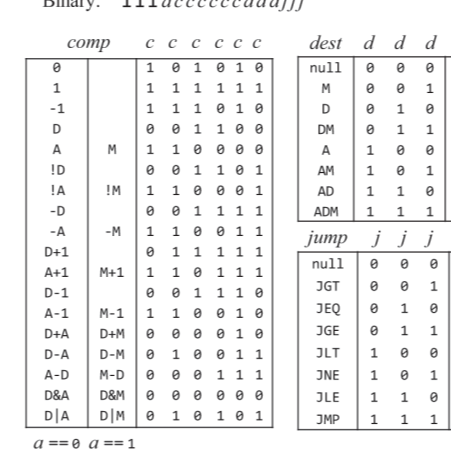
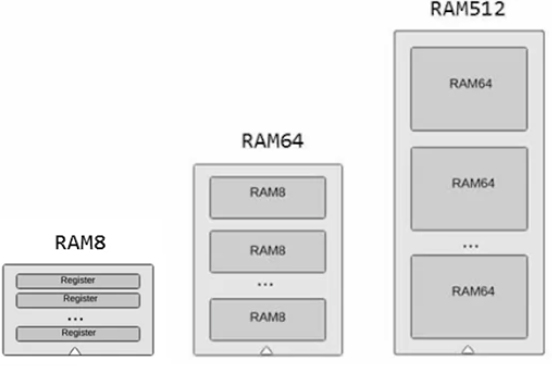
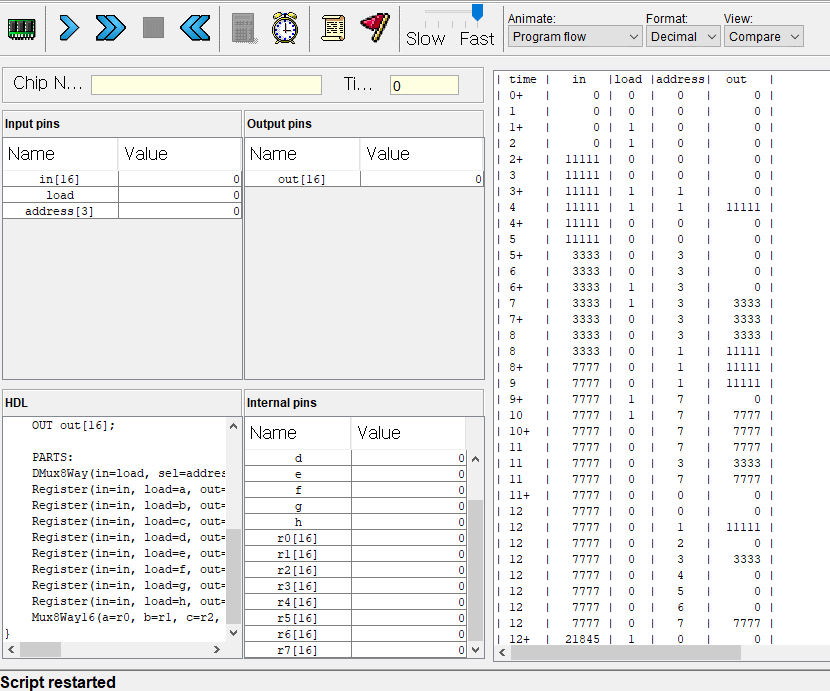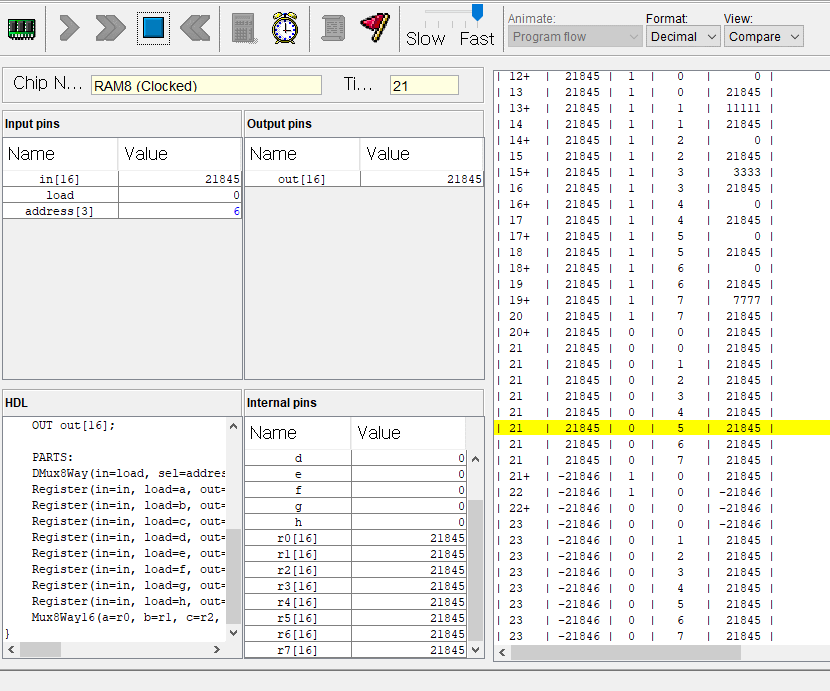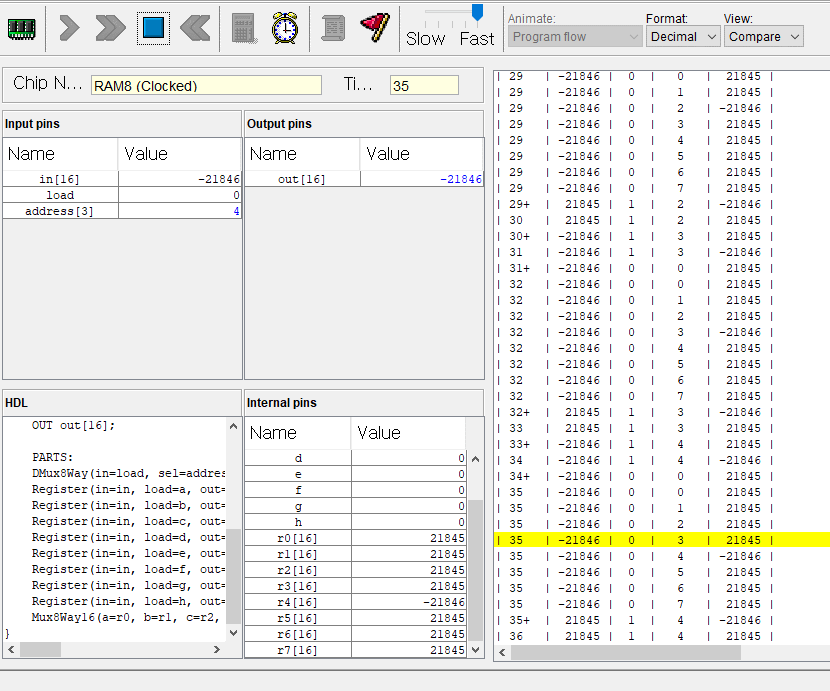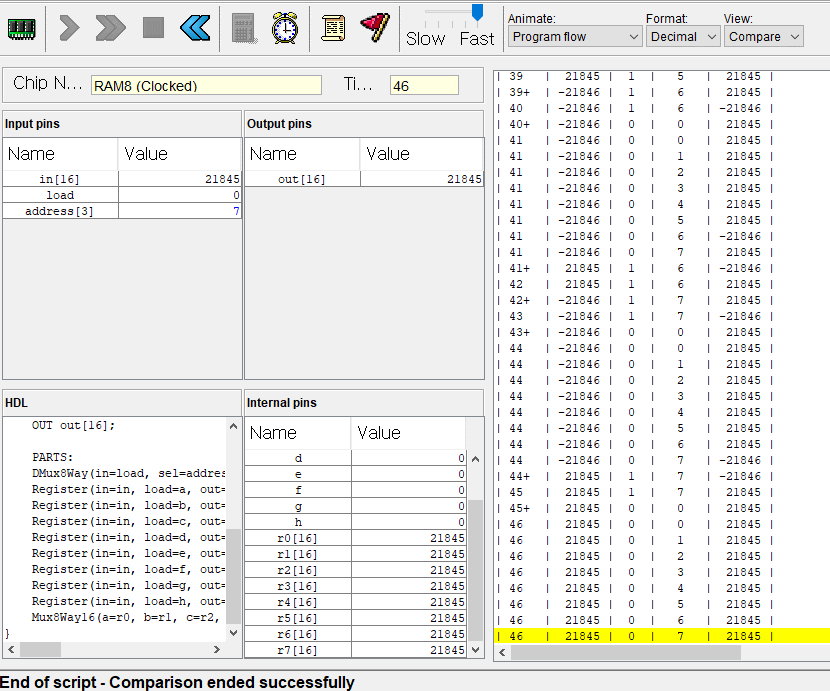
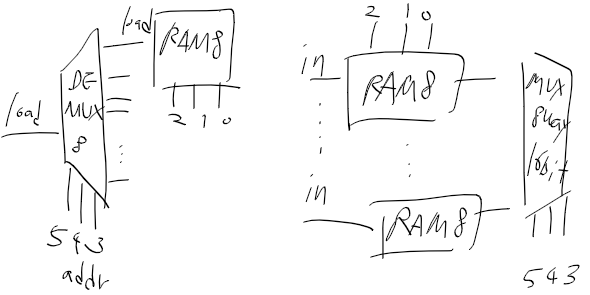
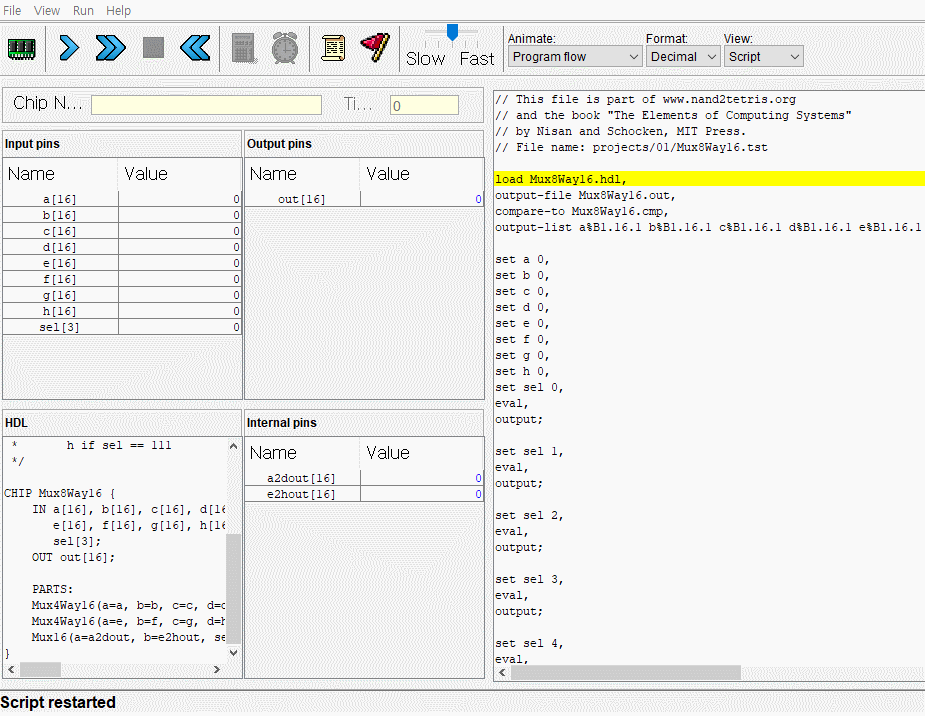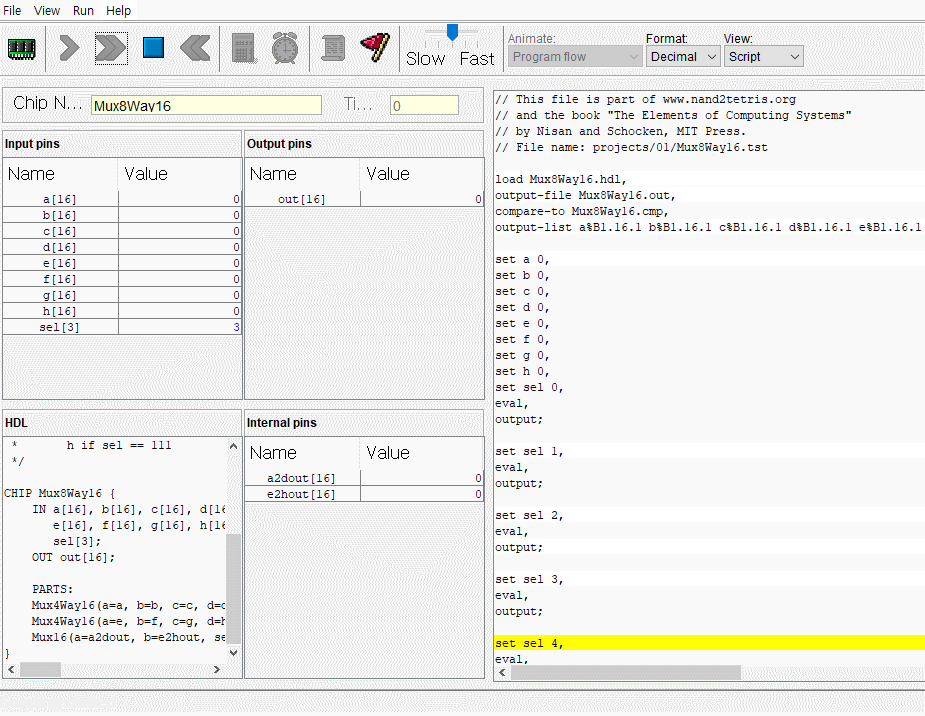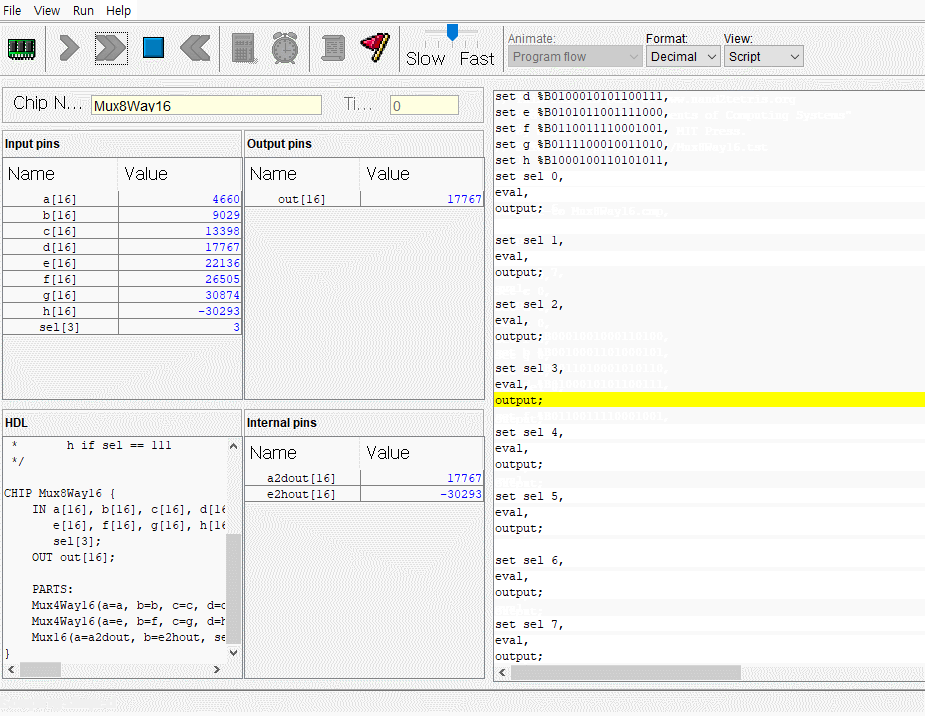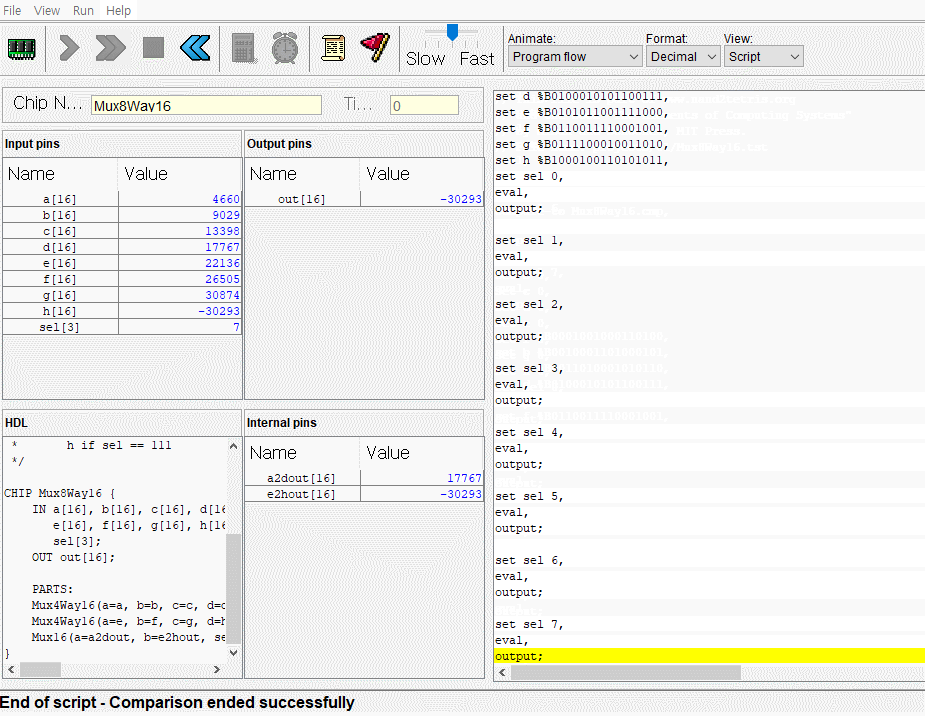
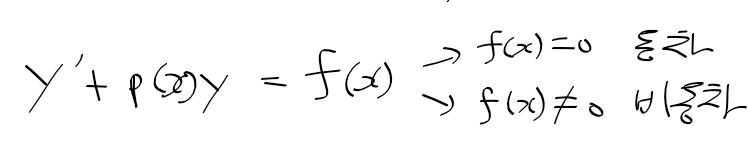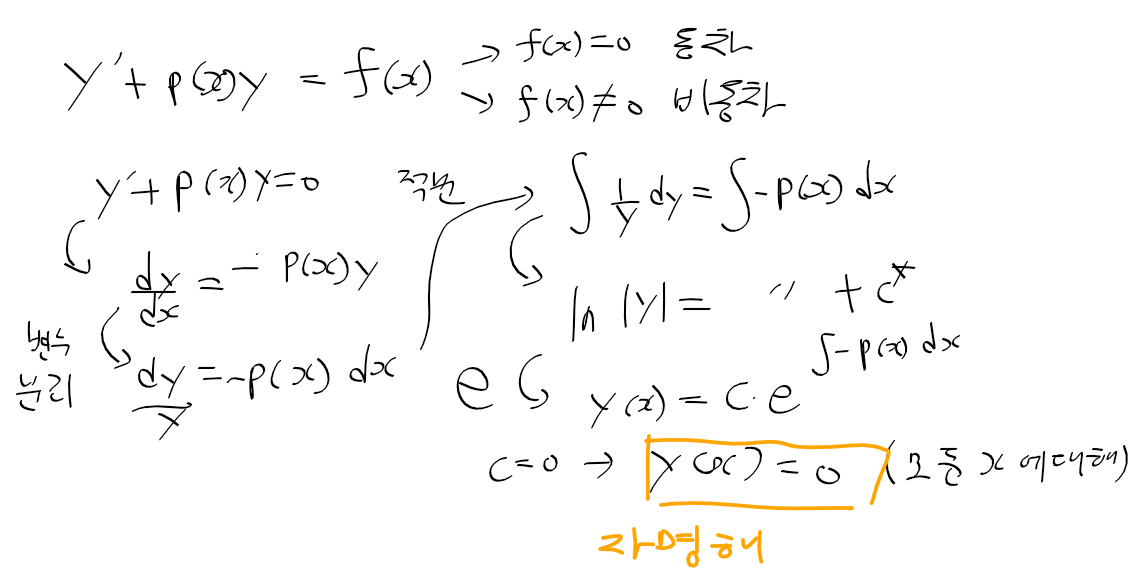