이번에는 3장을 할 차례
이 장에서는 다음의 순차 회로들을 만든다.
1. 1비트 레지스터(비트)
2. 16비트 레지스터(레지스터)
3. RAM8
4. RAM64
5. 프로그램 카운터
6. RAM512
7. RAM4K
8. RAM16K
여기서는 디지털 논리 회로에 대해서 제대로 설명하지는 않을거지만
전장에서 구현한 논리회로들을
조합논리회로
여기서 구현할 데이터를 저장한다던가, 시간에 따라 처리하는 논리회로를
순차논리회로라 한다.
논리회로의 출력에 시간의 영향이 있는지 없는지에 따라
조합논리회로와 순차논리회로가 구분되며
순차 논리회로는 = 조합논리회로 + 기억 논리회로 정도로 생각하면 되겠다.
클럭과 순차논리회로에 대해서는 디지털논리회로를 공부하면 잘 설명되어있으니
지연시간이니 기본적인 플립플롭이 뭔지에 대한 내용은 없이(설명 잘할 자신도, 그럴 여유도없고)
바로 구현시작한다.
이번에 순차논리회로 구현에 사용하는 기본 논리회로로는
데이타 플립플롭 DFF으로, 보통 공부하면 나오는 DS플립플롭에 바Q가 빠진거라 생각하면 될거같다.
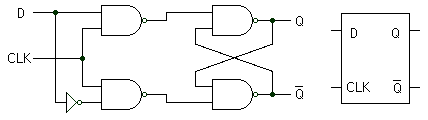
책 내용 중에서 난드는 안쓰고 왜 DFF를 바로 쓰는지 내용을 설명하는 부분이 있었는데,
난드 게이트가지고 루프 만들고 최적화하기에는 너무 복잡해서 빌트인 DFF를 주니
이걸로 만들라고 한 내용이 있었던걸로 기억한다. 어딘진 잊었지만 대강 그런내용이었던거같다.
1. bit(1bit registor)
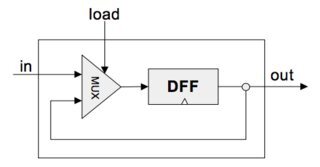
- 이 책에서는 1비트 레지스터를 비트라 부르기로 하고, DFF 하나를 이용해서 만들라고한다.
- DFF의 문제가 클럭을 받는동안 D 단자 입력을 Q로 내보내기는하는데, 새로운 값이 들어오면 새 값으로 저장할지 기존의 값을 유지할지 둘중 하나를 골라야하나 그럴수가없다.
- 그래서 비트는 (클럭은 당연하니 빼고) 입력으로 in, load, 출력으로 out을받는 형태인데 load의 값에 따라 in을 저장할지, 들어오는 in을 무시하고 기존의 값을 유지할지를 판단한다.
- 새로운 입력 저장 : load(t) =1이면 out(t+1) = in(t)
- 기존의 입력 유지 : load(t)=0, out(t+1) = out(t)
- 1비트 레지스터의 인터페이스가 어떻게 됫는지 찾아보다가 그냥 멀티비트 레지스터도 같이있는걸가져왔다.

그래서 load 값에 따라 저장하고 저장안하도록 어떻게 구현하나.
지난 글에 먹스 잘써먹었던것처럼 먹스써서 load = 1일때 새값이 들어와야하니 in이 넘어가게
load = 0일땐 기존 값을 유지해야하니 dff out이 들어오도록 해주면 된다.
CHIP Bit {
IN in, load;
OUT out;
PARTS:
Mux(a=loop1, b=in, sel=load, out=muxout);
DFF(in=muxout, out=loop1, out=out);
}mux쓸때마다 햇갈리는거지만
sel이 0일대 a, 1일때 b를 출력한다.
아무튼 1비트 레지스터 완성
2. 16비트 레지스터(레지스터)
16비트 레지스터의 경우 방금 구현한 비트를 16개 놓으면 된다.
CHIP Register {
IN in[16], load;
OUT out[16];
PARTS:
Bit(in=in[0], load=load, out=out[0]);
Bit(in=in[1], load=load, out=out[1]);
Bit(in=in[2], load=load, out=out[2]);
Bit(in=in[3], load=load, out=out[3]);
Bit(in=in[4], load=load, out=out[4]);
Bit(in=in[5], load=load, out=out[5]);
Bit(in=in[6], load=load, out=out[6]);
Bit(in=in[7], load=load, out=out[7]);
Bit(in=in[8], load=load, out=out[8]);
Bit(in=in[9], load=load, out=out[9]);
Bit(in=in[10], load=load, out=out[10]);
Bit(in=in[11], load=load, out=out[11]);
Bit(in=in[12], load=load, out=out[12]);
Bit(in=in[13], load=load, out=out[13]);
Bit(in=in[14], load=load, out=out[14]);
Bit(in=in[15], load=load, out=out[15]);
}
3. RAM8
드디여! 이름은 자주 듣지만 어떻게 동작하는지는 몰랐던 램을 구현할 차례다.
