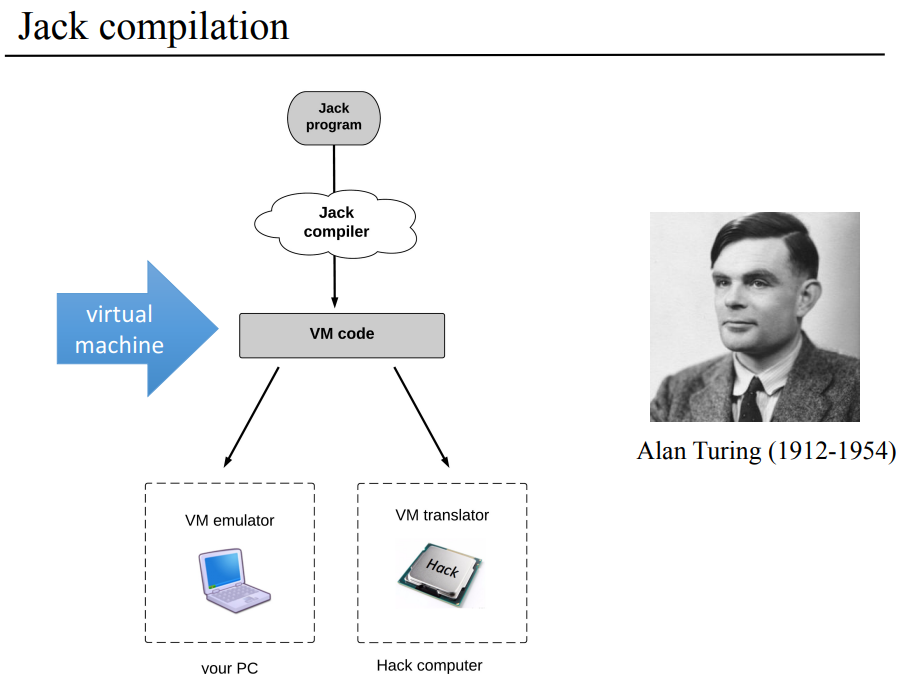
이 책을 보면서 7장에서 가장 햇갈렷던 부분에 VM 에뮬레이터랑 VM 번역기였는데, PPT로 보니까 좀 다르기는 하네. 글 순서에는 맞진 않는데 HACK 컴퓨터에 맞는 기계어를 만드는게 VM 번역기고, 지금 사용하는 PC에서 JACK 중간 언어를 돌릴수 있게하는게 VM 에뮬레이터인거같다. 잠깐 든 생각은 넘어가고 여기서 우선 VM 추상화? 추상 모델에 대해서 정리하면서 VM이 어떻게 된건지 어떻게 동작하는지를 보고 HACK에 맞는 VM 번역기 프로그램 구현에 대해서 다루게 된다.
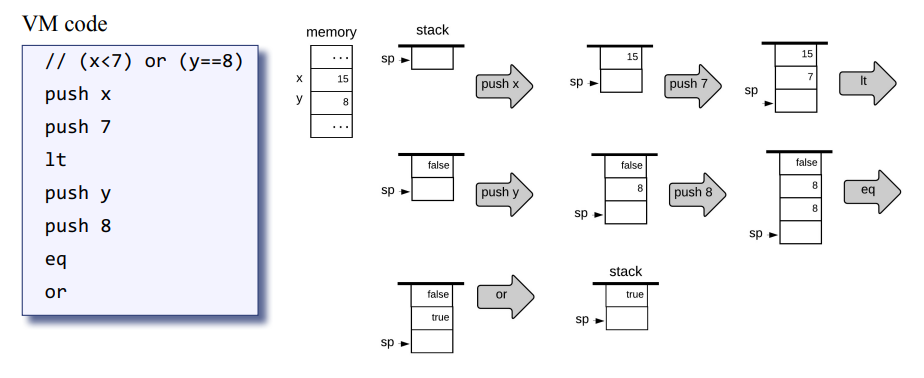
그래서 계속 VM 코드가 나오는데 VM 코드는 산술, 논리 연산과 메모리 제어 명령인 push와 pop, 분기 명령, 함수 호출 반환 명령 등으로 이뤄져 있다. 이 장에서는 기본 VM 번역기를 만들면서 산술논리연산과 push/pop 연산을 다루고, 다음 장에서는 분기와 함수 관련 명령을 배워 기본적이지만 완전한 가상 머신을 구현하게 된다. 그리고 이번 장에서 가장 중요한 스택의 동작 과정을 정리해보자.
스택 머신과 동작 과정
저자 분은 앞으로 VM 코드는 컴파일러로 쉽게 생성할수 있을 만큼 충분히 "고급 언어에 가까"워야 하며, VM 번역기로 효율적으로 기계어를 생성할 수 있을 만큼 "저급"이 아니라 "기계어에 가까워야" 한다고 한다. 즉, VM 코드는 고급어와 저급어의 차이를 잘 매꿔줘야 하는데 이를 가장 잘 정리할수 있는 자료 구조가 스택이며, 이 스택으로 번역 과정을 처리하는 아키텍처/구조를 스택머신이라고 한다.
스택이 어떻게 된건지, 연산하는건지는 자료구조 공부하면 나오는거니 그냥 넘어가고, VM code를 stack에서 어떻게 산술 논리 연산을 하는지 보면
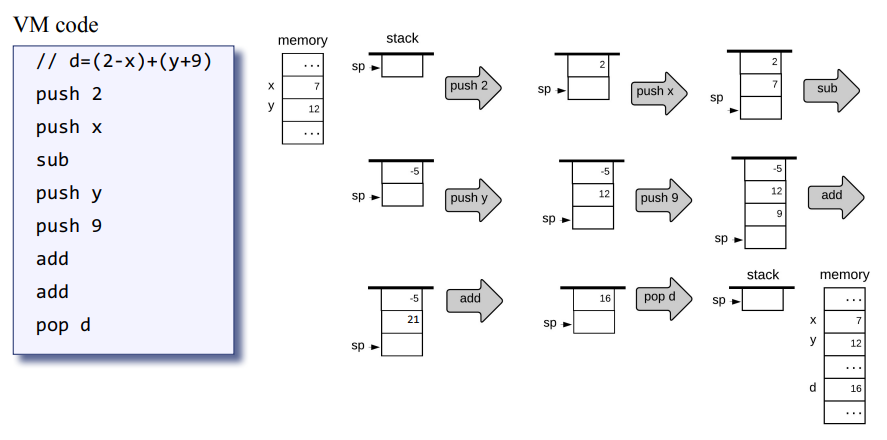
우선 산술 d = (2-x) + (y+9) 라는 산술연산의 과정을 보자.
1. push 2 : sp에 상수 2가 들어간다.
2. push x : sp에 변수 x의 값이 들어간다.
3. sub : 스택 최상위 2개의 값을 매개변수로 받아 뺀다. 2 - x
4. push y : sp에 변수 y의 값이 들어간다
5. push 9 : sp에 상수 9가 들어간다.
6. add : 스택 최상위 값인 y와 9를 꺼내 +연산 후 결과인 21를 push 한다
7. add : 최상위에 있는 -5와 21를 pop 한 뒤 -한 결과인 16을 push 한다.
8. pop d : 최상위에 있는 값을 pop 하여 메모리 변수 d 공간에 넣는다.
이번에 논리 연산 경우를 보자.
과정인 산술 연산과 동일하지만
논리 연산의 결과 true, false가 push 된다.
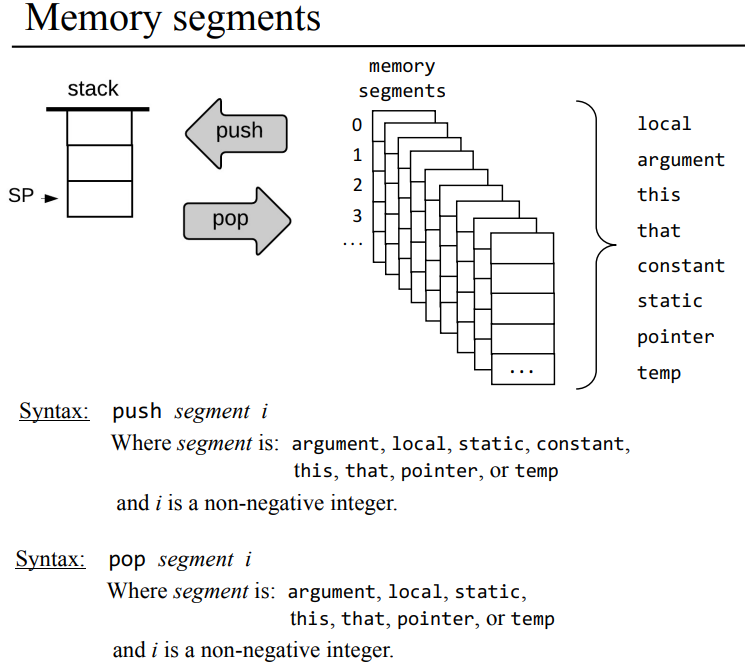
가상 메모리 세그먼트
특히 이 부분이 부족한 영어 실력으로 봐도 봐도 이해가 잘안가는 부분이었는데, ppt를 같이 봐야 이해가 좀 쉽더라
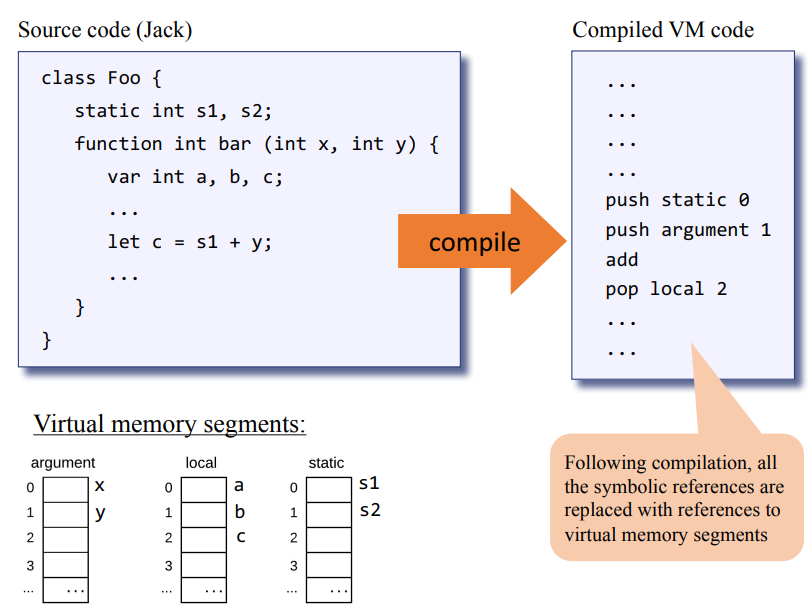
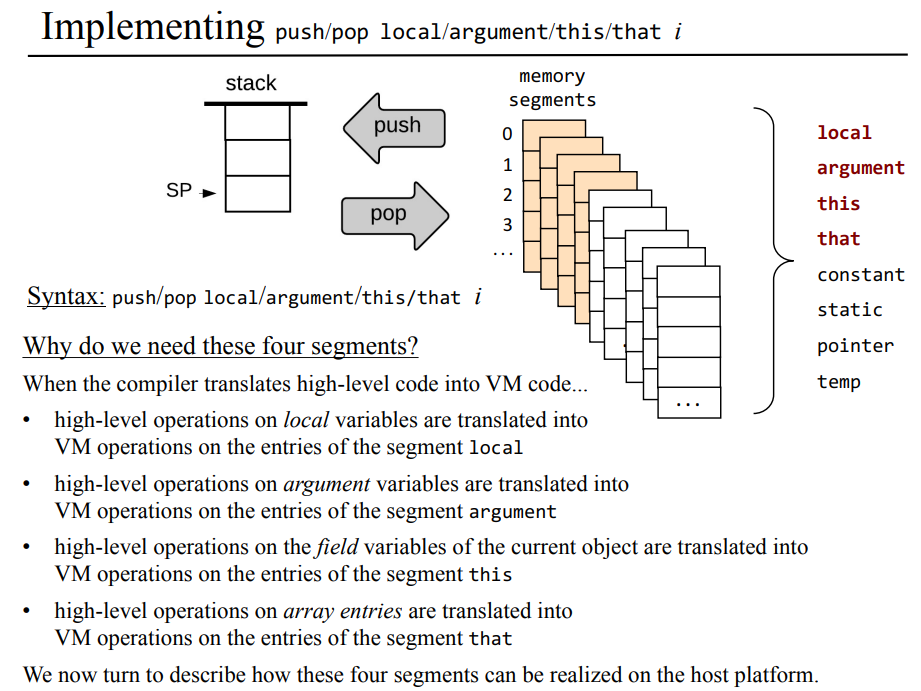
일단 메모리 세그먼트를 보기에 앞서 고급 언어를 공부하면 변수로 위의 소스코드 처럼 클래스 단의 static 변수나 함수 선언 문의 매개변수, 그리고 함수 안의 지역변수, 그리고 각 인스턴스의 속성 field 변수 등이 있다고 배웠을 것이다.
하지만 JVM이나 hack 플랫폼에서는 위의 s1, s2, a, b, c같은 심볼릭한 변수를 사용하지 않고, 가상 메모리 세그먼트의 일부로 표현하는데 이게 무슨소리냐면 static int s1, s2가 있으면 이 변수를 s1, s2라는 이름이 아닌 static 0, static 1 같은 식으로 변수로 사용하며, static 외의 변수 argument, local, static, constant, this, that, pointer도 뒤에 해당 변수의 번호를 붙여 쓴다.
예를 들어 지역 변수 x가 local 1, 인스턴스 속성 y를 this 3이라 할때 let x = y를 한다면, 스택에다가 y라는 값을 넣은 후(push), 스택의 값을 꺼내서(pop) x에다가 저장해야한다. 다시 정리하면 let x = y 연산은 아래와 같다.
push this 3 // 인스턴스 속성 변수 y(=this 3)을 스택에 넣어라
pop local 1 // 지역 변수 x(local 1)에다가 스택 최상위 값을 꺼내서 넣어라
위 내용만 봐서 가상 메모리 세그먼트가 뭔가 싶은데, ram 안에 argument, local, static, constant, this, that 등 각각의 메모리 세그먼트(일부 공간)이 존재한다고 보면 될거같다. 아래의 그림을 보면 이해가 더 잘될거 같은데 고급 언어 코드가 어떻게 VM 코드로 변환되는지 각 가상 메모리 세그먼트와 같이 정리되어있다.
그러면 위 그림의 고급언어 소스코드 let c = s1 + y; 부분을 컴파일한 VM Code 결과가 우측과 같이 된다.
차례를 정리하면 우측 항(s1 + y)를 한 후 좌측 항(let c)에다가 대입 해야하므로 다음과 같이 정리할수 있을거같다.
s1 + y 연산
1. push static 0 // static 가상 메모리 세그먼트의 0번째 값(s1)을 stack에다가 넣는다.
2. push argument 1 // argument 가상 메모리 세그먼트의 1번째 값 y를 넣어라.
3. add // stack 최상단 2개 값을 꺼내(pop), 덧셈 연산한 뒤에 스택에다가 다시 넣어라(push).
let c = s1 + y 연산
4. pop local 2 //스택 최상단 값(s1 + y)을 꺼내 local 2에다가 넣어라
스택 연산과 가상 메모리 세그먼트
스택과 가상 메모리 세그먼트 두가지만 놓고 본다면 위 처럼
push segment i
pop segment i
같은 문법으로 스택과 메모리 세그먼트 간에 값을 넣고, 꺼내고의 연산이 수행된다.
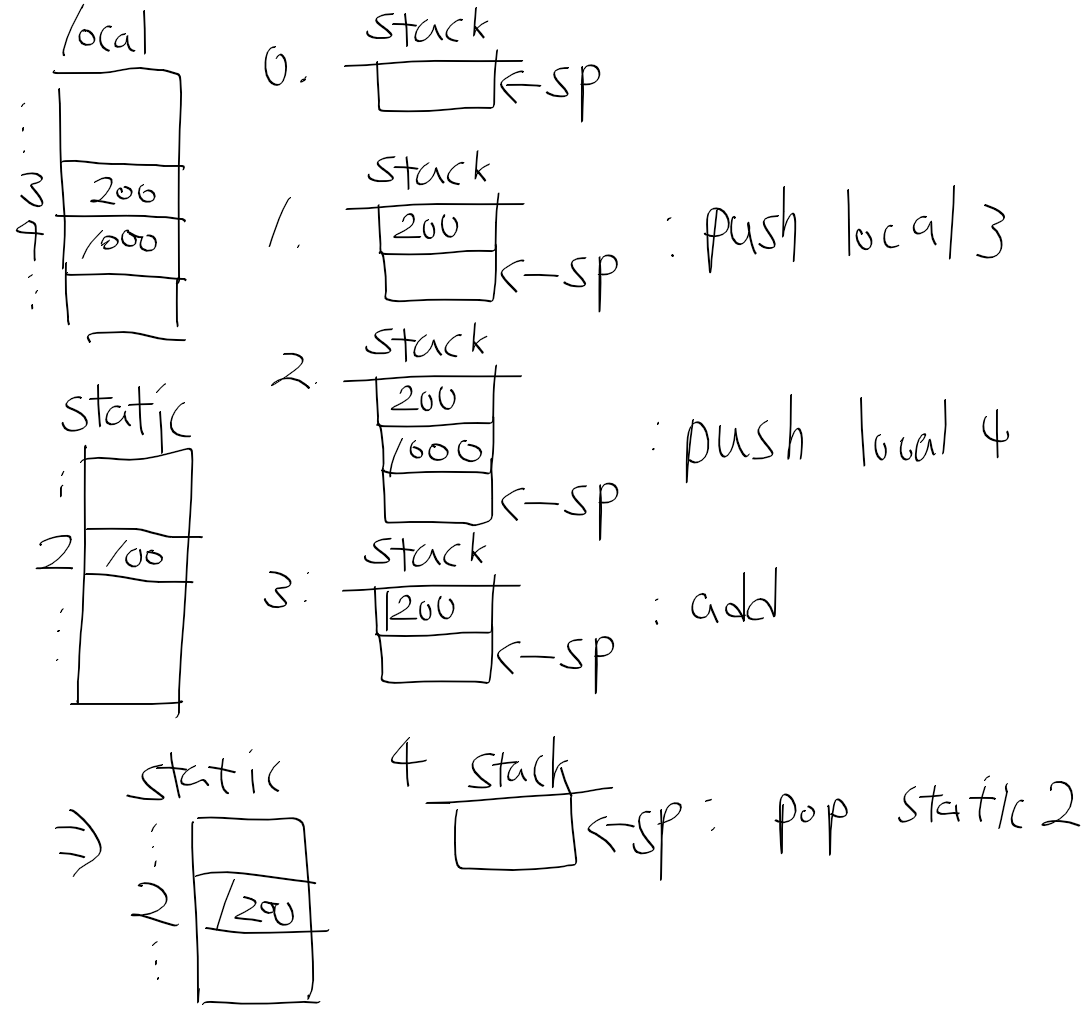
로컬 메모리 세그먼트의 3번지 값(200)과 4번지 값(1000)을 더한 후 static 메모리 세그먼트의 2번지에다가 넣는다면 다음과 같이 쓸수 있을거같다. (진작에 PPT랑 같이 볼껄, 괜히 잘 이해도 안되면서 그동안 책만 보느라 너무 해맨거같다.)
push local 3
push local 4
add
pop static 2
타겟 플랫폼(HACK)을 고려한 VM 구현
앞서 언급한 VM과 스택 머신에 대한 내용은 특정한 하드웨어 플랫폼을 고려하지 않은 추상화/요약한 것이라. 실제로 만들어 내려면 특정 하드웨어 플랫폼을 고려해서 표현해야 한다. 여기서는 VM 번역기를 구현하려고 하는데, 이를 만들려면 스텍과 타겟 플랫폼의 가상 메모리 세그먼트를 어떻게 할것인지를 고민해야하고, 또 VM 코드를 어떻게 타겟 플랫폼의 저급언어인지를 정리해야한다.
추상화와 구현의 차이 : 다시 정리하자면 이 앞의 내용은 VM 코드를 타겟 플랫폼의 어셈블리어를 고려하지 않은체 어떤 가상 메모리 세그먼트가 있고, 어떻게 연산할 것인지 대략적으로 정리했는데 어느 플랫폼에 한정하지 않고 대략적인 동작을 정리한 앞의 내용들을 VM 추상화 한것이라 하고, VM 코드와 타겟 플랫폼의 어셈블리어를 고려해서 맞춰 나가는걸 VM 구현이라 하는 거 같다.