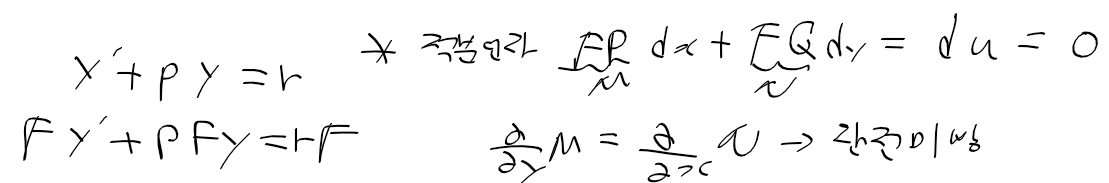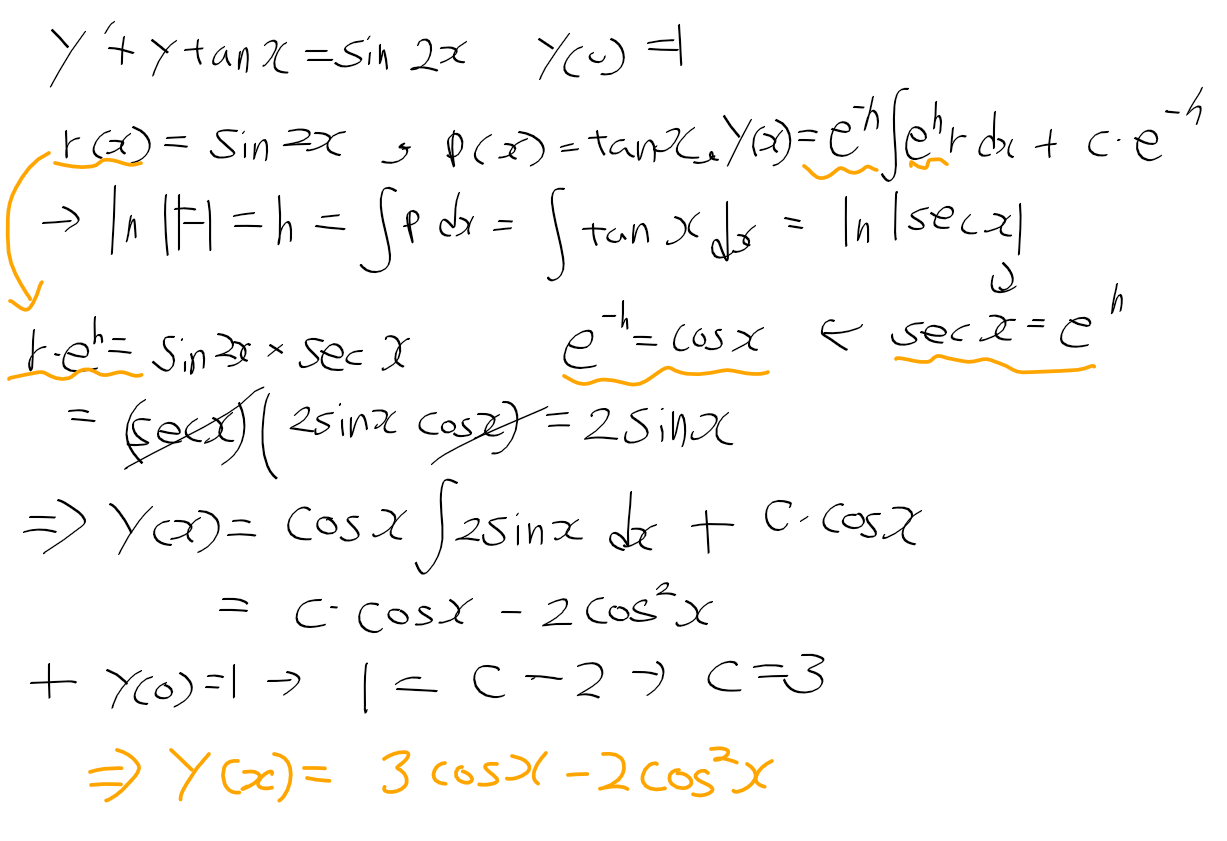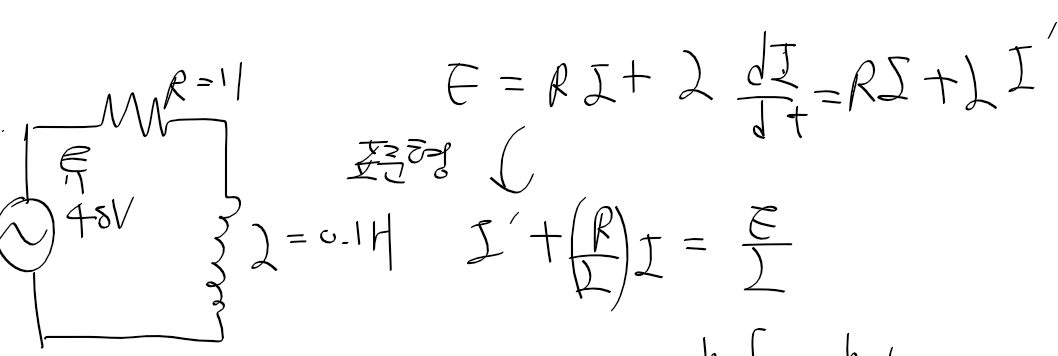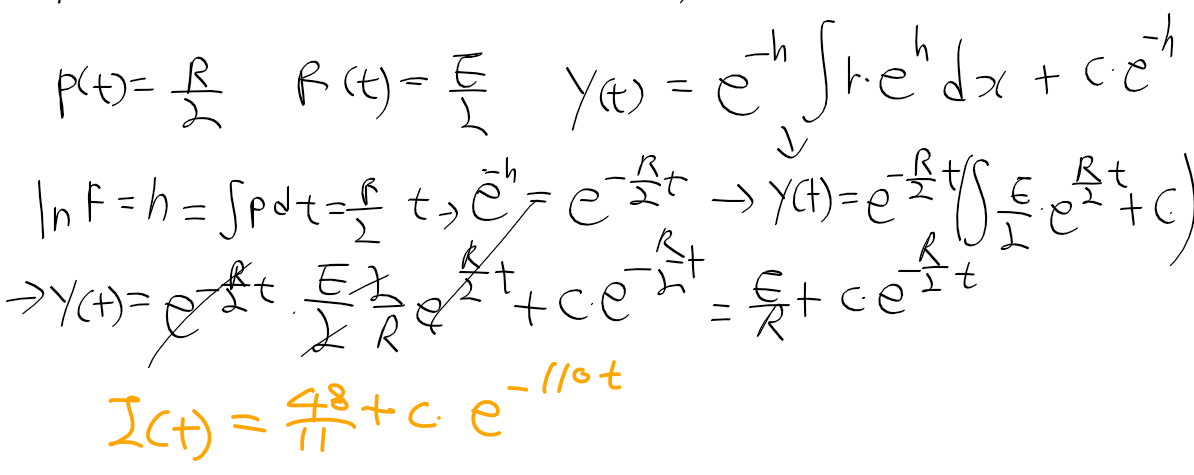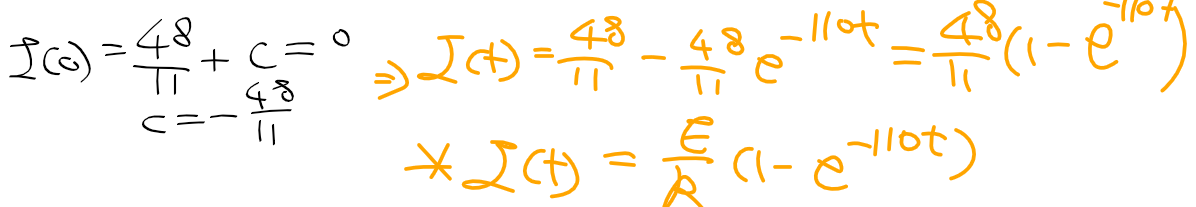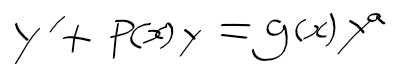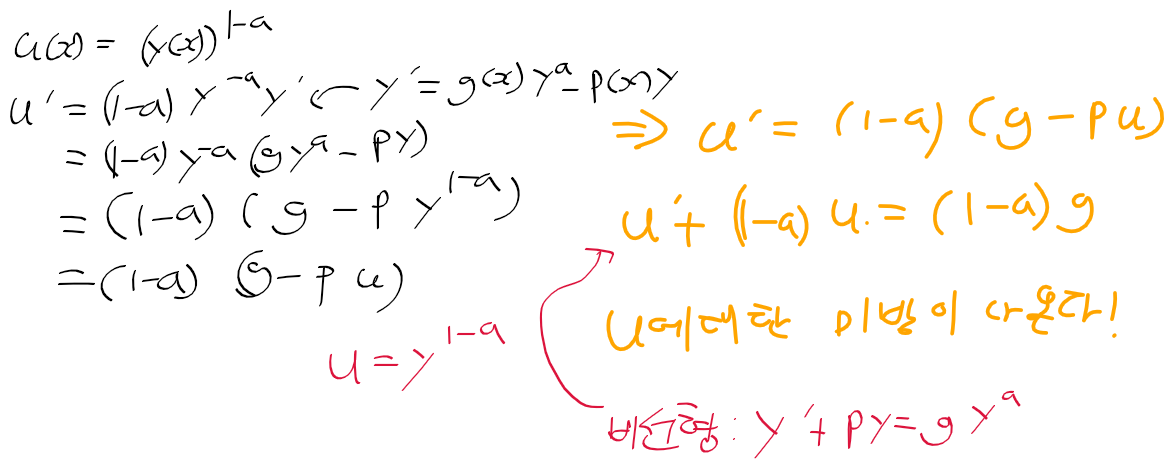C명령어는 연산 비트(comp, 7비트), 목적지 비트(dest, 3비트), 점프 조건 비트(jmp, 3비트) 세 부분으로 111accccccdddjjj 같이 구성된다.
(1) acccccc : 7비트로 ALU가 수행할 연산을 결정하는 comp 비트
* 위 표에 나오다 시피 a가 0일때와, 1일때 수행하는 연산이 따로 나눠져있다.
(2) ddd : 3비트로 ALU 연산 결과를 담을 목적지를 나타내는데 저장하지 않을지(null), M에 담을지(RAM[A]), D 레지스터에 담을지, A레지스터 D레지스터 둘다에 연산 결과를 담을지 등 이 세 비트의 값으로 결정한다.
(3) jjj : 3비트로 이뤄진 어떤 조건에 따라 점프를 할지를 의미하는 비트로 000인경우 점프 안함, 001 인경우 JGT로 연산 결과가 0보다 클때 점프, 111일때는 연산 결과에 상관없이 무조건 점프하는 JMP 명령이된다.
C 명령어의 연산 comp
2장에서 ALU 구현한걸 다시 떠올리면, 두 16비트 입력을 받도록 되어있었다. 그러면 이 두 입력을 가지고 어떻게 기계어로 연산을 할수 있을까? 첫번째 입력 x는 데이터 레지스터 D에 있던 값을, 두 번째 입력 y는 어드레스 레지스터 A로 지정한 데이터 메모리 레지스터 M에 담아둔 값을 사용한다.
(이부분이 조금 햇갈리긴한데 그냥 진행한다)
한번 comp의 입출력, ALU 상태 비트의 입출력 테이블을 같이 보면
comp 명령에서는 a가 0이고, cccccc가 001100일때 D의 값을 가져오고
ALU 상태 입력이 comp의 c비트와 동일하게 001100일때 x를 출력으로 하는걸 볼수있다.