책에서 설명하기를 RAM이 Random Access Memory인 이유는
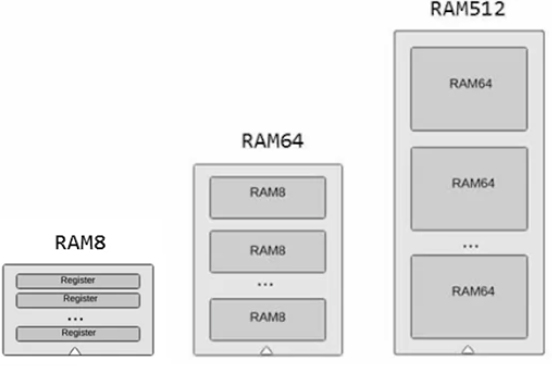
RAM을 구성하고 있는 어떤 레지스터든 간에
이 레지스터의 크기가 2bit든, 8비트든 16비트든
레지스터가 1024개든 4048개든 상관없이
모든 레지스터, 그중에 임의로 선택한 레지스터에 접근하는 시간이 동등하며 선택한 즉시 접근하여
Random 임의 Access 접근 Memory가 된다고 한다.

이제 8개의 레지스터로 구성된 RAM8을 구현해보자.
여기서 RAMn의 경우 입력으로 16비트 in 단자, 비트 수가 log_2 n인 address 단자,
write할지 read할지 판단하는 1비트인 load 단자가 있고,
출력은 16비트 크기인 out 하나가 나온다.
load가 0인경우 읽는 것이므로 현재 시간 t의 해당 주소의 16비트 값을 가져오고
load가 1인경우 읽는 것 자체는 load 0과 동일하게 현재 시간 t의 값을 가져오지만, t+1부터 입력한 값이 쓰여진게된다.
어드레스 단자의 경우
저장하는 레지스터의 개수가 8개 인경우, 3비트를 입력
저장하는 레지스터가 64개인경우, 6비트를 입력받는데
mux에서 입력 받는 개수가 늘어늘때 sel단자를 늘리던거랑 동일하게 생각하면 될거같다.
일단 RAM8부터 구현해보자.
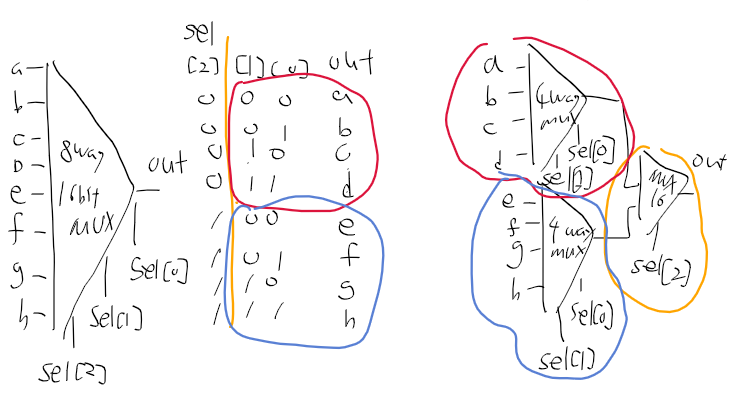
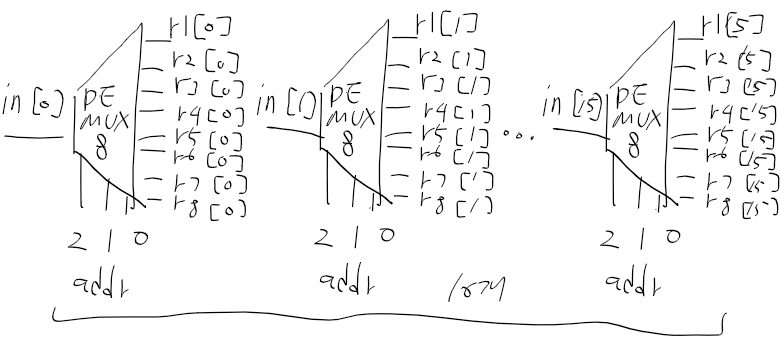
그냥 머리로하려니까 안되서 그림으로 그리면
하나를 입력받아 여러개 중에 하나 선택하니 demux 쓰는거같은데
일단 1비트 4웨이 디먹스를 보면 이런식으로 되어있다.

하지만 우리는 출력이 8개니 8웨이 디먹스를 쓰면 되고,
하지만 입력이 16비트라.. 16개를 써야될거같은데?
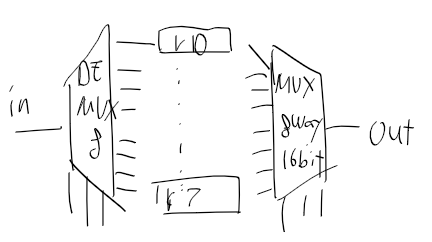
1비트 8웨이 디먹스를 이렇게 놓는다면
* 8way 디먹스 인터페이스는 입력으로 in, sel[3] 출력으로 a, b, c, d, e, f, g, h다.