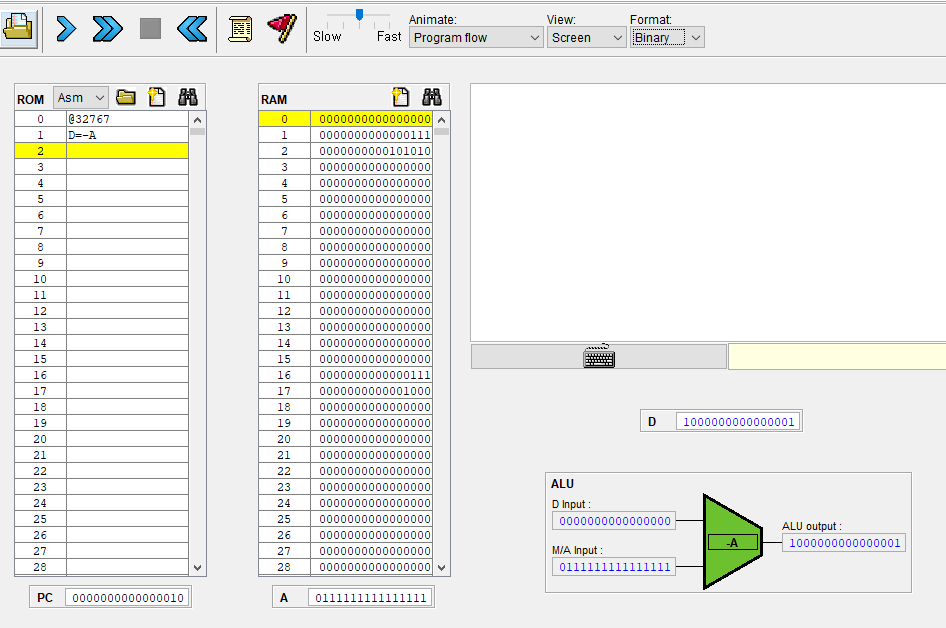
만들고자 하는 플랫폼이 폰 노이만 아키텍처를 따르고, VM 스택이 메모리 공간의 블록이며 이 VM 스택 블록은 고정된 베이스 주소에서 시작한다고 하자. 그리고 스택이 쌓일 수록(= 위에서 스택 연산 그림처럼 내려가는걸) RAM 상의 주소가 증가하고, 스택을 초기화/처음 만들면 스택 포인터를 스택 베이스로 지정해놓자.
그러면 이제 vm 코드인 push x과 pop x를 슈도 코드로 다음과 같이 표현 할수있다.
RAM[sp++] = x // push x = RAM[sp]에다가 x를 대입 후 sp를 1증가시켜라
x = RAM[sp--] // pop x = 변수 x에다가 RAM[sp]를 대입 후 sp를 1 낮춰라
이렇게 슈도 코드를 작성했으니 이번에는 이걸 어셈블리어로 표현시켜보자. 우리가 만들 HACK 컴퓨터는 스택 베이스 주소를 256로 잡고 있다. 그래서 SP = 256으로 설정해서 어셈블리어로 스택 초기화부터 시켜주면
@256
D=A
@SP
M=D
를 하면 SP 라는 가상 메모리 레지스터(R0)에다가 스텍 베이스 어드레스 256가 등록된다.
=> RAM[0] = 256 // ram 0번지가 스택 포인터이며, 베이스 어드레스 256 등록
그럼 이제 push x와 pop x는 아래의 연산이므로
1. RAM[256] 번지에 x를 넣고, sp++
2. RAM[256] 번지 값을 변수 x에다 넣고, sp --
어셈블리어로 표현하면 다음과 같을거 같다(책에 있는게 아니라 그냥 내가 짠거라 맞는지는 모르겠지만 대강 고급 언어랑 비슷한 슈도 코드를 위 SP 초기화 부분을 참고해서 이렇게 어셈블리어로 써봤다.)
1. RAM[SP++] = x
@x
D=M
@SP
A=M //SP(RAM[0])에 있는 값인 M(256)을 꺼내서 어드레스 레지스터 A에다가 넣어라
M=D //RAM[256]번지에 데이터 레지스터의 값(변수 x의 값)을 넣어라
@SP
M=M+1 //SP++
**
@SP
M=D
위 코드처럼 해버리면 R[0] = D가 되버리는거같아서 @SP에 있는 값인 256을 어드레스 레지스터 A에다가 담은 후 M으로 RAM[256]에 접근해 RAM[256] =D가 되도록 썻다.
2. x = RAM[SP--]
이 코드의 경우 현재 SP가 257이지만 꺼내고자하는 값은 257번지가 아닌 256번지에 있으므로 SP--와는 다르게 먼저 SP부터 -1해주자
@SP
M=M-1 // SP-- => SP가 257에서 256이 된다.
@SP
A=M //어드레스 레지스터에 256을 넣어 RAM[256]에 접근가능하도록하자
D=M // RAM[256]의 값을 데이터 레지스터에 저장한 뒤
@x
M=D // 변수 x에 데이터 레지스터에 저장해둔 RAM[256]의 값을 넣자
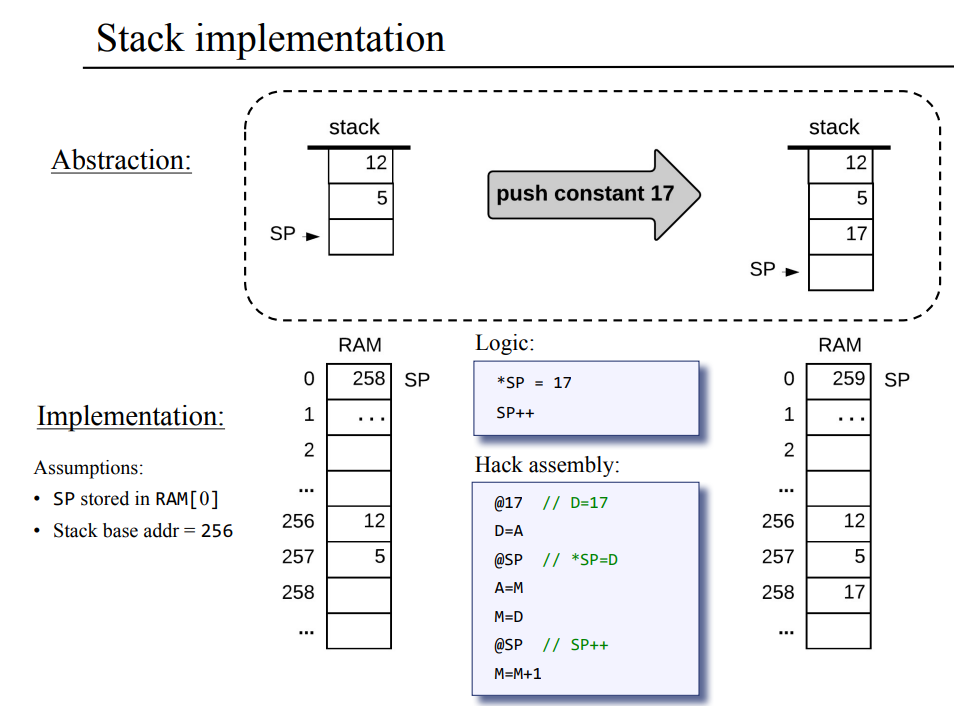
내가 책만 보고 이해한 내용은 위와 같은데 강의 자료에서는 그림과 같이 보기 좋게 추상화와 구현을 보여주고있다.
위 그림에서 보면 위의 abstaction 부분에서 push constant 17이라는 추상화된 VM 명령을
아래의 구현 파트에서 HACK 플랫폼에 맞게 어셈블리어로 정리하여 보여주고 있다.
구현 파트의 좌측 메모리를 보면 스택 포인터가 258을 가리키고, 258번지는 비어있었으나
push constant 17을 한 결과 sp는 259으로 +1이 되고, 스택 포인터가 가리키던 258번지에 17이 들어가 져있다.
다시 정리하자면 이와 같이 추상적인 VM 명령어들로 특정한 타겟 하드웨어에 맞는 저급언어를 만들어 내는것을 VM 구현 혹은 VM 번역기라 한다.
VM 프로그램
VM 프로그램은 다음 장에서 제대로 정리할거지만 VM 명령으로 이뤄진 프로그램이고, 확장자는 .vm으로 한다. 이 프로그램은 가상 머신 번역기로 한줄 한줄 읽어서 저급 언어로 번역되어 foo.vm을 번역후에는 foo.asm 파일이 나오게 된다.
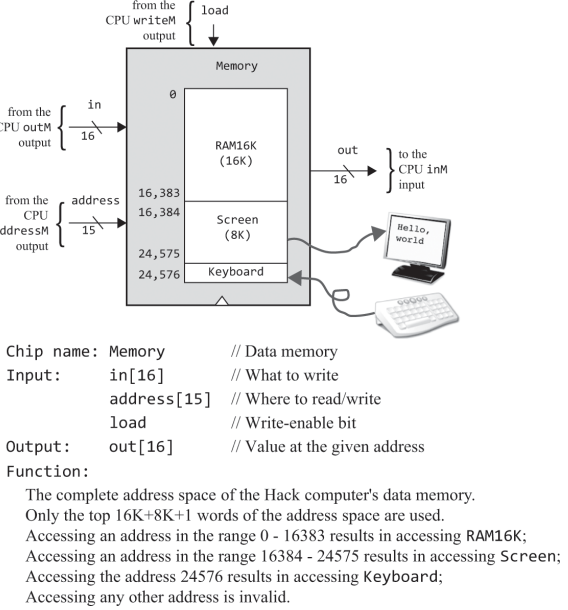
가상 머신과 RAM
앞 장에서 이미 봤었지만 Hack의 RAM은 32K 16비트 워드로 이뤄져 있었다.(하드웨어 만들때 16K RAM에다가 8K 스크린, 1개의 키보드 레지스터를 합쳐서 만들었던거 같긴한데 그냥 넘어가자) 여기서 RAM 주소 상 0 ~ 15는 가상 레지스터, 16 ~ 255는 정적 변수, 256 ~ 2047 은 스택 영역으로 사용하고 있으며, RAM[0]에서 RAM[4]번지 까지를 SP, LCL, ARG, THIS, THAT이라는 심볼릭한 변수 명으로 접근해서 쓸수 있고 이 주소들에 대한 내용은 아래의 표를 참고하자.
이름
위치
내용
SP
RAM[0]
R0으로도 접근 가능하며, 스택 포인터 역활로 처음에는 스택 베이스 어드레스 256을 넣어 초기화한다.
LCL
RAM[1]
local 메모리 세그먼트의 베이스 주소를 담는다.
ARG
RAM[2]
argment 메모리 세그먼트의 베이스 주소를 담는다.
THIS
RAM[3]
this segment의 베이스 주소를 담는다.
THAT
RAM[4]
that segment의 베이스 주소를 담는다.
TEMP
RAM[5-12]
temp segment
R13, R14, R15
RAM[13-15]
VM 번역기로 어셈블리어 코드 생성 시 별도 변수가 필요한 경우 이 레지스터를 쓴다.
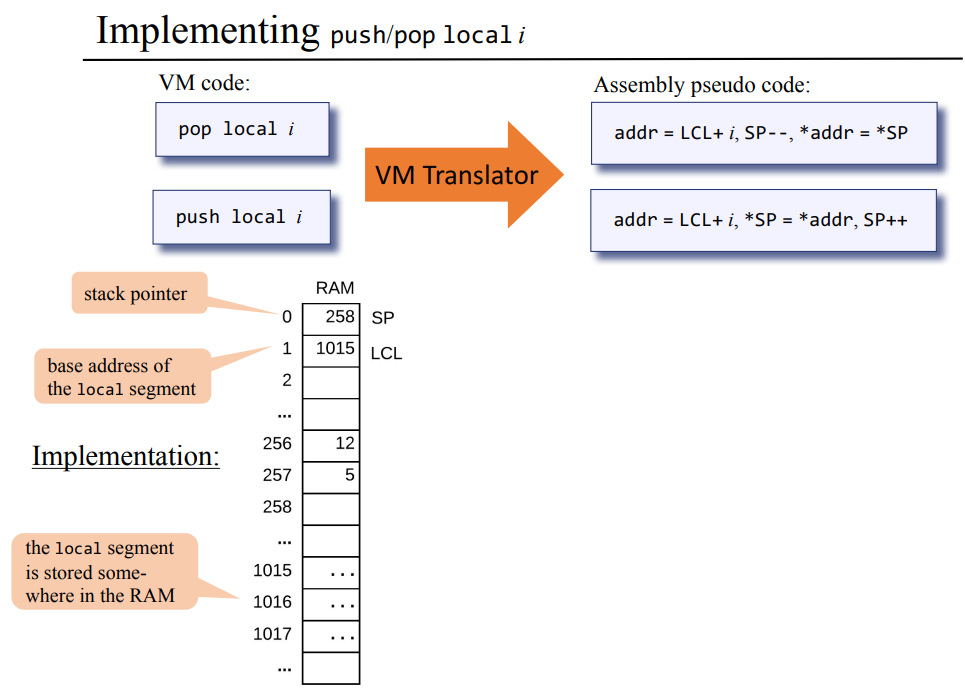
local 메모리 세그먼트 구현
앞서 스택의 상수 연산을 어셈블리어를 통해 구현한것 처럼 로컬 변수를 사용한 VM code를 번역한 결과 우측의 어셈블리 슈도 코드처럼 만들수 있다. 실제 위 슈도 코드를 어셈블리어로 정리하는건 시간 부족으로 그냥 생략하고 넘어간다. 그래도 잠깐 내용을 언급하고 넘어가면 LCL은 RAM[1]에 위치하고 있으며 베이스 어드레스가 1015가 된다.
LCL의 경우 값을 넣거나 뺄때마다 +1 혹은 -1 되던 SP와는 다르게 항상 고정된 값, 로컬 메모리 세그먼트의 베이스 주소를 가지고 있고 이 값은 변하지 않는다. 대신 pop/push local i 명령어가 올때마다 addr=LCL + i를 하듯이 기존 베이스 어드레스에서 해당 로컬 변수의 번호를 더한 주소에다가 값을 넣거나 가져온다.
다시말하면 LCL은 1015인 베이스 주소를 가지고 있고, push local 1을 한다면 addr = LCL+1, *SP = *addr, SP++ 연산을 하는데, RAM[1016]의 값을 스택 포인터가 가리키고 있는 위치에다가 대입하고, SP를 ++한다.
local, argument, this, that 메모리 세그먼트가 필요한 이유
결국에는 이런식으로 메모리의 일부, 세그먼트를 만들어서 사용하는 이유는 뭘까. 각 가상 메모리 세그먼트 이름에서 알 수 있다시피 local 세그먼트는 로컬 변수들을 보관하기 위해서, argument는 매개변수를 보관하기 위해서 this의 경우 현재 객체의 속성값을 다루기 위해서, that은 각 객체들(인가?)을 배열 처럼 다루기 위해서 만든 공간인거 같다.
이번 장을 공부하면서 아직 제대로 파지 않은 부분도 있고, VM 구현도 하기는 해야되지만 한동안은 이론 내용을 전체적으로 전보다는 좀 빠르게 훑어보려고 한다. 그래도 책만 아니라 PPT도 같이 본 더분에 많은 내용이지만 생각보다 빠르게 진도 나갈수가 있었다.
7장 VM 동작
1. 스택 머신
2. 메모리 세그먼트
3. VM 추상화와 구현
이번 장에서 정리한걸 크게 구분하면 위 세가지가 될거같고, 어느 정도 이해한거 같으니 이제 넘어가자.
여기서 만들 hack 어셈블러는 아무 고급 언어로 만들어도 된다고 한다. c나 자바같은 다른 언어는 공부한지 오래되서 다까먹엇다보니, 그냥 파이썬으로 구현해봐야될거 같고, 그러면 이런식(pyinstaller로 실행 파일로 만들지 않은 이상)으로 입력하면 기계어 파일을 만들도록 할거같다.
>python myAssembler Mult.asm
하면 Mult.hack이라는 기계어 바이너리가 나오도록
그런데 어떻게 어셈블러를 만드는게 좋을까?
책에서 말하기를 처음부터 다 하기보다는 두 단계로 나누어서 처음에는 심볼릭 참조 처리(대치)하는걸 고려하지 않은 어셈블러를 만들고, 동작이 잘 되면 심볼릭 참조 처리가능한 어셈블러를 만들라고 한다. 테스트 스크립트도 심볼릭을 쓴것과 안쓴 버전이 있다.
베이직 어셈블러 만들기
일단 베이직 어셈블러는 심볼 테이블을 제외한 내용들 그러니까 주석, 스페이스바를 넘기고 기계어록 하는 정도를 할수 있으면 되는거같은데, 베이직 어셈블러 구성요소로 파서 모듈과 코드 모듈을 만드는걸 추천하고 있다. 파서.. 프로그래밍 하다보면 종종 마주치는 용어인데 사전 보면 분석하다라고 나와있다. 근데 보통 동작은 다른 형태로 변환시키는게 주인거 같았는데, 당장은 입력을 분석해서 어째 저째한다는 의미 정도로 이해하고 넘어가야 겠다.
코드 모듈은 한글로 코드라 하면 늬앙스가 전달이 잘 안되는거 같고, 부호화라 하기에는 너무 딱딱하단 생각이 든다. 그냥 어셈블리어를 기계어로 부호화(변환) 시켜주는 부분이라 생각하자. 정리하면 파서는 어셈블리어 분석기, 코드는 어셈블리어 변환기 정도?
파서 모듈 & 코드 모듈
친절하게도 저자 분이 구현해야할 각 모듈별로 추천하는 함수와 매개변수, 반환값 동작들을 다 정리해주고 계신다. 근데 내가 정리하기는 싫어서 구현해놓고 그냥 동작하는지만 보고 코드나 올려야겠다.