그러니까 c가 001100 이더라도 a가 0일때는 데이터 레지스터 D, 1일때는 데이터 메모리 레지스터 M에있는 값을 가져온다.
ex) 심볼릭과 기계어로 D에 31, RAM[24]에 13이 들어있을때 D + M 연산해서 RAM[24]에 저장하자.
=> RAM[24] = 31 + 13
심볼릭
기계어(가독성을 위해 4비트씩 띄워쓰기함)
//1. RAM[24]에 13넣기 @13 D=A @24 M=D
//2. D = 31 @31 D=31
//3. D+M 후 RAM[24]에 쓰기 @24 M=D+M
0000 0000 0000 1101 // A명령어 13 1110 1100 0001 0000 // C 명령어 A를 로드해서(110000), D에다 저장(010), jmp안함(000) 0000 0000 0001 1000 // 24 1110 0011 0000 1000 // D의 값을 M에 쓰기 RAM[24]에 13넣기 끝
// 변수 i, sum 초기화 @i M=1 @sum M=0 (LOOP) // loop문 시작 @i D=M // D(i)-M(R0) = 0이면 i가 R0의 값과 같다 = i가 N까지 도달하였다. @R0 D=D-M // 모든 수를 더하였으므로 루프를 그만하고 (STOP) 문으로 넘어간다. @STOP D;JGT // STOP으로 점프하지 않았다면 루프를 진행하면 되니 sum = sum + i 연산 하자
@sum D=M @i D=D+M @sum D=M // sum + i 연산을 한 뒤 i = i+1을 하자 @i M=M+1 // 다시 루프 시작으로 가자 @LOOP 0;JMP (STOP) // 루프 종료 조건 충족시 아래의 루틴 진행 @sum D=M @R1 M=D (END) @END 0;JMP
진짜 A 명령어와 C명령어의 내용이 너무 햇갈린다. C 명령어의 dst와 jmp 둘다 쓸수 있지 않은지, 둘다 동시에 쓴다면 C 명령어 앞에 @R3이 있다면 R3의 값을 가져와서 1. dst 비트에 따라 M or A or D 에다가 C명령어의 연산 결과를 담고, 2. R3으로 JMP 간다고 생각하면 될까? 아니면 dst와 jmp를 동시에 쓰지 않고 dst만 하던가 jmp만 하는지. 지금까지 본 내용들을 보면 jmp와 dst 를 동시에 쓰는것 같지는 않다.
또 A 명령어의 값이 RAM과 ROM의 주소를 동시에 나타대나보니 C 명령어와 함께 너무 햇갈리게 되는데, 뒤에 오는 C 명령어에 M이 존재하는지 여부에 따라 A가 RAM 혹은 ROM의 주소를 나타내는지 판단할 수 있다.
뒤에 오는 C 명령어가 M을 사용하는 경우 => A 명령어의 값을 RAM의 주소로 쓴다
C 명령어로 점프를 사용하는 경우 => A 명령어의 값을 ROM의 주소로 쓴다
위의 두가지 경우 정도로 이해하고 넘어가자
hack 어셈블리어의 심볼
지금까지 본 심볼들은 숫자, 상수와 달리 의미를 가진 알아볼수 있는 문자였다. 어느 위치에 접근할 때마다. 숫자를 주소로 하여 사용하기도 하고, 위의 예시에선 i나 sum 같이 변수를 이용해서 값에 접근하기도 하였다. 근데 지금까지 본 어셈블리어에서는 i, 4 같은 숫자와 문자 뿐만아니라 R1, R3, (LOOP), (END) 같은 다른 것들도 있었는데 이 심볼들은 무엇일까? hack 어셈블리어에는 우리가 만든 심볼 외에도 미리 정의된 심볼들이 있다.
미리 정의된 심볼들
1. R0, ..., R15(가상 레지스터)
hack cpu는 16개의 레지스터를 가지고 있으며 R0은 RAM[0] ~ R15는 RAM[15]이 주소를 가지고 있다. A 레지스터가 주소 값으로 사용 될 때 @3의 경우 @R3가 동일한 동작을 한다고 할수 있긴 하지만, 미리 정의된 심볼을 사용하여 @3은 (확실하진 않지만) 데이터 레지스터로 사용되고 있구나, @R3은 데이터 메모리 주소로 사용되구나를 짐작할수 있는 장점이 있다.
2. SP, LCL, ARG, THIS 등
가상 레지스터 이외에도 스텍 포인터를 나타내는 SP, LOCAL 등 다른 미리 정의된 심볼들이 있지만 가상 머신을 배울때 다루므로 일단 넘어가자.
3. SCREEN, KBD
hack 컴퓨터는 IO장치로 스크린과 키보드를 사용하고 있다. 이 장치들을 사용하기 위해서 memory maped IO, 그러니까 스크린의 메모리 영역에 값을 쓰면 화면상에 표시되고, 키보드의 특정 키를 누르면 해당 키와 매핑된 메모리 주소의 값이 1이되는 식의 형태인데 이 미리 정의된 심볼들은 스크린 매모리맵, 키보드 매모리맵의 시작 주소 base address를 나타낸다. 이 내용은 5장 쯤에 다룬다.
4. 라벨 심볼
이 외에도 앞서 루프문 예제에서 봤듯이 (LOOP), (STOP), (END)와 같이 (내용)과 같은 형태의 심볼을 봤는데 이러한 심볼들을 라벨 심볼이라 한다. 이 라벨 심볼은 바로 다음에 나오는 명령어의 주소를 가리키고 있어 점프 시 라벨 심볼 뒤의 명령어를 시작하게 된다. 그리고 이 라벨 심볼은 대문자로 써야한다.
일반 변수 심볼
앞서 4가지의 미리 정의된 심볼에 대해서 정리하였고, 이런 심볼들 외 i, sum, x같은 것들을 변수 심볼이라 하며 @3을 사용했을때는 숫자 주소라 했지만 @i 일때는 어느 주소를 의미하는지 아직 알아보지는 않았는데 이는 어셈블리 파트에서 배울 수 있다.
우리가 이미 만든 alu로 and 연산을 하든 +1 연산을 하는든 뭔 연산을 할때의 기계어와
수정한 프로세서로하는 and 연산, +1 연산을 하도록 하는 기계어가 다를 것이다.
그래서 한 프로세서의 기계어는 다른 프로세서에서 사용할수 없으며
이를 하드웨어에 의존적이다. 호환되지 않는다는 식으로 표현한다.
x86이니 x64니 arm이니 코어텍스가 뭐니 하는 내용까지는 제대로 정리해본적이 없어서 설명할수는 없지만
이런 이유로 저급언어는 각 프로세스마다 다르기 때문에 하드웨어에 의존적이라고 한다.
하지만 고급언어는 어떨까?
처음 C언어나 Java, 파이썬 같은 언어를 공부할 때 이식성이 좋다,
하나의 코드로 여러 플랫폼에서 사용가능하다는 식으로 설명한다.
나도 처음에 수업 들을때 아무도 이거에 대해서 제대로 설명해주질 않아서
이식성이 좋다는게 무슨 의미인지는 잘 모르지만, 그냥 그러려니 하고 넘어갔었다.
이걸 공부하면서 조금 더 와닿게 이해할수 있는데,
여기서 이식성이 좋다는 말은 어느 환경에서 코드를 작성하던 간에
이 프로그램을 리눅스면 리눅스, 윈도우면 윈도우, x86, atmega이든지
각 프로세서가 뭔지 동작 할 환경을 선택해서 컴파일하기 때문에
하나의 코드로도 사용하는 컴파일러나 가상머신에 따라
해당 프로세서에 적합하게 기계어/바이너리를 만들어내어
똑같은 코드지만 안드로이드에서도 돌아가고 윈도우에서 돌아가고, 다른 MCU 등
다양한 환경에서 실행가능하게 된다는 의미로 이식성, 호환성이 좋다고 하는 거더라
하지만 이런 고급언어와 컴파일러같은걸 생각안하고
직접 어셈블리어든 기계어를 바로 작성 한다면 프로세서 마다 다르게 작성해줘야 할거다.
기계어와 구성 요소
그러면 기계어에는 어떤 것들이 있을까?
이미 알겠지만 이진수로 된 바이너리와 알아볼수 있는 문자로 된(=심볼릭한) 어셈블리어가 있다.
저자가 말하기를 기계어로 직접 코딩하는 사람은 많진 않지만 이런 저수준 프로그래밍을 할 수 있다면
우리가 일반적으로 쓰는 고급 언어의 동작을 더 잘 이해하고 효율적으로 작성할수 있게 된다고 한다.
이미 앞에서 말한거지만 기계어는 단순한 0과 1의 조합에서 조금 더 정확하게 이야기하면
프로세서가 레지스터와 메모리 사이에 값을 읽고 쓰도록 제어하도록 만든 동작 과정인데
메모리는 명령어와 데이터들을 저장하는 장치로, 지난 장에서 메모리를 만들때 봤다시피 한 레지스터마다 고유의 주소를 가지고 있어 우리는 이 주소값을 이용하여 해당 메모리에 접근해 값을 읽거나 덮어씌운다.
프로세서(CPU)의 경우 구성요소 중 하나인 ALU를 구현했을때 봤다시피 산술, 논리 연산뿐만이아니라 기억장치에 접근하고, 분기 연산을 수행가능하도록 만든 장치라 할수 있다. 분기 연산이 어떻게 되는지는 아직 보지는 않았지만 2장 과제를 하면서 이 게이트, 저게이트 합쳐서 만든 ALU가 실제로 산술논리 연산하는것을 시뮬레이션을 돌리면서 봤었다.
프로세서는 레지스터라고 하는 작은 기억장치를 가지고 있는데, 레지스터의 경우 프로세서가 메모리를 접근해서 값을 읽고 쓴다고 했었지만 프로세서와 메모리 사이의 거리는 사람 기준으로 가깝다 해도 컴퓨터의 동작 클럭을 생각하면 너무 먼 거리고 시간도 오래걸릴것이다. 그래서 다양한 이유로 CPU 내부에 사용할수 있도록 만든 작지만 고속의 기억장치를 레지스터라 한다.
잠깐 딴 소리지만 레지스터에 대해서 정리하다가 생각난게 그 동안 이전에 컴공 공부하거나 자격증 준비하면서 SRAM은 정적인 비활성메모리다, DRAM은 동적인 비활성메모리다. 정도로만 이해하고 있다가. 전기 자격증도 준비하고, 폴리텍에서 공부하면서 SRAM과 DRAM에 대해서 조금 더 자세히 알게 되었었는데,
SRAM의 경우 플립플롭을 이용해서 만든 저용량이지만 고속의 기억장치로 케시메모리로 사용되고,
DRAM의 경우 캐패시터를 이용해서 만든 기억장치로 케시메모리에 비해 느리지만 큰 용량이라 메인 메모리로 사용된다고한다.