이결 16개해서 이런식이면 될거같다.
레지스터에 저장후 값을 출력해야하니
레지스터 8개에서 mux 8way 16bit로 하나를 sel는 그대로해서 출력하자
그림과 코드는 대강 이런식인데
CHIP RAM8 {
IN in[16], load, address[3];
OUT out[16];
PARTS:
DMux8Way(in=in[0], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r00, b=r01, c=r02, d=r03, e=r04, f=r05, g=r06, h=r07);
DMux8Way(in=in[1], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r10, b=r11, c=r12, d=r13, e=r14, f=r15, g=r16, h=r17);
DMux8Way(in=in[2], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r20, b=r21, c=r22, d=r23, e=r24, f=r25, g=r26, h=r27);
DMux8Way(in=in[3], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r30, b=r31, c=r32, d=r33, e=r34, f=r35, g=r36, h=r37);
DMux8Way(in=in[4], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r40, b=r41, c=r42, d=r43, e=r44, f=r45, g=r46, h=r47);
DMux8Way(in=in[5], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r50, b=r51, c=r52, d=r53, e=r54, f=r55, g=r56, h=r57);
DMux8Way(in=in[6], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r60, b=r61, c=r62, d=r63, e=r64, f=r65, g=r66, h=r67);
DMux8Way(in=in[7], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r70, b=r71, c=r72, d=r73, e=r74, f=r75, g=r76, h=r77);
DMux8Way(in=in[8], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r80, b=r81, c=r82, d=r83, e=r84, f=r85, g=r86, h=r87);
DMux8Way(in=in[9], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r90, b=r91, c=r92, d=r93, e=r94, f=r95, g=r96, h=r97);
DMux8Way(in=in[10], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r100, b=r101, c=r102, d=r103, e=r104, f=r105, g=r106, h=r107);
DMux8Way(in=in[11], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r110, b=r111, c=r112, d=r113, e=r114, f=r115, g=r116, h=r117);
DMux8Way(in=in[12], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r120, b=r121, c=r122, d=r123, e=r124, f=r125, g=r126, h=r127);
DMux8Way(in=in[13], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r130, b=r131, c=r132, d=r133, e=r134, f=r135, g=r136, h=r137);
DMux8Way(in=in[14], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r140, b=r141, c=r142, d=r143, e=r144, f=r145, g=r146, h=r147);
DMux8Way(in=in[15], sel[2]=address[2], sel[1]=address[1], sel[0]=address[0]
, a=r150, b=r151, c=r152, d=r153, e=r154, f=r155, g=r156, h=r157);
Register(in[0]=r00, in[1]=r10, in[2]=r20, in[3]=r30, in[4]=r40, in[5]=r50,
in[6]=r60, in[7]=r70, in[8]= r80, in[9] = r90, in[10] = r100, in[11] =r110,
in[12] =r120, in[13] =r130, in[14]=r140, in[15]=r150, load=load, out=r0);
Register(in[0]=r01, in[1]=r11, in[2]=r21, in[3]=r31, in[4]=r41, in[5]=r51,
in[6]=r61, in[7]=r71, in[8]= r81, in[9] = r91, in[10] = r101, in[11] =r111,
in[12] =r121, in[13] =r131, in[14]=r141, in[15]=r151, load=load, out=r1);
Register(in[0]=r02, in[1]=r12, in[2]=r22, in[3]=r32, in[4]=r42, in[5]=r52,
in[6]=r62, in[7]=r72, in[8]= r82, in[9] = r92, in[10] = r102, in[11] =r112,
in[12] =r122, in[13] =r132, in[14]=r142, in[15]=r152, load=load, out=r2);
Register(in[0]=r03, in[1]=r13, in[2]=r23, in[3]=r33, in[4]=r43, in[5]=r53,
in[6]=r63, in[7]=r73, in[8]= r83, in[9] = r93, in[10] = r103, in[11] =r113,
in[12] =r123, in[13] =r130, in[14]=r143, in[15]=r153, load=load, out=r3);
Register(in[0]=r04, in[1]=r14, in[2]=r24, in[3]=r34, in[4]=r44, in[5]=r54,
in[6]=r64, in[7]=r74, in[8]= r84, in[9] = r94, in[10] = r104, in[11] =r114,
in[12] =r124, in[13] =r134, in[14]=r144, in[15]=r154, load=load, out=r4);
Register(in[0]=r05, in[1]=r15, in[2]=r25, in[3]=r35, in[4]=r45, in[5]=r55,
in[6]=r65, in[7]=r75, in[8]= r85, in[9] = r95, in[10] = r105, in[11] =r115,
in[12] =r125, in[13] =r135, in[14]=r145, in[15]=r155, load=load, out=r5);
Register(in[0]=r06, in[1]=r16, in[2]=r26, in[3]=r36, in[4]=r46, in[5]=r56,
in[6]=r66, in[7]=r76, in[8]= r86, in[9] = r96, in[10] = r106, in[11] =r116,
in[12] =r126, in[13] =r136, in[14]=r146, in[15]=r156, load=load, out=r6);
Register(in[0]=r07, in[1]=r17, in[2]=r27, in[3]=r37, in[4]=r47, in[5]=r57,
in[6]=r67, in[7]=r73, in[8]= r87, in[9] = r97, in[10] = r107, in[11] =r117,
in[12] =r127, in[13] =r137, in[14]=r147, in[15]=r157, load=load, out=r7);
Mux8Way16(a=r0, b=r1, c=r2, d=r3, e=r4, f=r5, g=r6, h=r7, sel=address, out=out);
}
코드는 보기도 안좋고 성능도 안좋겠지만 바로 생각나는게 이거라 이렇게 됬다.