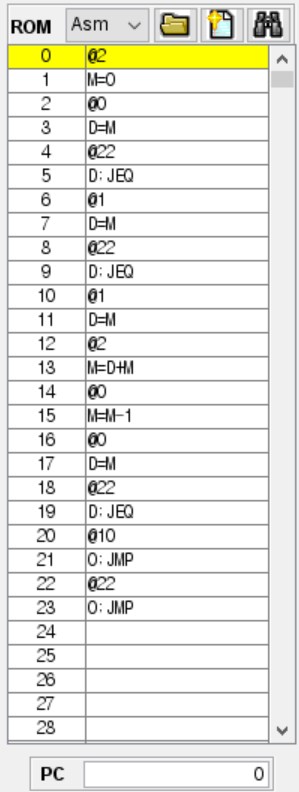
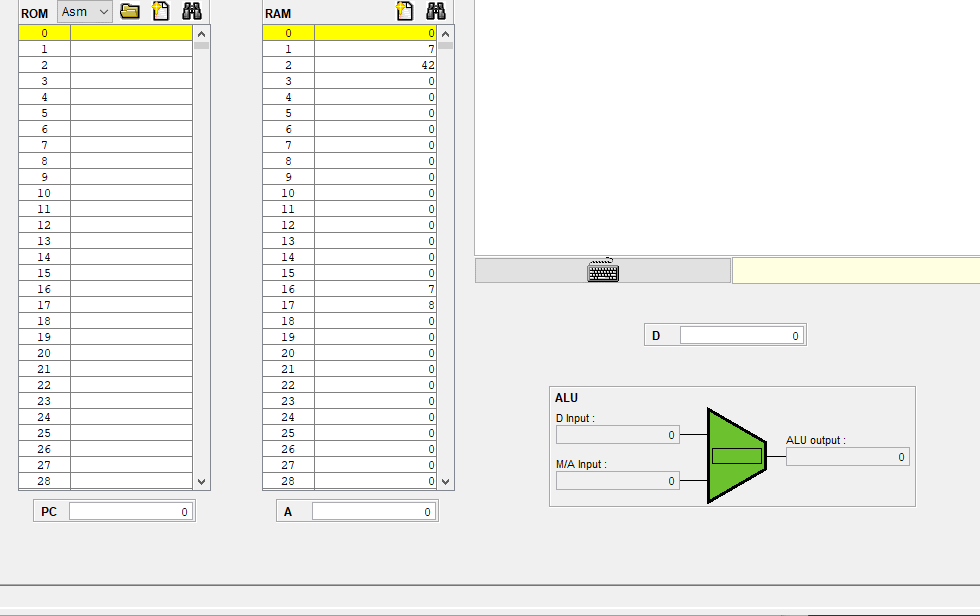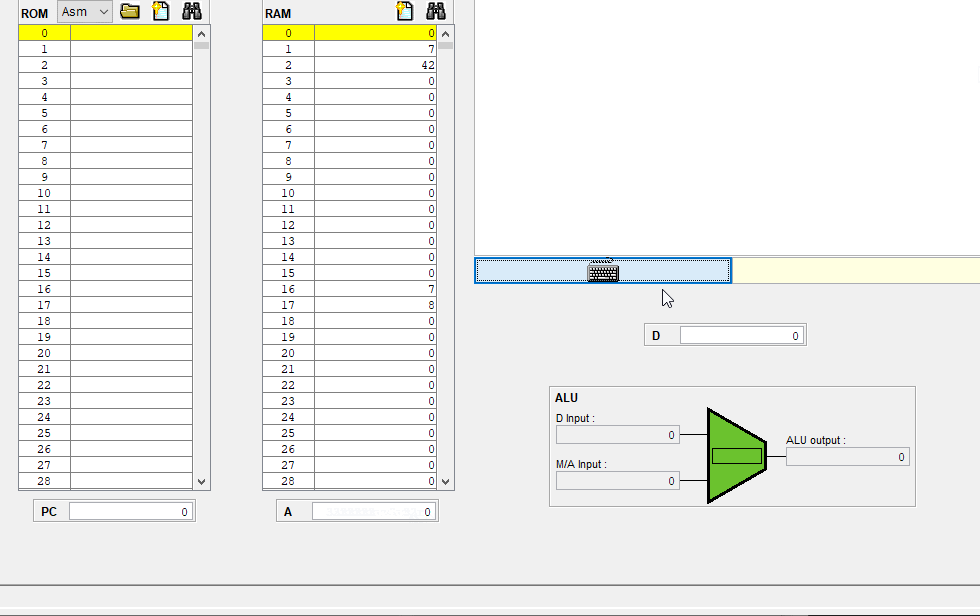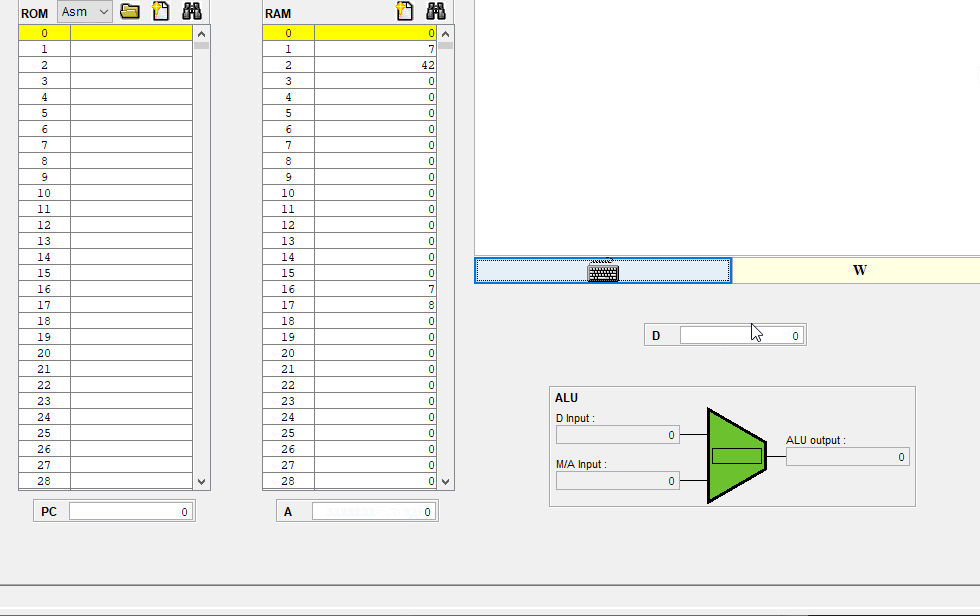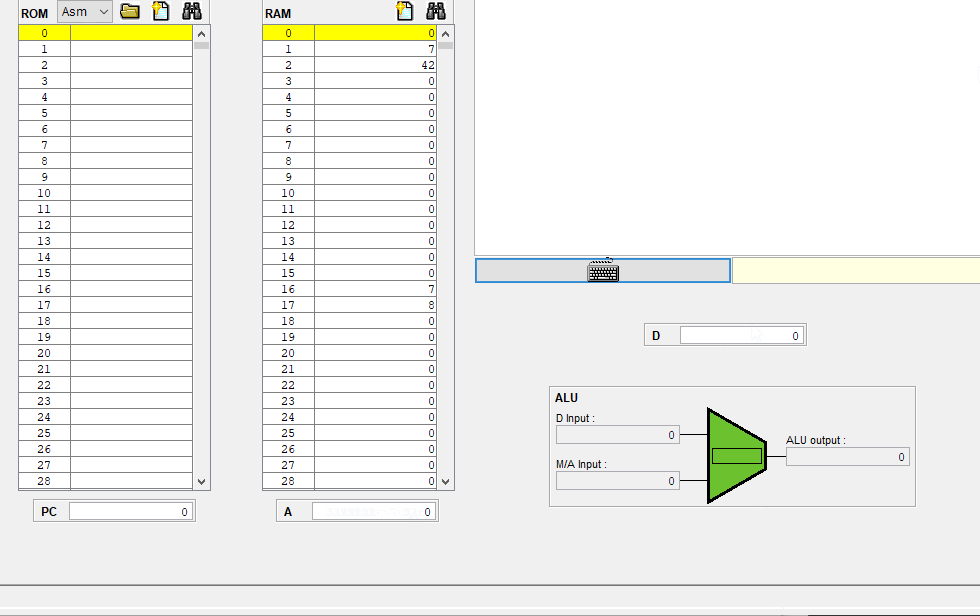
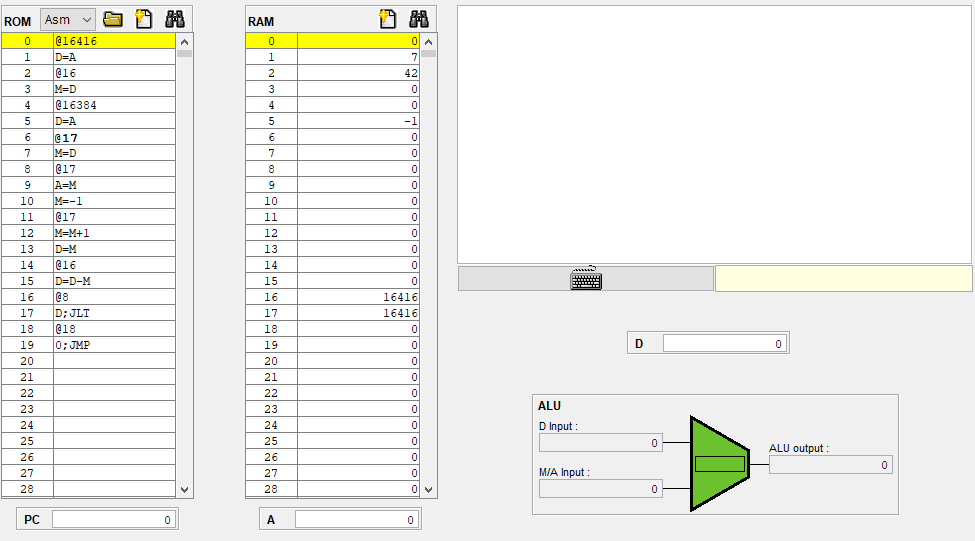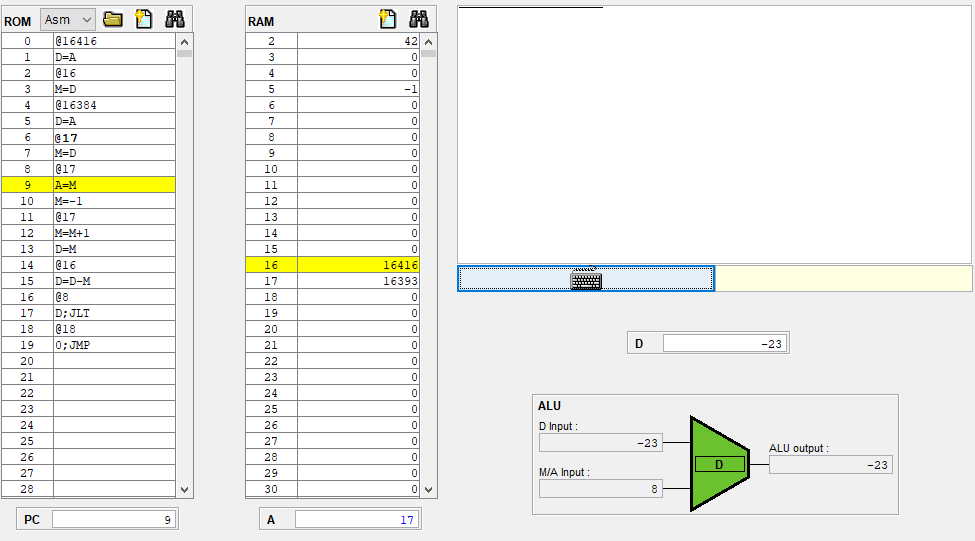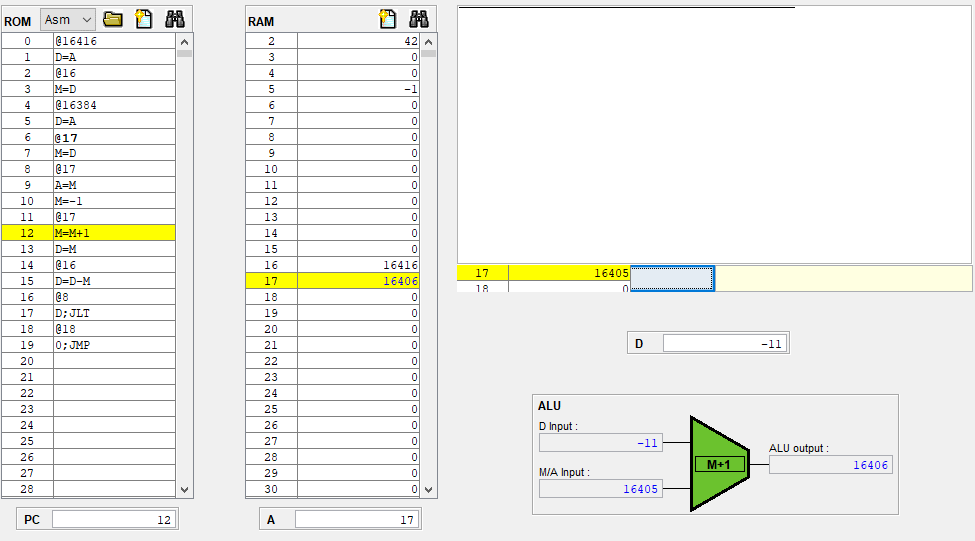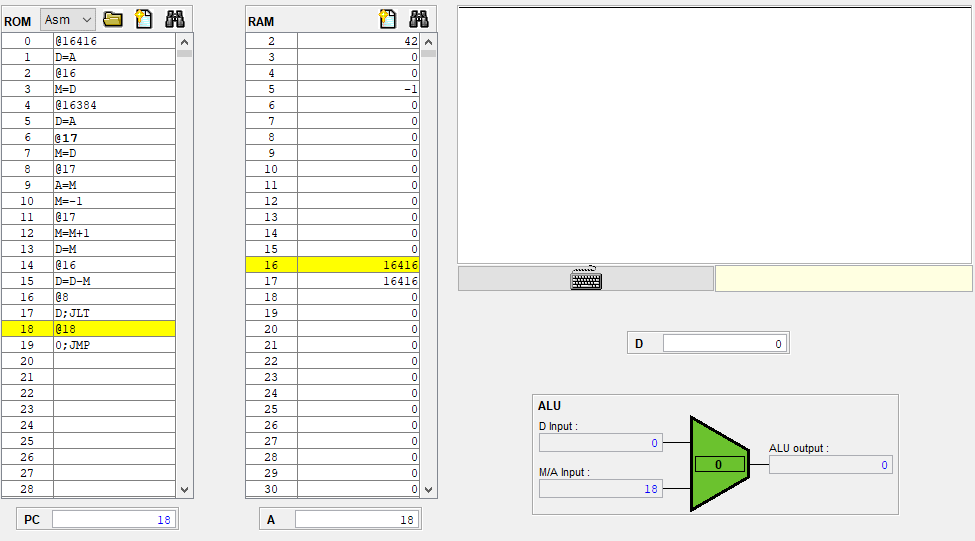
ROM에서 각자의 주소를 가지고 있었고 이들을 PC를 통해 넘어가거나 JUMP해서 다음 명령어를 수행할수 있었다.
라벨 심볼, 변수와 심볼 테이블
그런데 (LOOP), (END) 같은 라벨 심볼과 점프하기 전에 이 라벨심볼이 있었을때나@LOOP, @END
@i, @sum과 같이 변수 준 경우까지 분명 어떤 주소를 가리킨게 아니었어도, 시뮬레이션을 실행시키면 @LOOP 이던데가 @23이라던가 @i가 @53로 바뀌어져 있었다.
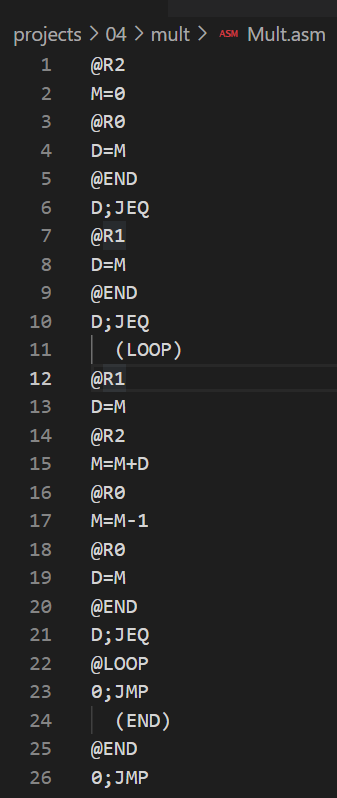
위는 4장에서 진행한 mult.asm 코드와 이를 cpu 에뮬레이터에 올렸을때 rom에 올라간 각 명령어들의 주소를 보여준다.
이 어셈블코드는 중간에 주석이 없음에도 총 26줄이었지만 ROM에 올라가면서 미리 정의된 심볼이 상수 주소로 바뀌었고, 라벨 심볼 (LOOP)는 사라졌었다. 그러면 이 라벨 심볼을 가리키고 있던 @LOOP는 어떻게 되었는지를 보면 @10으로 바뀌어 있다.
뒤에나오지만 미리 정의된 심볼이야 그 심볼들의 고유의 주소를 갖고, 라벨 심볼의 경우 그 라벨 심볼의 다음 줄에 있는 명령어를 가리키게 된다. Mult.asm의 경우 @LOOP는 기존의 (LOOP) 다음에 @R1(그리고 그 뒤에는 D=M)이 있었으므로 @LOOP는 @1(원래는 R1이므로 미리 할당된 주소 1으로 대체됨) 명령어의 주소인 @10으로 바뀌게 되었다.
이 때 라벨, 변수 심볼릭의 주소를 정리하기 위한 심볼 테이블이 사용되는데 어떻게 심볼릭 라벨과 변수가 각자의 주소를 가지게 되었는지를 그리고 심볼 테이블과 어셈블러의 동작 원리를 알아보고, 직접 구현한다.
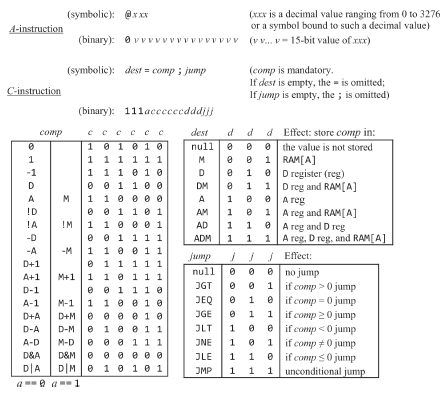
HACK 어셈블리어 복습
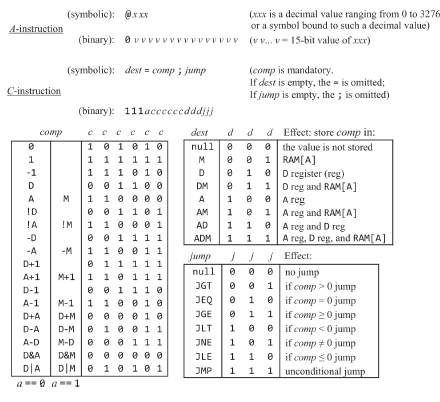
hack의 심볼릭과 바이너리 명령어를 정리한 테이블인데 또 복습을 할 필요가 있나 싶지만 잠깐 짚고 넘어가면 심볼릭에 따라 위 테이블의 바이너리가 나온다.
심볼릭에는 선정의된 심볼릭으로 가상 레지스터(R0, R1 ..., R15)가 있었고, 주소를 나타내는 SP, LCL, ARG, THIS, THAT, SCREEN, KBD도 선정의된 심볼릭이다(SP, LCL, ARG 등은 가상 머신 파트에서 다룬다). 라벨 심볼은 미리 정의되지 않았지만 어셈블리어를 작성하는 사람이 임의로 정할수 있는 점프 주소를 나타내는 심볼릭이 된다. 그리고 변수 심볼이 있지만 대충 넘어가고, 어쨋든 어셈블리의 과정에서 심볼릭으로 작성한 A 명령어들은 이 심볼들의 실제 주소를 나타내는 심볼 테이블의 값을 참조하여 대체된다.
심볼릭 규칙이야 심볼은 _, ., $, : 같은 특수기호로 시작되면 안되고, A 명령어 상수(주소)의 경우 0-32767(접근 가능 주소 공간 크기 : 2^15-1)의 범위 내여야 하며, 공백이나 빈줄은 넘어가니 ok, 위 동작을 나타내는 심볼릭<->기계어 테이블에도 나오지만 변수나 상수를 제외한 대부분의 경우 대문자로 써야한다.
어셈블러의 동작
일단 어셈블러의 동작을 크게 두가지로 나누면 명령어 처리와 심볼 처리가 있다.
1. 명령어 처리
어셈블러는 입력된 어셈블리어를 위 표처럼 기계어로 변환시켜야하고, 심볼릭 참조/참조 심볼릭이라고나와 있기는 한데 그냥 숫자 주소로 나타내는, 그러니까 실제로는 숫자 주소인 곳을 참조(의미)하는 라벨 심볼, 변수 심볼을 문자가 아닌 숫자(실제 주소)로 바꿀수 있어야한다.
2. 심볼 처리
일단 어셈블러로 어셈블리어를 변환시킬때 라벨 심볼이나 변수같은거 없이 상수만 쓰라고 할수도 있겠지만 어셈블리어로 코드를 짜야하는 사람들을 위해서 심볼릭을 쓸수 있게 해두었는데, 이를 위해서 어셈블러는 어셈블리어 코드 전체를 두번 봐야한다. 어셈블리어를 두번 읽어(한번은 심볼테이블만 만들고, 다음에는 심볼테이블을 참고하여 기계어로 변환) 변환하는 어셈블러를 투 패스 어셈블러라고 부른다.
투 어셈블러의 동작 과정은 두번 통과하기 전에 초기화 과정에서 우선 심볼 테이블을 만들고, 거기다가 선 정의된 심볼들과 그의 주소들을 넣어둔다.
첫 번째 통과 과정에서는 한줄 한줄 읽어가면서 라벨 심볼을 선언하거나 주석인 경우를 제외하여 A나 C 명령어를 만날때마다 0에서 시작하여 +1씩 카운팅을 하는데, 그러던 중에 (LOOP) 같은 라벨 심볼 선언문을 만났을때 심볼 테이블에다가 추가하고 그 라벨 심볼을 만났을때 카운팅 한 값 + 1 한 것을(라벨 심볼 다음 명령어 ROM 상의 주소)을 넣어주는 식으로 (LOOP)를 만났을때 카운팅된 값이 25이면, 라벨 테이블 상에서는 26이 등록된다.