전처럼 아예 책 번역하는게 아니라 생각 정리하는건데도 생각보다 오래걸린다..
아무튼 다시 레지스터로 돌아와서 다른 cpu도 비슷하겟지만 hack의 레지스터로는 값을 저장하는 데이터 레지스터와 데이터 값 또는 메모리 주소를 저장하는 어드레스 레지스터 두 종류가 있고, 어드레스 레지스터가 가진 주소값에 접근하여 값을 읽고 쓰게 된다. 지난 렘 시뮬레이션때는 어드레스 레지스터의 값은 아니지만 .cmp 파일에서 지정한 주소에 접근해서 값을 읽고 쓰는고 원하는 결과가 나왔는지 비교하는 시뮬레이션을 돌렸었다.
기계어 : 바이너리와 심볼릭
아까 기계어는 2진수 바이너리와 사람이 알아볼 수 있는 심볼릭(=어셈블리어 같은거) 두 가지가 있다고 했다.
R1 + R2한 결과를 R1에다가 저장하라는 연산을 바이너리랑 심볼릭으로 적어본다고 하자.
기계어로 쓸때 덧셈 연산을 6비트로 101011, R1과 R2 레지스터는 각각 5비트로 00001, 00010이라 할때 이들을 합쳐 16비트 바이너리 코드로 만들면 1010110001000001 -> 101011(add)/00010(R2)/00001(R1)이 된다.
심볼릭 하게 쓴다면(어셈블리어는 아니지만, 뭔소린지 알수있게) set R1 = R1 + R2 같은 식으로 될거같다.
심볼릭을 보면 R, 1, 2, + 같은 심볼(상징, 부호, 기호라고 하는데 부호 정도로 해야지)이 여러 차례 나오게 될텐데 이들을 어셈블리어라고 하며, 이런 심볼들을 기계어로 바꾸는 번역기가 어셈블리어가 된다.
아까도 말한거지만 어떤 하드웨어에 상관없이 사용가능한 고급언어와는 다르게 저급 언어는 ALU나 메모리, 레지스터 등에 따라서 다르다지만 비슷한 CPU 제품군 끼리는 동일한 기계어를 쓸수 있도록 되어있다고 한다.
심볼릭 명령어의 예시
1. 산술 논리 연산
load R1, 17 //17을 R1에 넣어라
add R1, R1, R2 //R1, R2를 더해서 R1에 넣어라
load R1, true //R1에다가 true를 넣어라
and R1, R1, R2 //R1에다가 R1, R2 and 연산 결과를 넣어라
2. 메모리 접근 방법
다른 컴퓨터는 어떤지는 모르지만 hack 컴퓨터의 경우 어드레스 레지스터 A를 이용해서 메모리 접근을 한다.
메모리의 15번지에다가 1을 넣고 싶다면,
(1) load A, 15 명령으로 어드레스 레지스터 A에다가 1을 넣고
(어드레스 레지스터 A는 값을 임시로 저장하거나, A에 저장된 값은 메모리 레지스터 M의 주소를 의미한다. A에다가 값을 저장한건지 M의 주소를 담는 건지는 기계어에 따라서 구분하니 뒤에 참고하면 된다.)
(2) load M, 1 명령으로 메모리 레지스터 M에다가 1을 대입하면 된다.
왜 M에 저장이 안되고 15번지에 저장이 되었는지는 어드레스 레지스터 A에 입력된 값이 곧 메모리 레지스터 M의 주소이기 때문이다. (꼭 A에 저장된 값이 M의 주소값으로만 사용되는 건 아니다.)
3. 흐름 제어와 심볼
우리가 C언어를 공부할 때 goto나 어떤 언어를 공부하던간에 반복문을 배웠을거고 정말 자주 사용한다.
goto나 반복문에서는 어떻게든 간에 goto를 만나거나 반복문의 끝에 도달하면 지정한 곳이나
반복문의 앞으로 돌아갔지만 그러면 어셈블리어에서는 어떻게 사용할까?
물리적인 주소를 사용하는 경우와 심볼릭 주소를 사용하는 두가지가 있다.
일단 물리적인 주소를 사용하는 경우는 돌아갈 장소의 줄을 직접 써서 가고
9: add R2, R2, 1
...
13: goto 9
심볼릭을 사용하는 경우는 알아볼 수 있는 심볼을 써서 해당 심볼로 돌아가게 된다.
add r3, r3, 1
...
(LOOP)
...
goto LOOP
그러면 물리적인 주소와 심볼릭한 주소를 사용한 경우의 차이점은 무엇일까? 우리가 프로그래밍 언어를 배우면서 상수보다는 변수 쓰는것과 동일하다고 생각할수 있을거같은데,
간단한 출력 예시를 든다면
print(3)
print(a)
위의 경우는 상수 3을 쓴 만큼 동작 중에는 바뀔수가 없고, 3대신 2를 출력하고 싶을때 기존의 3을 모두 2를 고쳐야 하면서 코드 작성할때 이해하거나 나중에 디버깅하는데 불편하다.
하지만 아래의 심볼릭으로 a를 썻을때는 a 에 3이 들어있더라도 2를 출력하길 원하면 a에 2를 넣으면 전체 a에 반영이 되기도 하고, 프로그램 실행 중에 a를 변경 할 수 이를 재할당 가능하다고 한다. 그래서 이런 재할당 가능한 심볼릭을 쓰면 물리적인 상수 주소를 썻을때보다 조금더 동적으로 변화하는 상황에 알맞게 동작하며 다루기도 좋다.
HACK 컴퓨터 구조
앞에 기계어가 뭐고, 고급언어가 뭐고, 심볼릭이니 어셈블리어니 하느라 말이 많았지만 이번에는 HACK 컴퓨터의 기계어에 대해서 정리하려고 하는데 HACK 컴퓨터에 대해서 잠깐 말하자면 앞서 구현한대로 HACK은 16비트 단위로 처리하는 폰 노이만 구조의 16비트 컴퓨터이다. 렘 파트에서 마지막에 16K 구현하길래 HACK의 메모리가 16K인줄 알았지만 32K였다.. 16K까지만 구현한 이유가 있는 곧 나오니도 하고 컴퓨터 구조를 간단하게 복습하면
* 이책 어딘가에 봤었는데 어딘질 모르겟다.
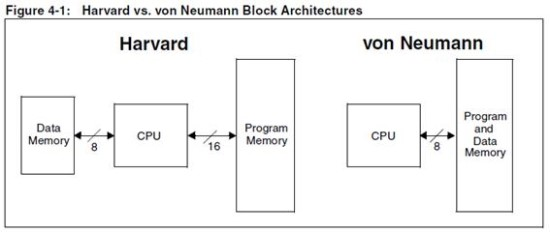
대표적인 컴퓨터 구조로는 폰 노이만 구조와 하버드 구조가 있다.
두 구조의 가장 큰 차이점이라면 폰 노이만 구조는 데이터메모리와 명령어 메모리가 붙어있어 동일한 통로(버스)로 되어있고, 하버드 구조는 데이터 메모리와 명령어 메모리가 분리되 서로 다른 버스로 읽고 쓴다고 한다.
폰 노이만 구조에서는 이전에 하드웨어로 직접 프로그래밍을 했던 것과는 달리 메모리에 저장하여 사용하게 되었지만(내장 프로그래밍) 통로가 하나 뿐이라 명령어와 데이터를 한번에 가져 올수없어 상대적으로 느리며(병목현상),
하버드 구조에서는 명령어 메모리와 데이터 메모리를 분리하여 한번에 두개를 가지고 올수 있어 상대적으로 빠른 처리가 가능하나 더 많은 메모리와 버스로 많은 공간을 차지한다고 한다.
HACK의 메모리와 레지스터 그리고 주소
아무튼 HACK 컴퓨터는 32K의 메모리를 가지고 있는데 폰 노이만 구조로 데이터 메모리와 명령어 메모리가 각각 16K씩 공간을 차지하고 있다. 그래서 지난번에 16K까지만 구현했나 보다. 데이터 값들을 담는 데이터 메모리는 값을 읽고 쓰니 RAM, 명령어 메모리는 여기에 저장된 명령어들을 읽기만 하니 ROM이라고 한다. 근데 이거 RAM 16K로 구현하였으니 휘발성 이니 이것도 RAM이라 하는게 맞지 않나? 아니면 명령어를 읽기만 해서 ROM이라 한건지는 좀더 봐야알거같다.
메모리와 레지스터 : 위 그림을 보면 데이터 메모리와 명령어 메모리, 아까 레지스터를 설명할 때 이야기한 어드레스 레지스터 A와 데이터 레지스터 D가 있다. 다시 반복하면 어드레스 레지스터 A는 데이터 레지스터와 동일하게 어느 값을 저장하고 있거나 데이터 메모리와 명령어 메모리의 주소를 저장하는 역활을 하는데, A가 주소를 담고 있을때, M = 0을 하면 RAM의 해당 주소에다가 0을 대입하게 된다. 어드레스 레지스터로 지정된 RAM 상의 레지스터를 데이타 메모리 레지스터 M이라 한다. ROM은 이름 그대로 읽기 전용 기억 장치로 차후에 자세히 설명하고, ROM의 레지스터 값은 현재 명령어를 나타낸다.
어드레스 레지스터 A에다가 18을 넣고자 한다면 어셈블리어로 @18(현재 A는 주소가 아닌 값을 저장하는 역할을한다)
이 값을 데이터 레지스터 D에 담고자 한다면 D = A를 하면 된다.
잠깐 뒷 내용을 당겨와서 하면 hack의 심볼릭과 기계어에는 주소와 값을 지정하기 위한 A명령어, 제어 명령을 나타내는 C명령어 두 종류가 있고, 이 hack 컴퓨터는 폰 노이만 구조라 데이터와 명령어 메모리가 하나의 버스를 공유하고 있다보니 hack 컴퓨터의 기계어는 값을 지정하기위해 A 명령어 먼저, 지정한 값을 사용하기 위해 C명령어가 따라와 같이 사용된다.
* hack의 심볼릭 예시 - 데이터 레지스터에다가 18 넣기(A는 값 저장 역할)
@18 // A 명령어
D = A // C 명령어
* 주소 처리 : 어드레스 레지스터를 이용하여 RAM 200번지에다가 값 18을 넣기 예시
@18 // A명령어 - 어드레스 레지스터에다가 데이터 레지스터에 임시로 담을 값을 지정
D=A // C명령어 - 어드레스 레지스터 값을 데이터 레지스터에 대입
@200 // A명령어 - 어드레스 레지스터에 200 대입
M=D // C명령어 - RAM 200번지에다가 데이터레지스터의 값(18) 대입
위의 예시를 보면 A 명령어 다음에 C 명령어에 데이터 메모리(RAM) 레지스터M이 사용되는 경우 A 명령어는 어드레스 역활을 하고, M이 없는 경우 A는 값을 보관하는 역활을 하고 있다.