동작도 거의 잘 되기는한데 문제가
모든 레지스터에 load를 동일하게 주는 탓에
다른 주소 연산중에 레지스터에 기존에 입력된 값이 사라져서인지
기존의 값을 읽어들이려할때마다 은근히 에러가 꽤 발생하고 있다.
마지막으로 할건 address 주소만 load를 주고 나머지 레지스터 load는 덮어쓰면 안되니 0을 주면 될거같은데..
디먹스가 이렇게 유용한건지 몰랐는데 만능 디먹스로 해결하자
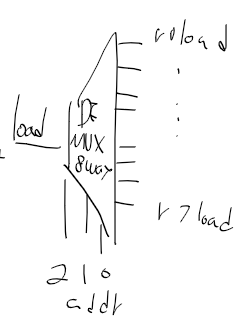
DMux8Way(in=load, sel=address, a=r0load, b=r1load, c=r2load, d=r3load,
e=r4load, f=r5load, g=r6load, h=r7load);
Register(in[0]=r00, in[1]=r10, in[2]=r20, in[3]=r30, in[4]=r40, in[5]=r50,
in[6]=r60, in[7]=r70, in[8]= r80, in[9] = r90, in[10] = r100, in[11] =r110,
in[12] =r120, in[13] =r130, in[14]=r140, in[15]=r150, load=r0load, out=r0);
Register(in[0]=r01, in[1]=r11, in[2]=r21, in[3]=r31, in[4]=r41, in[5]=r51,
in[6]=r61, in[7]=r71, in[8]= r81, in[9] = r91, in[10] = r101, in[11] =r111,
in[12] =r121, in[13] =r131, in[14]=r141, in[15]=r151, load=r1load, out=r1);
Register(in[0]=r02, in[1]=r12, in[2]=r22, in[3]=r32, in[4]=r42, in[5]=r52,
in[6]=r62, in[7]=r72, in[8]= r82, in[9] = r92, in[10] = r102, in[11] =r112,
in[12] =r122, in[13] =r132, in[14]=r142, in[15]=r152, load=r2load, out=r2);
Register(in[0]=r03, in[1]=r13, in[2]=r23, in[3]=r33, in[4]=r43, in[5]=r53,
in[6]=r63, in[7]=r73, in[8]= r83, in[9] = r93, in[10] = r103, in[11] =r113,
in[12] =r123, in[13] =r130, in[14]=r143, in[15]=r153, load=r3load, out=r3);
Register(in[0]=r04, in[1]=r14, in[2]=r24, in[3]=r34, in[4]=r44, in[5]=r54,
in[6]=r64, in[7]=r74, in[8]= r84, in[9] = r94, in[10] = r104, in[11] =r114,