위 심볼 테이블의 LOOP 같은 경우에는 주석문을 제외하고 보면 @i가 ROM의 0번을, M=1가 ROM의 1번을, @sum이 ROM의 2번을, M=0가 ROM의 3번을 받고, 그 다음에 (LOOP)를 만났으므로 심볼 테이블에 LOOP : 3 + 1=4가 심볼 테이블에 추가된다 하지만 라벨 심볼이 선언되었으므로 아직은 +1하지 않고, 그 다음의 @i는 ROM의 4번 주소를 받게 된다. 이 부분이 조금 했갈리지만 (LOOP)에서도 +1 카운팅을 했다면 @i는 ROM의 5번 주소를 받게 될것이다. 아무튼 이 과정에서는 변수는 아니지만 라벨 심볼의 주소들을 심볼 테이블에 등록해는것 까지만 하였다.
두 번째 통과 과정에서는 기계어로 번역하면서 변수도 처리하는데, 변수를 만난날 때 어떻게 되는지 예를들어 생각해보자. 만약 번역 중에 @R0을 만났을 때 하자 R0은 이미 심볼 테이블에 ROM의 0번 주소라고 정의되어있으므로 0으로 대치하여 기계어로 번역하게 된다. 하지만 심볼 테이블에 등록 되지 않은 경우에는 이 변수를 심볼 테이블에다가 추가하고, RAM 상의 주소를 할당받게 된다.
잠깐 앞에서 햇갈렸던거 같은데 (LOOP), @LOOP 라벨 심볼의 경우 @LOOP는 점프할 명령어 주소, 그러니까 ROM 상의 주소로 대치되고, @i, @sum과 같이 라벨 심볼이 아닌 변수의 경우는 명령어의 주소가 아닌 데이터의 주소 RAM 상의 주소로 대치된다.
아무튼 다시 돌아와서 심볼 테이블에 없는 새 변수를 처음 만나게 된다면 RAM의 16번지를 할당 받게 되는데 0 ~ 15까지가 가상 레지스터 선정의 된 심볼들의 저장 공간으로 먼저 할당 받았기 때문이다. 그래서 그 다음 또 새 변수를 만나면 17, 18, ... 씩 올라가며 주소를 값으로 가지게 된다.
다시 어셈블리어와 심볼 테이블을 보면, 첫번째 패스로 LOOP와 STOP의 ROM 상의 주소가 선정의된 심볼들(KBD 뒤에 LOOP) 다음에 추가 되어 있고, 두 번째 패스때 가장 먼저 변수 @i를 만나 RAM 16번지를, 그 다음에 @sum을 만나면서 RAM 17번지가 할당되어있다.
이번 장은 간단한 어셈블러를 만드는거다 보니까 투패스와 심볼 테이블 말고는 크게 새로운 내용도 없고 분량도 적었다. 이제 어셈블러 구현으로 넘어가자.
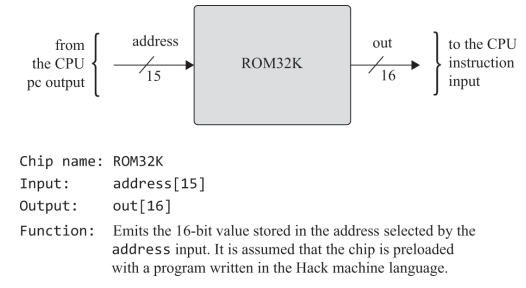
그 다음으로 만들건 32K ROM이다 32K니까 2^5 * 2^10 = 32 * 1024이고 2^15만큼의 주소를 갖는다.
1. ROM 32K
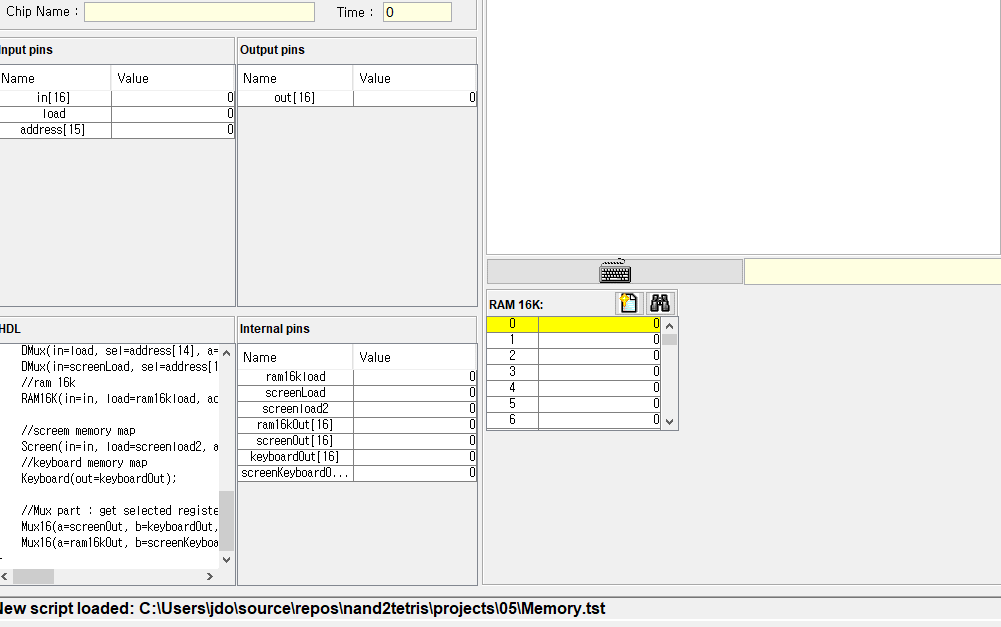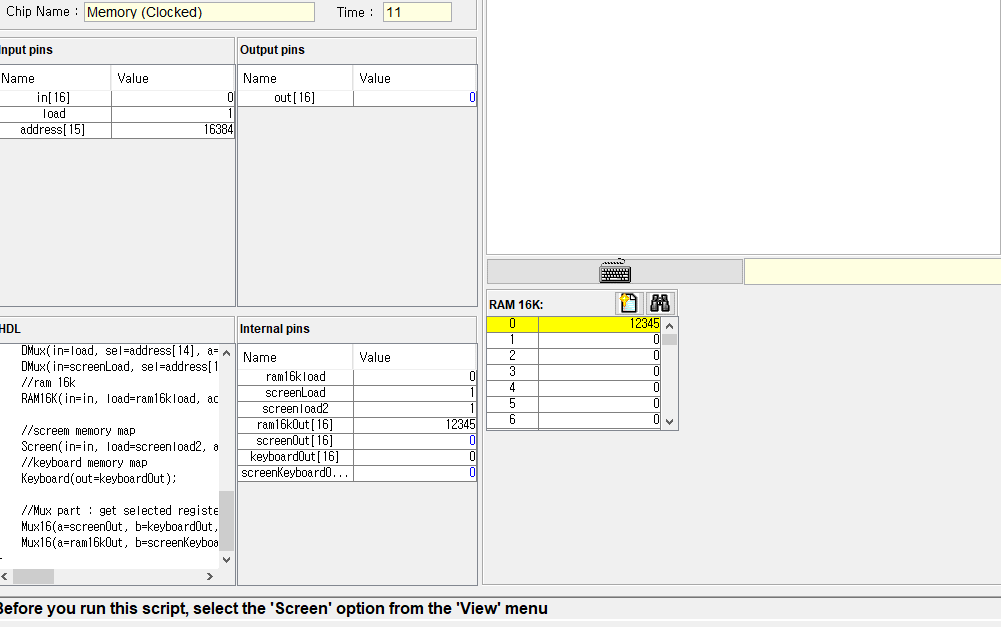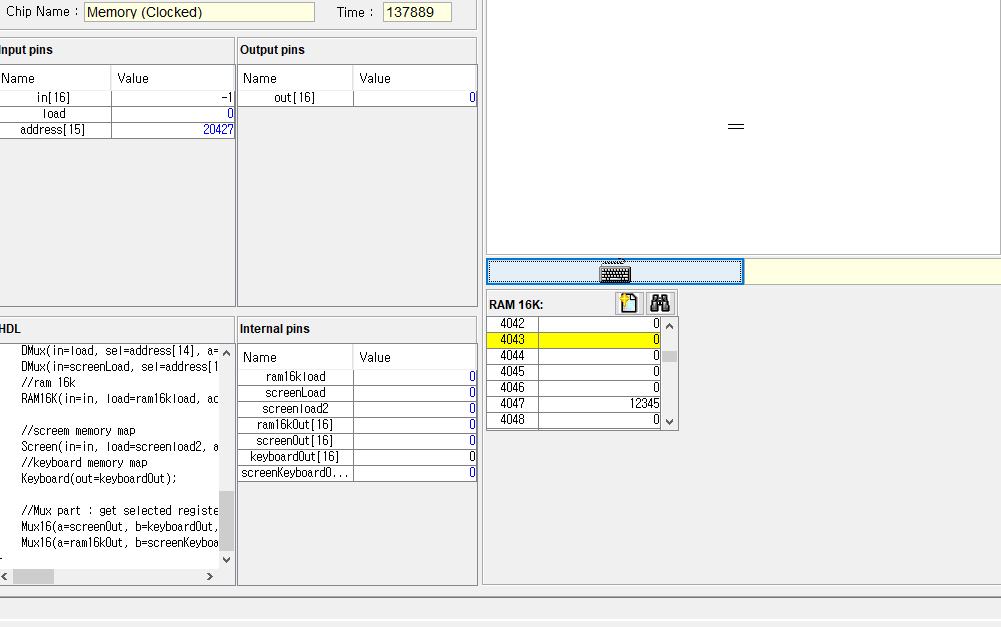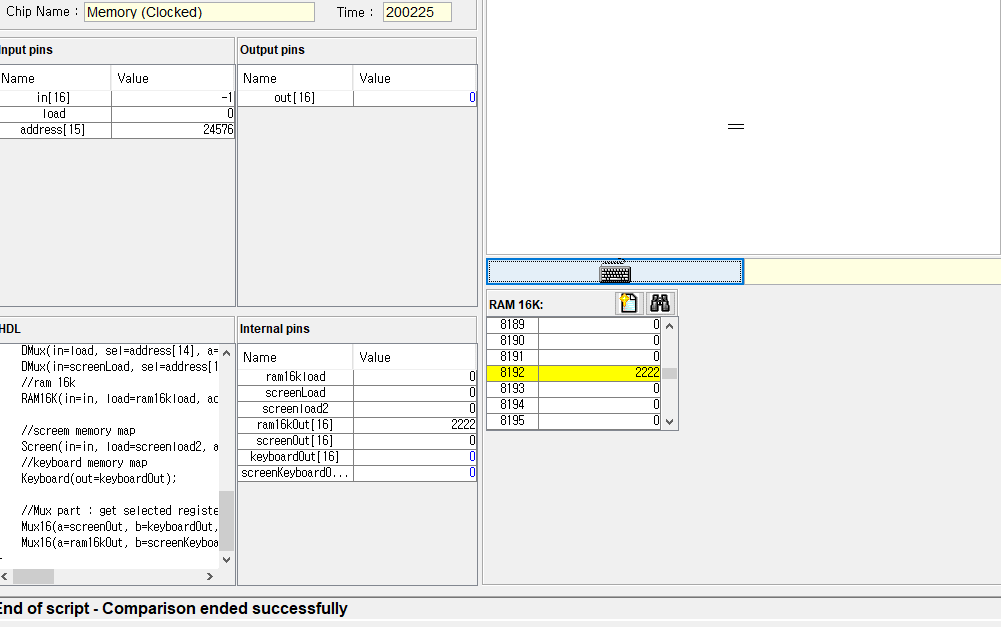
롬이야 읽기 전용 기억장치이니 쓰기를 위한 load 단자는 필요없고, 지난번에 16K까지 만들었는데 그냥 RAM16K 2개를 디먹스로 연결해주면 될거같다.
근데 5장에서 롬을 만들려고 하니까 ROM.hdl은 없고 남은건 memory(ram)와 computer 뿐이다. rom은 어샘블러로 만든 기계어를 넣어둿다가 꺼내서 실행하니까 별도로 만드는건 아닌거같다.
2. RAM
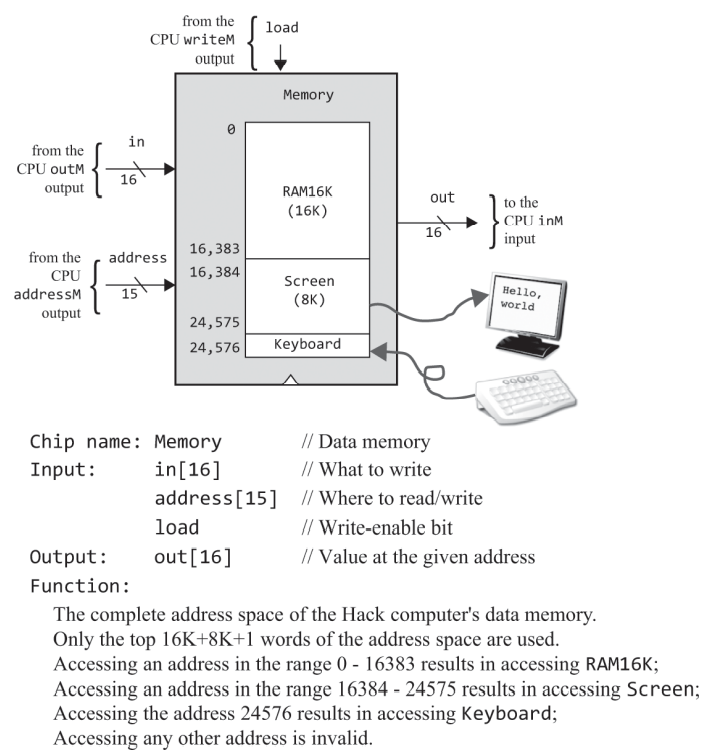
그래서 바로 램을 구현하게 잠깐 살펴보자. 여기선 RAM이랑 다른 입출력장치 매모리맵을 합쳐서 memory라고 하고 있네, RAM은 이전에 본 대로 16K 크기에다가 16K인 이유는 A 명령어가 14개의 비트 크기의 값과 주소를 저장해서 사용하기 때문이며, 그 뒤에는 스크린과 키보드의 공간이 존재한다.
스크린은 16K램뒤에 바로 붙기 때문인지 16,384부터 시작하며, HACK의 스크린은 256 x 512 크기로 2^8 x 2^9 = 2^17 이나 레지스터 한개에 16=2^4개의 픽셀 값이 매핑되어있으므로 메모리 맵 상에서는 2^17/2^4 = 2^13 = 8K의 크기를 갖는다. 키보드야 키보드 베이스 레지스터 한개만 읽으면 되니 주소는 24,576 하나 뿐이다.
HACK 컴퓨터의 메모리에 관한 설명은 여기까지 하고 바로 구현해보자
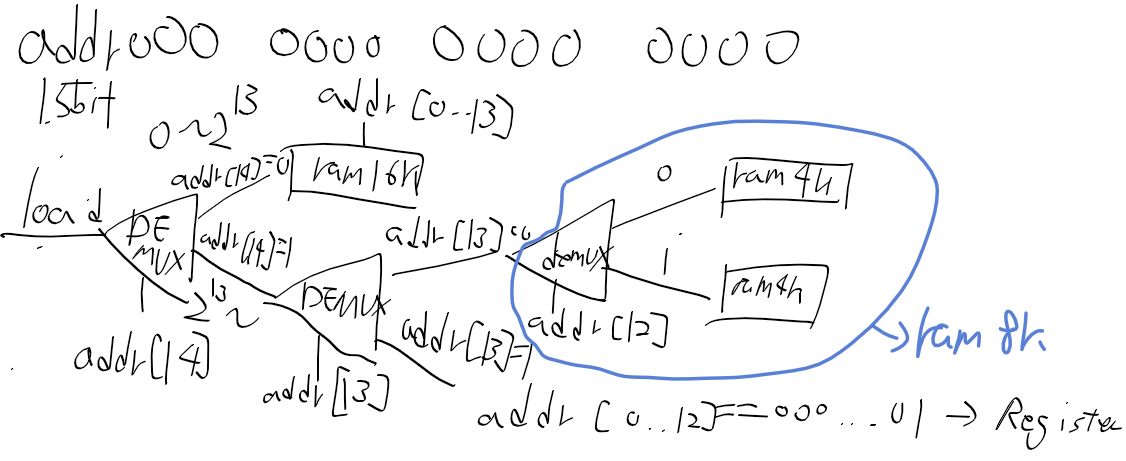
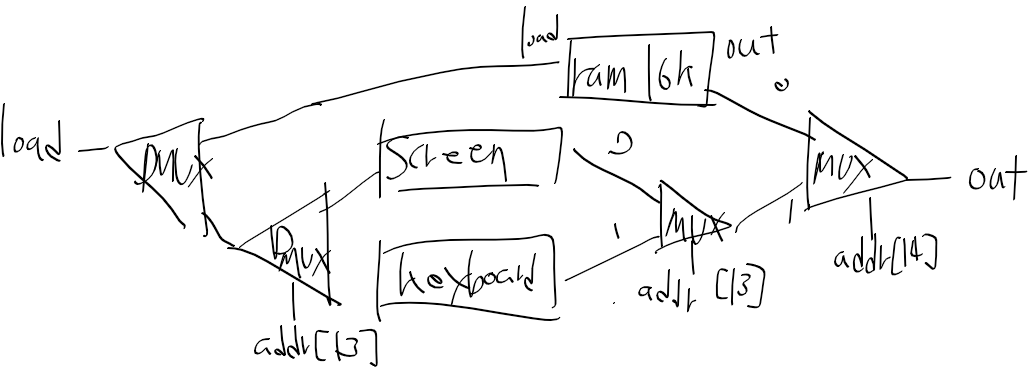
RAM16K(렘), RAM8K(스크린 매모리맵), register(키보드 메모리맵) 각각 한개씩에다가 어째저쨰 잘 연결하면 될거같다.
어떻게 할까 생각해봣는데 일단 address[15]를 sel단자에 받는 디먹스를 놓고 생각해봐야할거같다.
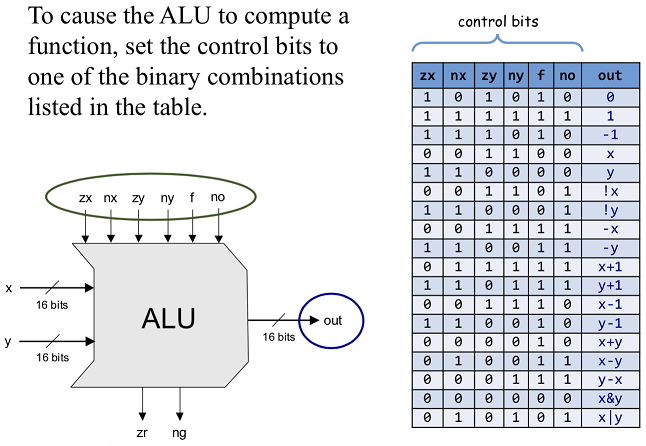
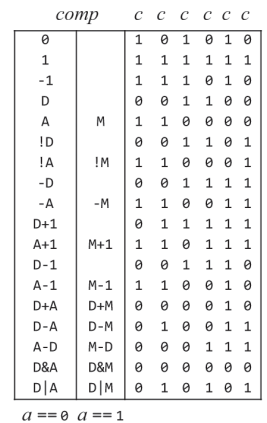
A명령어 때는 ALU는 어떤 출력을 하는지 잠깐 보면 이전 C 명령어의 연산 결과가 그대로 유지되고있다.
하지만 A 명령어의 11 ~ 6비트 자리의 값에 따라서 멋대로 ALU가 연산하고 결과를 내보내면 안되니 별도의 로직이 필요하고
ALU는 기억장치가 아닌데 값을 유지하려면 기존의 ALU 출력을 다시 피드백해서 내보내고 있어야한다.
ALU 출력 결과를 그대로 가져온다면
1. D Registor의 값을 받아서 ALU가 그대로 내보내거나
2. 좌측 먹스에서 ALU OUT이 선택되고, A레지스터에 선택된후 우측 먹스를 통해 넘어온게 다시 출력으로 간다고 봐야할거같다.
아무튼 결국 A 명령어인 경우 a 혹은 b 입력을 그대로 전달해주기만 하면될거같은데.
a 단자를 전달한다면 001100, b단자의 값을 내보낸다면 110000을 제어 비트 단자에 넣어주면 되겠지만
어쩔때 a 혹은 b 입력을 전달할지 판단 기준이 필요하다.
....
와 CPU 구현하는데만 순수하게 6-7시간 쯤 걸린거 같다.