분기 : hack 심볼릭 언어에서 조건 혹은 무조건적으로 특정 위치로 넘어가기 위해 goto를 하는 JMP 명령이 있으며, 무조건적으로 분기/넘어가고자 한다면 C명렁어로 0;JMP를 사용한다. 만약 무조건 56번지에 간다면 A명령어와 같이사용하여 다음 처럼 쓰면 된다.
@56
0;JMP
하지만 조건에 따라(0과 같거나 JEQ, 크거나 JGT, 작거나JLT) 분기하고자 하는 경우도 가능하며, 조건이 주어질때의 분기는 다음과 같이 할수있다.
@56
D;JEQ //D가 0과 같은 경우 56번지로 점프한다.
변수 이용하기 : 앞서 A 명령어를 사용할때마다 @{숫자}를 넣어서 사용해왔는데, @뒤에는 상수 뿐만이 아니라 심볼도 올수 있다. 예를들어 심볼/변수 x를 26로 지정하여 사용하고자 한다면
@26
D=A
@x
M=D
이렇게 하면 심볼 x에다가 값으로 26을 넣게 된다. 그런데 이 변수 x의 주소가 어디인지는 좀 더 봐야 알수있을거같고 일단 변수에다가 이런 식으로 값을 넣을수있다 정도로만 알고 넘어가자.
빌트인 심볼 : 그리고 hack 어셈블리에는 기본적으로 미리 지정된 빌트인 심볼 16개가 있는데 R0, R1, ..., R15로 R0은 데이터 메모리 0번지, R1는 1번지 ..., R15는 15번지라 할수 있고, 다음 명령어를 수행하면
@14
D=A
@R6
M=D
RAM[6]에다가 14를 넣은것과 같다고 생각하면 된다. 이 빌트인 레지스터들을 가상 레지스터라 한다.
A명렁어와 C명령어
조금 전에 hack 어셈블리어를 설명하기 위해 간단하게 A 명령어와 C 명령어 그리고 두 명령어의 심볼릭에 대해서 설명을 했었는데 어셈블리어는 기계어와 1:1 매칭되는 만큼 심볼릭을 아래와 같이 기계어 바이너리로 바꿀수 있다.
A명령어와 C명령어 구분 : hack은 16비트 컴퓨터라 명령어 길이가 16비트인데, 앞에 시작하는 바이너리 수를 보고 A 명령어인지 C명령어인지 구분할 수 있다. 아 잠깐 놓친건데 기계어 바이너리는 2부분으로 나눌수 있는데 opcode와 오퍼랜드이다. opcode는 이 명령어가 할 동작을 나타내고, 오퍼랜드는 이 명령어의 값 혹은 주소를 나타낸다.
hack 기계어의 MSB, 즉 가장 좌측 비트가 0인 경우 A 명령어로 보고 나머지 15비트는 오퍼랜드가 되겠다. 만약 MSB가 1인 경우에는 C 명령어가 되는데, 뒤의 따라오는 11은 칸을 채워주기 위함이며 나머지 13개 비트가 오퍼랜드가 된다.
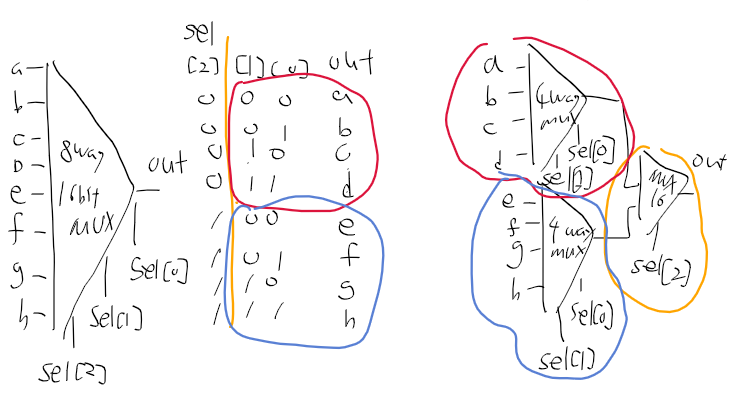
A 명령어 : A 명령어는 1비트를 이미 사용하고 있으므로 표현 가능한 숫자는 15비트, 부호없이 0 ~ 32767까지 표현이 가능하며 2^15만큼의 주소에 접근할수 있게 되겠다. RAM32K를 구현했지만 RAM과 ROM은 각각 16K이고, 16K = 2^10 * 2^4인데다가 실제로는 ROM 전체를 다 사용하지 않아 A 명령어를 통해 모든 메모리 주소에 접근 가능하다.
최적화 문제로 이전 장에서 만든것보다는 빨리 동작가능한 빌트인 된걸 사용한다고 나왔던거같다.
1. 반가산기
반가산기의 진리표, 입출력, 구조는 아래와 같다.
그대로 hdl을 작성해서 돌리면
CHIP HalfAdder {
IN a, b; // 1-bit inputs
OUT sum, // Right bit of a + b
carry; // Left bit of a + b
PARTS:
Xor(a=a, b=b, out=sum);
And(a=a, b=b, out=carry);
}
잘 된다.
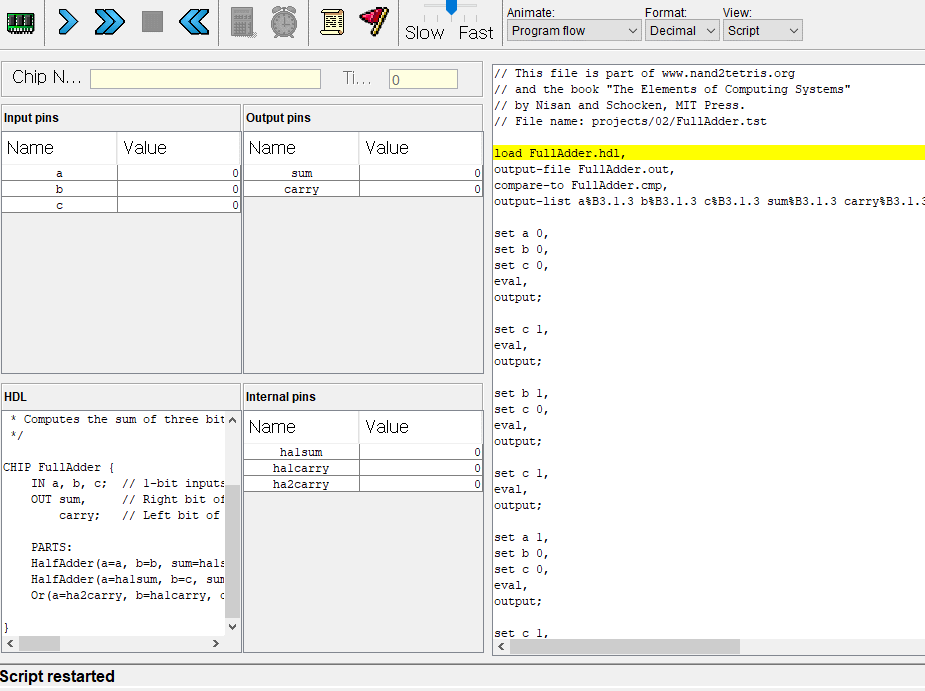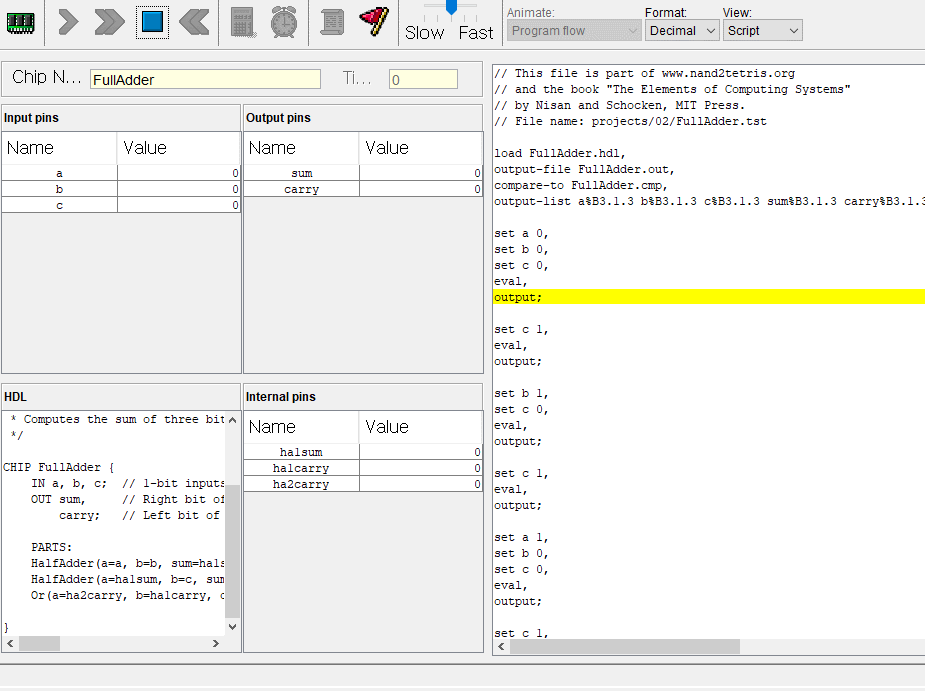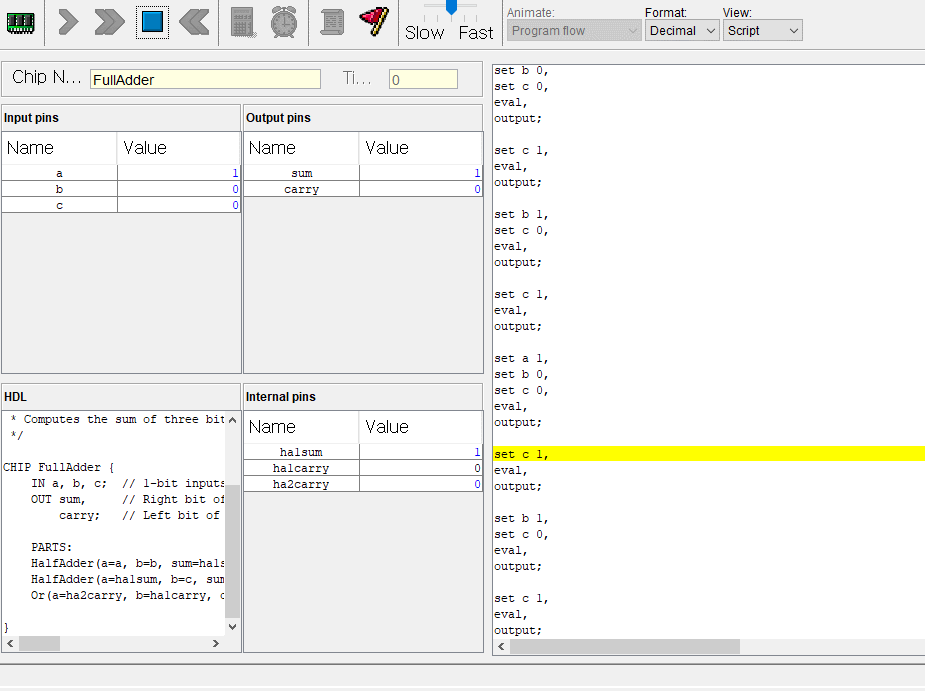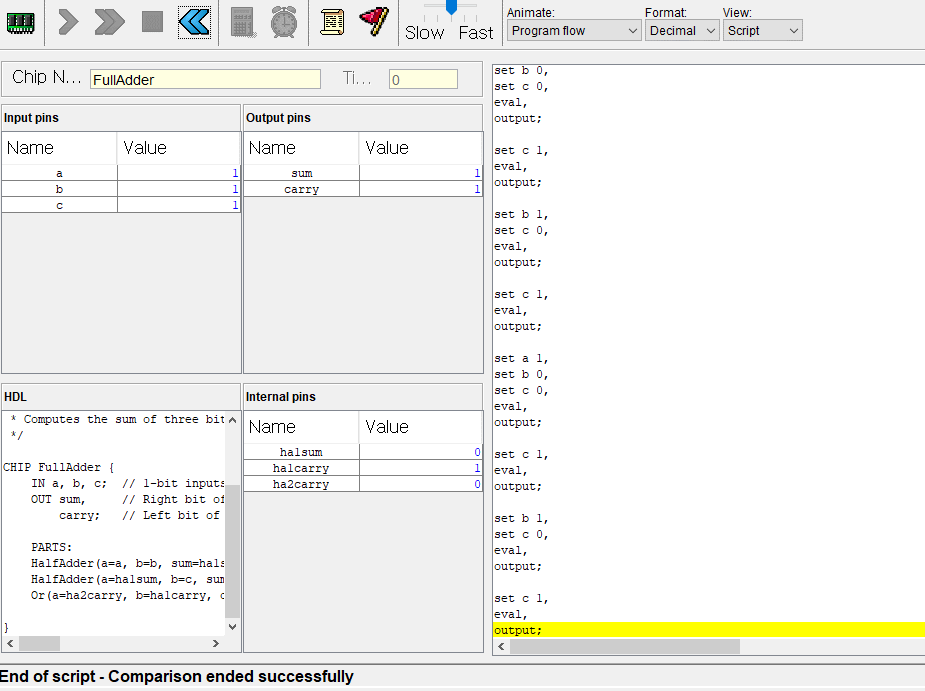
2. 전가산기
이번에는 전가산기
반가산기와 차이점이라면 캐리도 같이 입력받아서 가산연산을한다.