in[12] =r124, in[13] =r134, in[14]=r144, in[15]=r154, load=r4load, out=r4);
Register(in[0]=r05, in[1]=r15, in[2]=r25, in[3]=r35, in[4]=r45, in[5]=r55,
in[6]=r65, in[7]=r75, in[8]= r85, in[9] = r95, in[10] = r105, in[11] =r115,
in[12] =r125, in[13] =r135, in[14]=r145, in[15]=r155, load=r5load, out=r5);
Register(in[0]=r06, in[1]=r16, in[2]=r26, in[3]=r36, in[4]=r46, in[5]=r56,
in[6]=r66, in[7]=r76, in[8]= r86, in[9] = r96, in[10] = r106, in[11] =r116,
in[12] =r126, in[13] =r136, in[14]=r146, in[15]=r156, load=r6load, out=r6);
Register(in[0]=r07, in[1]=r17, in[2]=r27, in[3]=r37, in[4]=r47, in[5]=r57,
in[6]=r67, in[7]=r73, in[8]= r87, in[9] = r97, in[10] = r107, in[11] =r117,
in[12] =r127, in[13] =r137, in[14]=r147, in[15]=r157, load=r7load, out=r7);
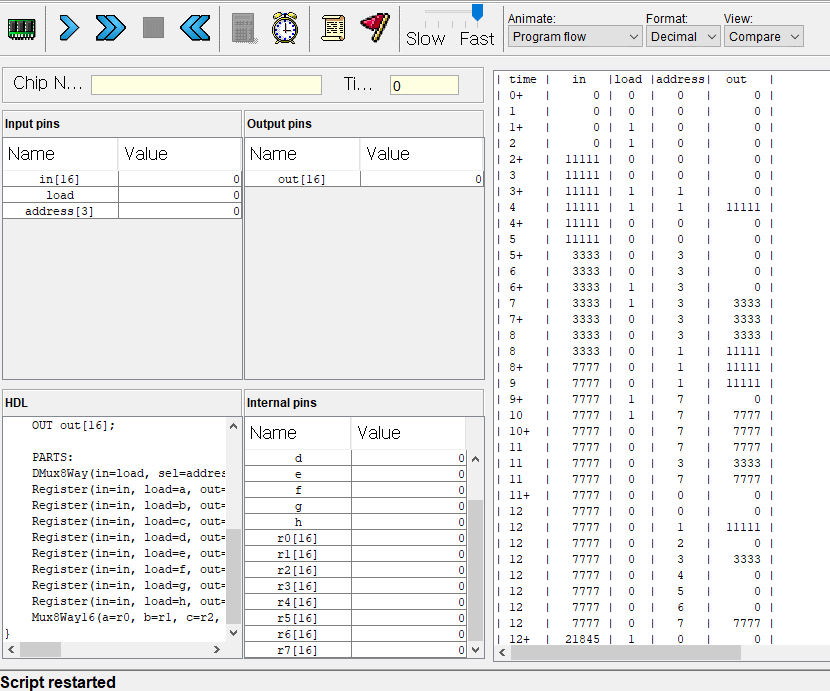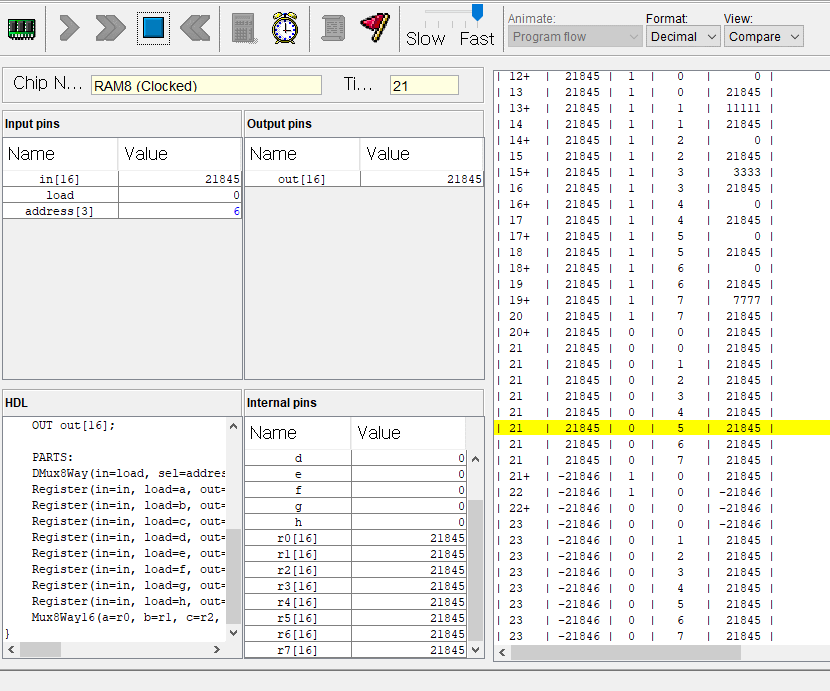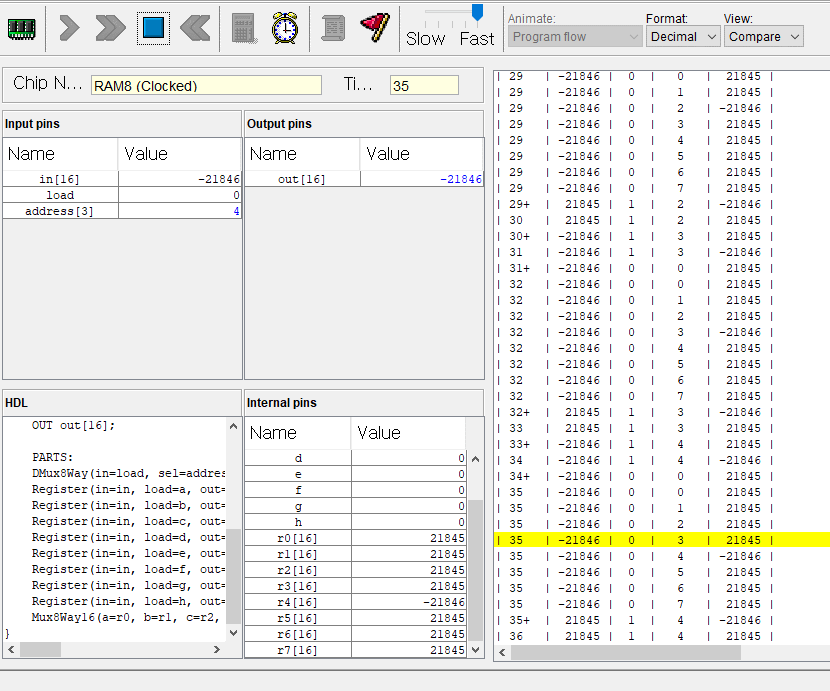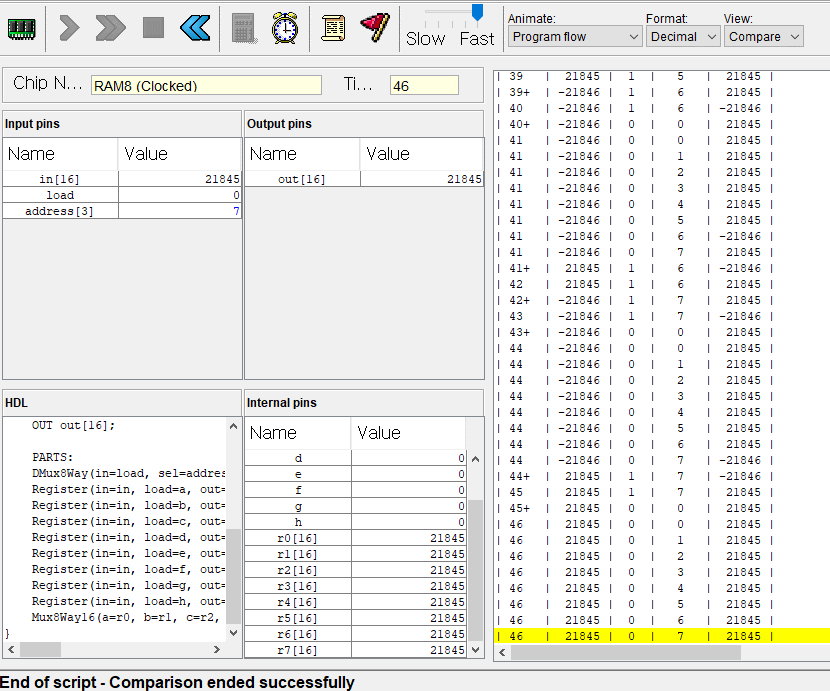
이젠 저장도 잘되고, 로드도 잘되는데
오버플로우 때문인지 중간에 이상한 값이 떠서 자꾸 막힌다..
그냥 여기서 더 시간낭비하기싫어서
남이쓴거 써야겠다.
이렇게 단순하게 할수있는걸 내가 뭘한걸까 ㅋㅋㅋㅋ
CHIP RAM8 {
IN in[16], load, address[3];
OUT out[16];
PARTS:
DMux8Way(in=load, sel=address, a=a, b=b, c=c, d=d, e=e, f=f, g=g, h=h);
Register(in=in, load=a, out=r0);
Register(in=in, load=b, out=r1);
Register(in=in, load=c, out=r2);
Register(in=in, load=d, out=r3);
Register(in=in, load=e, out=r4);
Register(in=in, load=f, out=r5);
Register(in=in, load=g, out=r6);
Register(in=in, load=h, out=r7);