어제 저녁부터 새벽 내내 하고, 오늘도 수업 시간 중에 틈틈이 계속하고 지금이 8시 좀 넘었는데 지금까지 했으니
원래는 글 적어가면서 전체 틀잡고, 에러 고쳐가려고했는데 수정해야될게 너무 많더라
책에서는 어떻게 회로들을 연결하면 CPU가 만들어지는지 친절하게 설명해줘서
CPU야 금방 만들겟꺼니 했는데
단순 연결을 떠나서 각 회로의 제어 비트를 어떻게 값을 넣일지 조정하는게 너무 어렵더라
A, D 레지스터의 로드 비트,
좌 우측 먹스에 어쩔때 a를 넘길지 b를 시킬지
가장 힘들었던건
프로그램 카운터 점프 시점을 조절하는게 너무 힘들었다.
8가지의 점프 조건과 D 값이 일치하는 경우에만 load 자리에 1을 대입시켜 전달 받은 A 레지스터의 값을 저장시키도록
로직 구현하는데 CPU 구현하는 시간의 2/3정도 낭비했다.
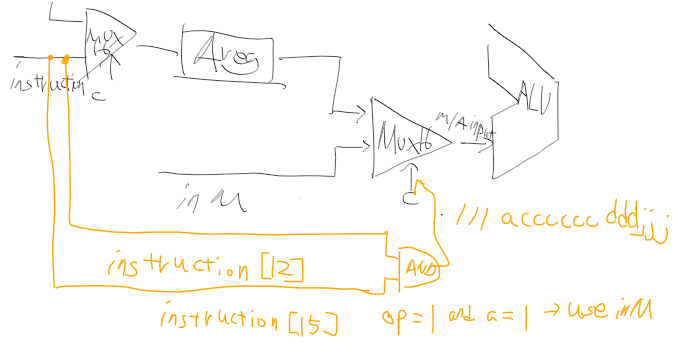
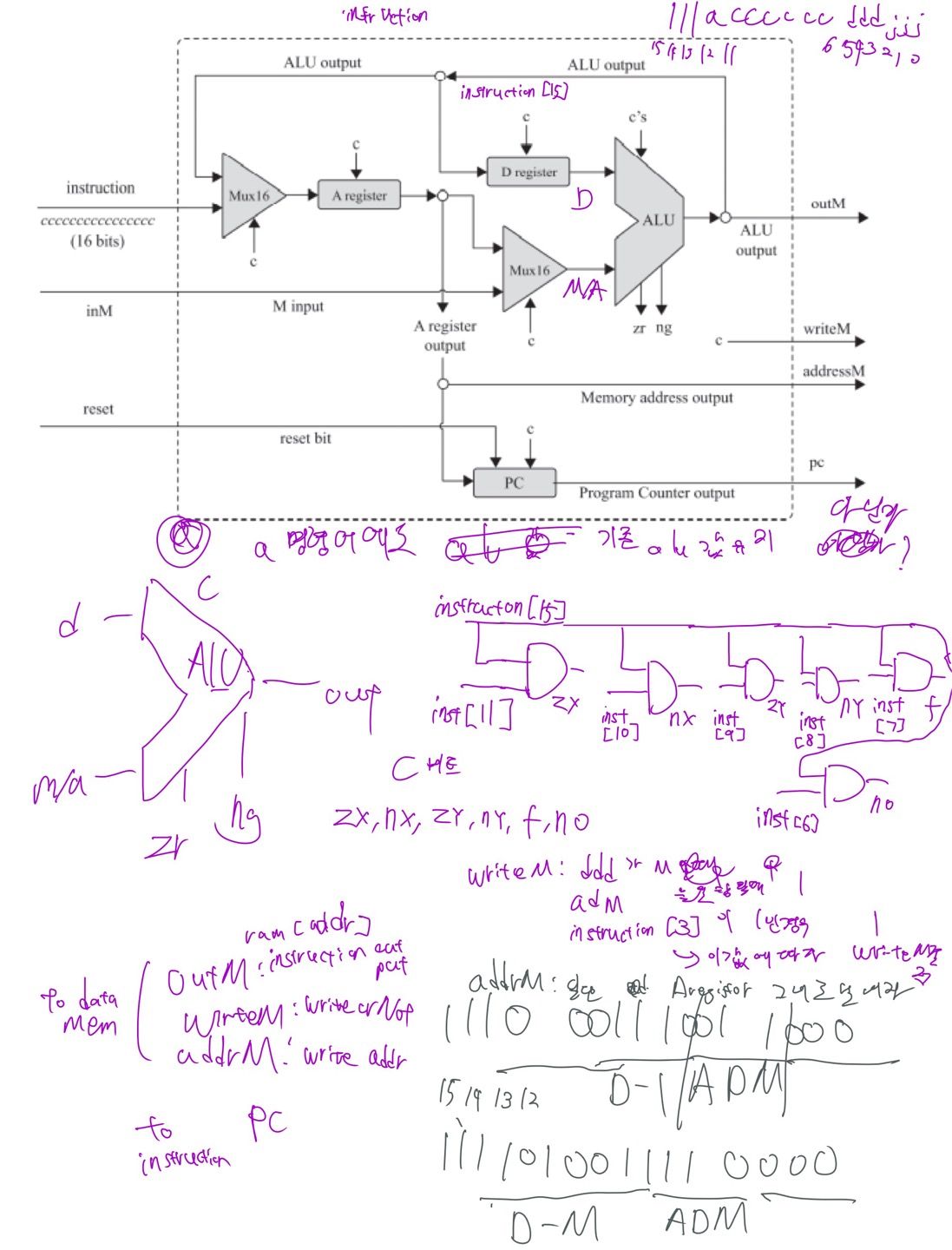
이건 어떻게 배치해야할까 생각하면서 정리한 내용인데 중간에 instruction[15]와 and 게이트 여러개 있는건 명령어로부터 ALU 제어 비트를 뽑아내기 위한 로직이고, 아래에는 writeM, addressM, 목적지 고민하면서 끄적데던 흔적이다.
나는 처음에는 점프를 C 명령어 j 비트에 값이 존재한 경우에 무조건 PC의 load 비트에 1을 대입하여 점프하도록 시켰었는데, 그랬더니 jjj의 조건에 맞지 않는 연산 결과가 나와도 점프 해버리는 문제가 발생했었다.
그 문제때문에 어떻게 하면 jjj 비트에 따라서 올바른 조건을 찾아 그 조건이 성립하는지에 따라 load 비트로 값을 전달하는 로직을 고민하면서 mux를 이용했다. jjj로 먹스의 셀렉트할 단자를 선택하고 각 입력에서는 jjj 비트별 연산 출력을 받도록 하는데, JEQ, JGT, JNE 등 각 연산을 해서 조건에 맞으면 1, 안되면 0을 출력하는걸 sel 비트로 선택해서 load로 전달하는게 되겠다.
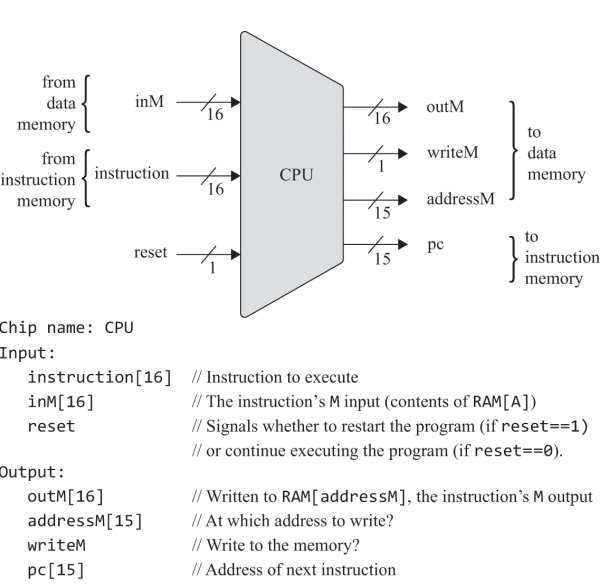
CHIP CPU {
IN inM[16], // M value input (M = contents of RAM[A])
instruction[16], // Instruction for execution
reset; // Signals whether to re-start the current
// program (reset==1) or continue executing
// the current program (reset==0).
OUT outM[16], // M value output
writeM, // Write to M?
addressM[15], // Address in data memory (of M)
pc[15]; // address of next instruction
PARTS:
//PC PARTS
Or(a=instruction[0], b=instruction[1], out=jmp12or);
Or(a=jmp12or, b=instruction[2], out=jmp123or);
And(a=instruction[15], b=jmp123or, out=isJump); //c instruction and jmp
// jump condition implementation * comp = outMLoop
Mux(a=true, b=false, sel=true, out=noJump); // jump con 1. 000 no jump
Not(in=ng, out=isNotNegative); // jump con 2. 001 JGT comp > 0 jump = not zero & not negative
And(a=isNotNegative, b=isNotZero, out=isPositive);
Mux16(a=false, b=true, sel=isPositive, out=isJGT16); // end JGT
Mux16(a=false, b=true, sel=zr, out=isJEQ16); // jump con 3. 010 JEQ
Or16(a=isJGT16, b=isJEQ16, out=isJGE16); // jump con 4. 011 JGE, comp >= zero, jump
Mux16(a=false, b=true, sel=ng, out=isJLT16); // jump con 5. 100 JLT
Not(in=zr, out=isNotZero); // jump con 6. 101 JNE, comp != zero, jump
Mux16(a=false, b=true, sel=isNotZero, out=isJNE16); // end JNE
Or16(a=isJLT16, b=isJEQ16, out=isJLE16); // jump con 7. 110 JLE
Mux16(a=false, b=true, sel=true, out=jump16); // jump con 8. 111 JMP, always jump
Mux8Way16(a=false, b=isJGT16, c=isJEQ16, d=isJGE16,
e=isJLT16, f=isJNE16, g=isJLE16, h=jump16,
sel[2]=instruction[2], sel[1]=instruction[1],
sel[0]=instruction[0], out[0..7]=isJump0to7, out[8..15]=isJump8to15);
Or8Way(in=isJump0to7, out=jumpRes1);
Or8Way(in=isJump8to15, out=jumpRes2);
Or(a=jumpRes1, b=jumpRes2, out=isJumpCondition);
And(a=isJump, b= isJumpCondition, out=isPCLoad);
Not(in=reset, out=isNotReset);
PC(in=aRegistorOut, load=isPCLoad, inc=isNotReset, reset=reset, out[0..14]=pc);
//A registor PARRTS
Not(in=instruction[15], out=opcodeOut); // A instruction == store to A registor
And(a=instruction[15], b=instruction[5], out=loadA); //if instruction is C and dest is a, store outM to A registor
Or(a=opcodeOut, b=loadA, out=aRegistorLoad);
//if opcode is 0 (== A instruction) -> opcodeOut = 1 -> load = 1
ARegister(in=leftMuxOut, load=aRegistorLoad, out=aRegistorOut, out[0..14]=addressM);
//D registor PARTS
And(a=instruction[15], b=instruction[4], out=loadD); //if instruction is C and dest is d, store outM to A registor
DRegister(in=outMLoop, load=loadD, out=dRegistorOut);
//right Mux16
And(a=instruction[15], b=instruction[12], out=mIsUsed);
Mux16(a=aRegistorOut, b=inM, sel=mIsUsed, out=inputMA);
//left Mux16
And(a=instruction[5], b=instruction[15], out=isOutMLoop);
Mux16(a=instruction, b=outMLoop, sel=isOutMLoop, out=leftMuxOut);
//ALU parts
And(a=instruction[15], b=instruction[11], out=zx);
And(a=instruction[15], b=instruction[10], out=nx);
And(a=instruction[15], b=instruction[9], out=zy);
And(a=instruction[15], b=instruction[8], out=ny);
And(a=instruction[15], b=instruction[7], out=f);
And(a=instruction[15], b=instruction[6], out=no);
ALU(x=dRegistorOut, y=inputMA, zx=zx, nx=nx, zy=zy, ny=ny, f=f, no=no, out=outMLoop, out=outM, zr=zr, ng=ng);
//writeM
And(a=instruction[15], b=instruction[3], out=writeM);
}
이 코드가 HDL을 이용해서 우리가 앞서 구현한 칩들을 잘 조합해서 만든 CPU이고,
테스트 코드도 잘 동작한다.
다른 사람이 만들어둔거 참고해서 할수도 있었는데
조금만 더하면 해결되겠지 싶어서 계속하던게 너무 오래걸렸다.
그래도 결국에는 난드 게이트로 CPU를 만들었다!
잠깐 되돌아볼까?
난드 게이트로 and, or, mux, demux 등을 만든 후 이걸 조합해서 alu를 만들었고
데이터 플립플롭을 앞의 조합논리회로랑 결합하여 레지스터, 메모리, 프로그램 카운터를 구현했다.
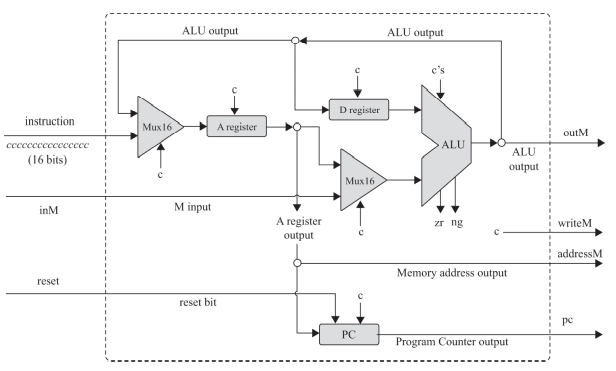
CPU는 ALU와 세 레지스터 - 어드레스 레지스터, 데이터 레지스터, 프로그램 카운터로 만들면 된다. 각각이 뭐하는건지는 직접 만들기도 하고 수차례 시뮬레이션도 돌렸으니 넘어가고 고맙게도 아래의 그림처럼 연결하면 된다고 알려준다. 동작 과정은 다음과 같다.
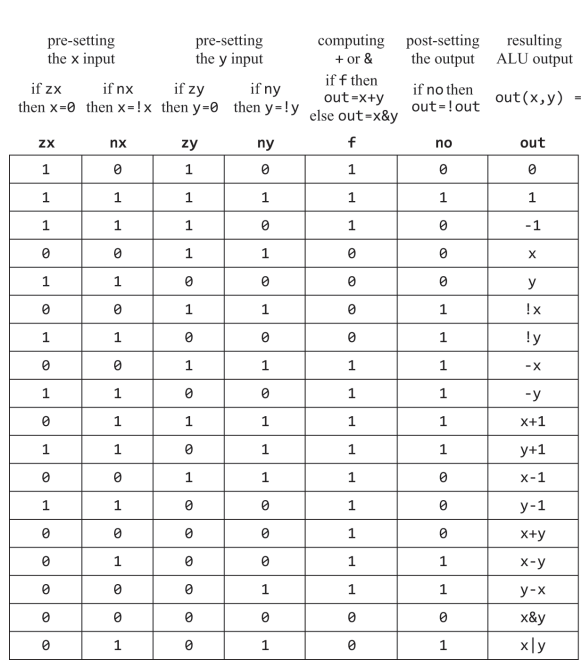
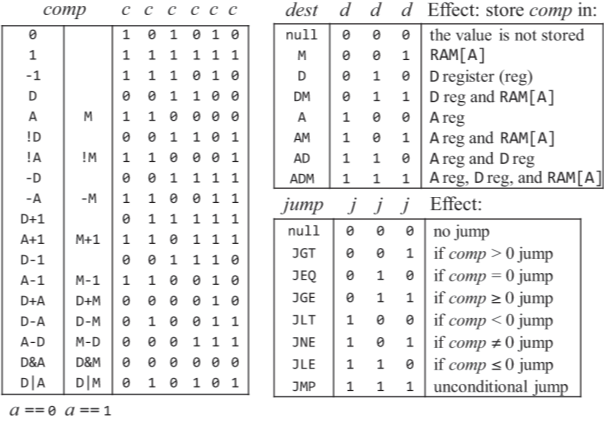
1) 명령어 해독 : CPU 입력 - 명령어 instruction은 A 명령어(MSB가 0, op-code라고도 했던거같은데), C 명령어(MSB가 1일때) 올수 있고, C 명령인 경우 111accccccccdddjjj 6개의 제어 비트 ccccccc와 a로 선택된 연산을 수행하고, ddd로 지정한 곳에 연산 결과를 저장한다. jjj가 000이 아닌 경우 연산 결과에 따라서 jjj의 조건(0과같거나, 크거나, 작거나 등)에 따라 어드레스 레지스터에 입력된 명령어 주소로 점프한다.
2) 명령어 실행 : 들어온 명령어가 A 명령어인 경우 A 레지스터에 담는다. C 명령어의 경우 해독된 명령어의 연산을 수행한다.
3) 명령어 가져오기 : 명령어가 실행되면 프로그램 카운터는 다음에 실행할 명령어의 주소를 준비하고, 현재 명령어가 끝나면 PC에 지정된 주소의 명령어가 실행된다. 하지만 앞서 보았듯이 "@LOOP\n 0;JMP" 처럼 라벨 심볼로 점프할때는 어드레스 레지스터 A에 담겨진 라벨 심볼 (LOOP)의 주소로 점프하여 명령어를 수행하게 되고, PC도 이를 따라가 다음 실행할 주소를 담아서 수행한다.
이제 CPU 구현에 필요한 내용은 대강 정리했는데
어디부터 시작하는게 좋을지가 고민이다.
프로그램 카운터나 각 먹스, 레지스터에는 제어 비트를 어떻게 넣어야 하는건지
위 그림을 보고 사용해야할 회로들의 인터페이스를 정리해보자
CPU = ALU + D/A registor + PC +(Mux 16 2개)
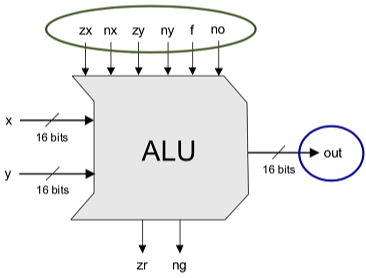
1. ALU
- 입력 : 16비트 x(D), y(M/A), 제어 비트 6개
- 출력 : 상태 출력 비트 2개 zr ng, alu 연산 출력 16비트 outM
2. PC
- 입력 : 16비트 입력(다음 실행 주소 A-점프시), 제어 비트 3개(reset, load, inc-이 순서대로 조건에따라 수행)
- 출력 : 제어 비트에 따라 리셋시 0, 로드시 점프할 주소, 증산시 다음 명령어, 이도저도 아닐땐 상태 유지
3. Regsitor
- 입력 : 16비트 입력 in, 로드 제어비트 load
- 출력 : 현재 값 out, 입력 로드시 out[t+1] = in[t]가 된다.
4. MUX 16
- 입력 ; 16비트 a, b
- 출력 : sel이 0인경우 a, sel == 1일때 b
CPU
- 입력 : inM(데이터 메모리에서 읽어온 값), instruction(현재 실행할 명령어)
- 출력
outM : RAM[addressM]에 쓰여진 결과
addressM : 값이 쓰여질 주소, A 레지스터의 출력
writeM : 메모리에 쓸지 읽을지 여부
pc : 다음 명령의 주소
1.1 PC 구현하기
1. reset 입력 : PC의 제어비트 같은 경우에는 reset을 바로 연결시켜주면 될거같기는 한데 ..
2: inc 입력 : inc는 reset이 0이 아니면 1이니까 Not(in=reset, out=resetNotOut) 해서 넣어주면 될거같다.
3. load 입력 : load 의 경우에는 명령어의 j 비트가 000인 경우에만 점프하는게 아니니까3bit or한 결과가 0이면 load는 0, 1이면 1로해야겠다. 일단 instruction의 LSB 3비트만 받아서 or 연산 후 jmp123or을 출력하여 load 자리에 넣는다고 생각하고 이 이름을 입력받도록 하자.
4. in 입력 : A 레지스터의 출력을 써야하니 일단 A 레지스터를 어떻게 할지 생각하지는 않았지만 aRegistorOut이란 이름으로 해놓자.
가장 먼저 PC를 만들면서 A의 입력을 받도록 했었으니까 이번에는 A 레지스터를 한번 보자
A Registor는 일단 좌측의 Mux16의 결과를 받아 우측의 Mux16과 PC로 보내고 있으며, 제어비트 c가 0인지 1인지에 따라 값을 읽기만 하거나 저장을 한다.