반가산기 2개와 or 게이트 1개로 만들 수있다.
진리표는 생략
CHIP FullAdder {
IN a, b, c; // 1-bit inputs
OUT sum, // Right bit of a + b + c
carry; // Left bit of a + b + c
PARTS:
HalfAdder(a=a, b=b, sum=ha1sum, carry=ha1carry);
HalfAdder(a=ha1sum, b=c, sum=sum, carry=ha2carry);
Or(a=ha2carry, b=ha1carry, out=carry);
}
캐리도 입력받지만 가산연산이 잘되고있다.
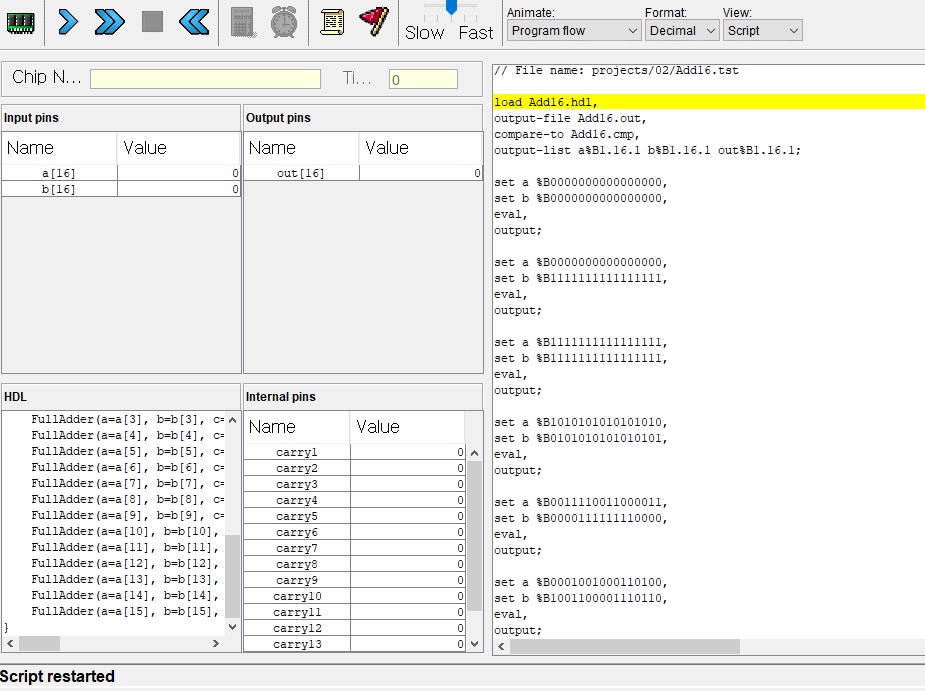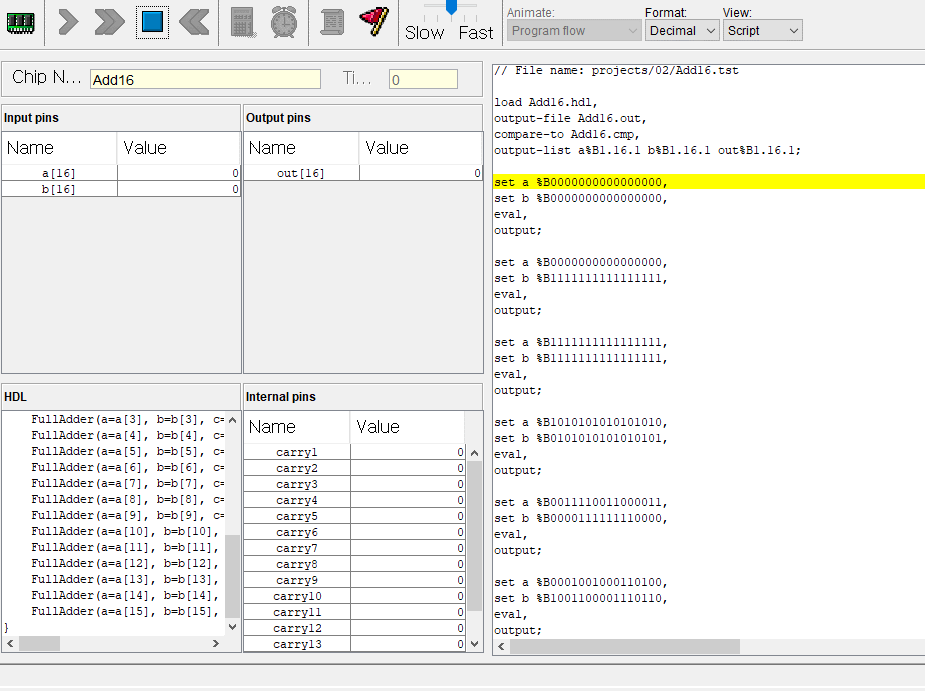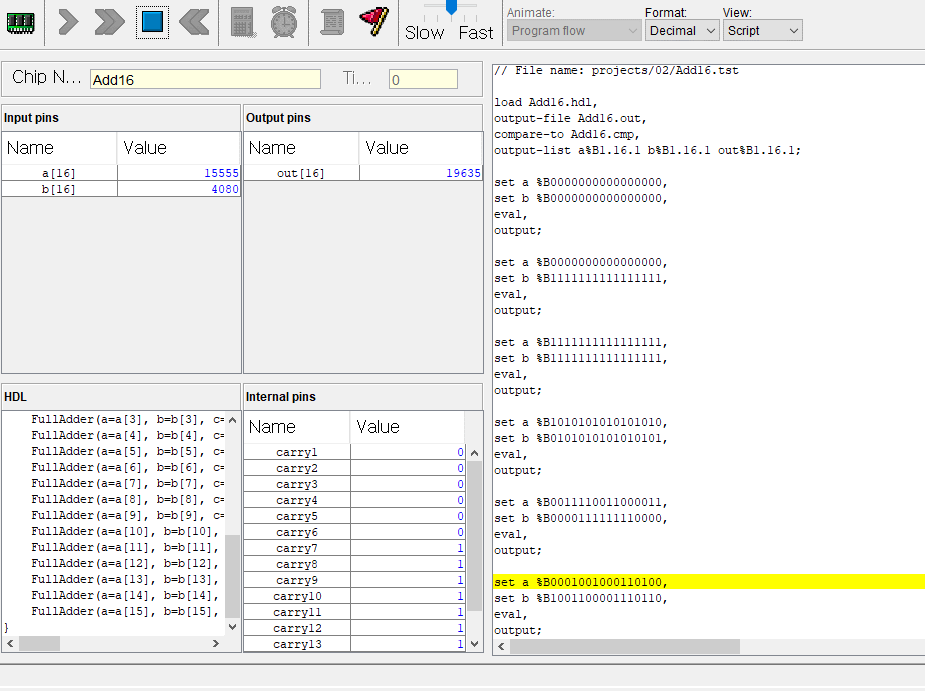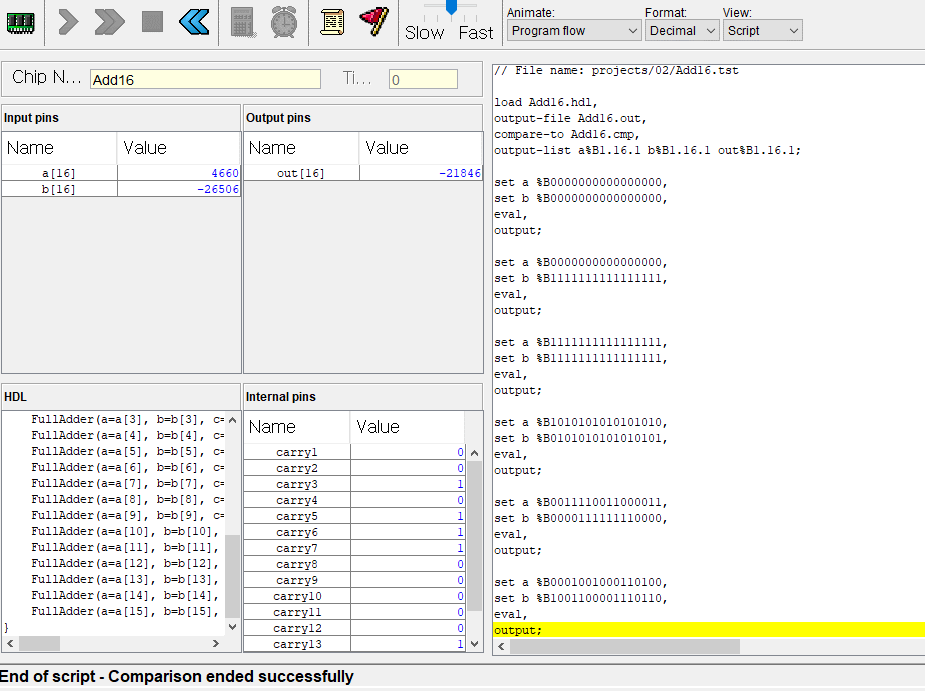
3. 16비트 전가산기
이번에는 16비트 전가산기. 처음에는 캐리가 없으니 반가산기 쓰고 뒤에서부터는 전가산기 15개 정도 쓰면될거같다.
zr의 경우 out이 0일때 1이 되고, ng의 경우 out이 음수인 경우 1이 되어 출력 결과의 상태를 나타낸다.