Mux8Way16(a=r0, b=r1, c=r2, d=r3, e=r4, f=r5, g=r6, h=r7, sel=address, out=out);
}
4. RAM64
RAM8에서의 삽질을 멈추고 이번에는 RAM64를 만들어보자.
RAM64는 이름 그대로 레지스터 64개니까 RAM8 8개를 쓰면 된다.
어드레스의 경우 6비트가 되고.
아까의 삽질을 또 하지 않고 정리하면 이럴거같은데
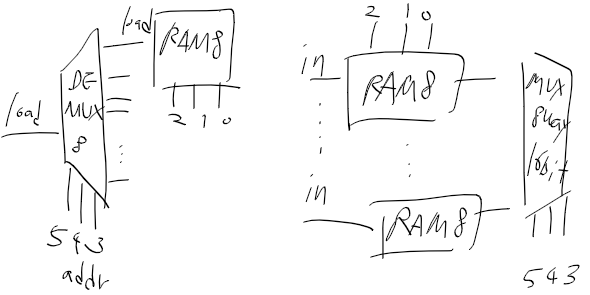
CHIP RAM64 {
IN in[16], load, address[6];
OUT out[16];
PARTS:
DMux8Way(in=load, sel[2]=address[5], sel[1]=address[4], sel[0]=address[3],
a=ram0load, b=ram1load, c=ram2load, d=ram3load, e=ram4load,
f=ram5load, g=ram6load, h=ram7load);
RAM8(in=in, load=ram0load, address[2]=address[2], address[1]=address[1], address[0]=address[0], out=r0);
RAM8(in=in, load=ram1load, address[2]=address[2], address[1]=address[1], address[0]=address[0], out=r1);
RAM8(in=in, load=ram2load, address[2]=address[2], address[1]=address[1], address[0]=address[0], out=r2);
RAM8(in=in, load=ram3load, address[2]=address[2], address[1]=address[1], address[0]=address[0], out=r3);
RAM8(in=in, load=ram4load, address[2]=address[2], address[1]=address[1], address[0]=address[0], out=r4);
RAM8(in=in, load=ram5load, address[2]=address[2], address[1]=address[1], address[0]=address[0], out=r5);
RAM8(in=in, load=ram6load, address[2]=address[2], address[1]=address[1], address[0]=address[0], out=r6);
RAM8(in=in, load=ram7load, address[2]=address[2], address[1]=address[1], address[0]=address[0], out=r7);
Mux8Way16(a=r0, b=r1, c=r2, d=r3, e=r4, f=r5, g=r6, h=r7,
sel[2]=address[5], sel[1]=address[4], sel[0]=address[3], out=out);
}다행이 이번에는 잘된다!