1. in 입력 : in의 경우 좌측 먹스의 출력을 받으니 일단 leftMuxOut 정도로 해놓자
2. 출력 : A 레지스터의 출력은 우측 먹스의 입력으로, PC의 입력으로도 사용하는데 일단 aRegistorOut 정도로 해놓자.
3. c 입력 : A 레지스터에 값을 쓸지 말지 여부는 명령어가 A 명령어인지 C 명령어인지에 따라 결정되었었다. 라벨 심볼이든, 변수든, 상수가 오던간에 A 명령어 이므로 instruction의 MSB를 보고 0이면 c에는 1, MSB가 1이면 c에는 0을 놓도록 Not 게이트(출력명은 opcodeOut)를 추가하여 연결해보자.
A 레지스터에는 A 명령어가 들어올때 외에도 C 명령어일 때, 첫번째 d비트의 값이 1인 경우 instruction[5]==1, 연산 결과를 A 레지스터에 담는다. 명령어가 C 명령어고 첫번째 d비트가 1인지 여부 ((instruction[15] && instruction[5]) 한 결과를 loadA라 하면, opcodeOut과 loadA 둘중 하나가 1이면 1이되도록 or 연산을 한 후 aRegistorLoad 라는 이름으로 전달해주자.
//A registor PARRTS
Not(in=instruction[15], out=opcodeOut); // A instruction == store to A registor
And(a=instruction[15], b=instruction[5], out=loadA); //if instruction is C, store outM to A registor
Or(a=opcodeOut, b=loadA, out=aRegistorLoad);
//if opcode is 0 (== A instruction) -> opcodeOut = 1 -> load = 1
Register(in=leftMuxOut, load=aRegistorLoad, out=aRegistorOut);
1.3 D registor
이번에는 D registor를 구현해보자. D 레지스터는 A명령어로 입력하지는 못하고, C 명령어의 ddd 값에 따라서 대입하도록 되어있었다. 그러면 D 레지스터에 입력하는 경우는 어떤 경우가 있었나?
위 표를 보면 2번째 d비트가 1일때만 D 레지스터에 입력하도록 되어있었다. 그러니까 A D M 순서니까 instruction[5], instruction[4], instruction[3] 순이 되겠다. 근데 지금보니까 d의 첫번째 비트가 1인 경우에도 A 레지스터에 값을 저장하도록 하고 있다. 그러니까 A 명령어인 경우 외에도 instruction[5] == 1일때도 A 레지스터의 load = 1이 되도록 해줘야 하는거같다. 일단 처음에 쓴 부분 뒤에다가 추가로 표기해놔야겠다.
1. in 입력 : D Registor는 ALU의 연산 결과를 담을수 있으므로 outM을 연결해주면 될거같은데, outM은 외부로 나가므로 루프할수 없으니 outMLoop 라는 루프 출력을 만들어서 in에다가 넣자.
2. c 입력 : 앞서 설명한것 처럼 명령어가 C 명령어이고 5번째 비트가 1일때 c에 넣도록 구현하자.
3. 출력 : A 레지스터때 처럼 dRegistorOut 정도로만 하자.
//D registor PARTS
And(a=instruction[15], b=instruction[4], out=loadD); //if instruction is C and dest is d, store outM to A registor
Register(in=outMLoop, load=loadD, out=dRegistorOut);
이제 PC, A, D, 레지스터는 전부 구현했고, ALU 하기전에 먹스부터 정리해보자.
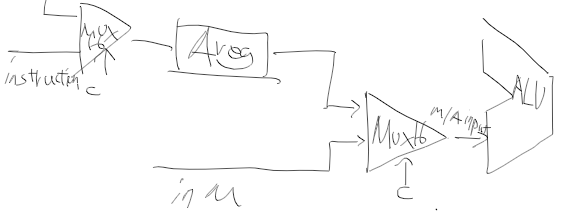
1.4 좌측 MUX16(한참 삽질하여 뒤에 다시 정리함)
일단 좌측 먹스부터 생해보자. 왼쪽 먹스의 경우에는 a 자리에 ALU의 출력 outM, 이건 루프가 안되니 D 레지스터의 입력으로한 outMLoop를 사용하고, b 자리에는 instruction을 그대로 넣어주면 될거같다. MUX16은 sel이 0일때 a, 1 일때 b를 내보냈었는데 평소에는 A 레지스터에 A 명령어를 넣고, 아니다 C instruction[5]가 1일때만 outM을 A 레지스터에 넣었으니 이걸 sel 기준으로 잡으면 될거같다.
먹스는 sel이 0일때 a를 출력으로 하지만, C instruction[5] == 1일때 A레지스터에 저장해야하니 Not(C instruction[5]) 한것을 sel에 넣어야 alu의 출력이 A 레지스터로 넣어지고, C instruction[5]가 0이라면 not 연산으로 sel에 들어가는 값이 1이되고 instruction이 A 레지스터로 전달 되겠다.
잠깐 A 레지스터는 값과 주소를 저장한다 했는데, 값은 지금까지 한걸보면 A 명령어와 C 명령어의 목적지에 따라 ALU의 결과를 값으로 넣어주도록 했다. 하지만 C 명령어인데 instruction[5]가 아닌 경우는 A registor에 넣어도 되는건지 햇갈리기 시작했다.
지난번에 ALU, PC 구현할때는 완벽하게 동작을 이해하지 않더라도 표만 보고, 동작 조건만 따라서 연결만 해줬어도 어떤 흐름인지 따라가지는 못하지만 원하는 동작을 하기는 했었다. 지금도 A 레지스터에 먹스 a를 넣는 조건을 찾았으니 전처럼 해야할까? 그냥 그랬다가는 나중에 놓친 부분이 있으면 엄청 해맬거같은데 고민된다.
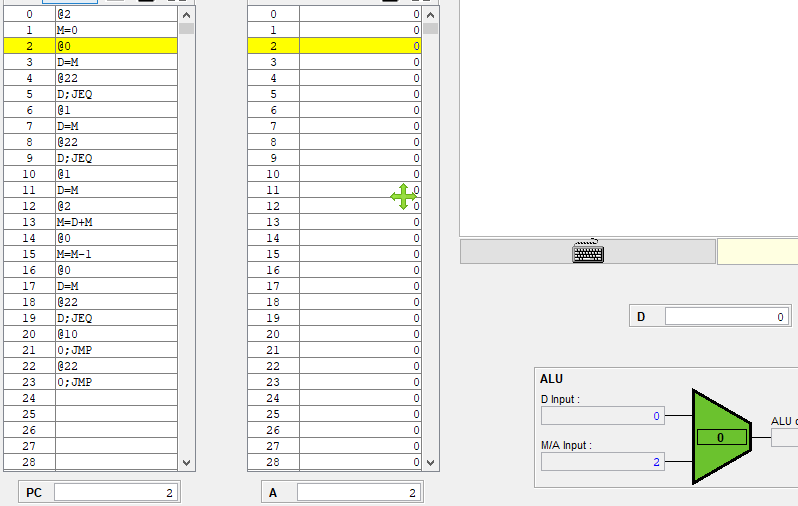
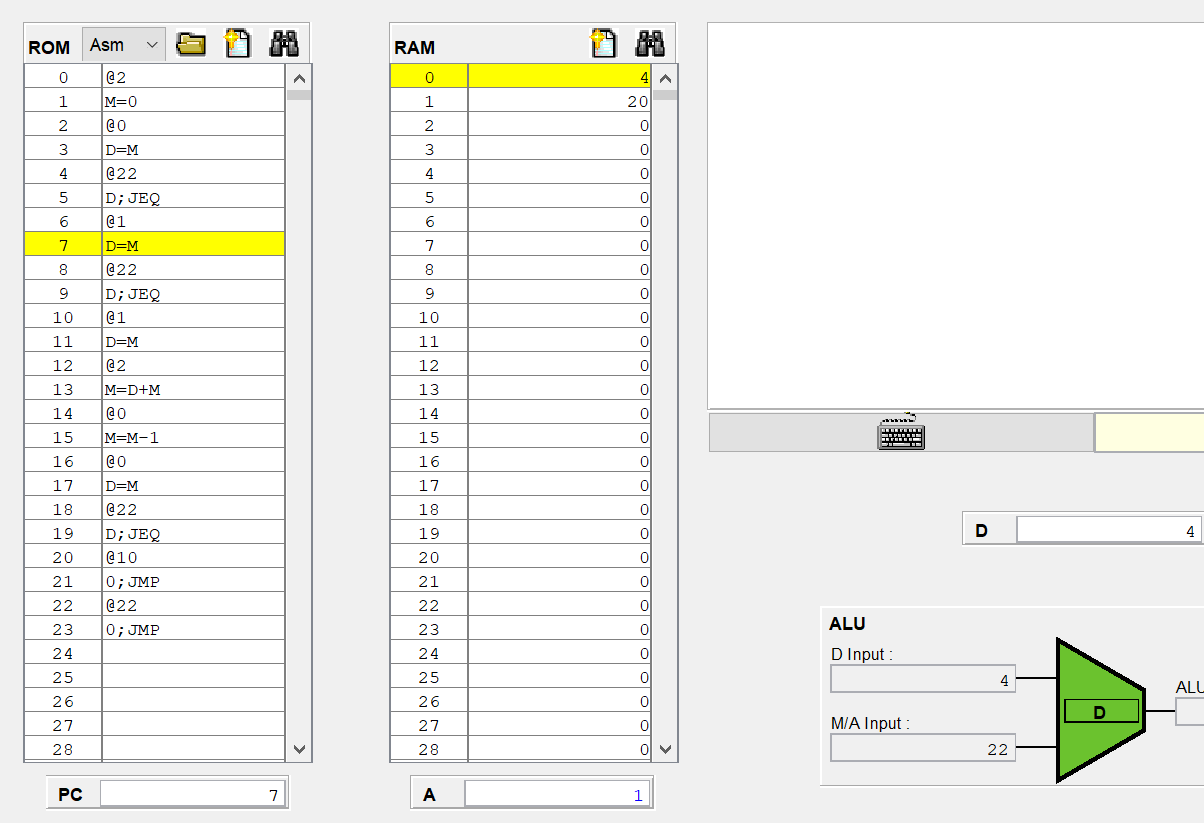
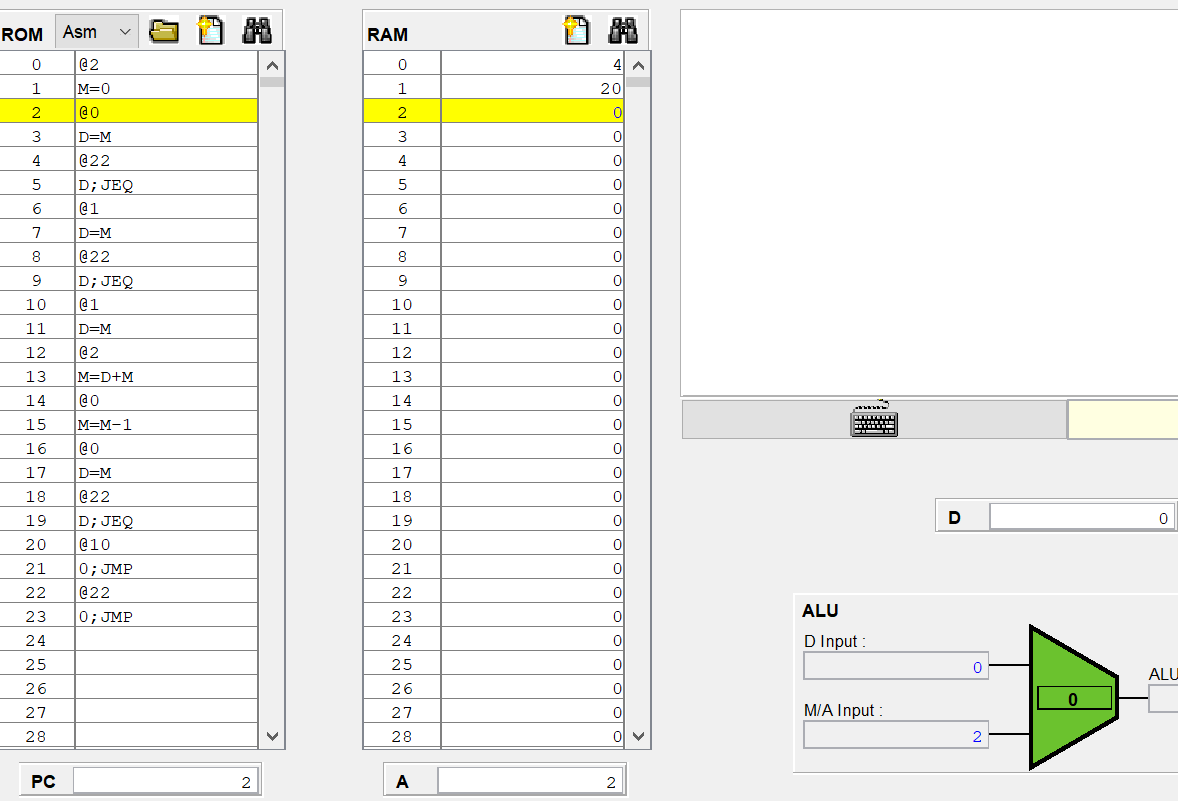
C 명령어가 (A=)가 아닐때 잠깐 곱셈 어셈블리어로 CPU 에뮬레이터를 보니
@1 //이때 A에는 1이 들어가고, 현재 1번지의 값은 20이다.
D=M //그러면 M에는 20이 들어갈 것이고, A 레지스터는 명령어를 저장하는게 아니라 기존의 1을 유지해야한다.
D=M 연산한 결과 A 레지스터는 1로 그대로 유지되고 있고,
D의 값이 RAM[1]의 값으로 덮어씌워졌다.
아 지금 보니까 생각난게 이래서 A 레지스터의 load를 조절해줘야 되구나.
아까 수정한 A 레지스터에는 C 명령어이고, instruction[5]가 1인 경우에만 load=1이 되도록 했으니
어셈블리어에서 A=이 아닐때는 load에 0이들어가 기존 값을 유지하는게 된다.
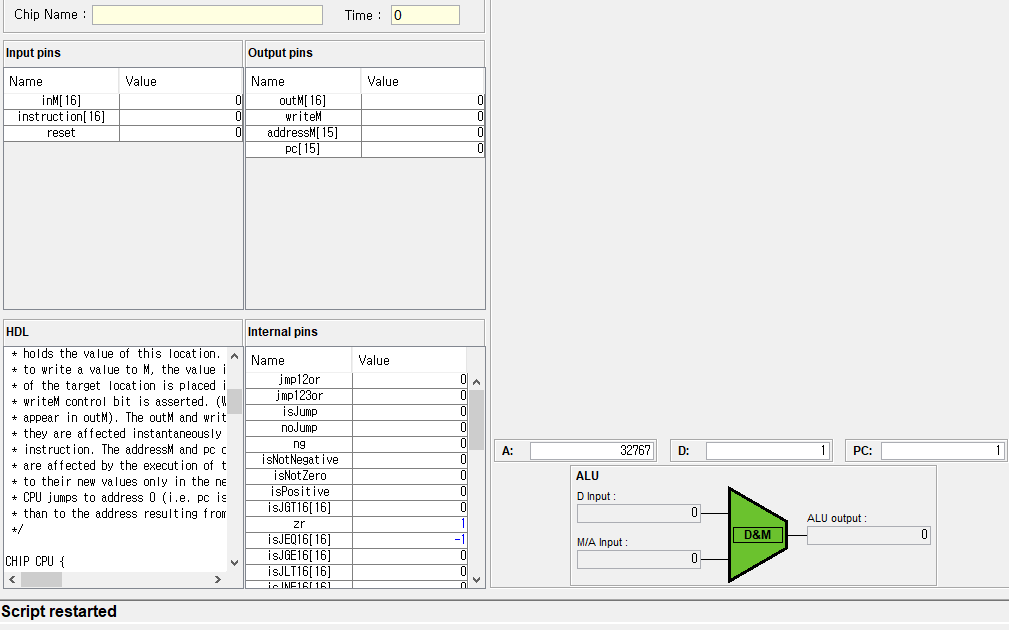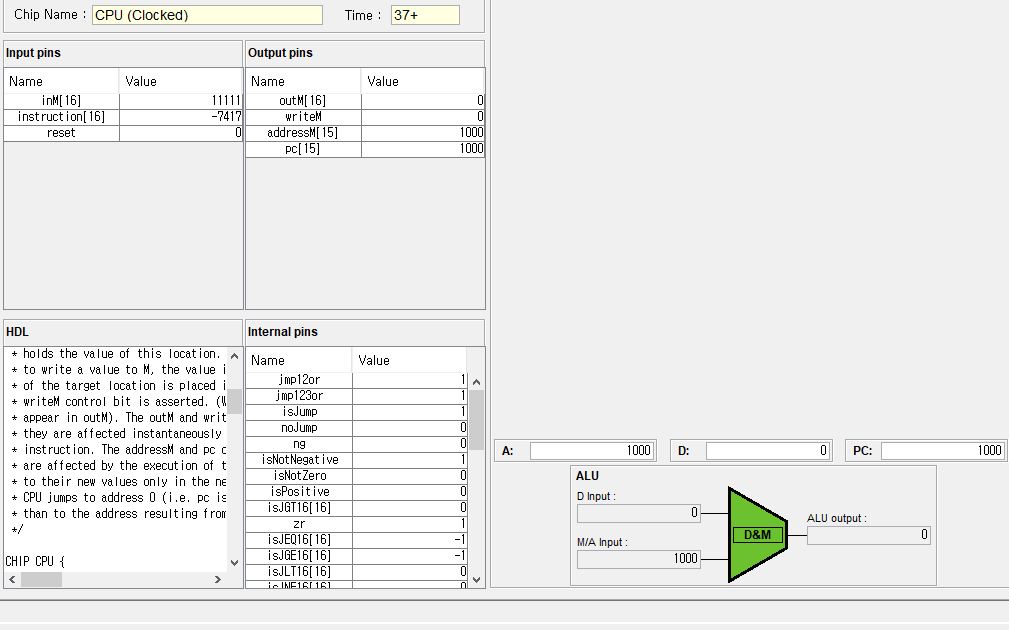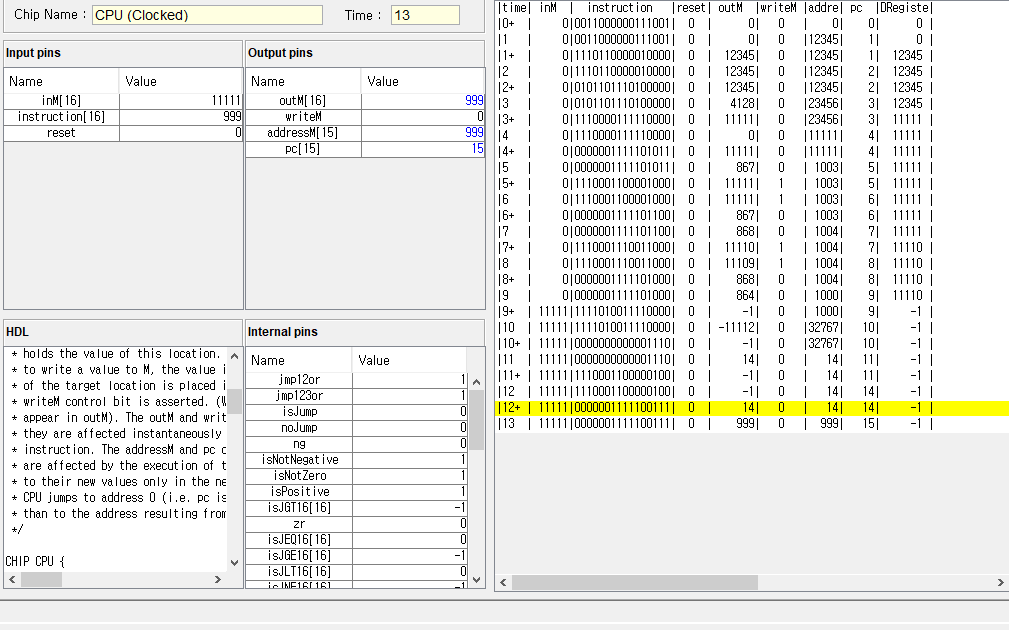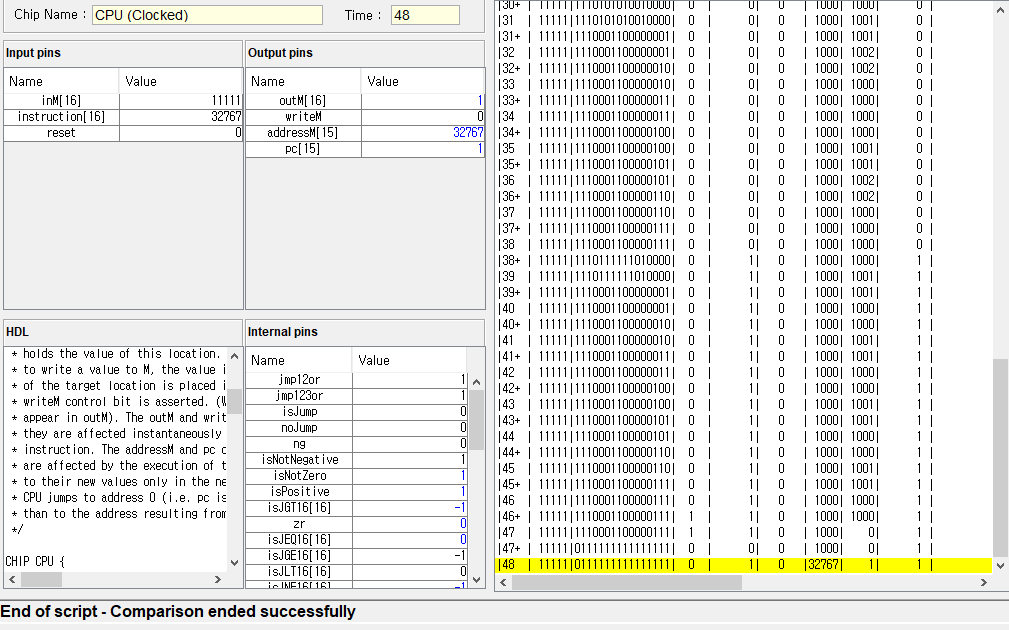
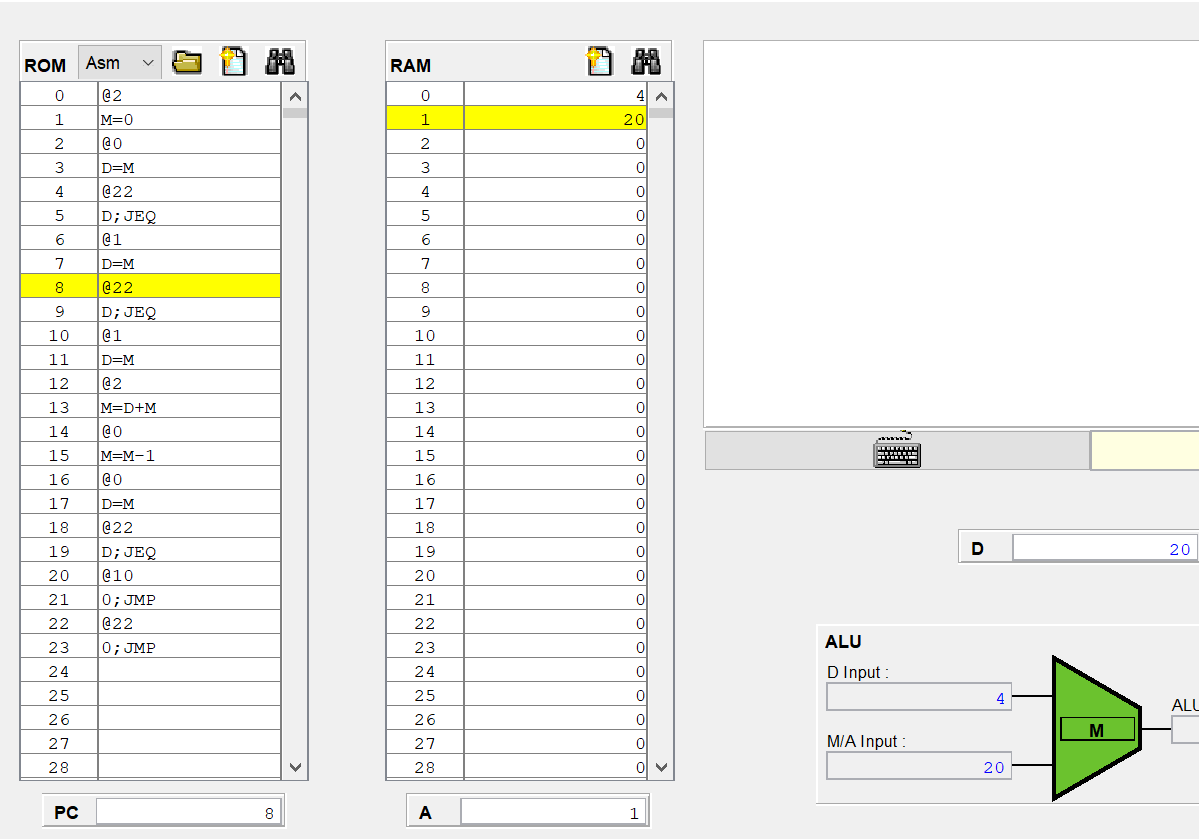
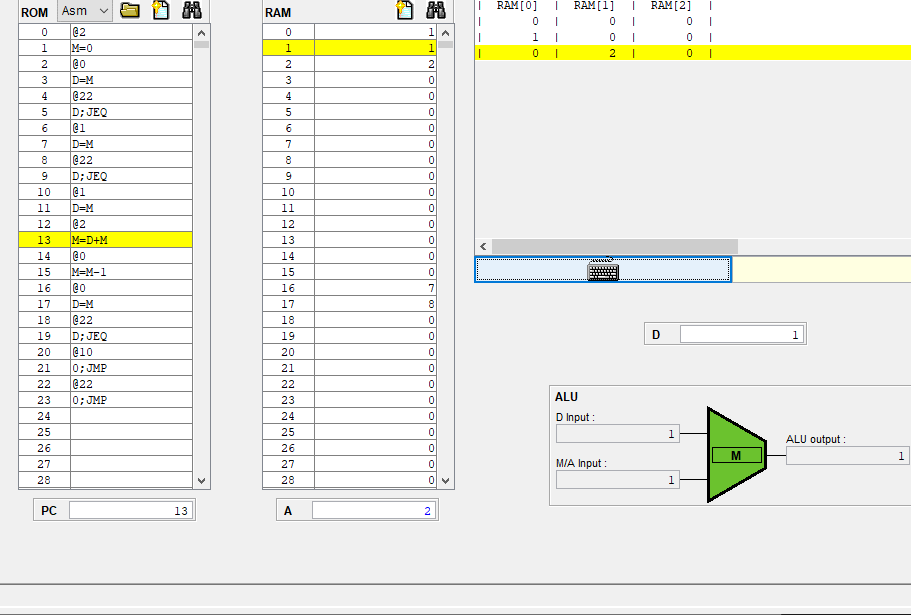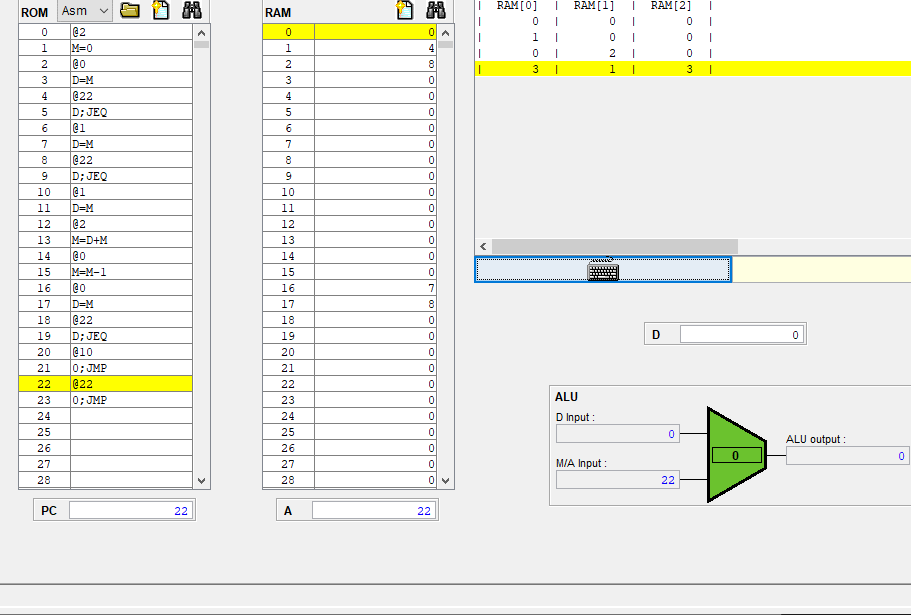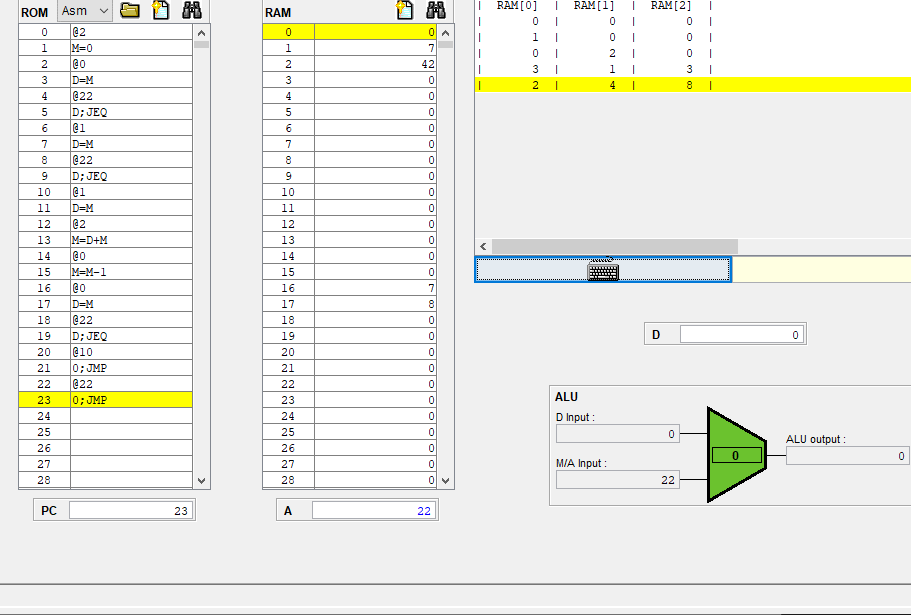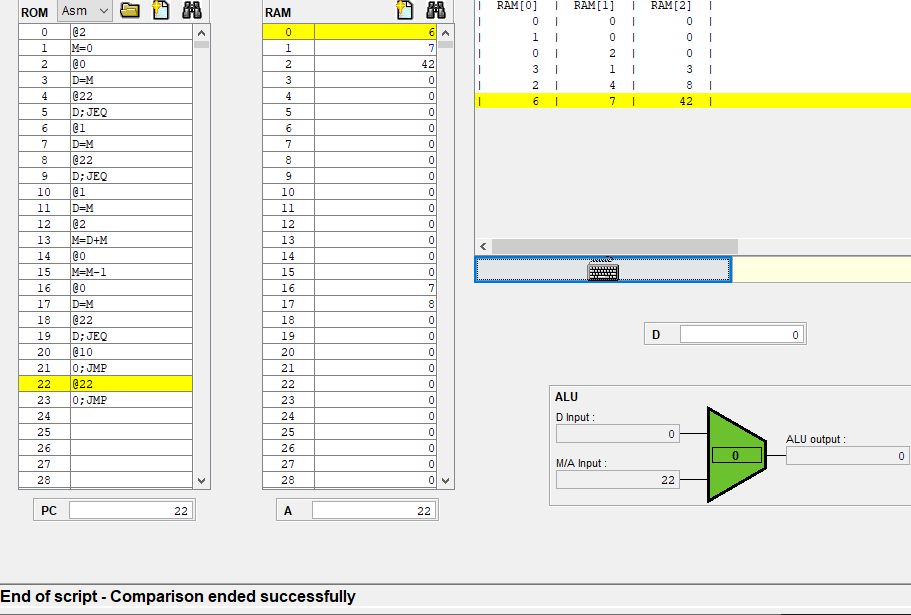