일단 zxy, nxy 논리연산부터 구현해보자.
z가 들어가면 0과 and16 연산을 하면되고
n이 들어가면 16비트 입력을 not16해주면 될거같다.
일단 zx값에 따라 0 or x가 나오도록 해봤다.
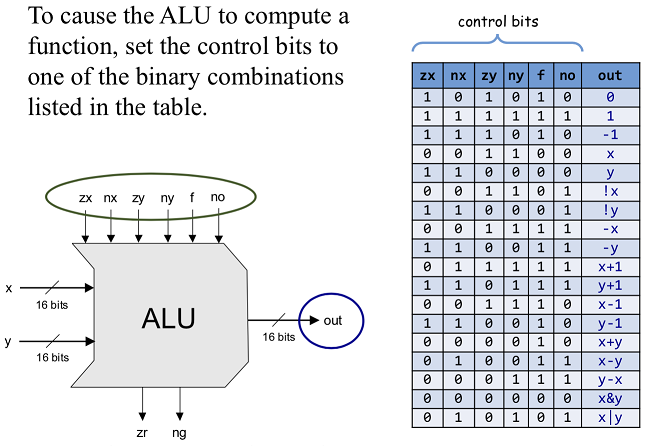
CHIP ALU {
IN
x[16], y[16], // 16-bit inputs
zx, // zero the x input?
nx, // negate the x input?
zy, // zero the y input?
ny, // negate the y input?
f, // compute out = x + y (if 1) or x & y (if 0)
no; // negate the out output?
OUT
out[16], // 16-bit output
zr, // 1 if (out == 0), 0 otherwise
ng; // 1 if (out < 0), 0 otherwise
PARTS:
Mux16(a=x, b=false, sel=zx, out=out); // zx == 0 ? x : 0000000..
}
제대로 구현한게 아니니까 진행 안되는게 맞기도하고 ,
생각한데로 x에 17이 들어갈때 zx=0이면 x가 나오고, 1이면 0이 뜬다.(mux16의 out을 바로 최종 출력으로보냇으니)
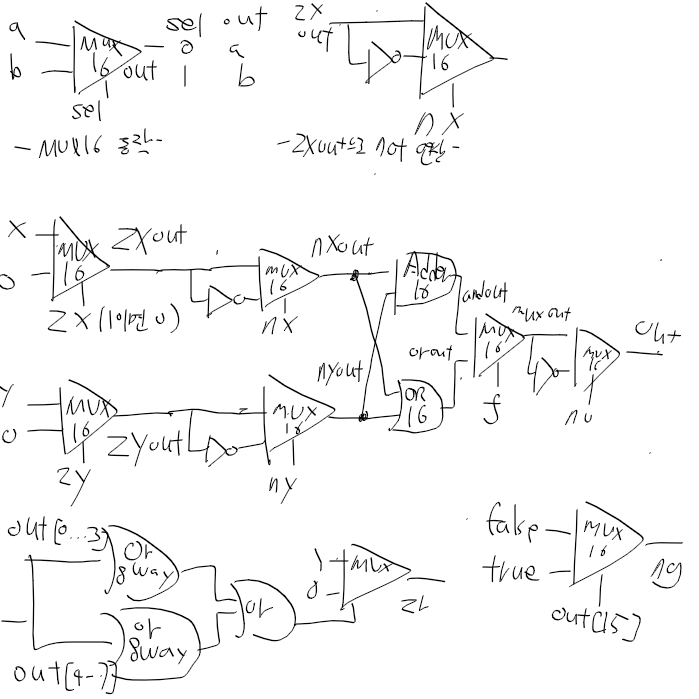
일단 이런 느낌으로 한번 그림으로 그리면
일단 nx, ny까지는 그렸다.
이제 f와 no만 고려하면 되는데,
no야 앞에서 zxout한거 처럼 not 돌리면되니까 문제없고 f랑 zr, ng 부분만 더 생각해보자
if f == 1 ? x + y : x & y이고, mux는 sel이 1일때 아래거(b)를 내보내니
mux a = and(x,y), b=or(x,y), sel=f 대강 이런식이면 될거같다.
zr, ng 빼고는 완성!
일단 out만 생각한데로 되는지 보자
CHIP ALU {
IN
x[16], y[16], // 16-bit inputs
zx, // zero the x input?
nx, // negate the x input?
zy, // zero the y input?
ny, // negate the y input?
f, // compute out = x + y (if 1) or x & y (if 0)
no; // negate the out output?
OUT
out[16], // 16-bit output
zr, // 1 if (out == 0), 0 otherwise
ng; // 1 if (out < 0), 0 otherwise
PARTS:
Mux16(a=x, b=false, sel=zx, out=zxout);
Mux16(a=y, b=false, sel=zy, out=zyout);
Not16(in=zxout, out=notzxout);
Not16(in=zyout, out=notzyout);
Mux16(a=zxout, b=notzxout, sel=nx, out=nxout);
Mux16(a=zyout, b=notzyout, sel=ny, out=nyout);
And16(a=nxout, b=nyout, out=andout);
Or16(a=nxout, b=nyout, out=orout);
Mux16(a=andout, b=orout, sel=f, out=fout);
Not16(in=fout, out=notfout);
Mux16(a=fout, b=notfout, sel=no, out=out);
}
계산이 되기는한데 생각한거랑은 좀 다르게 나온다..
자꾸 에러때문에 막혀서 일단 zr, ng부터 구현하고 다시 보자
zr은 연산 결과가 0인 경우 1이 되는거니
기존의 out을 mux sel단자에 넣어서 쓰려고 했는데
mux16 sel은 1비트, out은 16비트다.
out 모든 비트를 or연산한 결과가 0이면 zr = 1, 아니면 zr=0이 되도록
우선 out을 or16 돌린뒤에 sel에 넣으면 될거같다.
다시보니 or 16은 16비트 두입력 or연산이었네
Or8way 두개, or 1개 쓰자.
CHIP ALU {
IN
x[16], y[16], // 16-bit inputs
zx, // zero the x input?
nx, // negate the x input?
zy, // zero the y input?
ny, // negate the y input?
f, // compute out = x + y (if 1) or x & y (if 0)
no; // negate the out output?
OUT
out[16], // 16-bit output
zr, // 1 if (out == 0), 0 otherwise
ng; // 1 if (out < 0), 0 otherwise
PARTS:
Mux16(a=x, b=false, sel=zx, out=zxout);
Mux16(a=y, b=false, sel=zy, out=zyout);
Not16(in=zxout, out=notzxout);
Not16(in=zyout, out=notzyout);
Mux16(a=zxout, b=notzxout, sel=nx, out=nxout);
Mux16(a=zyout, b=notzyout, sel=ny, out=nyout);
And16(a=nxout, b=nyout, out=andout);
Or16(a=nxout, b=nyout, out=orout);
Mux16(a=andout, b=orout, sel=f, out=fout);
Not16(in=fout, out=notfout);
Mux16(a=fout, b=notfout, sel=no, out[0..7]=out0to7, out[8..15]=out8to15, out=out);
Or8Way(in=out0to7, out=or8way1out);
Or8Way(in=out8to15, out=or8way2out);
Or(a=or8way1out, b=or8way2out, out=zrsel);
Mux(a=true, b=false, sel=zrsel, out=zr);
}
zr도 구현을 잘 했는데
컨트롤비트가 111111인경우 왜 1이 나오는지 잘 이해가 안된다.
계산도 해보니 ng는 그렇다쳐도 값이 좀 이상하게 나온다.
다시 진리 테이블을 보니
f=1 일때 or연산이 아니라 + 연산을 해야되더라. +라길래 or연산을 의미하는줄알았다.
Or16을 Add16으로 바꿔줫더니 out 결과는 잘나온다.
이제마지막으로 ng만 처리해주면된다.
ng야 MSB가 1이면 음수로 보면 되니까 mux에 바로연결하자.
sel = 1- > ng = 1
sel = 0 -> ng = 0
으아아아 드디여 진리표만 보고 그림그려서 alu를 구현했다
CHIP ALU {
IN
x[16], y[16], // 16-bit inputs
zx, // zero the x input?
nx, // negate the x input?
zy, // zero the y input?
ny, // negate the y input?
f, // compute out = x + y (if 1) or x & y (if 0)
no; // negate the out output?
OUT
out[16], // 16-bit output
zr, // 1 if (out == 0), 0 otherwise
ng; // 1 if (out < 0), 0 otherwise
PARTS:
Mux16(a=x, b=false, sel=zx, out=zxout);
Mux16(a=y, b=false, sel=zy, out=zyout);
Not16(in=zxout, out=notzxout);
Not16(in=zyout, out=notzyout);
Mux16(a=zxout, b=notzxout, sel=nx, out=nxout);
Mux16(a=zyout, b=notzyout, sel=ny, out=nyout);
And16(a=nxout, b=nyout, out=andout);
Add16(a=nxout, b=nyout, out=addout);
Mux16(a=andout, b=addout, sel=f, out=fout);
Not16(in=fout, out=notfout);
Mux16(a=fout, b=notfout, sel=no, out[0..7]=out0to7, out[8..15]=out8to15, out[15]=out15, out=out);
Or8Way(in=out0to7, out=or8way1out);
Or8Way(in=out8to15, out=or8way2out);
Or(a=or8way1out, b=or8way2out, out=zrsel);
Mux(a=true, b=false, sel=zrsel, out=zr);
Mux(a=false, b=true, sel=out15, out=ng);
}