* 시간이 느니까 용량도 너무 커져서 gif 를 반토막 냈다. 그래서 time이 2-3씩 뛴다.

5. 프로그램 카운터
PC는 조금 뒤에 하고 RAM부터 마무리하자
6. RAM512
RAM8가지고 RAM64도 만들었는데 안될게있나. 아까 그림 그린거처럼 해보면 될거같다.
CHIP RAM512 {
IN in[16], load, address[9];
OUT out[16];
PARTS:
DMux8Way(in=load, sel[2]=address[8],sel[1]=address[7],sel[0]=address[6],
a=r0l, b=r1l, c=r2l, d=r3l, e=r4l, f=r5l, g=r6l, h=r7l);
RAM64(in=in, load=r0l, address[0..5]=address[0..5], out=r0);
RAM64(in=in, load=r1l, address[0..5]=address[0..5], out=r1);
RAM64(in=in, load=r2l, address[0..5]=address[0..5], out=r2);
RAM64(in=in, load=r3l, address[0..5]=address[0..5], out=r3);
RAM64(in=in, load=r4l, address[0..5]=address[0..5], out=r4);
RAM64(in=in, load=r5l, address[0..5]=address[0..5], out=r5);
RAM64(in=in, load=r6l, address[0..5]=address[0..5], out=r6);
RAM64(in=in, load=r7l, address[0..5]=address[0..5], out=r7);
Mux8Way16(a=r0, b=r1, c=r2, d=r3, e=r4, f=r5, g=r6, h=r7,
sel[2]=address[8], sel[1]=address[7], sel[0]=address[6], out=out);
}
7. RAM4K
남은 RAM4K, RAM16K도 RAM512 내용 복붙해서 조금 고치면 될거같다.
CHIP RAM4K {
IN in[16], load, address[12];
OUT out[16];
PARTS:
DMux8Way(in=load, sel[2]=address[11],sel[1]=address[10],sel[0]=address[9],
a=r0l, b=r1l, c=r2l, d=r3l, e=r4l, f=r5l, g=r6l, h=r7l);
RAM512(in=in, load=r0l, address[0..8]=address[0..8], out=r0);
RAM512(in=in, load=r1l, address[0..8]=address[0..8], out=r1);
RAM512(in=in, load=r2l, address[0..8]=address[0..8], out=r2);
RAM512(in=in, load=r3l, address[0..8]=address[0..8], out=r3);
RAM512(in=in, load=r4l, address[0..8]=address[0..8], out=r4);
RAM512(in=in, load=r5l, address[0..8]=address[0..8], out=r5);
RAM512(in=in, load=r6l, address[0..8]=address[0..8], out=r6);
RAM512(in=in, load=r7l, address[0..8]=address[0..8], out=r7);
Mux8Way16(a=r0, b=r1, c=r2, d=r3, e=r4, f=r5, g=r6, h=r7,
sel[2]=address[11], sel[1]=address[10], sel[0]=address[9], out=out);
}
8. RAM16K
RAM16K는 4K를 4개만 쓰면되니
디먹스, 먹스 8way가 아니라 4way를 쓰자
CHIP RAM16K {
IN in[16], load, address[14];
OUT out[16];
PARTS:
DMux4Way(in=load, sel[1]=address[13],sel[0]=address[12],
a=r0l, b=r1l, c=r2l, d=r3l);
RAM4K(in=in, load=r0l, address[0..11]=address[0..11], out=r0);
RAM4K(in=in, load=r1l, address[0..11]=address[0..11], out=r1);
RAM4K(in=in, load=r2l, address[0..11]=address[0..11], out=r2);
RAM4K(in=in, load=r3l, address[0..11]=address[0..11], out=r3);
Mux4Way16(a=r0, b=r1, c=r2, d=r3,
sel[1]=address[13], sel[0]=address[12], out=out);
}

으아아아 진짜 이렇게 RAM 16K를 하드웨어로 구현했다.