그리고 위에 사진에는 @22에 노란줄이 되어있는데 이 명령어는 A 명령어이고, A 레지스터는 순차 논리 회로이므로 다음 클럭때 A는 22로 반영이 될거같다.
실제로 A 레지스터의 값이 22로 변했다.
그런데 아직 ALU아 하단 입력 M/A가 20 그대로 유지되고 있다.
현재 22이니까 22이여야 하는데 안바뀐건 시간이 안지나서 그런걸까?
아니면 우측 먹스에서 inM이 들어와 아직까지는 아래에 20이 들어가는거같다.
8번 명령어는 값을 저장하는 A 명령어라 M이 반영이 안된건지
아 다시 처음부터 보니까 이해가 되는게
내가 그동안 노란줄을 현재 실행한 명령어로 오해하고 있었다. 실제로는 프로그램 카운터가 가리키는 주소라
다음에 실행하는 명령어인데도
다시 이 코드를 한번씩 실행하면
PC가 0일때 모두 0이지만, 0번 명령어를 실행하는 즉시 PC는 1, A에는 A 명령어를 통해 2가 저장된다.
registor(load=1) out(t+1) = in(t) 이었으므로 아직 ALU의 M/A 입력이 0이고,
다음 클럭때(PC가 2를 가리킬때) 2를 출력하게 된다.
일단 오케이 아까보다는 PC니 A 레지스터 값 저장이니 더 이해된거같네
아까 햇갈렷던 A 레지스터의 값이 22인데 ALU에 반영안된 이유는
현재 실행한 명령어는 8번 명령어라 A에는 즉시 저장되었지만 출력이 아직 안되었기 때문이고
8번 시점에 M/A 입력이 20인건, 7번 시점에서는 A가 1이지만 우측 먹스에 의해서 inM이 전달되서 그런거같다.
좌측 먹스를 정리하면서 좀 많이 해매버렸는데, A에 A 명령어든 C 명령어 연산 결과를 저장하든 말든간에 우측 먹스에 의해서 alu 아래 단자 값이 정해지니 이게 중요한거같다.
먹스 하나가 내용 정리하는데 어쩌다 보니 다른 회로 합친거보다 길어졌다.
잠깐만 다시 정리하자
outMLoop와 instruction을 A 레지스터로 저장 조건과 전달 조건
A 레지스터 저장 조건
1. 명령어가 A레지스터인 경우 - instruction을 저장한다.
2. 명령어가 C 명령어이고, instruction[5] = 1인 경우 - outMLoop를 저장한다.
A 레지스터 전달 조건
1. 명령어가 A레지스터인 경우 - instruction을 저장한다.
-> 좌측 먹스로 명령어를 전달한다.
2. 명령어가 C 명령어이고, instruction[5] = 1인 경우 - outMLoop를 저장한다.
-> 좌측 먹스로 outMLoop를 전달한다.
3. 그외 경우 : C 명령어이나 instruction[5] = 0인 경우
-> 저장 하지 않아 기존의 저장된 값을 출력하므로 무관하다.
그러므로 ((instruction[5] == 1) && (instruction[15] == 1)) ==1일때만 outMLoop를 A 레지스터로 전달하도록 하고
범용 목적 컴퓨터는 우리가 사용하는 PC나 휴대폰처럼 게임이든, 인터넷이든, 음악이든 하나의 목적이 아닌 다양한 용도로 사용할수 있는 컴퓨터를 말하며,
범용 목적 컴퓨터 외 다른 분류로 특수 목적/단일 목적 컴퓨터가 있다.
단일 목적 컴퓨터의 경우 처음 이 단어를 보는 사람에게는 막연할거같은데 나도 그랬었고,
우리 주위를 보면 신호등, 엘리베이터, 밥솥, 냉장고 등 다양한 기계, 전자장치들이 존재한다.
아직 시퀀스에 대해서 잘 아는건 아니지만 이런 기계 중에서는 엘리베이터나 자동 수양장치, 자기 유지 회로 등 프로세서없이 만들어서 사용할 수 있는 시퀀스 시스템도 있고,
아날로그 시퀀스 만으로는 구현하기는 어려워 프로세서를 이용한 디지털 시스템이 있는데 우리가 사용하는 PC나 휴대폰 외에도 TV나 밥솥, 냉장고도 내부에 프로세서가 들어가 있고 프로그래밍을 하여 사람이 쉽게 사용할수 있고, 원하는 동작을 하도록 되어있다.
이런 냉장고, 식기세척기, 밥솥 등과 같이 아날로그 회로만으로는 구현하기 어려워 사용한 프로세서를 특수 목적/단일 목적 컴퓨터라 하며, 단일 목적 컴퓨터는 PC같은 범용 목적 컴퓨터와는 다르게 밥솥은 밥솥역활만 하도록, 냉장고는 냉장고 역활만 하도록 특정 용도에 한정한 컴퓨터를 의미한다.
범용 목적 컴퓨터와 차이점이라면 다양한 작업을 할 필요가 없으니 계산 성능이나 메모리 공간, 주변 장치등이 범용 목적 컴퓨터에 비해 적이며 저렴하다는 점이다.
정도로 이해하고 있는데, 당장은 이 정도만 이해해도 답답하거나 막히는 일은 없었다.
외장 프로그램 방식과 내장 프로그램 방식
컴퓨터 구조를 공부하다 나오면 자주 보는 폰 노이만 구조니 하버드 구조랑 더불어 내장 프로그램 방식이란 단어를 종종 보곤 했었다. 그런데 처음 컴퓨터를 공부 할때는 당연히 프로그램은 컴퓨터 안에 있으니까 원래 내장된거 아닌가? 왜 내장 프로그램이라는 용어가 나온건지 잘 이해가 되지를 않았었다.
전기랑 디지털 논리 회로를 배우면서 동기 카운터를 만들고, 난드투 태트리스에서 ALU, 램 만들면서 이전보다는 좀 더 와닿았는게, 특히 직접 만든 ALU를 시뮬레이터로 테스트를 할때/기계어 어셈블리어 작성한걸 돌리면서 상태 비트 레지스터/C명령어에 따라 +1 연산하기도 -1 연산하기도하고 D+A M+D 든 연산을 하는걸 봤었다.
지난 장에서는 어셈블리어로 곱셈기 프로그램을 짜서 CPU 에뮬레이터로 돌렸었는데, 그 때는 직접 만든 바이너리 코드를 ROM에다가 저장해서 돌린덕에 PC로 지정한 명령어 실행하고, 그다음 명령어 가져와서 ALU에 넣어 실행하고를 반복했었다.
하지만 이런식으로 프로그램을 기억장치에 넣어서 사용하기 전에는 직접 프로세서가 원하는 동작을 하도록, 원하는 값을 넣을 수 있도록 하드웨어를 조작(선을 뺏다 꽂앗다)하여 만들었으며 이를 하드웨어로 프로그래밍 하는 방식을 외장 프로그램 방식이라 하더라.
잠깐 찾아보니 최초의 전자식 컴퓨터인 애니악이 이런 외장 프로그래밍 방식이라 한다. 디지털 논리회로를 지금 만큼 모르고 애니악이 최초의 컴퓨터니 에드박이니 하는걸 들을때는 그냥 연도 외우는 문젠갑다 싶어 억지로 외웠었는데 애니악과 우리가 현재 쓰는 컴퓨터가 이런 차이가 있다더라.
당장에 FPGA로 앞서 만든 ALU를 구현한다 하더라도 입력 두개나 상태 입력 비트에다가 +1, -1, +M, 0, not 연산을 하도록 전선을 일일이 연결해서 전원을 줬다면 얼마나 어려웠을까?
하드웨어를 이용한 동작 구현과 소프트웨어를 이용한 동작 구현
그리고 내장 프로그래밍 방식의 장점은 간단한 명령어들을 합쳐서 복잡한 명령어를 구현할 수 있다는 점이다. 가장 최근에 본 예시로 곱셈 연산일거같은데, 위의 ALU 제어 테이블이나 HACK의 어셈블리어 명령어 테이블을 봐도 하드웨어적으로는 곱셈 연산을 만든 적이 없고, 덧셈 뺄샘 그리고 논리 현산 몇개 뿐이다.
그런데 어떻게 곱셈 연산을 해냈던가? sum = D+M 연산을 D 횟수 만큼 하도록 루프를 돌면서 곱셈한것과 동일한 결과가 나오도록 어셈블리어를 만들었다. 거기다가 명령어 테이블에도 없던 입출력 제어도 ROM에다가 넣어둔 어셈블리어로 할수 있었다. 명령어 테이블에 없는 동작을 어셈블리어, 그러니까 소프트웨어 적으로 구현했는데 하드웨어로 구현할수 없을까?
곱셈기
잠깐 찾아보면 곱셈이나 나눗셈도 논리 곱셈기, 논리 나눗셈기가 나오는데 직접 하드웨어로 구현할수가 있다. 그런데도 사용하고자 하는 모든 연산을 하드웨어적으로 구현안하는 이유가 ALU로 원하는 모든 연산을 할수 있도록 각 연산들을 하드웨어로 구현해 짚어넣으면 하드웨어로 구현하기 힘든 연산도 있을 것이고, 그 만큼 비용도 비싸지고, 크기도 커진다.
하지만 곱샘 연산 구현때와 같이 ALU에서 제공하는 단순한 연산들로 소프트웨어 적으로 구현하는 것이 하드웨어로 구현하는것 보다 쉽고, 프로세서가 커질 필요도 없으며 소모하는 비용도 늘진 않는다. 지금 당장은 이정도로 이해하고 있고, 이게 RISC와 CISC의 차이인거 같은데 뒤에 또 보자
컴퓨터 구조 : 튜링 머신과 폰 노이만 구조
아 내장 프로그램 생각 정리하다가
외장 프로그램으로 넘어가고, RISC CISC 얘기까지 가버렸는데,
결국에는 이 내장 프로그램 방식이 대표적인 컴퓨터 모델인 튜링 머신이나 폰 노이만 구조같은 컴퓨터 구조의 핵심이 된다.
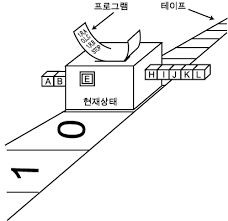
튜링 머신은 컴퓨터 공부하면서 몇번 들어봤지만 자주 까먹던 개념인데, 실제 물리적인 컴퓨터는 아니고 어떻게 프로그램을 읽고 처리할지 판단하는 추상적인 개념의 컴퓨터라 한다(만든 것도 있긴한데).
잠깐 나무 위키를 봤는데 (위 그림과는 조금 다르지만) 튜링머신은 테이프, 헤드, 상태 기록기, 행동표 등으로 구성되어있다고 한다. 지금 하는거와 빗댄다면 테이프는 기억 장치, 메모리 역활, 헤드는 어드레스 레지스터 역할, 상태 기록기는 상태 레지스터 쯤 되는거 같고, 행동표는 행동을 지시한다니까 프로그램 카운터쯤? 비슷한게 아닌가 싶기도 하다.
결국에는 헤드를 통해 테이프의 값을 읽거나 쓸수 있다는 점에서 튜링 머신도 내장 프로그램 방식이라고 하는거같다.
폰노이만 구조는 지난번에 하버드 구조와 같이 정리했던거 같은데, 내장 프로그램 방식인 만큼 메모리가 내장 되어있으며, 하버드 구조(데이터 메모리와 명령어 메모리가 다른 버스를 이용)와는 다르게 데이터 메모리와 명령어 메모리가 같은 버스를 통해서 CPU에서 읽고 썻었던게 특징이었다.
메모리
아무튼 우리가 만든 컴퓨터 HACK은 계속 봤지만 데이터 메모리 RAM과 명령어 메모리 ROM 두개로 나눠져 있으며 어드레스 레지스터 A를 이용하여 데이터 메모리의 값 M == RAM[A] 에 접근하기도 했었다. 근데 아직도 잘 이해안가는 건 어드레스 레지스터 A가 명령어 메모리의 현재 명령을 가리키고 있다고 하는데,
12: @23
13: D=A
위 연산에서 어드레스 레지스터 A는 23이란 값을 저장하고 있지, D=A란 연산의 주소를 가지고 있지는 않았던거같다.
다음에 실행할 거긴 하지만 명령어의 주소를 가지고 있는건 프로그램 카운터가 아니었나?
어드레스 레지스터 A가 어떻게 명령어 메모리의 명령어 주소를 가리키는가?
아 어셈블리어 천천히 돌리고 나서야 이해가 된다.
위 사진을 보면 지금 ROM의 16번지에서 A레지스터에다가 0을 담고
17번 명령어에는 RAM[0]의 값을 데이터 레지스터에 넣도록 하고 있다.
그런데 그 다음 줄을 보면 A 명령어와 C명령어로
@22
D; JEQ
가 있는데,
이 명령어를 진행하면 @22라는 A 명령어에 의해 A 레지스터에 22가 담기게 되고,
D에 있는 값에 따라 ROM의 22번지로 점프하게 된다.
그러니까 여기서 어드레스 레지스터 A는 점프해서 갈 명령어의 주소를 가리키고 있다.
해당 부분의 실제 어셈블리 코드는
@R0 D=M @END D;JEQ
인데 어셈블리어에서 작성한 @END가 어셈블리로인해 @22가 된후 기계어로 되어 롬에 올라갔고,
어드레스 레지스터에 담겨져 주소 역활을 한게 되었다.
이제야 이해된다!
그래서 어드레스 레지스터 A가
데이터의 주소, 명령어의 주소, 임시 데이터 보관 역활을 하는건가보다.
CPU
앞에서 메모리니, 어셈블리어니, 명령어니 계속 정리해왔는데, 이제 CPU를 다룰 차례가 되었다. 계속 공부해왔지만 구현했던 ALU, 레지스터, 제어기 등으로 구성되어 있다.
ALU : 이름 그대로 산술 논리 연산하는 장치이며, 구현되지 않은 기능은 하드웨어로 구현해도되고 소프트웨어로 구현해도되며 비용이나 성능, 효율성을 고려해서 설계된다.
레지스터 : 레지스터는 CPU 안에 있는 작지만 고속의 기억 장치인데 CPU가 아주 빠르게 동작하다보니, 기억 장치 CPU 밖에 있는 메모리라 한다면 메모리에 값을 잠깐 저장한다거나 원하는 값이든 명령어든 가져 오려고 하면 CPU의 작업 속도에 비해 오랜 시간이 걸려 일을 못하고 지연되는데 이를 stavation 기아 상태라고 한다. 이런 기아 상태를 방지하고, 계산 속도를 늘리기 위해 CPU 내부에 작지만 고속으로 읽고 쓰기가 가능한 기억 장치를 둔 걸 레지스터라고 한다. 일반 컴퓨터에서는 레지스터가 많이 존재하지만 우리가 만들 HACK에는 어드레스 레지스터, 데이터 레지스터 그리고 프로그램 카운터 3개 뿐이다.
제어 : 어셈블리어를 보면 알수 있지만 명령어들은 ALU에 입력으로 쓰거나, 메모리에서 가져오거나, 레지스터에 잠깐 저장하는 등 각 하드웨어 장치에 읽고/쓰기 등의 동작들 중에서 어떤 동작을 프로그램 실행중에 할지를 의미한다.
가져오기 및 실행 : fetch-execute를 가져오기 및 실행이라 적었는데, 대강 의미는 맞으니까 CPU의 과정은 명령어를 가져오고 실행하기의 반복이라 할수 있을거 같다. 에뮬레이터에서 봤지만 CPU는 프로그램이 실행되는 동안 각 사이클(클럭 마다) 명령어 메모리 ROM에서 실행할 명령어(에뮬레이터상에서는 어셈블리어지만 실제로는 이진 기계어)를 가져오게 되고 C 명령어의 c 비트에 따라 어떤 동작을 할지 해석(판단)하여 그 동작을 실행/수행 execute한다. 그래서 이 과정을 fetch-execute 사이클이라고 부르나보다.
입출력 장치
지난 장에서 설명한거지만 컴퓨터 주변장치인 키보드와 화면을 memory mapped i/o 방식으로 ram 상에 화면과 키보드의 메모리맵에 접근해서 값을 읽거나 써왔다. 이런식으로 입출력 장치를 제어하는 이유는 실제 컴퓨터 주변 장치로 키보드, 화면 뿐만 아니라 마우스, 카메라도 있을 것이고, 프린트나 다른 센서 등 수 많은 장치들이 있다. 하지만 이런 장치들 각각을 어떻게 컴퓨터와 연결해서 사용할까 각 장치가 어떤지 다 알아야할까?
그런 번거로움을 줄이기 위해서 각 장치들의 메모리 맵을 RAM의 영역에 배당하여 해당 매모리맵 영역에 접근함으로서 주변장치들을 사용가능하도록 약속한게 memory mapped i/o 방식이고 이덕분에 지난 과제에서 간편하게 스크린과 화면을 제어할수가 있었다.
오늘 새벽에 그 과제를 하면서 너무 피곤하기도 하고 시간이 늦어서 제대로 설명하지는 않았지만, 클럭 사이클마다 각 주변장치의 매모리맵을 보고 (ex. 키보드 입력이 들어오면 화면에 검은칠을 하라)원하는 동작을 하도록 처리하다보니 사람이 보기에는 알아차릴수 없을 만큼 빠르게 반영된다.
그리고 화면은 2차원 배열 형태로 되어있는데, 메모리는 1차원 주소로 접근 했었다. 그런데도 입출력 메모리 맵핑 방식으로 스크린에 접근할수 있었던건 스크린의 2차원 주소를 1차원으로 직렬화를 했기 때문이다. 일일히 적기는 번거로워서 안했지만 1차원으로 변형한 주소를 이용해서 스크린의 모든 픽셀에(정확히는 각 픽셀들을 담은 레지스터에) 접근할수 있었다.
입출력 매모리 맵핑 방식을 사용하기로 약속/표준화 하여 컴퓨터든 주변장치든 서로 상관없이 만들더라도 이런 약속을 지킨 덕분에 주변 장치의 매모리 맵을 할당하고 사용할수 있게 되었다고 이해하면 될거같다.
주변장치 인스톨러 : 그래서인가 예전에 카메라든 프린터든 새로사서 컴퓨터에서 쓰려면 그런 장치를 쓸수 있도록 설치 프로그램을 돌렸는데, 이런 설치 프로그램을 설치하면서 컴퓨터가 새 장치의 메모리 맵과 베이스 주소를 가져서 사용할수 있게 되는거고
디바이스 드라이버 : 리눅스를 공부하면서 보게되는 디바이스 드라이버도 이것도 인스톨러와 해당 입출력 장치의 메모리맵을 설정하고 물리적인 주변장치에서 값을 어떻게 가져올지를 정리하는 프로그램이라고 한다.
이제 이번장 이론 마지막으로 HACK 컴퓨터의 구성 요소들을 간단하게 보고 과제를 좀 해야겠다.
그래도 이번 장은 생각보다 빨리 정리 끝낼거같네.. 과제가 얼마나 걸릴지는 모르겠지만 ㅋㅋㅋㅋㅋㅋㅋㅋ
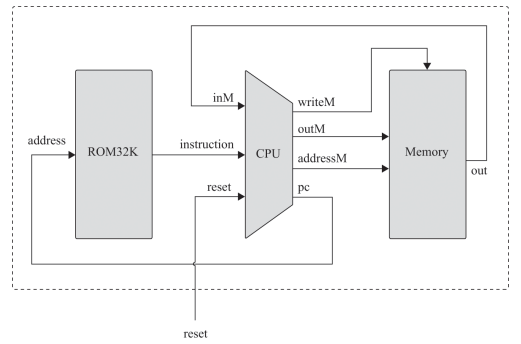
HACK 컴퓨터
HACK 컴퓨터는 확장자명을 hack으로 하는 기계어 프로그램을 동작시키는 16비트의 폰 노이만 구조의 컴퓨터다. 데이터 메모리인 RAM과 명령여 메모리인 ROM이 컴퓨터에 내장되며 같은 버스, 어드레스 레지스터 A로 접근해서 값 혹은 주소를 읽고 썻었다.
CPU
1) 입력
- inM은 이름 그대로 데이터 메모리에서 가져오는 값
- instruction인 A 명령어 혹인 C명령어로 A 명령어일때는 A=값, C명령어일땐 명령을 수행 or A/D/M 레지스터 중 지정된 곳에 저장(C 명령어의 목적지가 M이면 writeM은 쓰기 명령을 위해 1이되고, 그렇지 않으면 0이된다. 결과는 outM)
- reset이 0이면 다음 명령을 하지만 1이되면 프로그램 카운터가 0을 가리킨다.
* 주의사항 : 출력 outM과 writeM은 조합 논리회로로 구현되서 명령어 실행 즉시 반영된다!
출력 addressM과 pc은 순차 논리회로로 구현되어 다음 타임 스탭, 클럭에서 반영된다.
명령어 메모리
ROM32K이기도 하며, 0000 0000 0000 0000 ~ 0111 1111 1111 1111 2^15(32K)만큼 접근할수 있고, 한 레지스터가 16비트로 이뤄지다보니 출력은 16비트 크기를 갖는다. ROM이다 보니 어드레스로 접근은 해도 쓰기 작업은 없어 in이나 load 단자는 없다.
입출력 장치
화면과 키보드는 데이터 메모리 RAM에 매핑되어 사용되고, 클럭마다 반영되는데 이 장치들의 매모리 맵을 별도의 빌트인 칩인 Screen과 Keyboard으로 다룬다고 한다. 이것들이 따로 있다는건지 아니면, 램 상에 들어있는걸 칩이라고 부르는지는 잘 이해는 안되지만 일단은 좀 더보자
화면 메모리 맵 : 쓰기 작업을 하다보니 전에 구현한 RAM과 비슷하게 address와 load 입력을 받는다. 차이라면 스크린 공간이 8K다보니 주소가 13비트 입력으로 되어있다.
키보드 메모리 맵 : 키보드 베이스 어드레스의 위치에 있는 레지스터 하나의 값으로 키보드 입력을 나타내다보니, 입력 값이나 주소가 필요없고, 16비트 출력만 내보낸다.
데이터 메모리 RAM
앞서서 스크린과 키보드를 칩으로 나타내고 있으니까 순간 혼동했는데 RAM4K, RAM16K를 구현할 떄 처럼 저만 스크린, 키보드 칩은 그냥 저 크기를 가지는 주변장치의 입출력을 저장하는 기억장치였다. 이 주변장치들이 RAM 안에 포함되어 있어서 16K와 합친다고 별도의 칩으로 표현해놓은 것이고, 결국에는 RAM = RAM16K + 스크린(RAM8K) + 키보드(레지스터, 읽기전용) 하여 데이터 메모리를 구현하나보다.
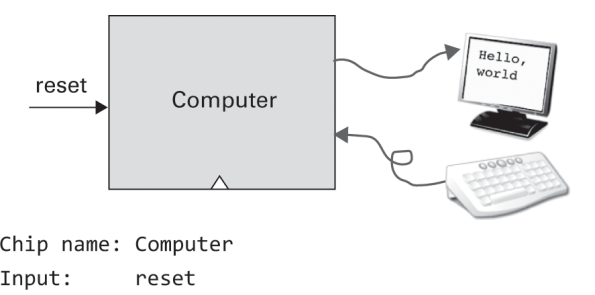
컴퓨터
드디여 난드 투 테트리스의 마지막 하드웨어인 컴퓨터를 구현할 차례다. 프로그램을 어떻게 집어 넣는지는 아직 잘은 모르겠지만 앞서 만든 CPU와 RAM, ROM을 잘 조합한게 컴퓨터이고, 이 컴퓨터는 reset 입력만 받는다. 0일때는 그대로 프로그램 카운터 진행되는데로 연산하지만 reset 1이 되었다가 0이되면 프로그램 카운터가 0이되어 다시 시작한다.
와 벌써 하드웨어 마지막 과제라니 내가 이걸 주말부터만들기 시작해서 이제서야 5장까지 왔다.
책 페이지로는 1/3 조금 넘게 밖에 못온게 너무 충격이긴한데,
디지털 논리회로만 넘기면 나머지는 쉬울줄 알앗지만 장난아니었다.
2년전에 ALU하다가 포기하기도 했었고
이번에 다시하면서 처음에 논리회로 만들때만 해도 포기하고 싶었는데 계속 하다보니까 컴퓨터 구현까지
// This file is part of www.nand2tetris.org
// and the book "The Elements of Computing Systems"
// by Nisan and Schocken, MIT Press.
// File name: projects/04/mult/Mult.tst
load Mult.asm,
output-file Mult.out,
compare-to Mult.cmp,
output-list RAM[0]%D2.6.2 RAM[1]%D2.6.2 RAM[2]%D2.6.2;
set RAM[0] 0, // Set test arguments
set RAM[1] 0,
set RAM[2] -1; // Test that program initialized product to 0
repeat 20 {
ticktock;
}
set RAM[0] 0, // Restore arguments in case program used them as loop counter
set RAM[1] 0,
output;
set PC 0,
set RAM[0] 1, // Set test arguments
set RAM[1] 0,
set RAM[2] -1; // Ensure that program initialized product to 0
repeat 50 {
ticktock;
}
set RAM[0] 1, // Restore arguments in case program used them as loop counter
set RAM[1] 0,
output;
set PC 0,
set RAM[0] 0, // Set test arguments
set RAM[1] 2,
set RAM[2] -1; // Ensure that program initialized product to 0
repeat 80 {
ticktock;
}
set RAM[0] 0, // Restore arguments in case program used them as loop counter
set RAM[1] 2,
output;
set PC 0,
set RAM[0] 3, // Set test arguments
set RAM[1] 1,
set RAM[2] -1; // Ensure that program initialized product to 0
repeat 120 {
ticktock;
}
set RAM[0] 3, // Restore arguments in case program used them as loop counter
set RAM[1] 1,
output;
set PC 0,
set RAM[0] 2, // Set test arguments
set RAM[1] 4,
set RAM[2] -1; // Ensure that program initialized product to 0
repeat 150 {
ticktock;
}
set RAM[0] 2, // Restore arguments in case program used them as loop counter
set RAM[1] 4,
output;
set PC 0,
set RAM[0] 6, // Set test arguments
set RAM[1] 7,
set RAM[2] -1; // Ensure that program initialized product to 0
repeat 210 {
ticktock;
}
set RAM[0] 6, // Restore arguments in case program used them as loop counter
set RAM[1] 7,
output;
사용한 테스트 스크립트는 이건데
ALU로 M=M+D 연산이 가능한걸 잊어버리고,
+1연산으로 이중루프를 만들어 곱셈 연산을 구현하느라
클럭 루프를 너무 많이 돌아버렸고,
앞에 작은 수를 다루는 경우는 문제 없었지만
마지막 6 * 7 예제에서 210회 클럭안에 수행해야하는데
M=M+D 연산으로 하면 금방할걸
+1연산으로 구현해 놓으니 210회 클럭안에 연산을 마치지 못해서 자꾸 에러뜨길래
이게 라인 수가 너무 많아서 그런갑다 싶어 라인 수를 줄이느라 시간낭비했다.
그러다가 갑자기 +1 안해도 되는게 생각나서 했더니 20분도 안걸리고 해결했다 ㅜㅜ
아아아아아ㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏㅏ
이거에서 해매지만 않았어도 진작에 입출력 제어 끝내고 다음 장으로 넘어갈텐데
곱셈 연산 해결한게 밤 11시 30분이라
입출력 헨들링까지 하고 글 정리하고 가면 좀 더 지나야 갈수있을거같다.
Mult_v1.asm
Mult_v2.asm
Mult_v3.asm
//210 클럭안에 6 * 7 곱연산을 마무리하지 못해 실패 @0 // init R2 as 0 D=A @R2 M=D @R0 // if R0 or R1 == 0 -> end D=M @BIG_STOP D;JEQ @R1 D=M @BIG_STOP D;JEQ @j // init j(=R0) - j * i = result M=1 (BIG_LOOP) //--start of big loop-------------------------------- @j // make big loop end condition value D=M @R0 D=M-D @BIG_STOP // if (R0 - j < 0 ) goto BIG_STOP r0 = 3, d = 4 => 3-4 < 0 D;JLT @i M=1 (SMALL_LOOP) // -----------start of small loop-------------- @i //make small loop end condition value D=M @R1 D=M-D @SMALL_STOP // if (R1 - i < 0 ) goto SMALL_STOP r1 =5, i = 6 -> 5 - 6 < 0 D;JLT @R2 //small loop start M=M+1 @i M=M+1 @SMALL_LOOP // goto small loop 0;JMP (SMALL_STOP) // -----------end of small loop-------------- @j //start big loop M=M+1 @BIG_LOOP 0;JMP //goto big loop (BIG_STOP) //--end of big loop-------------------------------- @BIG_STOP 0;JMP