오늘 안에는 CPU까지 할수 있을줄 알았는데,
메모리 구현에서 이렇게 오래걸릴줄 몰랐다.
아직 PC도 못만들었는데,
마지막으로 프로그램 카운터를 만들고 마치자.
이번에 구현할 카운터는 16비트 카운터로
카운터야 기본적인 동작이 0에서 시작해서 한클럭마다 1씩 올라간다.
입력 : 16비트 입력, load, inc, reset
출력 : 16비트 출력
동작
if reset = 1 인경우 out(t+1) = 0
else if load = 1일때 out(t+1) = in(t)
else if inc = 1 일때는 out(t+1) = out(t) + 1
else out(t+1) = out(t)
내가 구현할 카운터는 16비트 레지스터에다가
reset 기능 load 기능 inc 기능이 필요하니
inc는 앞장에서 만든 증산기 쓰면되고
reset, load는 mux16가지고 다루면 될거같다.
일단 PC 완성시키고 정리한다고 봤는데
RAM보다 더 어려웠다.
RAM이야 8, 64, 512 .. 여러개다보니 오래걸렸는데
이건 뭐 지금까지 했던것들 다써서 만들어야하는 것도 모잘라서
프로그램 카운터가 reset을 최우선, 그다음 load를 우선, 그다음 inc, 이더저도 아니면 상태 유지다보니
위 조건에 맞게 겹치지 않게 세 연산을 하나의 레지스터에 저장되도록 회로 배치하는게 쉽지 않았다.
도저히 어떻게 해야할지 감이 안잡혀 우선 필요해보이는 논리 회로랑, reset 연산, load 연산, inc 연산 따로따로 어떻게 할수 있는지 올려봤다.

문제는 아래의 1, 2, 3 회로들을 단순히 먹스 디먹스로 연결시키면
레지스터를 3개를 쓰는게 되어서 할수가 없었고
하나의 레지스터만 쓰도록, 조건을 고려해서 동작하도록 한참 고민해서 완성시켰다!
일단 레지스터 로드 단자 부터 고민해봤는데
1. reset, load, inc 순서대로 셋중 하나의 값만을 반영해야 했기 때문에 먹스를 3개 연결한 형태로 만들었다.
2. 레지스터의 입력이 오기전에 reset, load, inc 연산하도록 가장 먼저되는 reset을 레지스터 옆에, 가장 나중에 되는 inc 연산은 멀리 그리고 셋다 아닌경우를 처리하기 위해 먹스로 in을 그대로 레지스터 까지 전달하도록 했다.
처음에는 in과 inc연산을 한 in 두개를 inc mux 넣었더니, 기존의 값을 +1하는게 아니라
새로운 입력을 저장해서 +1하는 바람에 레지스터 아웃을 피드백루프해서 in 대신 inc의 입력 으로 넣었다.

생각보다 어려워서 시간 걸리긴 했지만 완성했고 잘돌아간다.
CHIP PC {
IN in[16],load,inc,reset;
OUT out[16];
PARTS:
Inc16(in=loop1, out=incout);
Mux16(a=in, b=incout, sel=inc, out=incmuxout);
Mux16(a=incmuxout, b=in, sel=load, out=loadmuxout);
Mux16(a=loadmuxout, b=false, sel=reset, out=resetmuxout);
Mux(a=false, b=true, sel=inc, out=incmuxload);
Mux(a=incmuxload, b=true, sel=load, out=loadmuxload);
Mux(a=loadmuxload, b=true, sel=reset, out=resetmuxload);
Register(in=resetmuxout, load=resetmuxload, out=loop1, out=out);
}

와 진짜 지난번에 nand2tetris할때는 alu부터 못넘기고 포기했었는데
드디여 CPU 만들기 앞에 까지 왔다.
이렇게 3장을 마무리했지만
이거 다음 장은 기계어에 대해서 소개하는데
기계어와 hack 컴퓨터에 쓰는 어샘블리어부터 파악해야
왜 이런 cpu 구조를 갖는지 알수있기 때문이고,
실제 cpu 만드는건 5장 가서야 한다.
오늘이면 cpu까지 다만들줄 알았는데,
여유 되는데로 마저 진행해야지
'컴퓨터과학 > 디지털회로' 카테고리의 다른 글
| nand2tetris - 7. hack 기계어와 어셈블리어 2 (0) | 2022.05.17 |
|---|---|
| nand2tetris - 6. hack 기계어와 어셈블리어 1 (0) | 2022.05.16 |
| nand2tetris - 4. 반가산기부터 ALU까지 구현하기 (0) | 2022.05.15 |
| nand2tetris - 3. 4way/8way 16bit muletiplexer까지 기본논리회로 마무리 (0) | 2022.05.15 |
| nand2tetris- 2. Xor부터 8way Demultiplexer까지 (0) | 2022.05.15 |